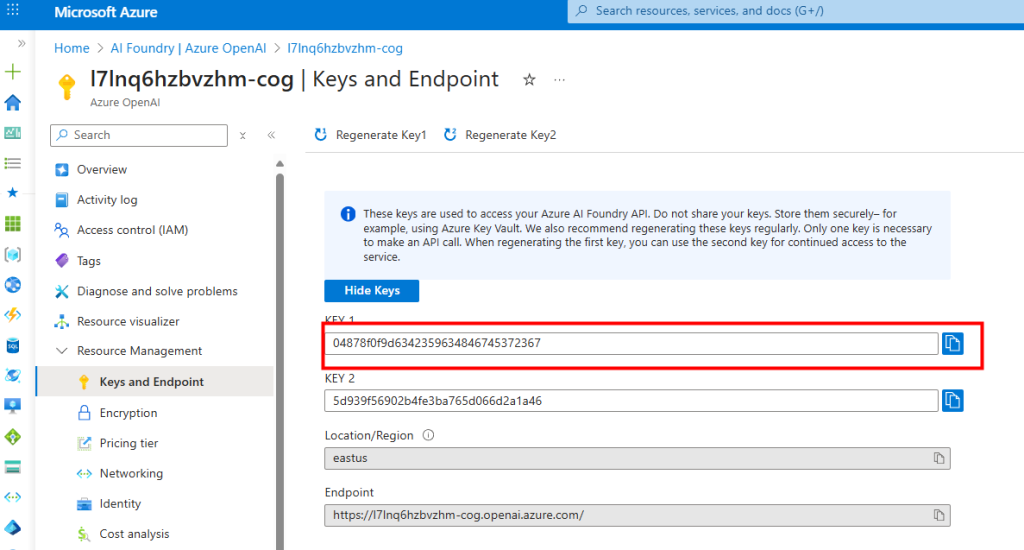
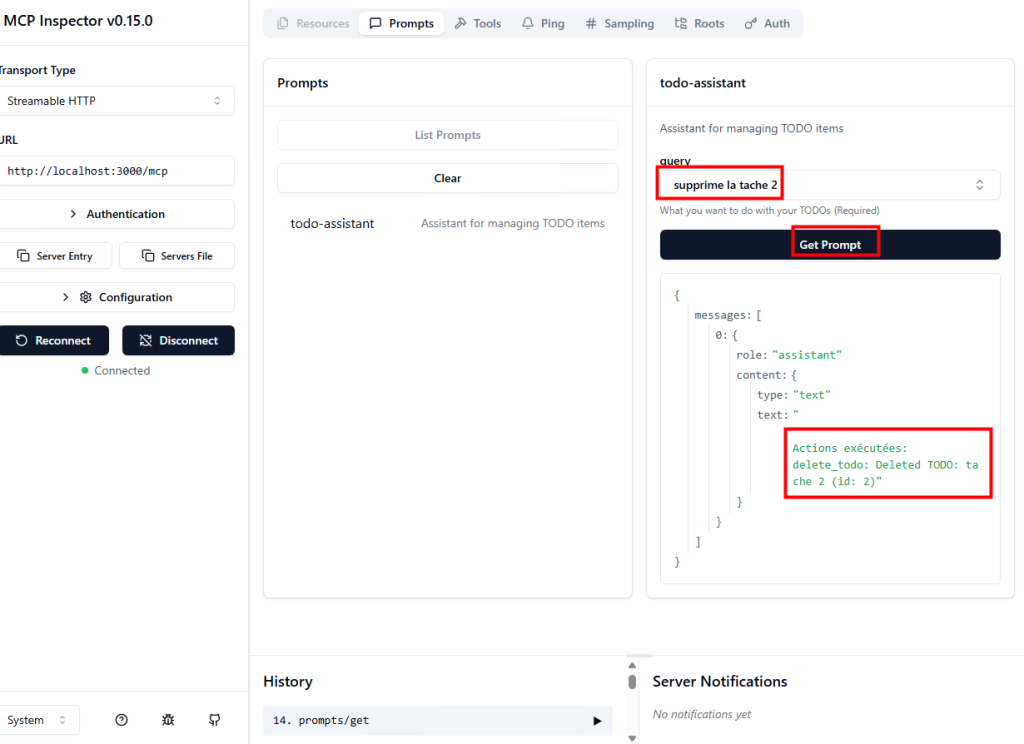
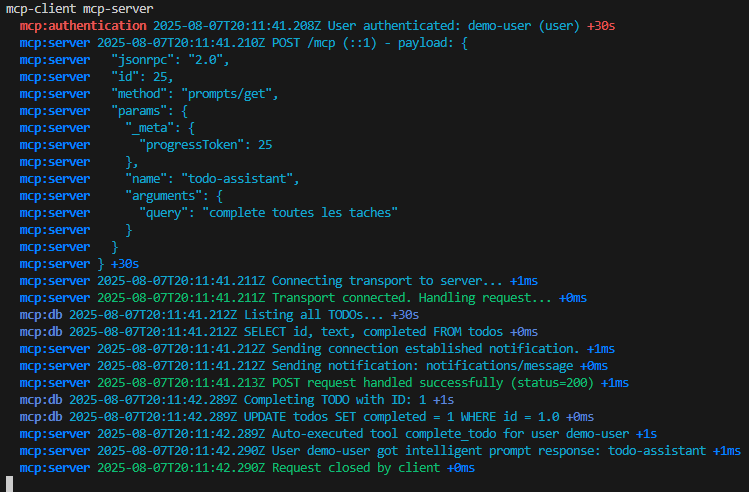
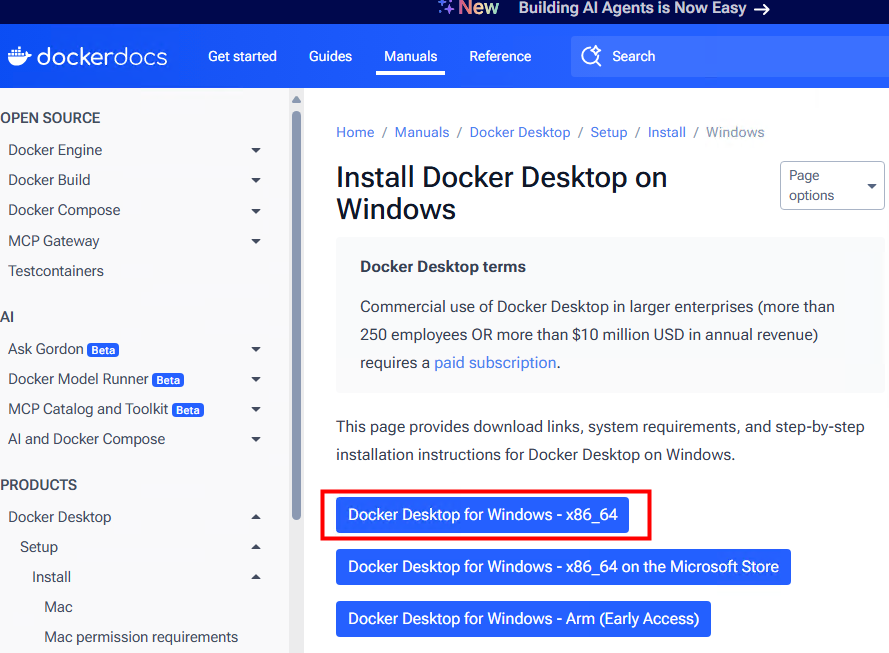
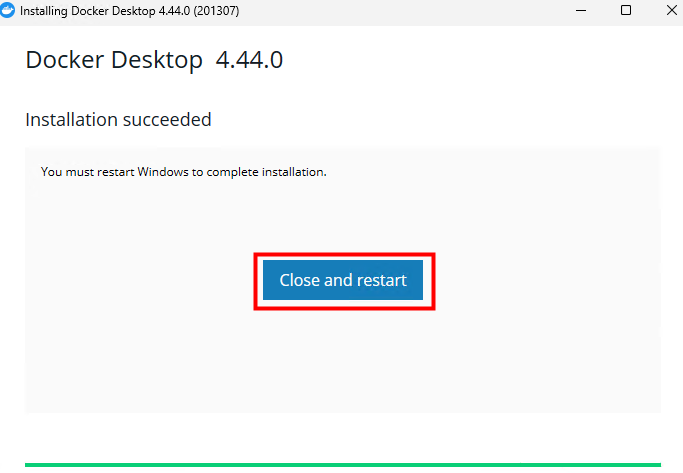
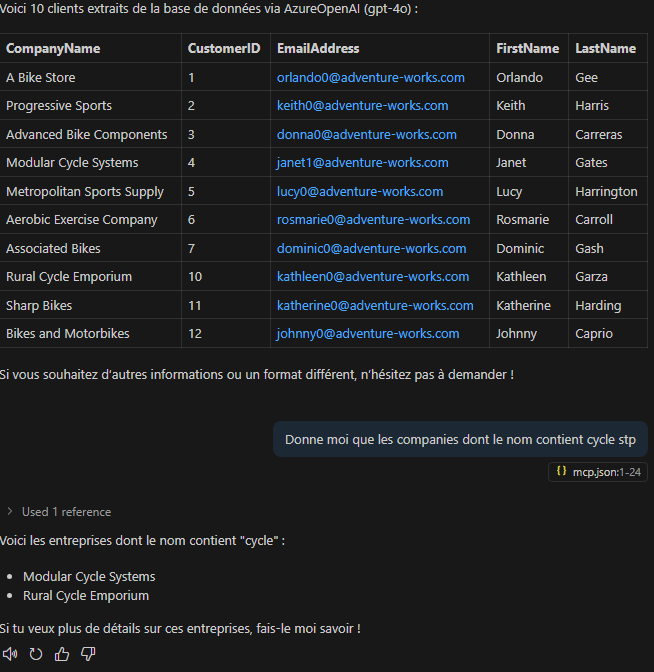
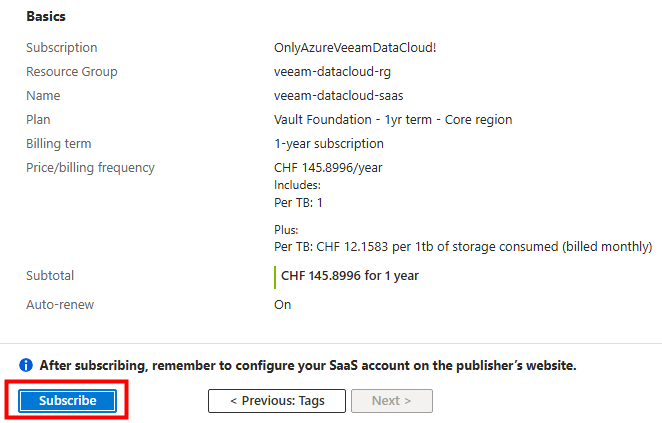
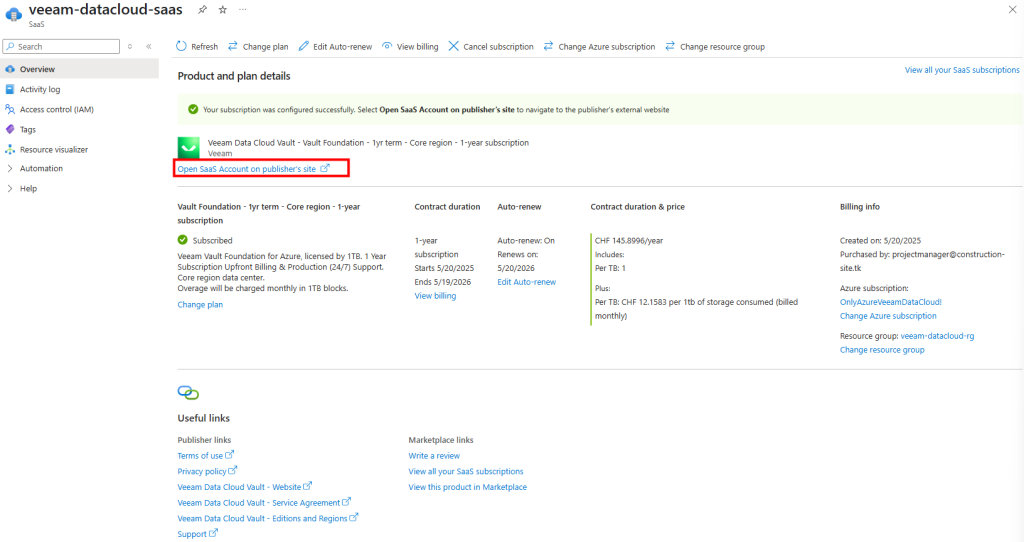
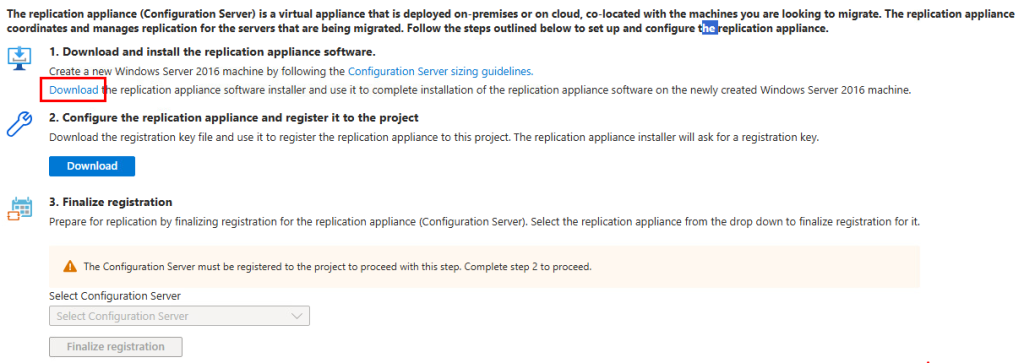
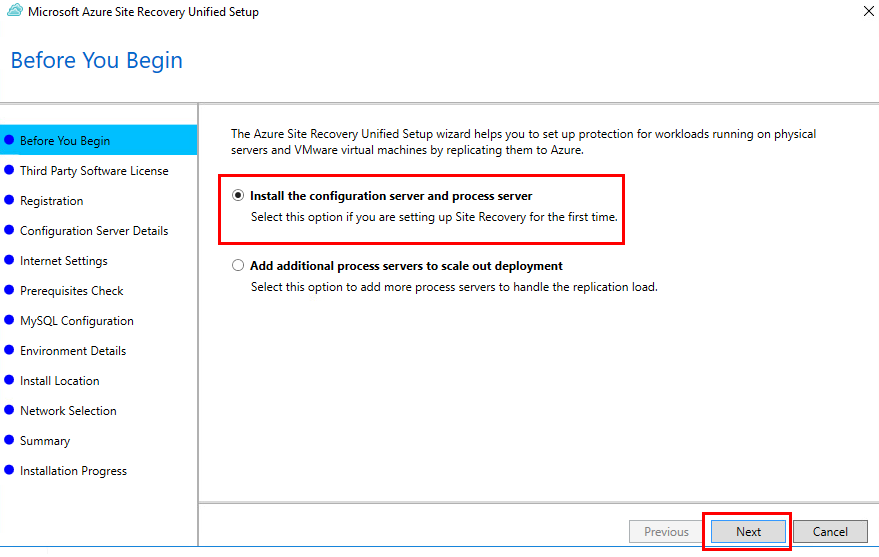
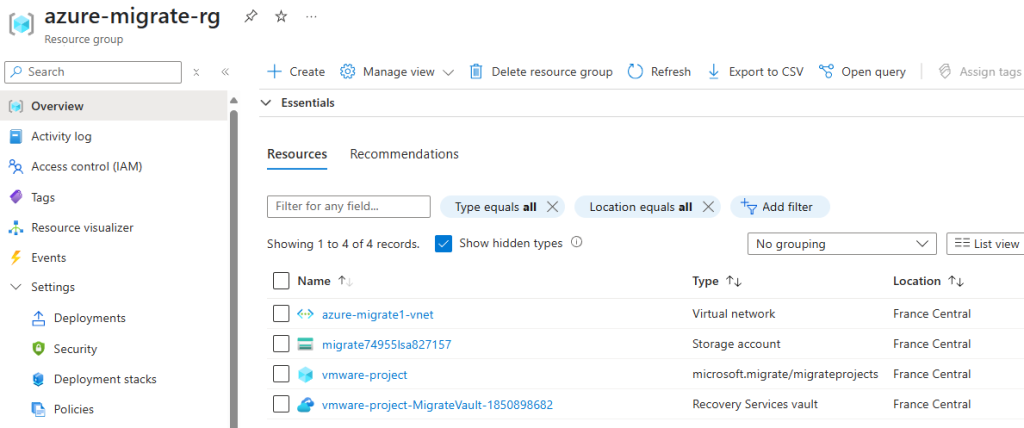
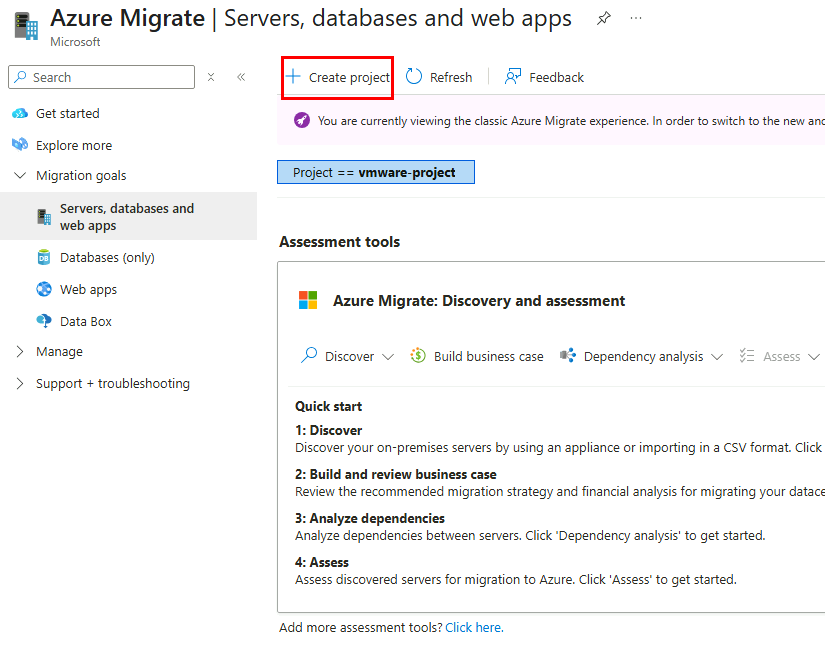
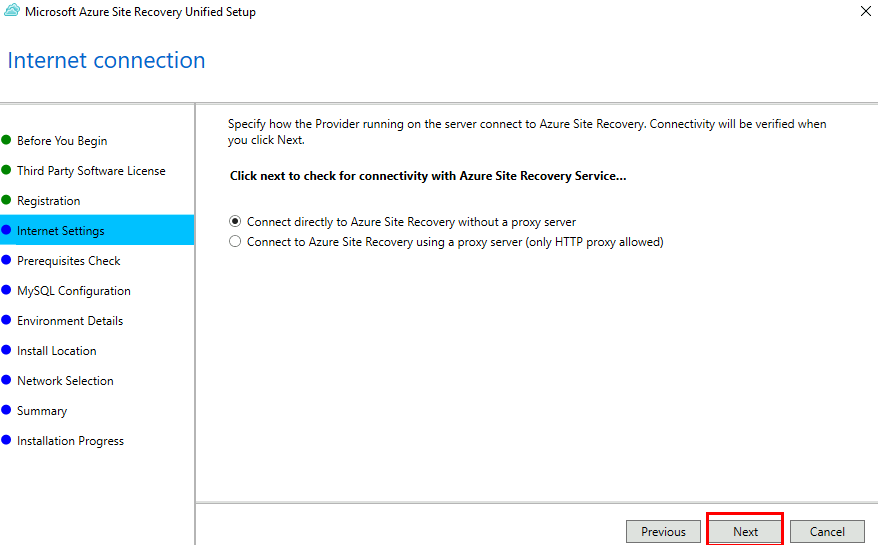
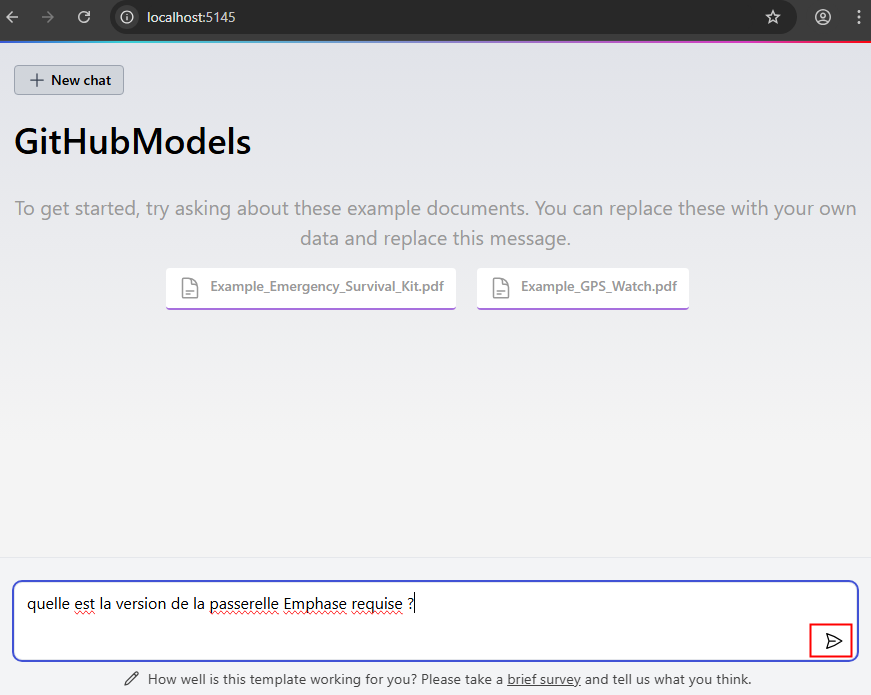
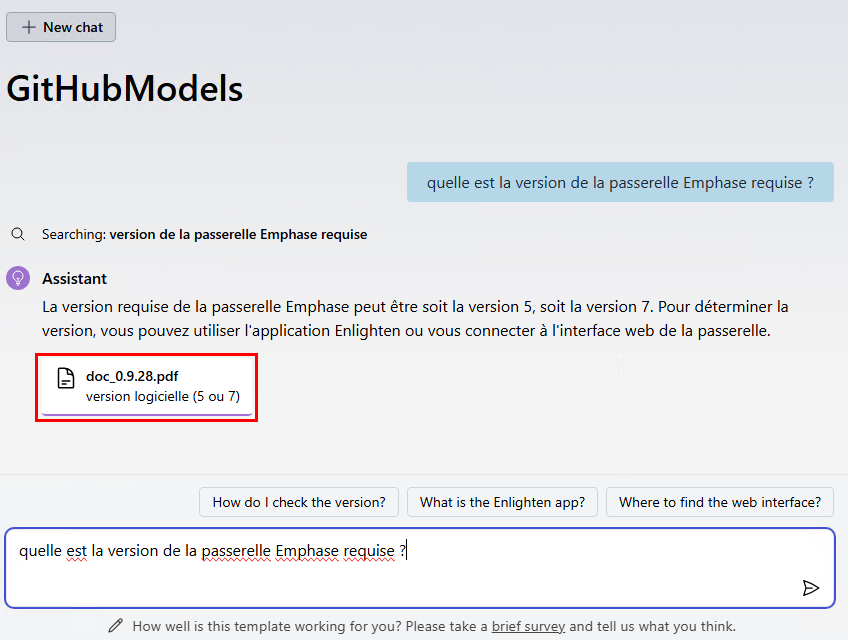
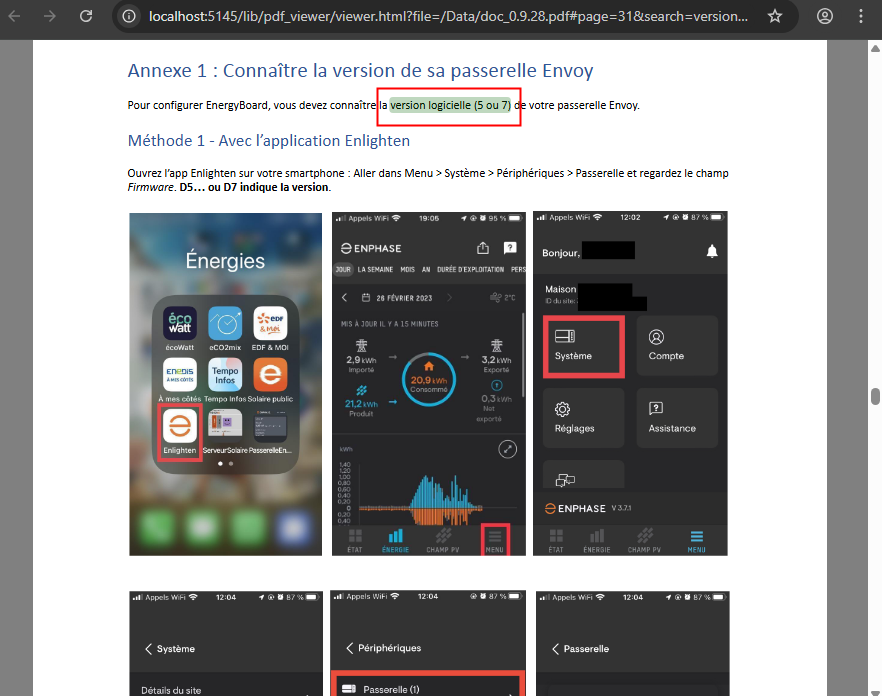
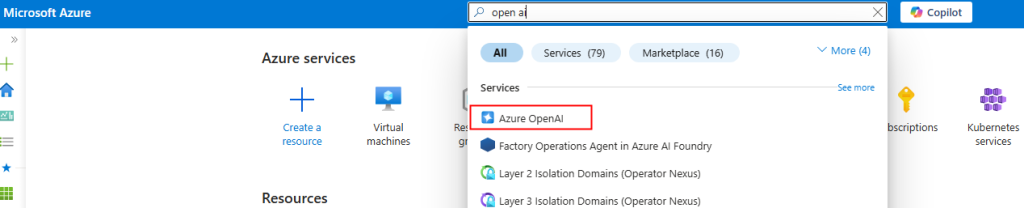
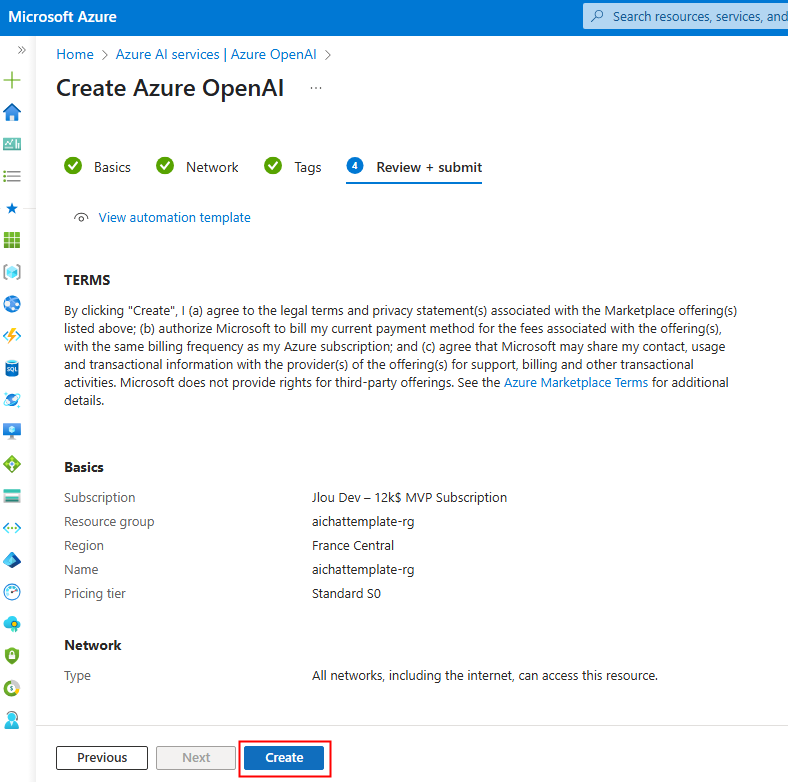
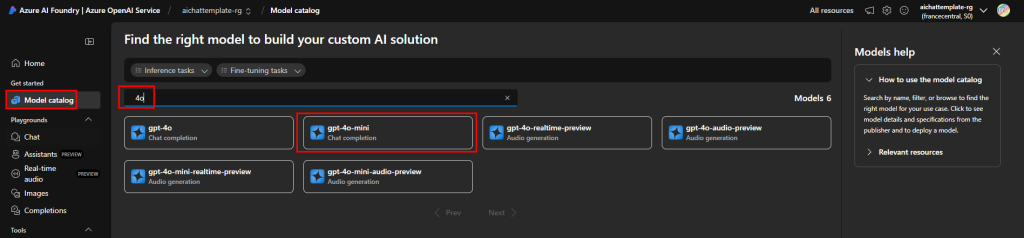
Depuis toujours, Azure offrait une “porte de sortie cachée” vers Internet à toutes les machines virtuelles déployées dans un réseau virtuel sans configuration explicite : le fameux Accès sortant par défaut (Default Outbound Access). En clair, si vous créiez une VM sans NAT Gateway, sans Équilibreur de charge, sans IP publique attachée… eh bien Azure vous donnait quand même un accès internet de secours via une IP publique éphémère. Mais tout cela change bientôt !

À partir du 30 septembre 2025, cette facilité disparaît pour tous les nouveaux réseaux virtuels. Les workloads qui comptaient dessus devront désormais passer par des méthodes explicites de sortie (NAT Gateway, Load Balancer SNAT, ou IP publique directe).
Pas d’inquiétude donc pour vos environnements déjà en place ! Ce changement ne concerne pas les réseaux virtuels déjà déployés avant cette date. Mais une modernisation de ces derniers est à envisager afin de les harmoniser avec les nouveaux réseaux virtuels dépourvus de l’Accès sortant par défaut.
Qu’est-ce que l’Accès sortant par défaut ?
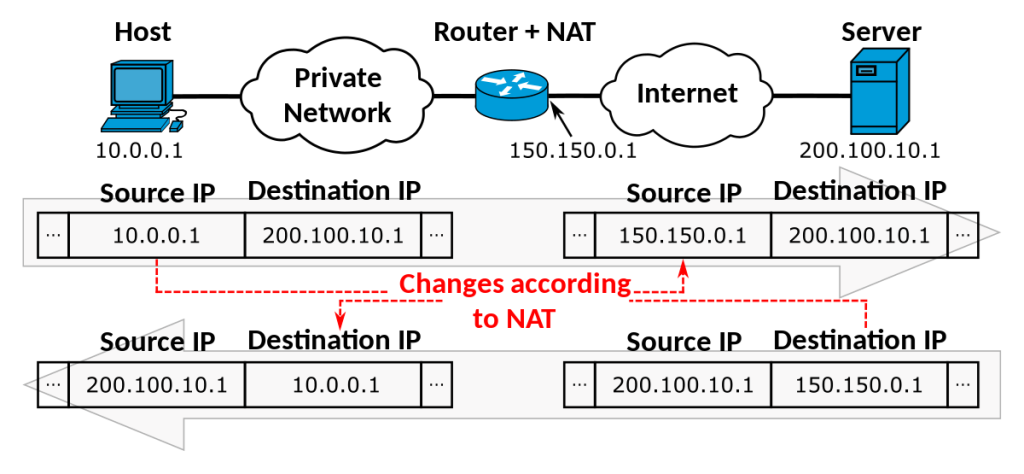
L’Accès sortant par défaut est une connectivité internet implicite que Microsoft Azure attribuait automatiquement aux machines virtuelles créées dans un réseau virtuel sans configuration explicite de sortie.
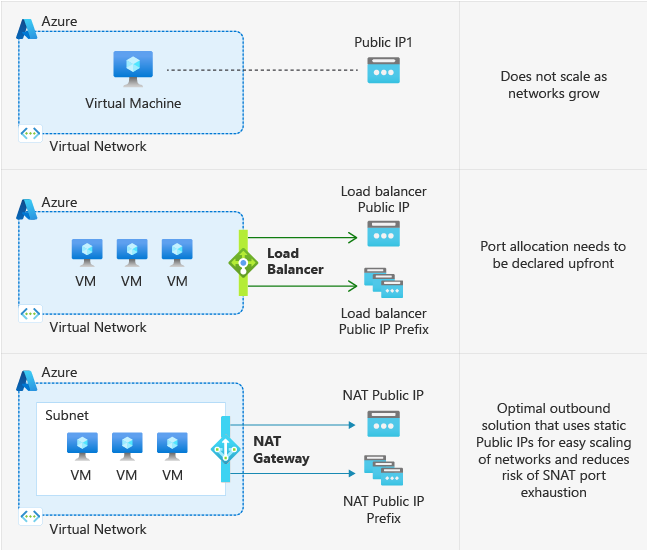
Dans Azure, lorsqu’une machine virtuelle (VM) est déployée dans un réseau virtuel sans méthode de connectivité sortante explicitement définie, une adresse IP publique sortante lui est automatiquement attribuée.
Cette adresse IP permet la connectivité sortante depuis les ressources vers Internet et vers d’autres points de terminaison publics au sein de Microsoft. Cet accès est appelé « accès sortant par défaut ».
Comment et quand l’accès sortant par défaut était-il utilisé ?
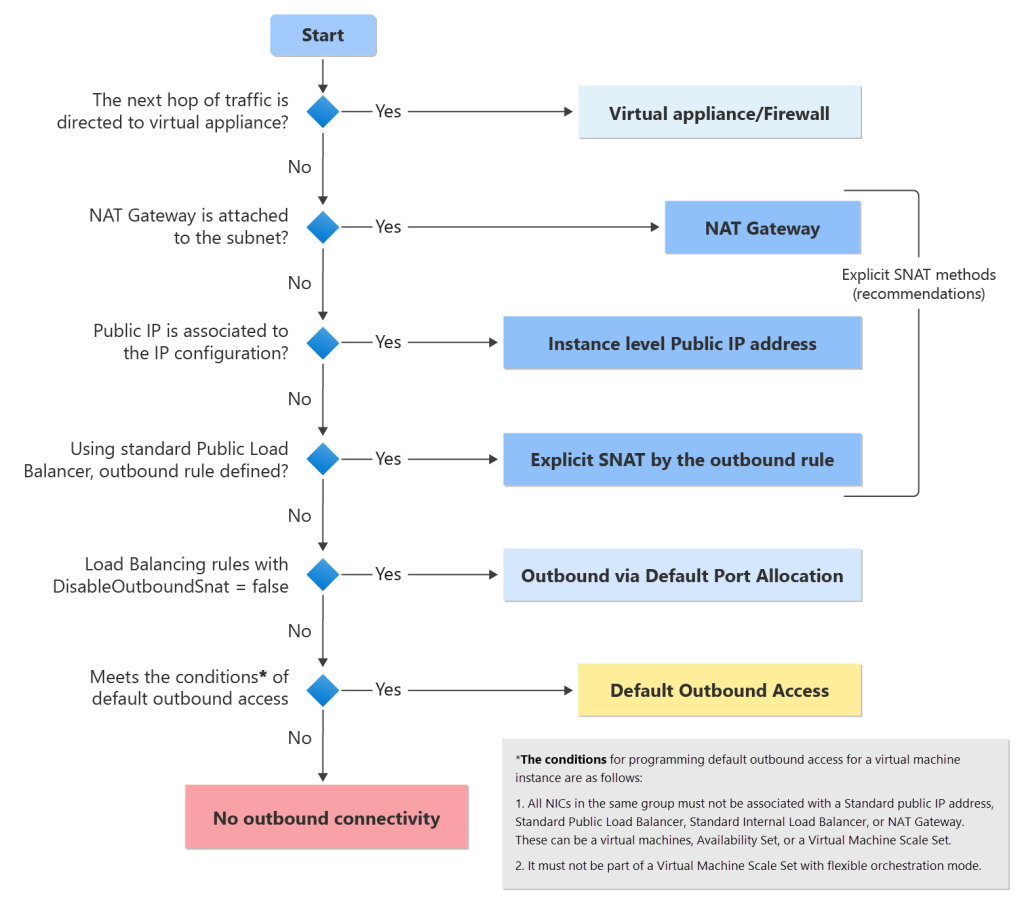
Microsoft décrit ici l’ordre de résolution de la connectivité sortante d’une VM dans Azure par plusieurs tests chaque par ordre de priorité :
- Firewall
- NAT Gateway
- IP publique
- Équilibreur de charge
- Accès sortant par défaut
- Équilibreur de charge
- IP publique
- NAT Gateway
L’accès sortant par défaut n’est donc qu’un dernier recours. Et après la fin septembre 2025, il disparaîtra pour les nouveaux réseaux virtuels, seules les méthodes explicites resteront.
Pourquoi Microsoft le retire ?
Microsoft met fin à ce mécanisme pour trois raisons principales :
- La première est la sécurité : cette IP “fantôme” ne figurait souvent dans aucun inventaire, ce qui compliquait la gestion et exposait à des risques.
- La deuxième est la stabilité : ces adresses publiques pouvaient changer sans prévenir, cassant certaines intégrations critiques avec des services externes.
- Enfin, la troisième est la conformité : dans un contexte d’audit, il était difficile de tracer les flux sortants d’une VM utilisant ce mode implicite. L’objectif est donc de forcer les clients à adopter des méthodes explicites et maîtrisées de connectivité.
Voici un exemple concret avec un Accès sortant par défaut :
Vous déployez une VM, elle se met à parler à internet avec une IP que vous ne connaissiez pas, qui peut changer sans prévenir, et qui n’apparaît pas dans vos inventaires de sécurité. C’était cela l’Accès sortant par défaut.
Dès la fin septembre, Microsoft dit stop à cette approche :
En supprimant cette facilité, Microsoft pousse à adopter des designs réseau clairs, contrôlables et audités. Malgré la contrainte en tant que telle, cela reste une excellente nouvelle pour la gouvernance cloud.
Qui est impacté ?
Tout le monde. Mais seuls les nouveaux réseaux virtuels créés après le 30 septembre 2025 seront concernés :
Après le 30 septembre 2025, les nouveaux réseaux virtuels exigeront par défaut des méthodes de connectivité sortante explicites au lieu d’avoir un repli vers la connectivité d’accès sortant par défaut.
Les réseaux existants continueront de fonctionner comme avant, mais Microsoft recommande déjà à tous les clients de migrer afin d’éviter les discordances entre les anciens et nouveaux réseaux virtuels :
Toutes les machines virtuelles (existantes ou nouvellement créées) dans les réseaux virtuels existants qui utilisent l’accès sortant par défaut continueront de fonctionner après cette modification. Cependant, nous vous recommandons vivement de passer à une méthode sortante explicite.
Même confirmation sur le site Learn de Microsoft :
Aucune modification n’est apportée aux réseaux virtuels existants. Cela signifie que les machines virtuelles existantes et les machines virtuelles nouvellement créées dans ces réseaux virtuels continuent de générer des adresses IP sortantes par défaut, à moins que les sous-réseaux ne soient modifiés manuellement pour devenir privés.
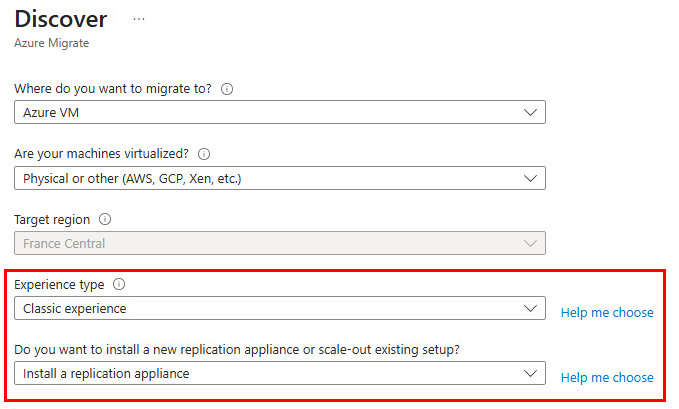
Quelles sont les alternatives recommandées ?
Afin de maintenir un accès internet à vos machines virtuelles, plusieurs services sont proposés par Microsoft selon vos besoins :
- La solution de référence est le NAT Gateway, qui offre une connectivité sortante hautement disponible, scalable et simple à gérer.
- Dans certains cas, on pourra également utiliser un Équilibreur de charge configuré avec des règles SNAT.
- Pour des scénarios plus ponctuels, il reste possible d’associer une IP publique directement à une VM, même si cela n’est pas conseillé pour des environnements critiques.
- Enfin, dans les architectures plus sécurisées, le trafic sortant peut être centralisé à travers un Azure Firewall, un proxy ou une appliance réseau virtuelle (NVA).
Comment préparer ma migration ?
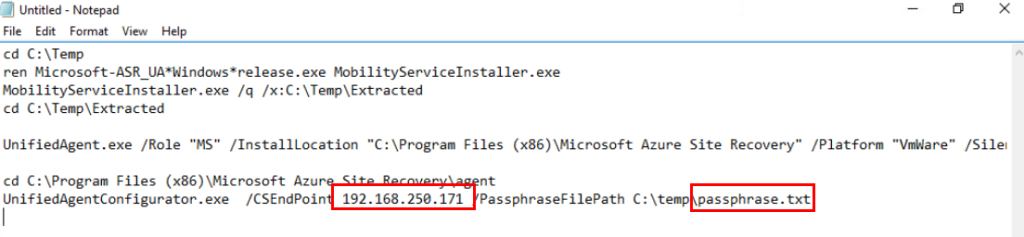
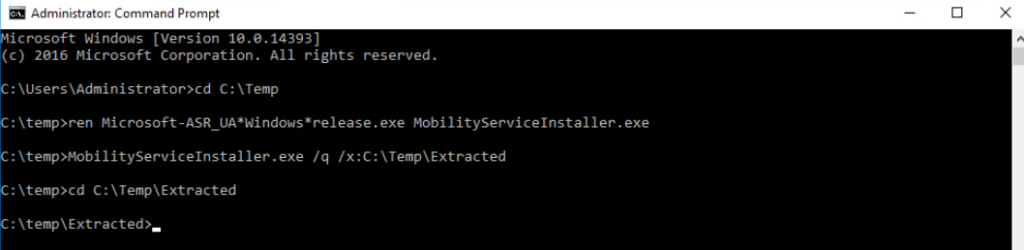
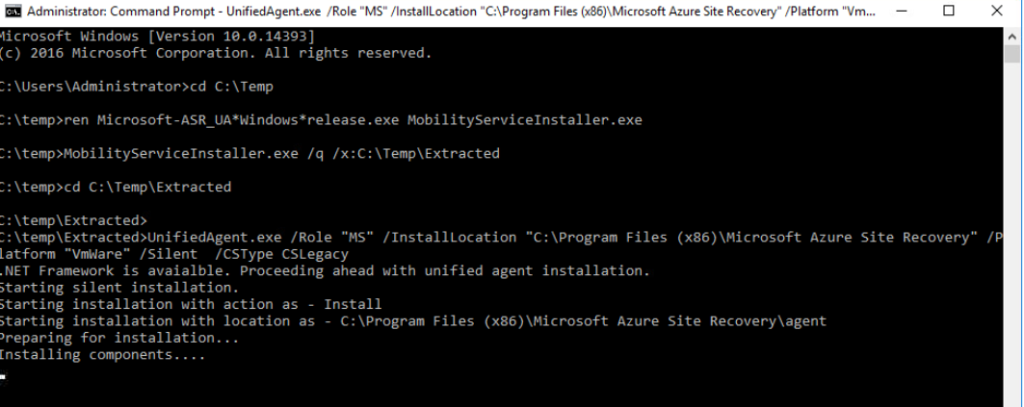
La première étape est d’inventorier vos workloads et d’identifier ceux qui reposent encore sur ce mode implicite d’Accès sortant par défaut.
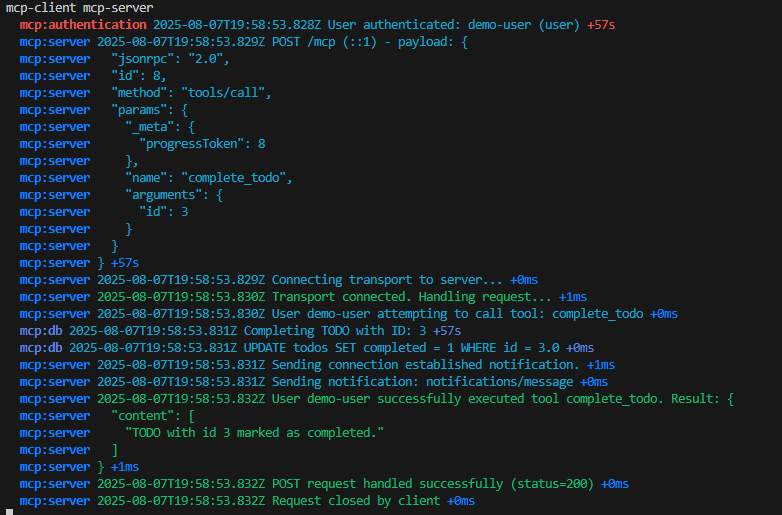
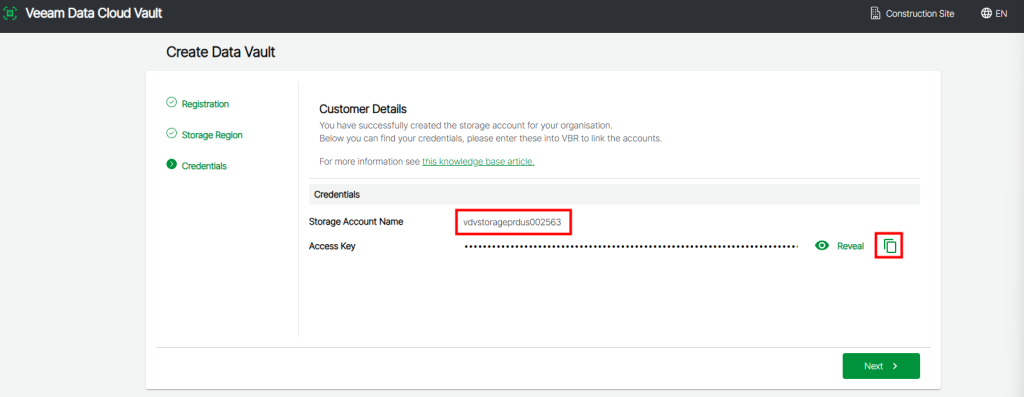
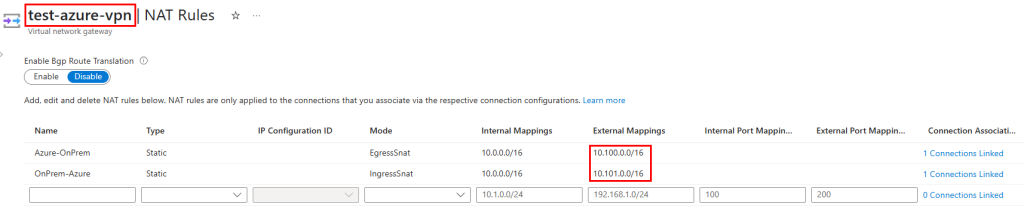
Ce script PowerShell parcourt toutes les souscriptions Azure et dresse, pour chaque réseau virtuels et sous-réseaux, l’état de l’option Accès sortant par défaut :
$results = New-Object System.Collections.Generic.List[object]
$subs = Get-AzSubscription -ErrorAction Stop
foreach ($sub in $subs) {
Set-AzContext -SubscriptionId $sub.Id -Tenant $sub.TenantId | Out-Null
$vnets = Get-AzVirtualNetwork -ErrorAction SilentlyContinue
foreach ($vnet in $vnets) {
foreach ($subnet in $vnet.Subnets) {
$hasProp = $subnet.PSObject.Properties.Name -contains 'DefaultOutboundAccess'
$raw = if ($hasProp) { $subnet.DefaultOutboundAccess } else { $null }
$status = if ($raw -eq $false) { 'Disabled' } else { 'Enabled' }
$results.Add([PSCustomObject]@{
SubscriptionName = $sub.Name
SubscriptionId = $sub.Id
ResourceGroup = $vnet.ResourceGroupName
VNet = $vnet.Name
Region = $vnet.Location
Subnet = $subnet.Name
DefaultOutbound = $status
}) | Out-Null
}
}
}
$results |
Sort-Object SubscriptionName, ResourceGroup, VNet, Subnet |
Format-Table -AutoSize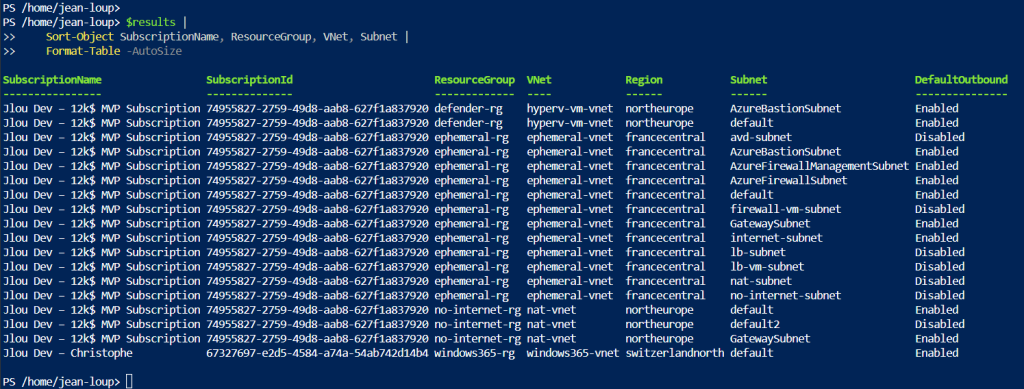
Ensuite, choisissez une stratégie adaptée :
- Associez une passerelle NAT
- Associez un équilibreur de charge
- Associez une adresse IP publique
- Ajoutez un pare-feu
Puis, testez ensuite vos flux réseau, notamment tout ce qui dépend de l’accès à Internet : mise à jour, activation Windows, appels API externes, DNS.
Quelles sont les limitations des subnets privés ?
Dans un sous-réseau privé entièrement fermé à Internet, certaines contraintes importantes impactent la bonne marche des machines virtuelles.
Plusieurs fonctionnalités essentielles demandent de mettre en place obligatoirement une méthode explicite de connectivité sortante.
- Impossibilité d’utiliser les services Microsoft 365
- Impossibilité d’activer le système d’exploitation
- Impossibilité de mettre à jour le système d’exploitation via Windows Update
- Impossibilité d’associer une machine virtuelle à Azure Virtual Desktop
- Les routes configurées avec un next hop de type Internet deviennent inopérantes
Note : Les sous-réseaux privés ne s’appliquent pas non plus aux sous-réseaux délégués ou gérés utilisés par des services PaaS. Dans ces scénarios, c’est le service lui-même (par exemple Azure SQL, App Service, etc.) qui gère sa propre connectivité sortante.
Puis-je déjà désactiver l’Accès sortant par défaut avant septembre 2025 ?
Oui, il est déjà possible de désactiver ce mécanisme dans vos réseaux virtuels pour anticiper la transition.

Cela permet de vérifier vos workloads dans des conditions proches de ce qui deviendra la norme à partir de septembre 2025 et d’éviter les mauvaises surprises le jour où le support sera officiellement retiré.
Important : Il est nécessaire d’arrêter/désallouer les machines virtuelles concernées dans un sous-réseau pour que les modifications de l’Accès sortant par défaut soient prises en compte.
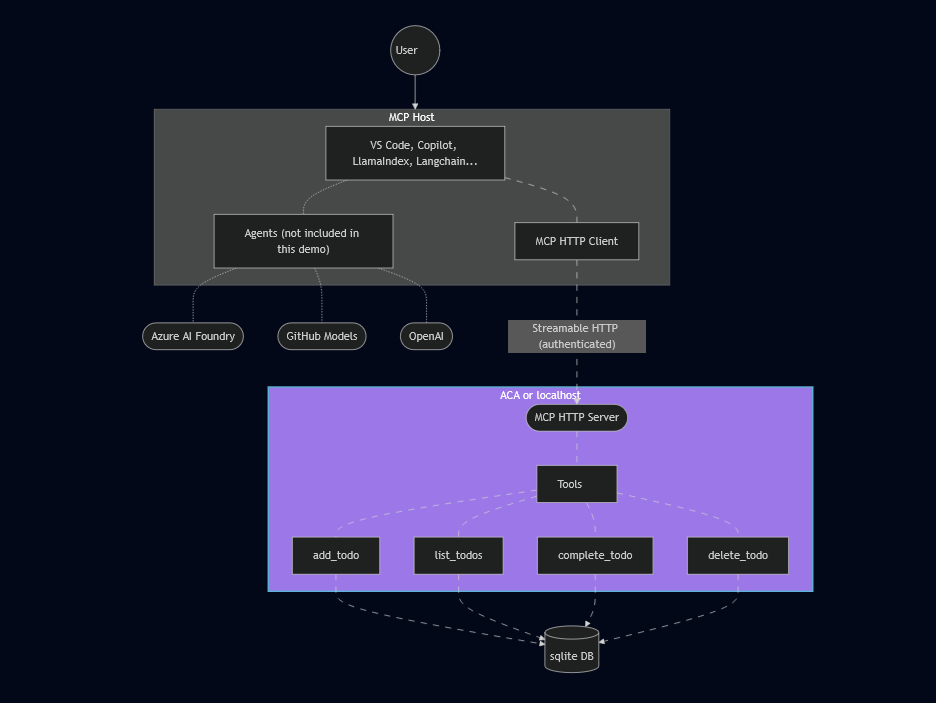
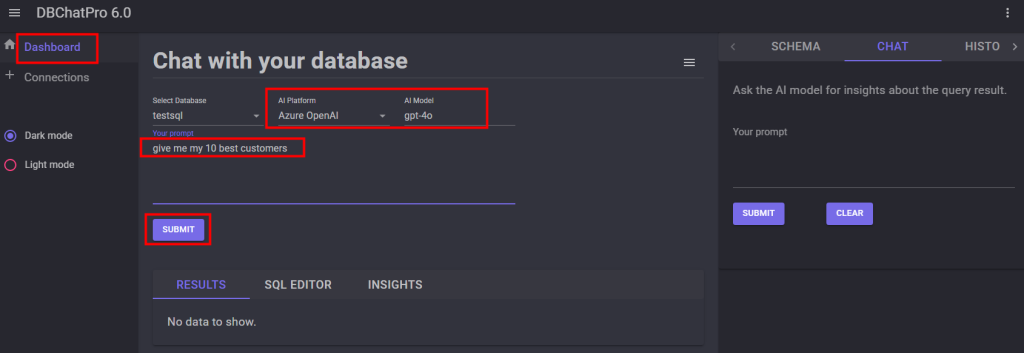
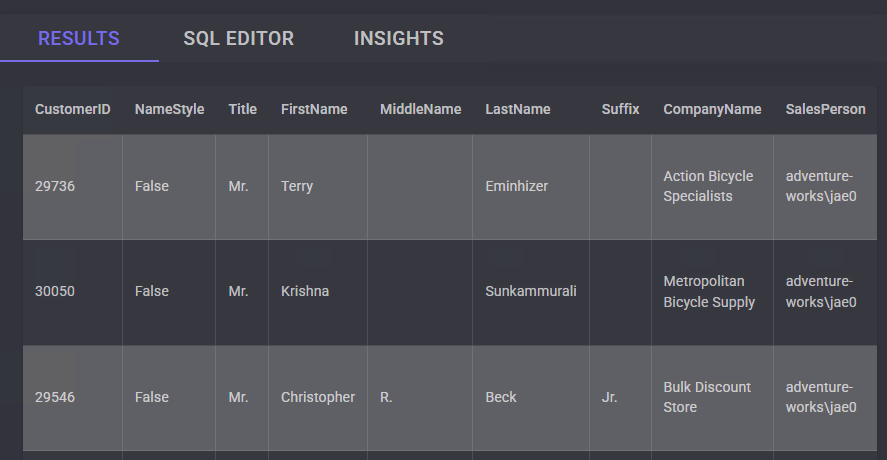
Une fois ces choses dites, je vous propose de tester cela depuis un environnement de démonstration afin de voir ce qu’il est actuellement possible de faire ou de ne pas faire de nôtre côté :
- Etape 0 – Rappel des prérequis
- Test I – Connexion internet depuis un sous-réseau non privé
- Test II – Connexion internet depuis un sous-réseau privé
- Test III – Connexion Azure Virtual Desktop depuis un sous-réseau privé
- Test IV – Connexion internet avec une adresse IP publique
- Test V – Connexion internet avec Azure NAT Gateway
- Test VI – Connexion internet avec Azure Firewall
- Test VII – Connexion internet avec Azure Load Balancer
Maintenant, il ne nous reste plus qu’à tester tout cela 😎
Etape 0 – Rappel des prérequis :
Pour réaliser cet exercice, il vous faudra disposer de :
- Un abonnement Azure valide
- Un tenant Microsoft
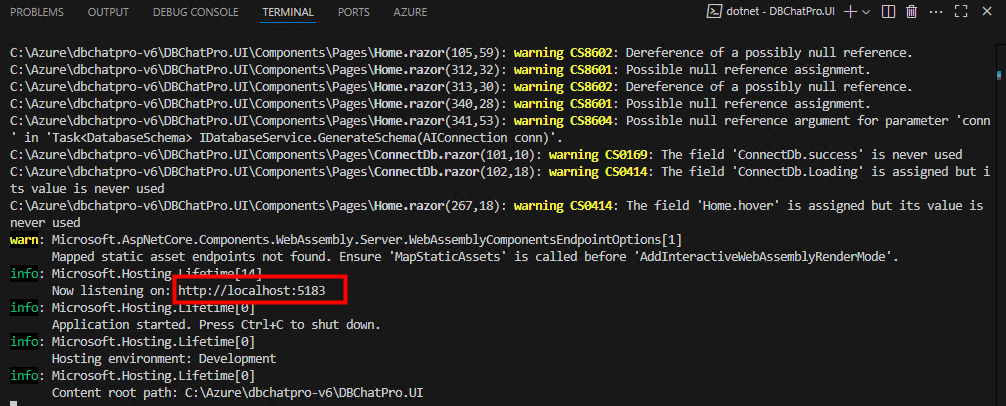
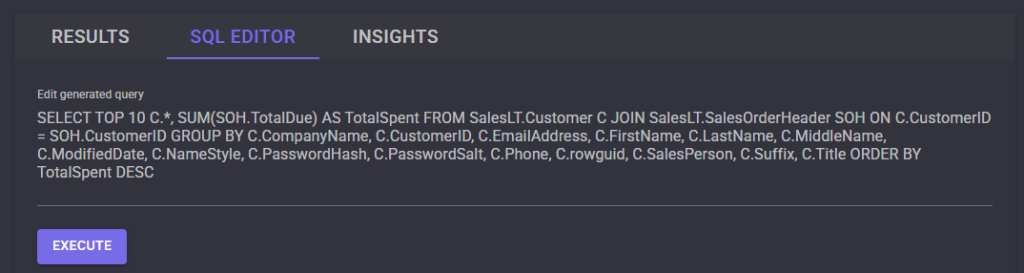
Commençons par tester la connectivité à internet depuis un réseau Azure créé avant septembre 2025.
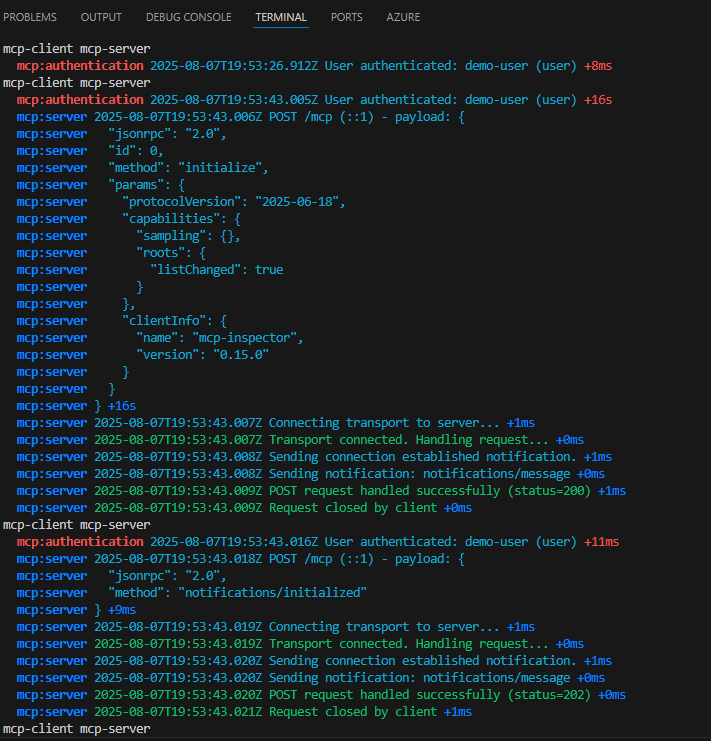
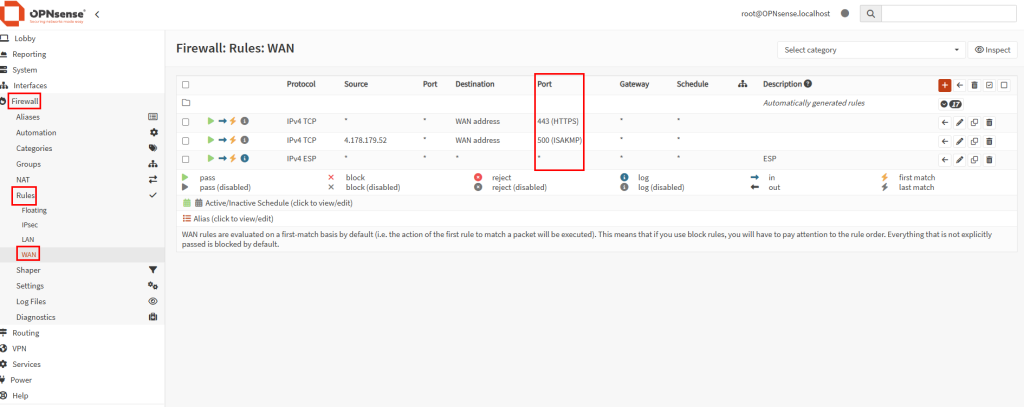
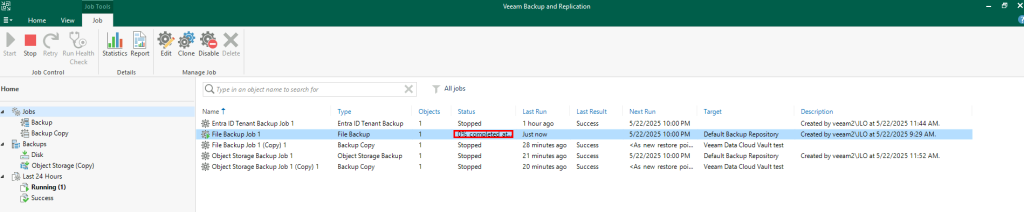
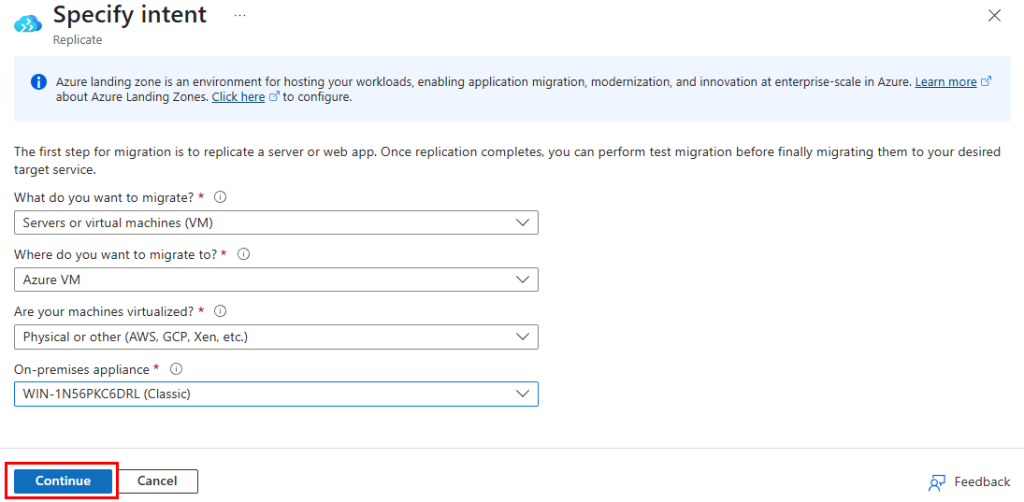
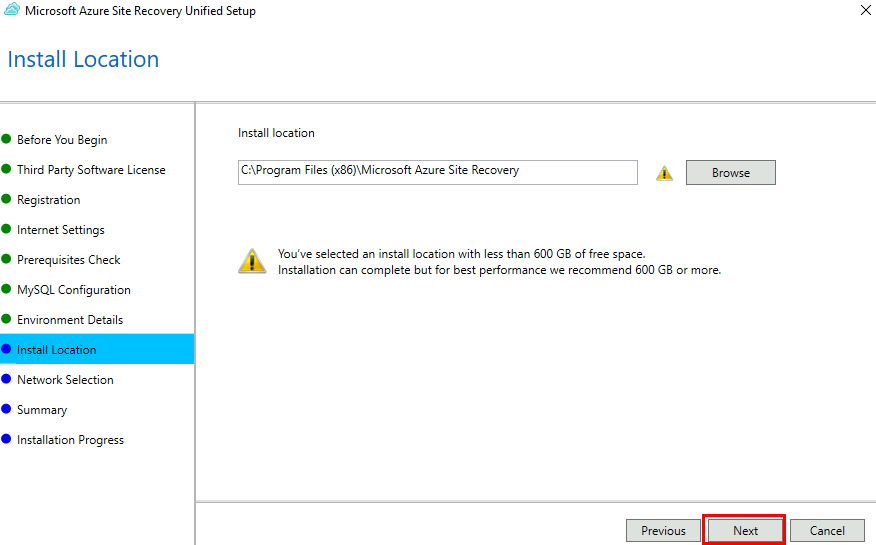
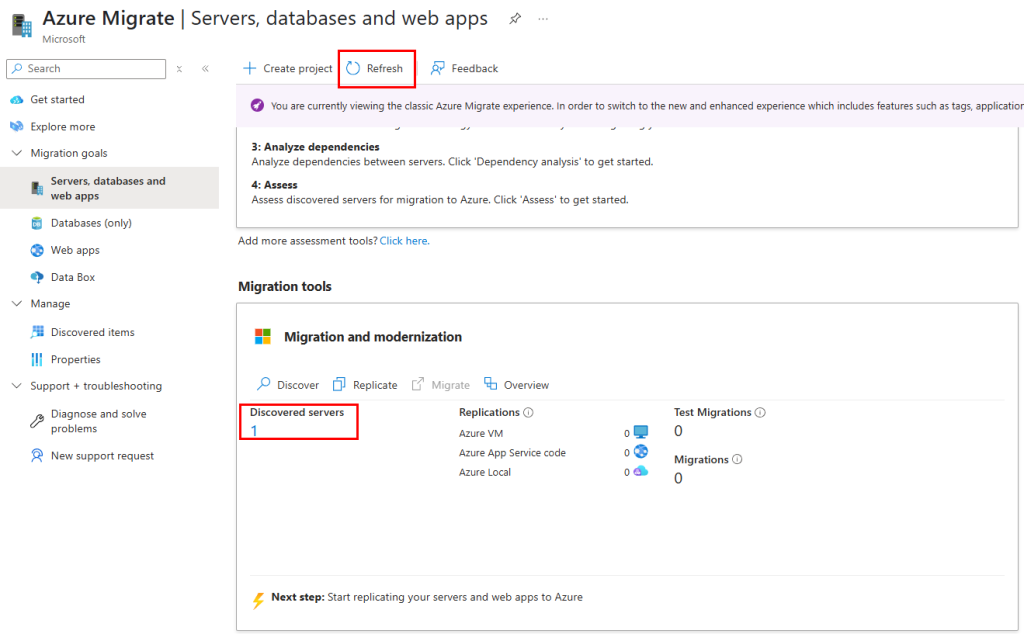
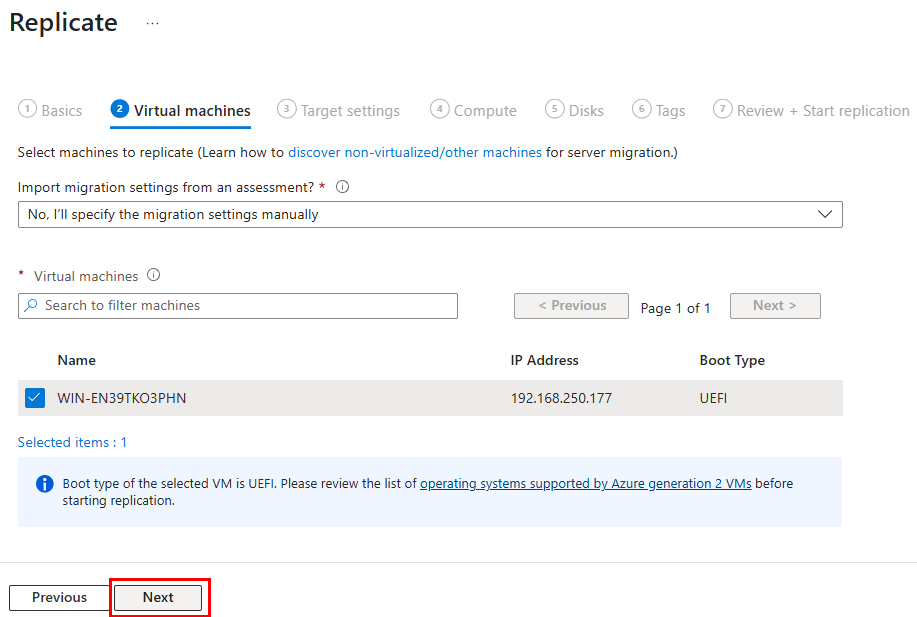
Test I – Connexion internet depuis un sous-réseau non privé :
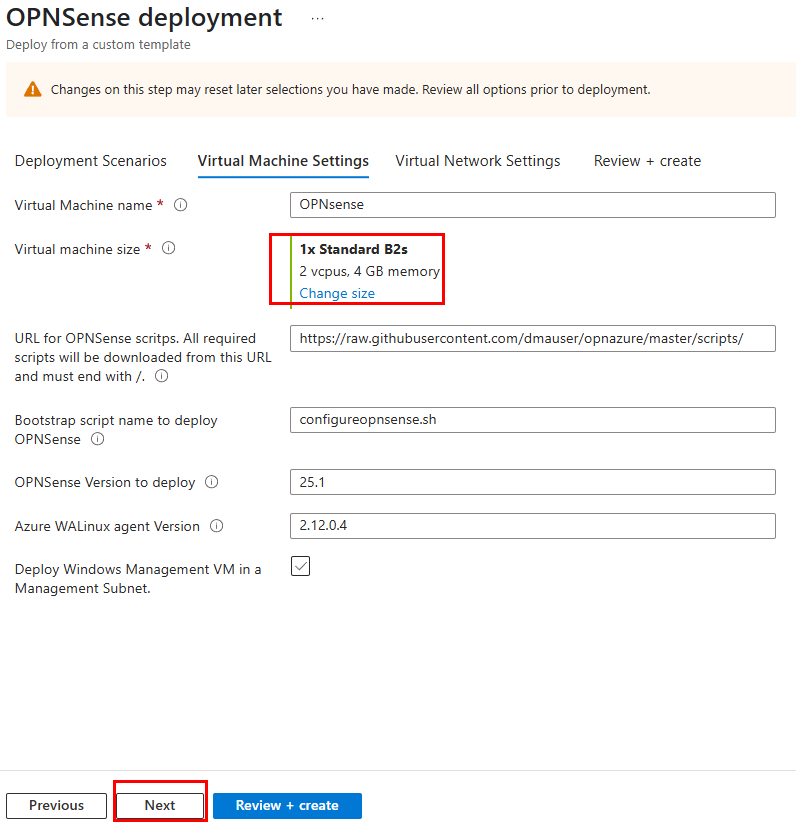
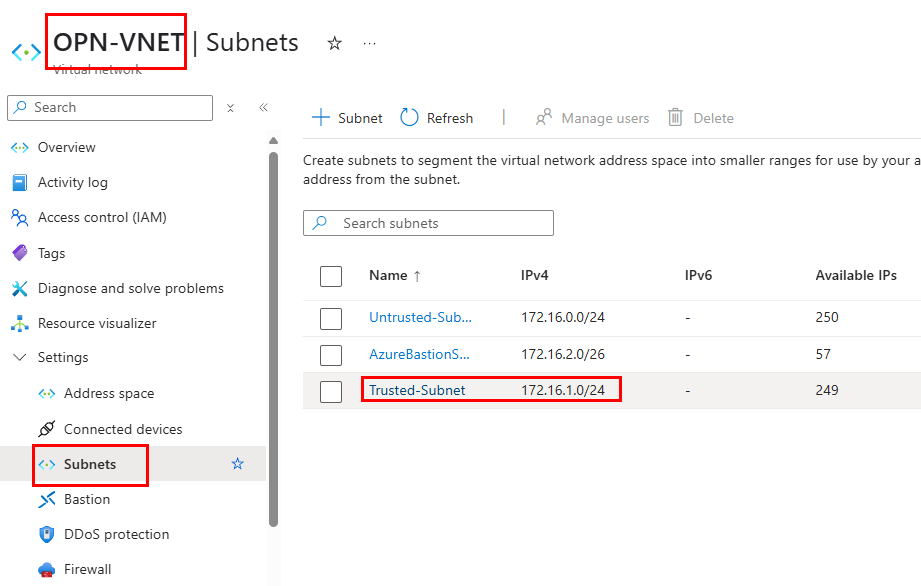
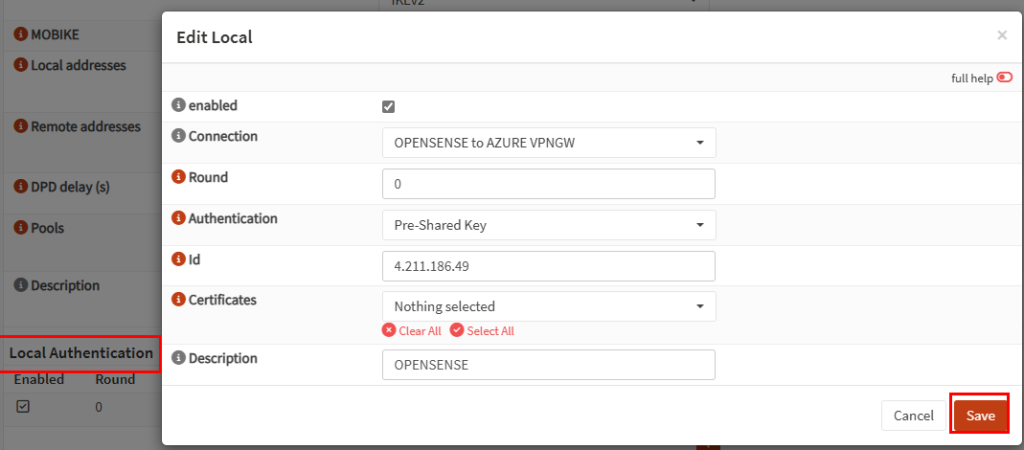
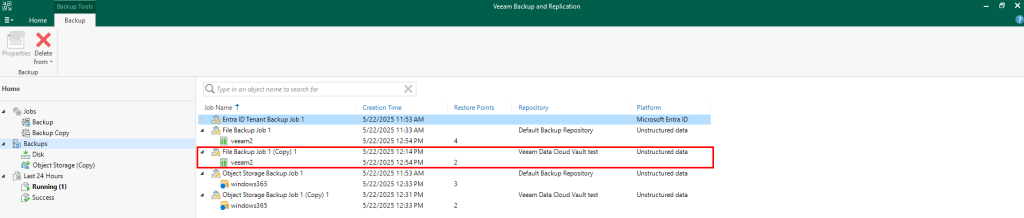
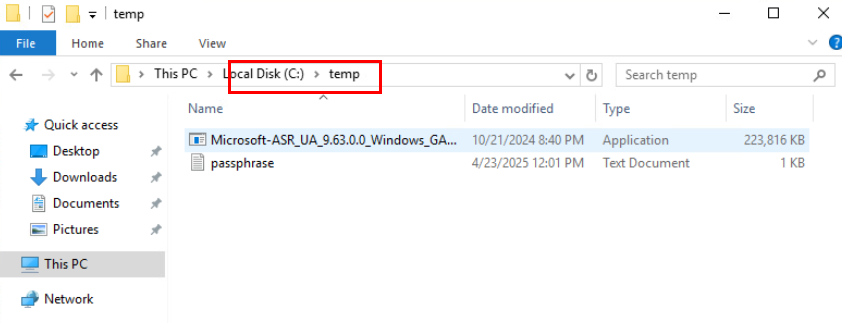
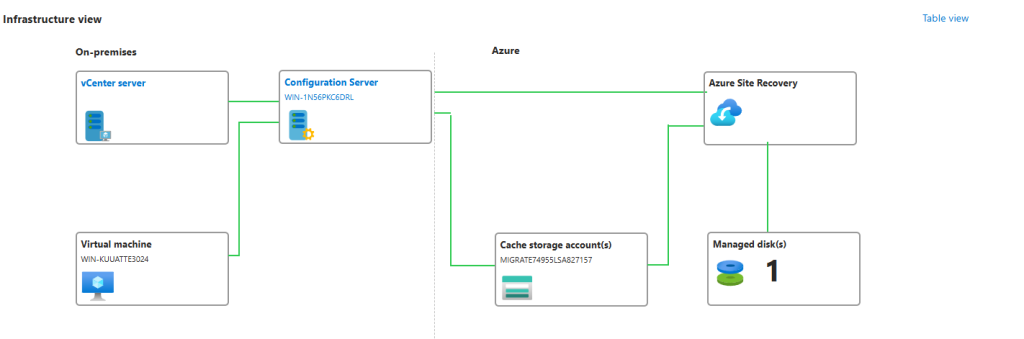
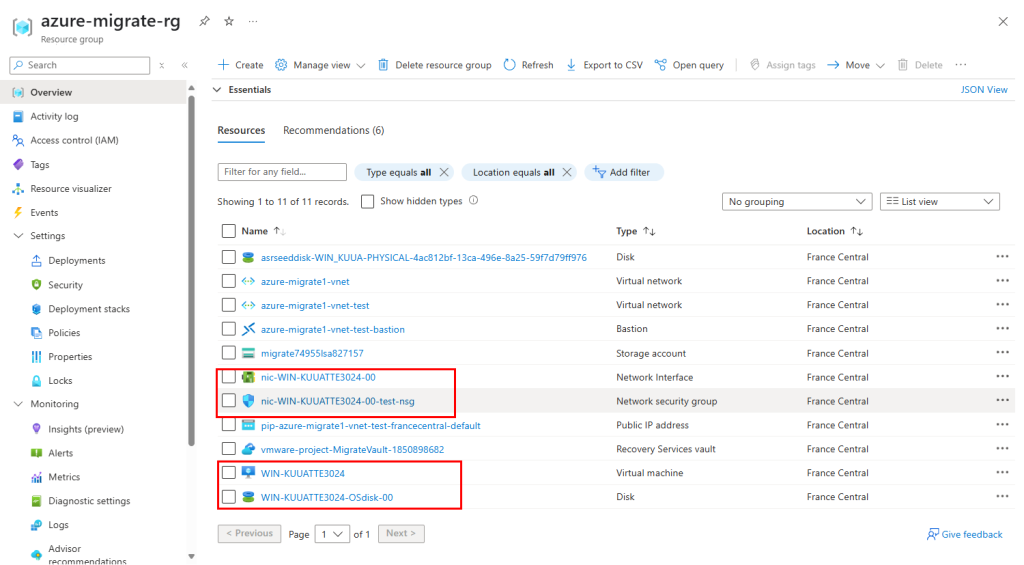
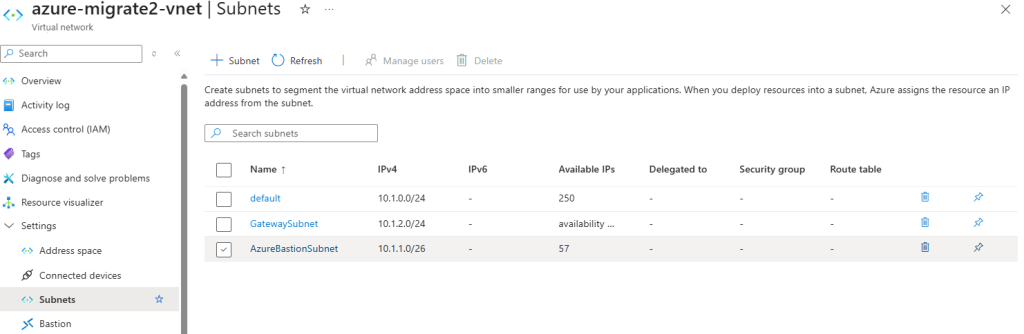
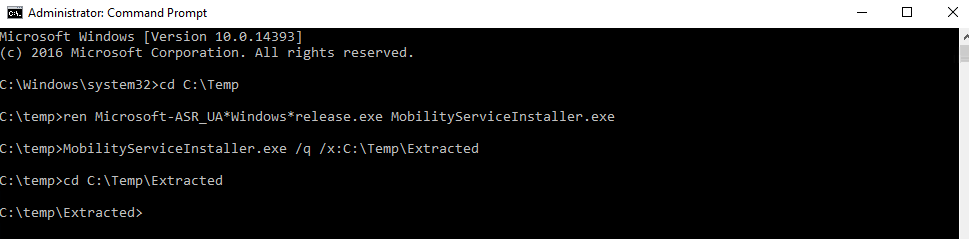
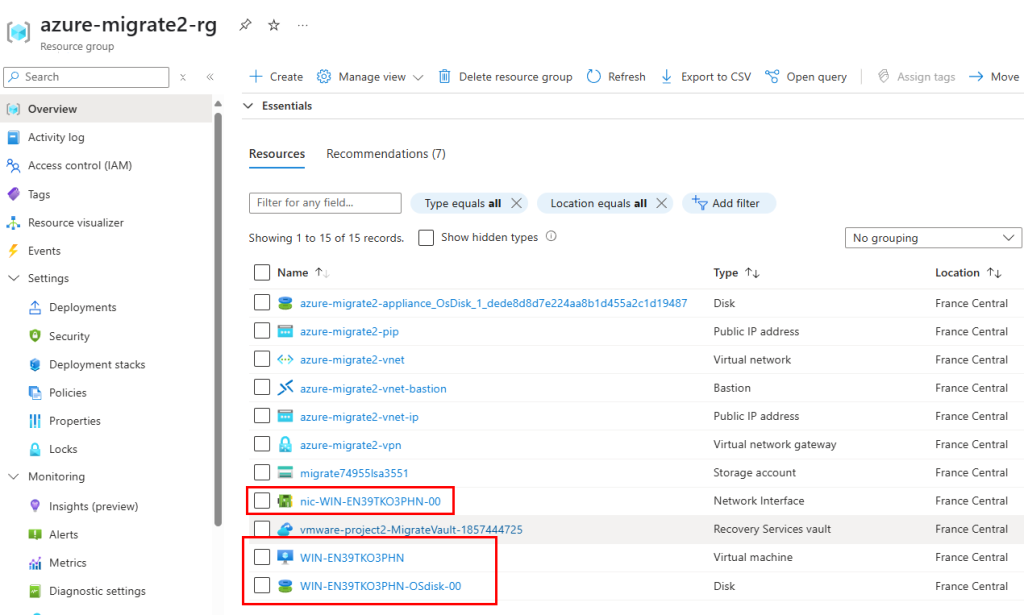
Dans un réseau virtuel Azure déjà créé, j’ai commencé par créer un premier sous-réseau non privé :
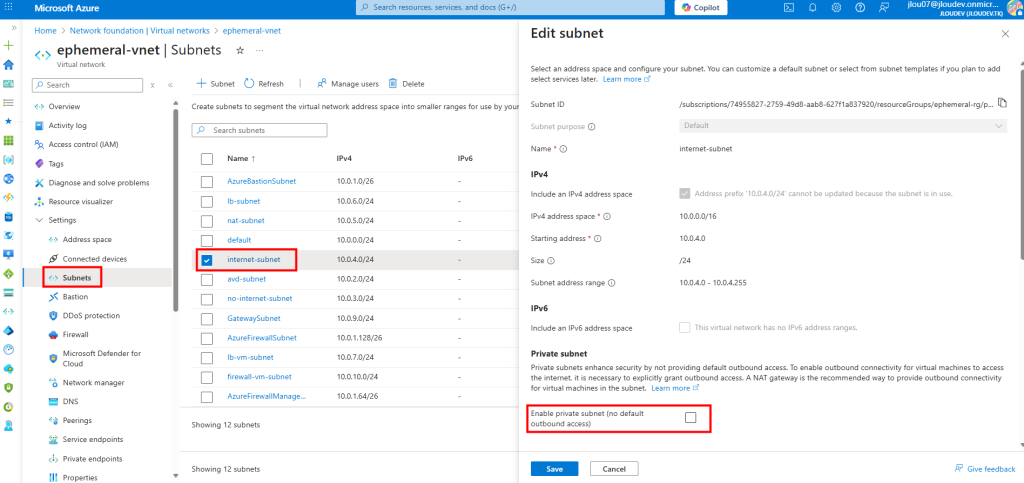
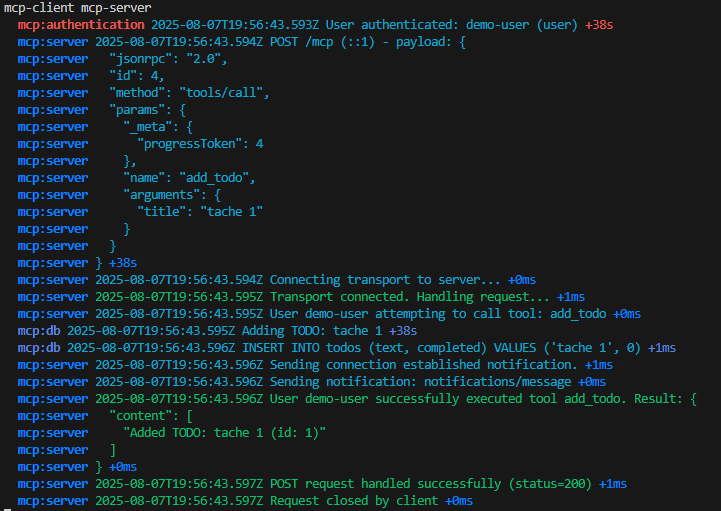
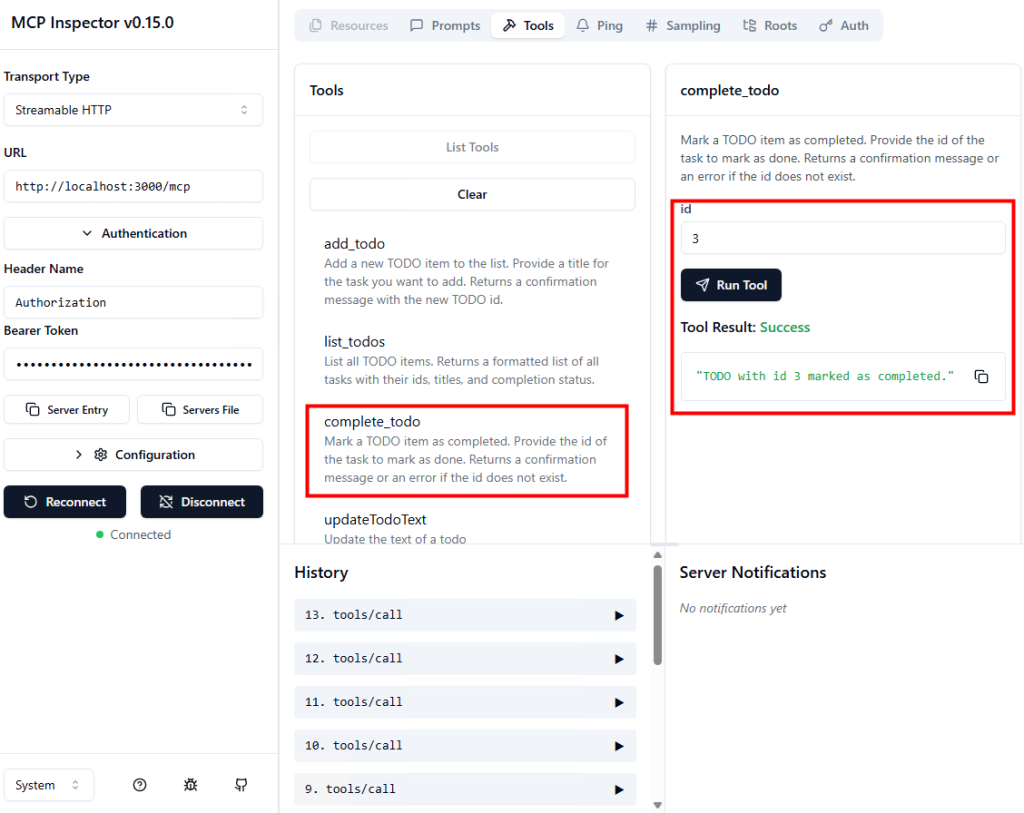
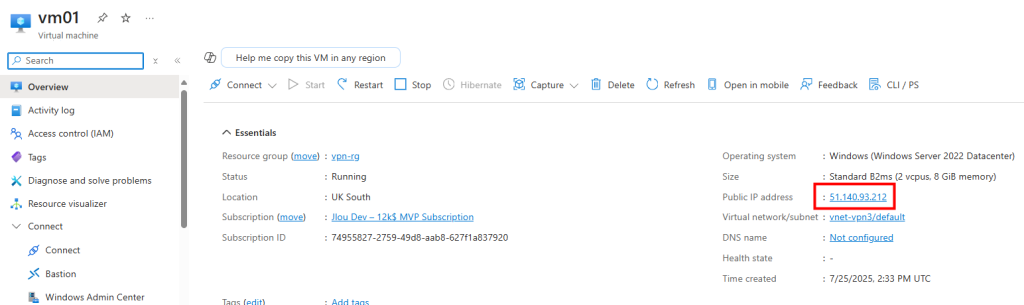
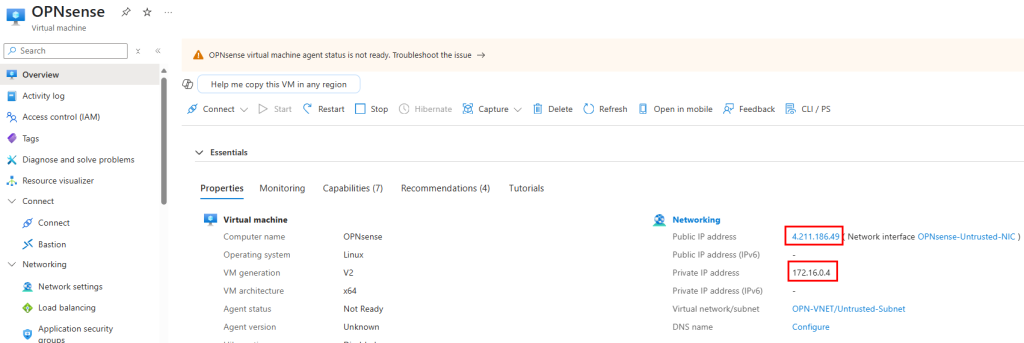
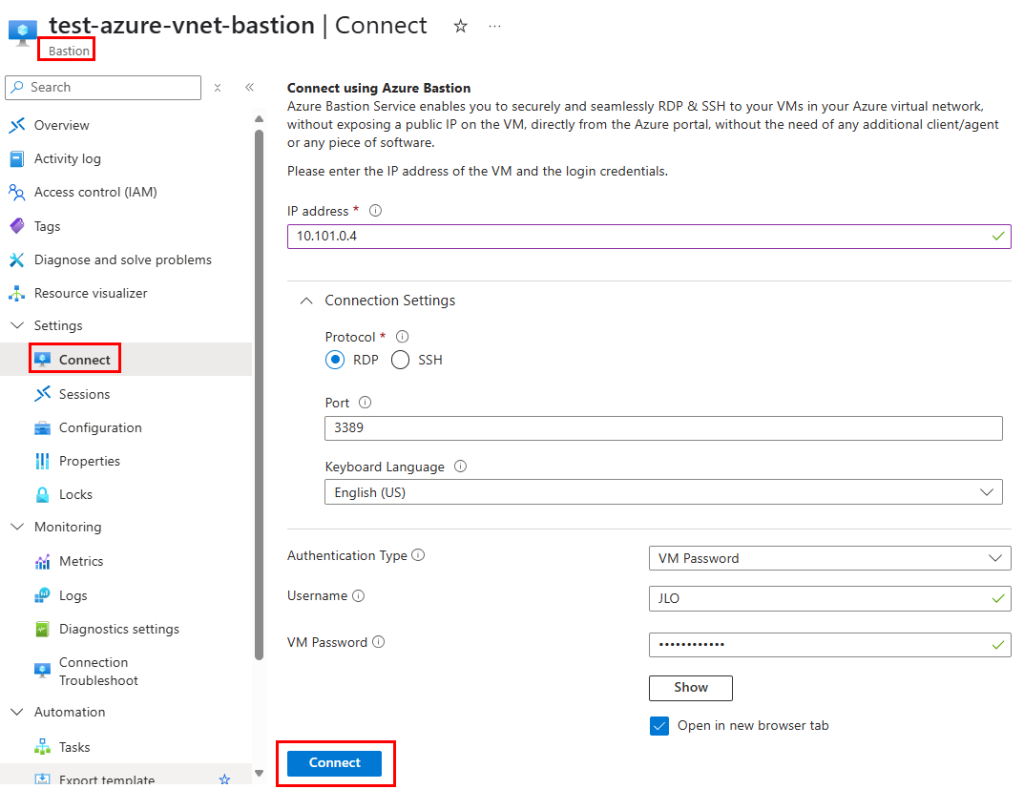
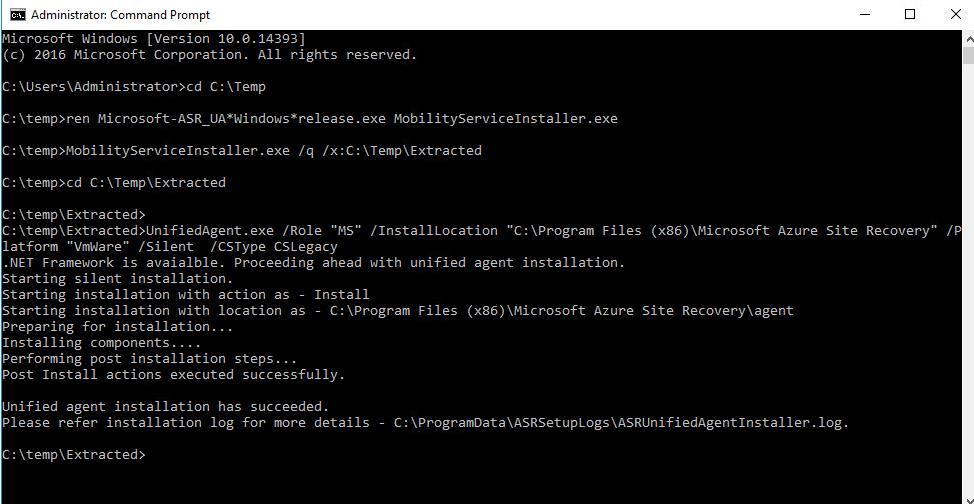
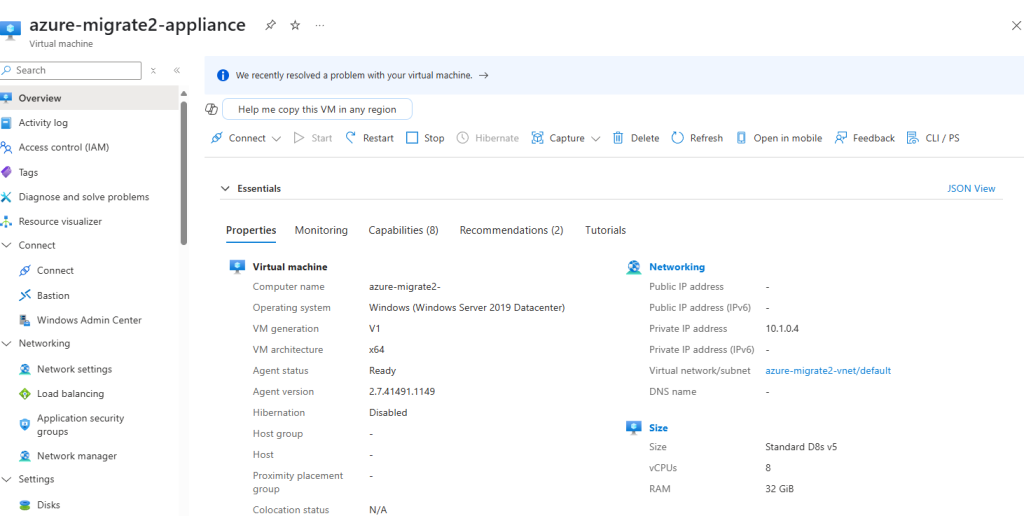
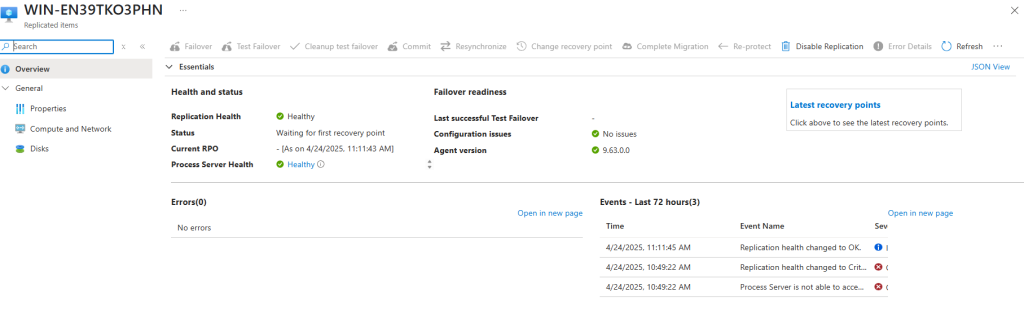
J’ai crée une machine virtuelle sans adresse IP publique associée :
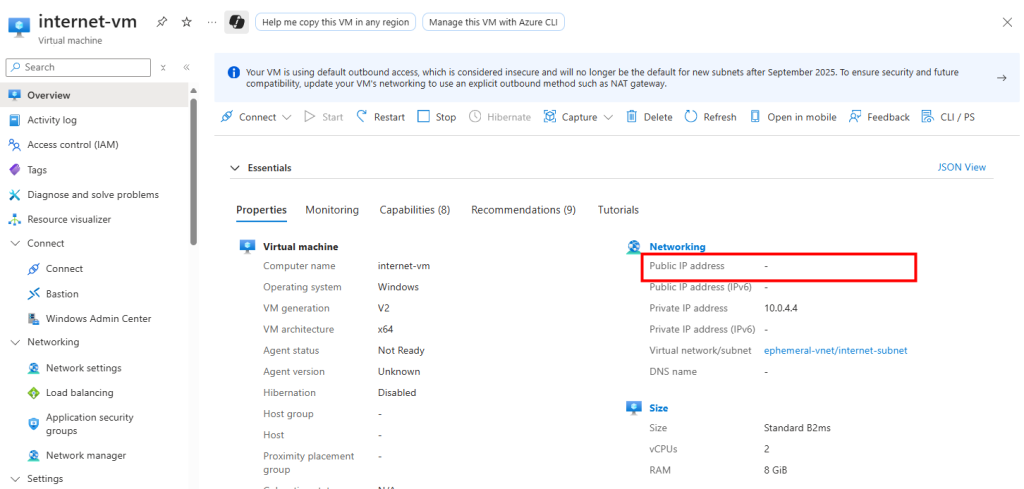
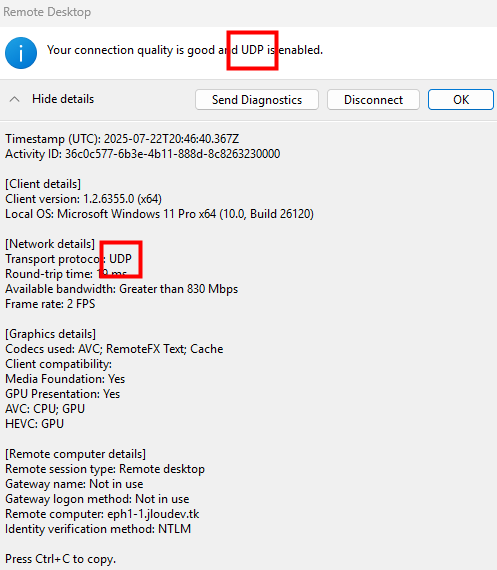
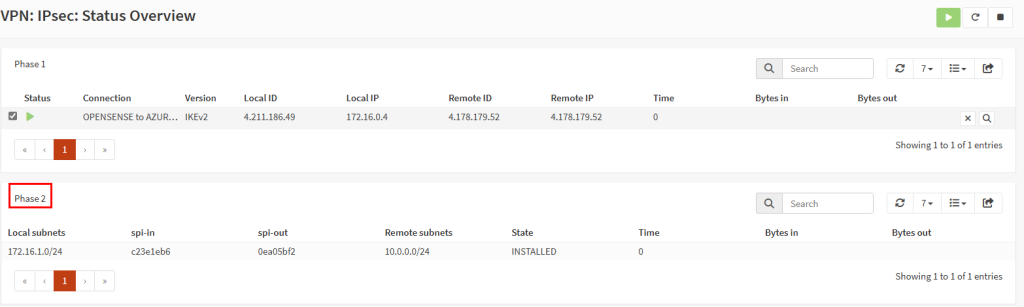
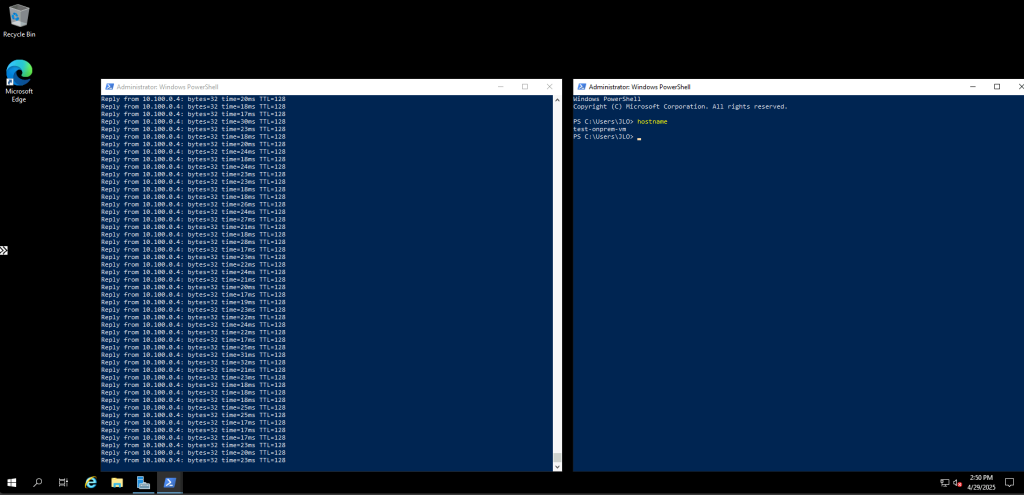
Une fois la VM démarrée, la machine obtient quand même un accès Internet sortant :

Et OneDrive se configure sans problème :
Tout fonctionne comme cela à toujours fonctionné. Passons maintenant à un test reposant sur un sous-réseau virtuel cette fois privé.
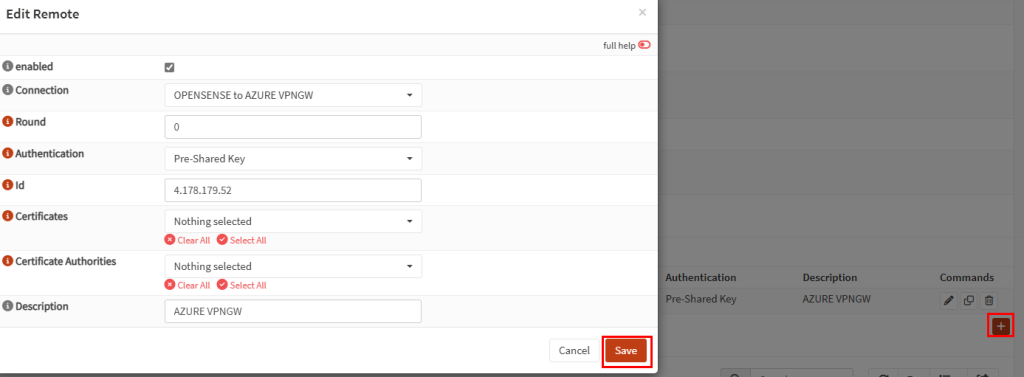
Test II – Connexion internet depuis un sous-réseau privé :
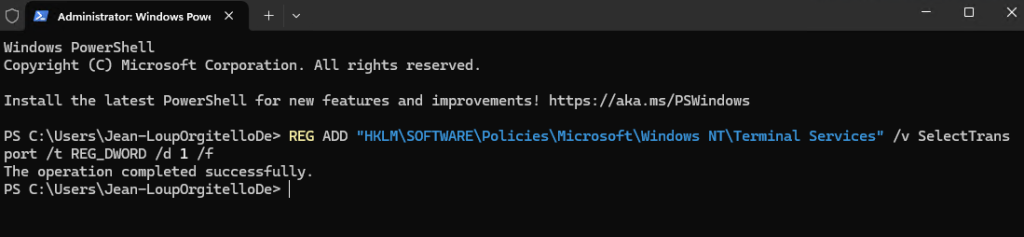
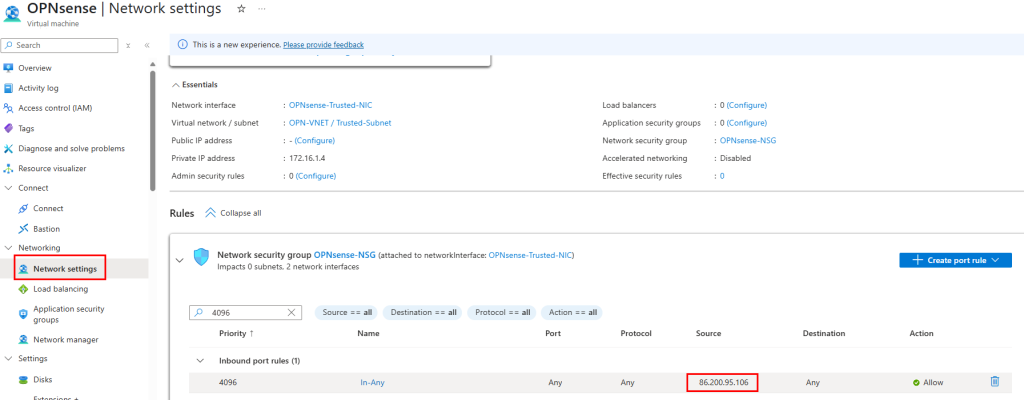
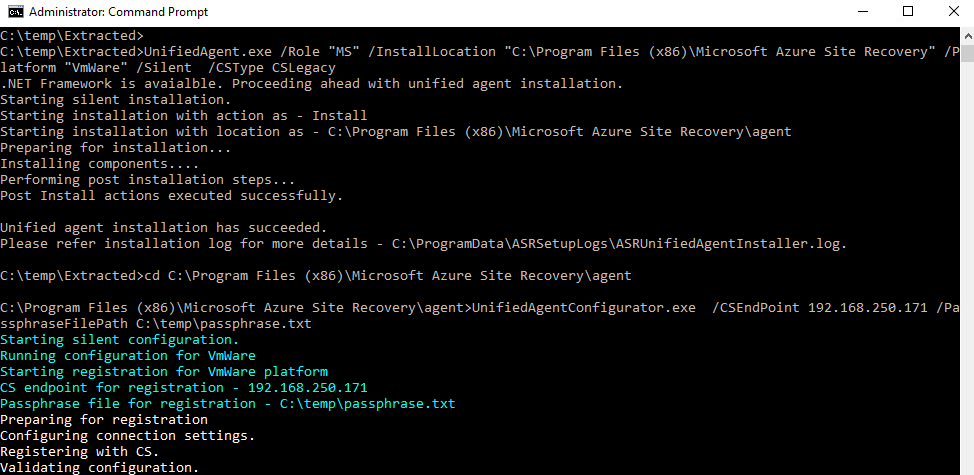
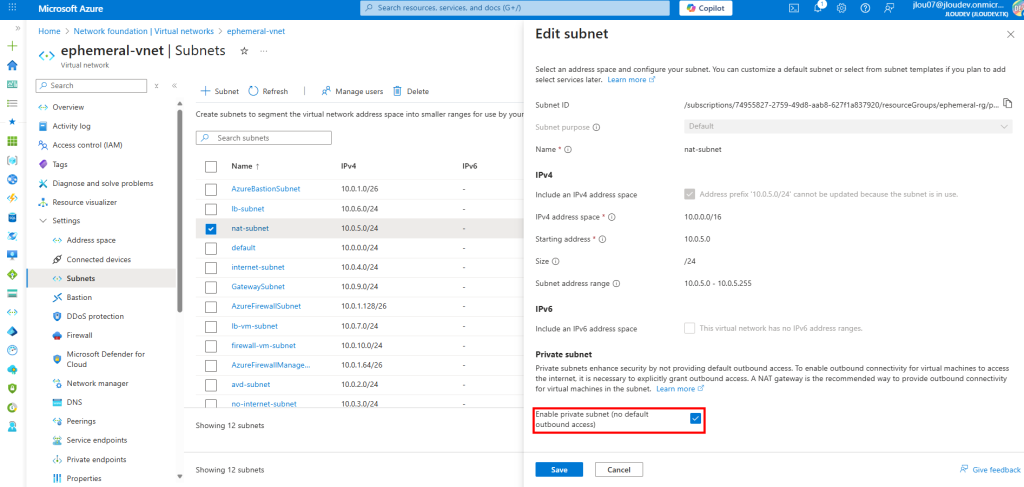
Sur ce même réseau virtuel, j’ai crée un second sous-réseau, avec l’option Private subnet cochée :
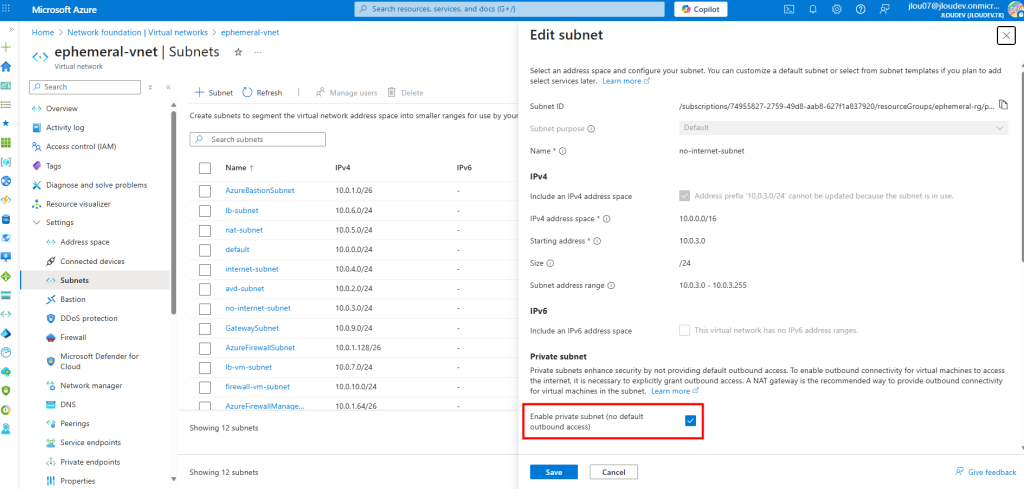
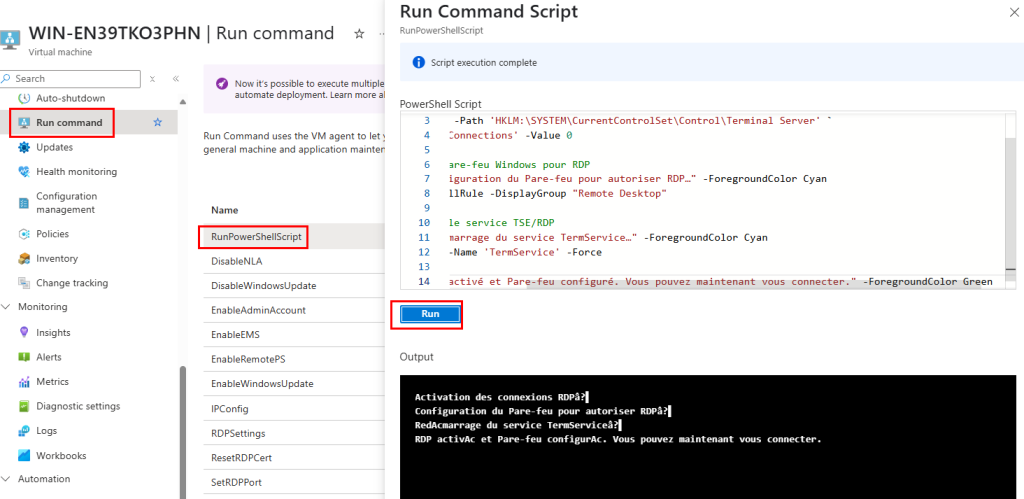
Une fois connecté à la machine virtuelle, dans les paramétrages Windows, l’état du réseau indique qu’il n’y a plus d’accès Internet :
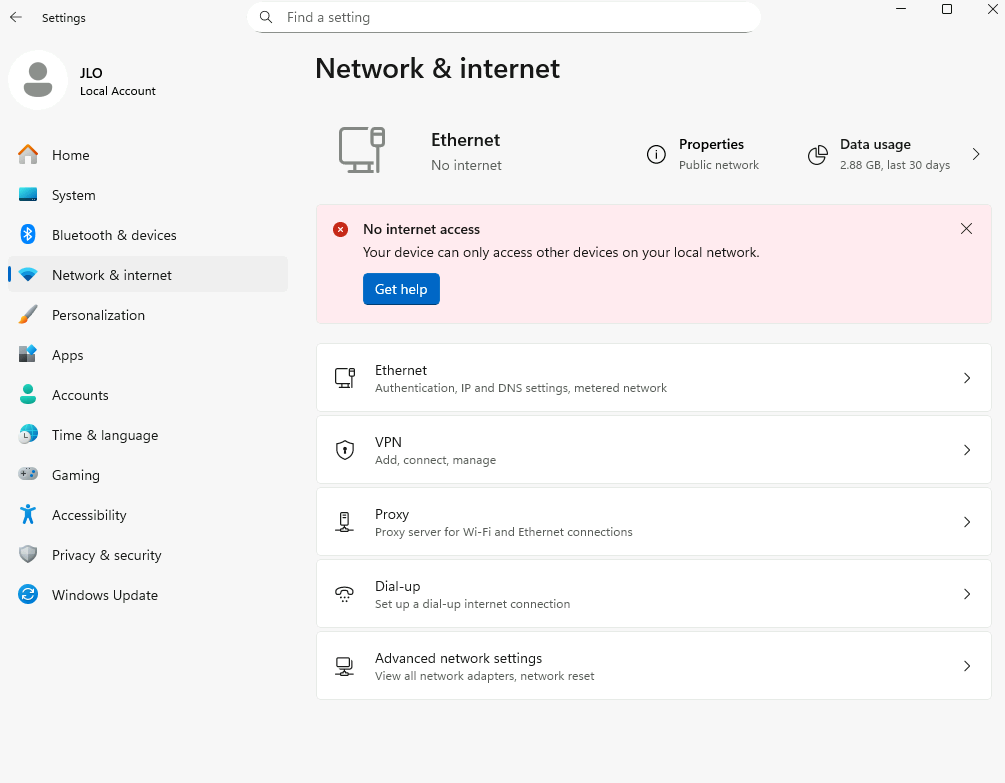
Impossible d’ouvrir des sites web depuis le navigateur internet :
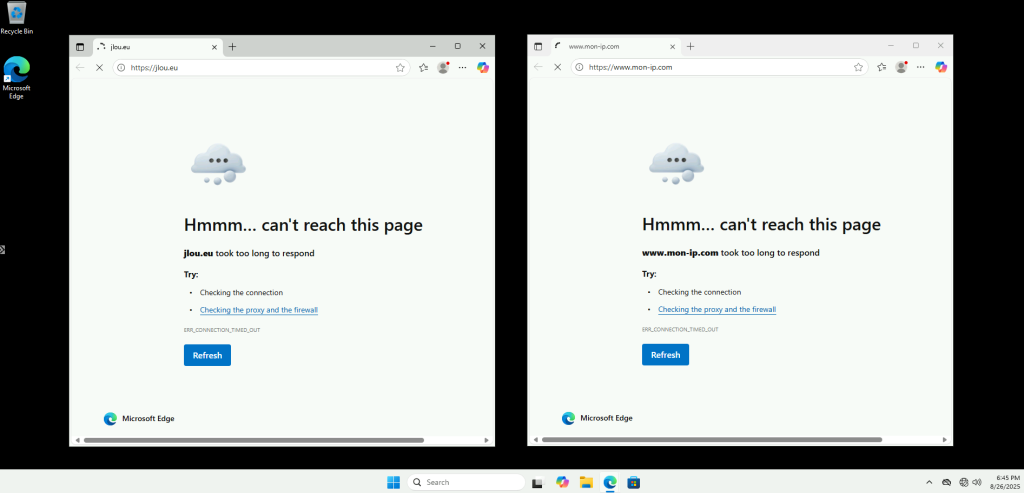
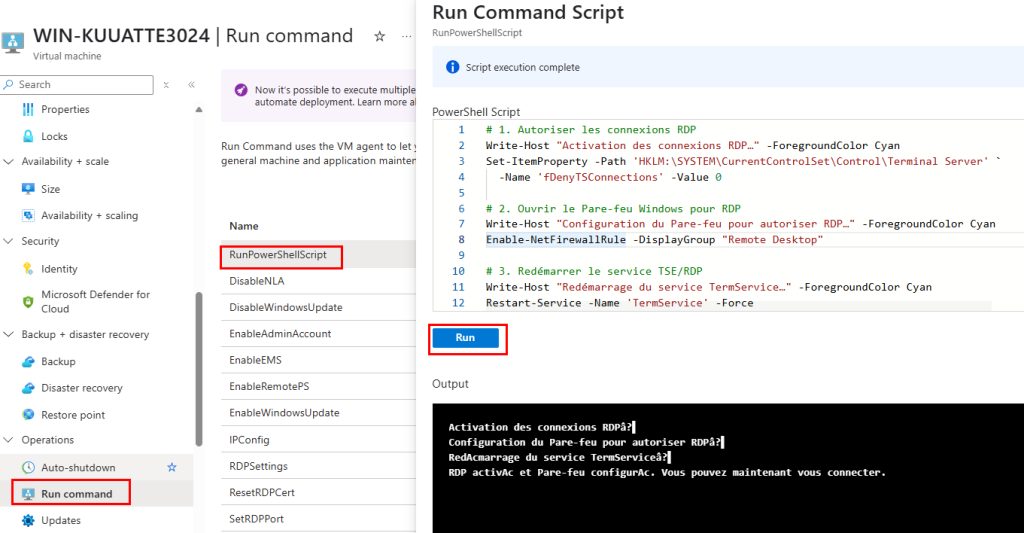
Windows Update échoue également à télécharger les mises à jour :
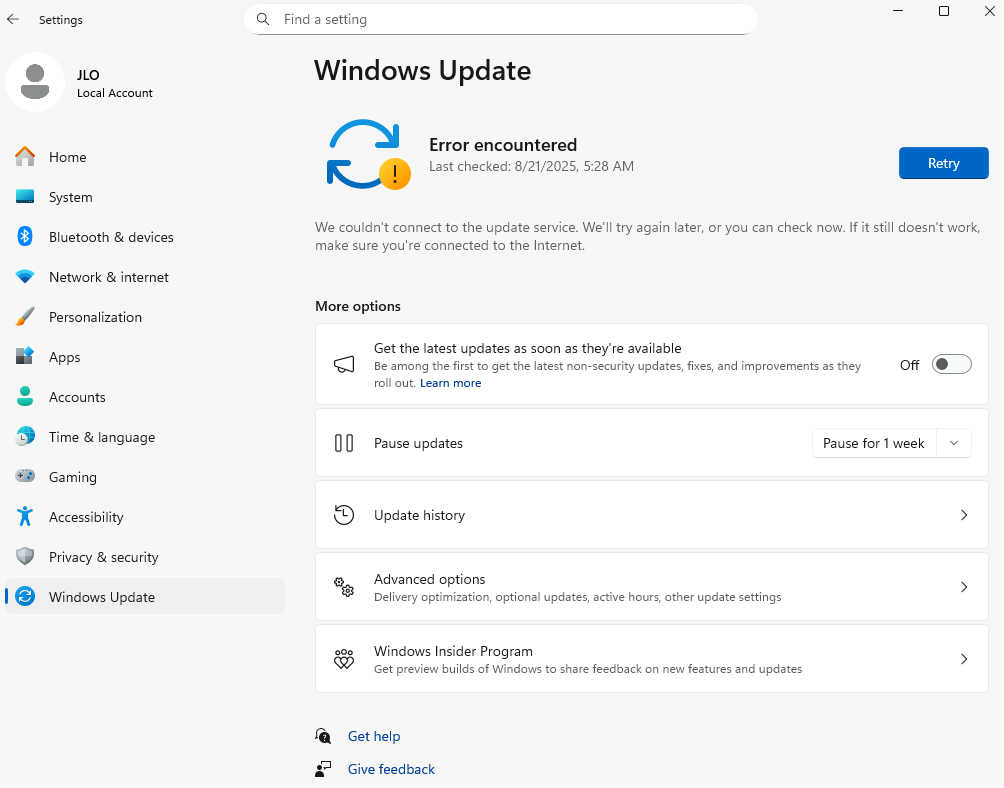
L’activation Windows ne se fait pas non plus :
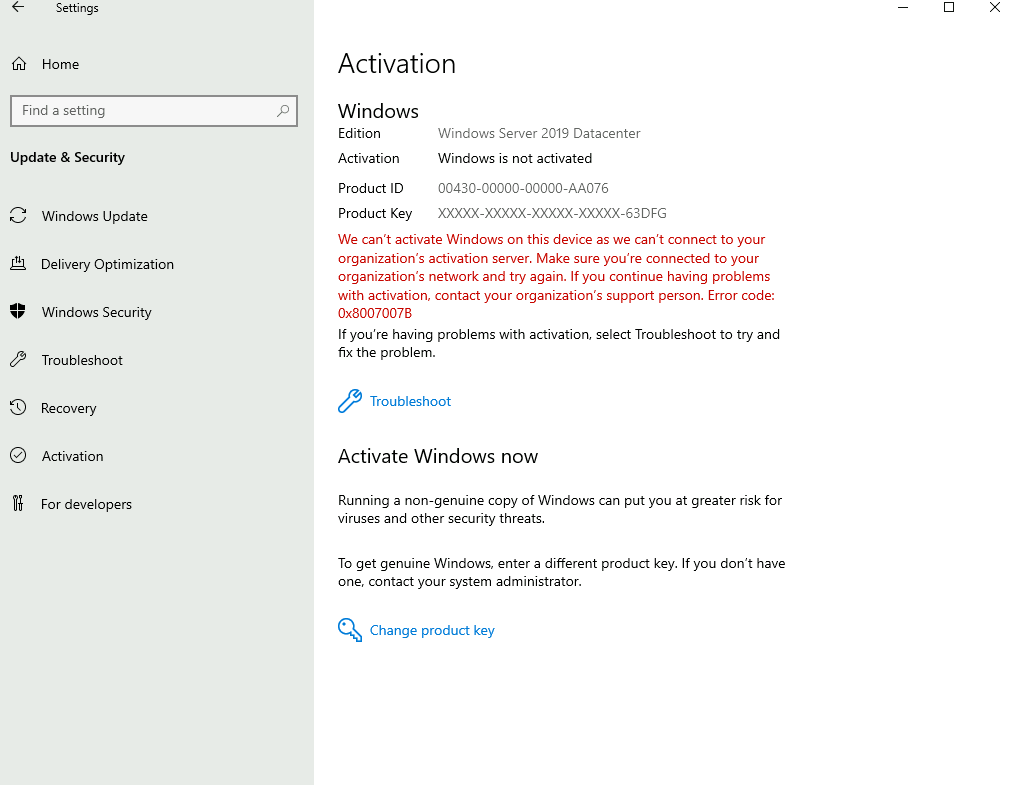
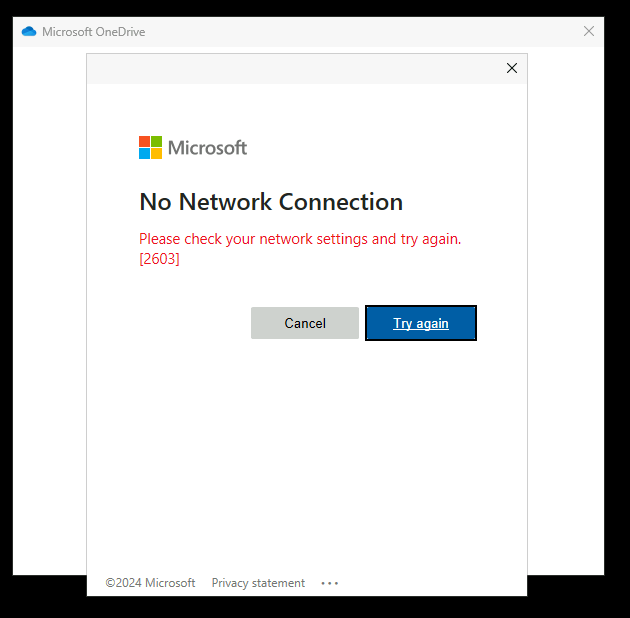
Et cette fois, OneDrive refuse de se configurer :
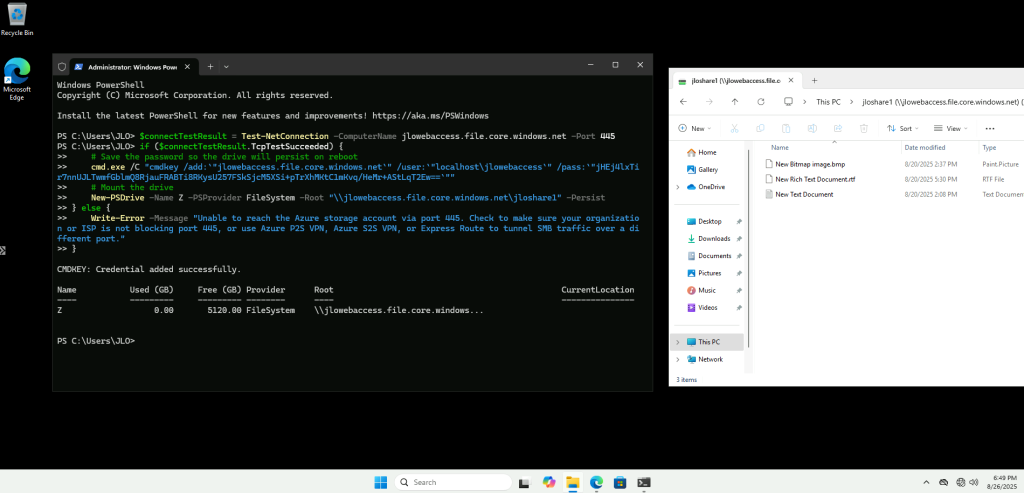
Et pourtant, j’accède sans problème à un compte de stockage via son URL publique :
Tout montre que l’accès extérieur à Azure, y compris Microsoft 365, est bloqué dans ce sous-réseau privé.
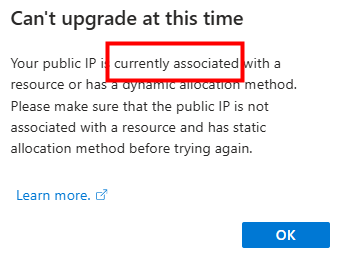
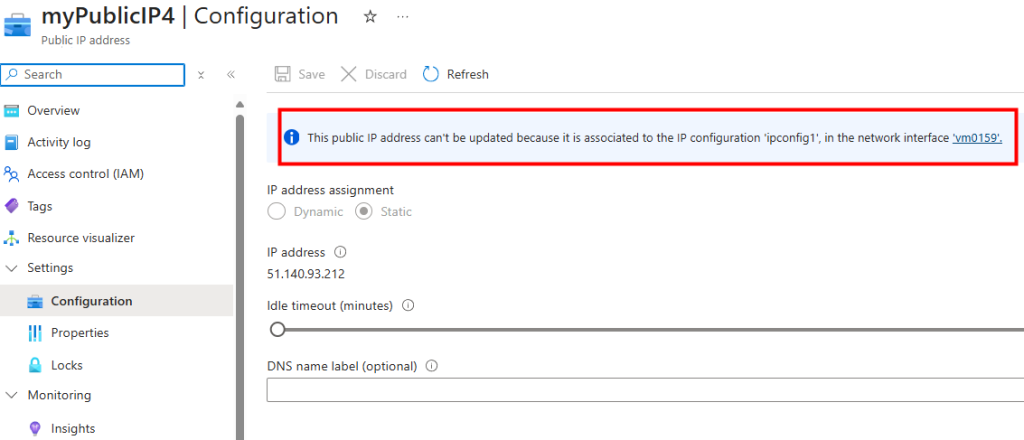
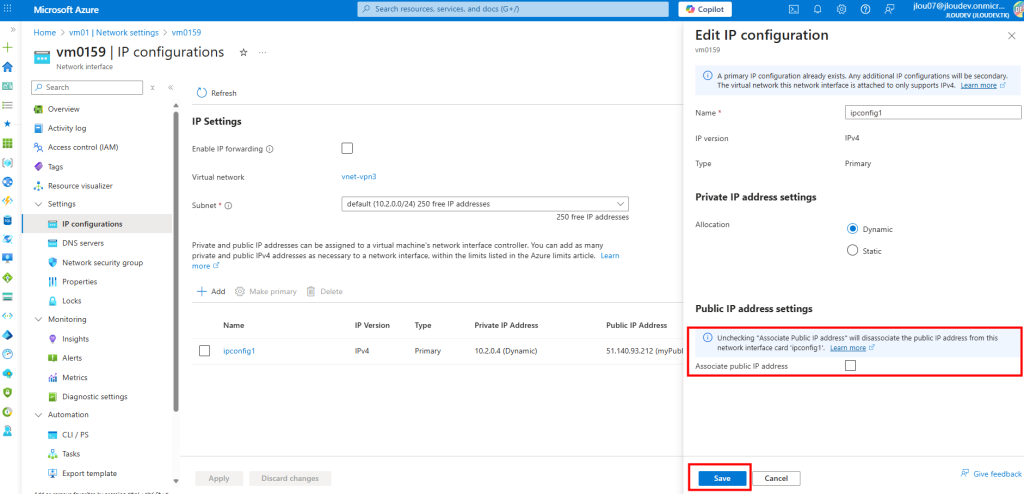
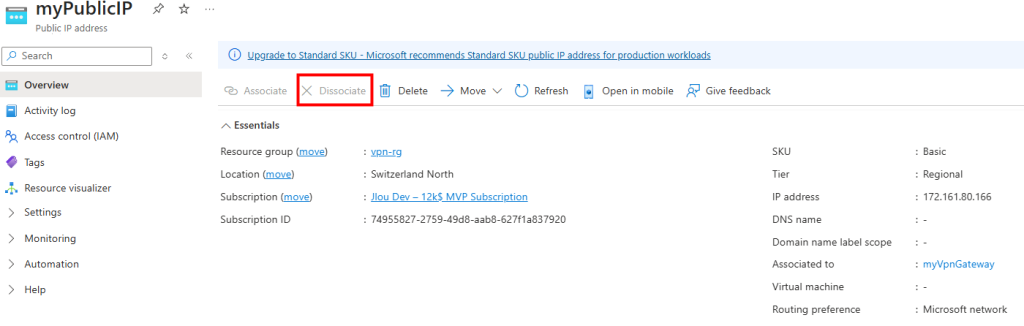
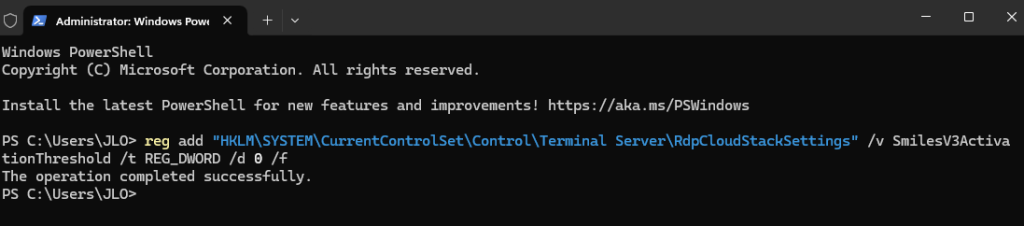
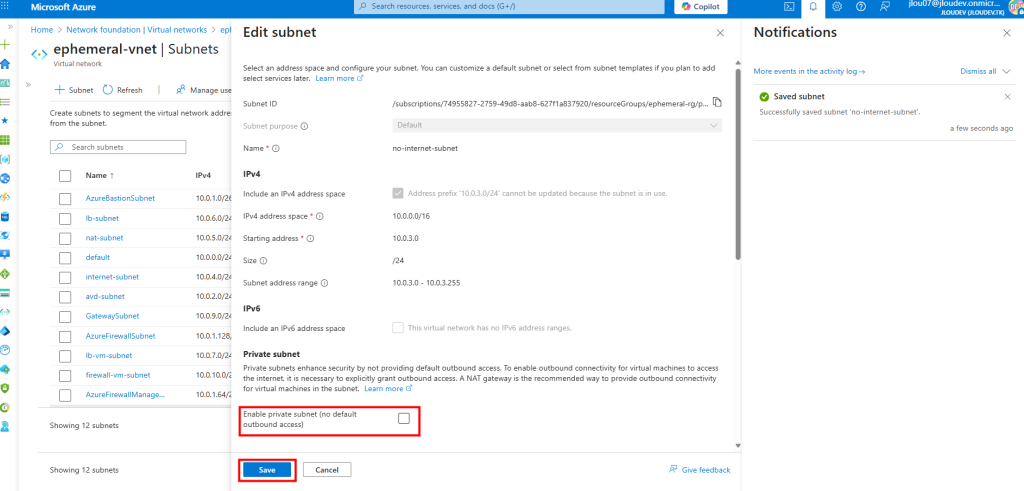
Sur ce second sous-réseau, je décoche l’option précédemment activée, puis je sauvegarde :
Malgré cela, la machine n’a toujours pas retrouvé Internet :
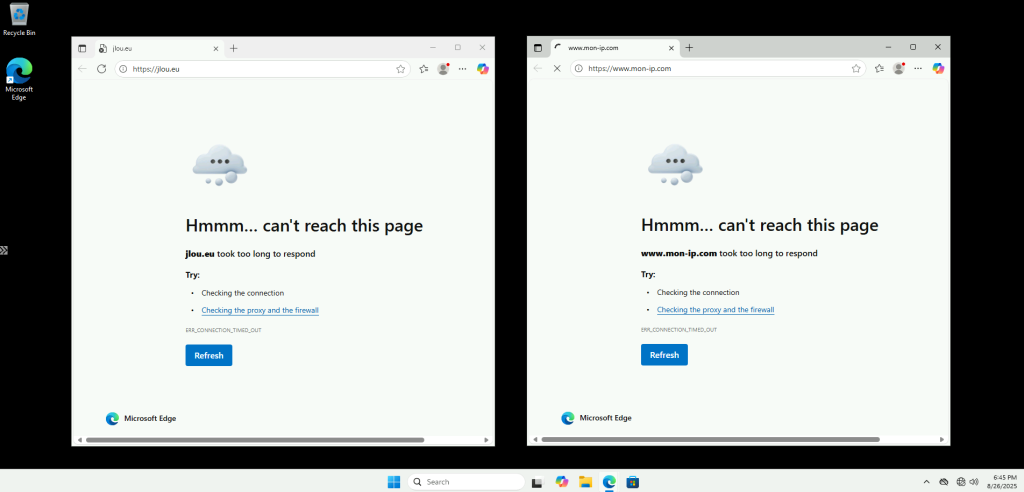
Je tente même un redémarrage de la machine virtuelle depuis le portail Azure :
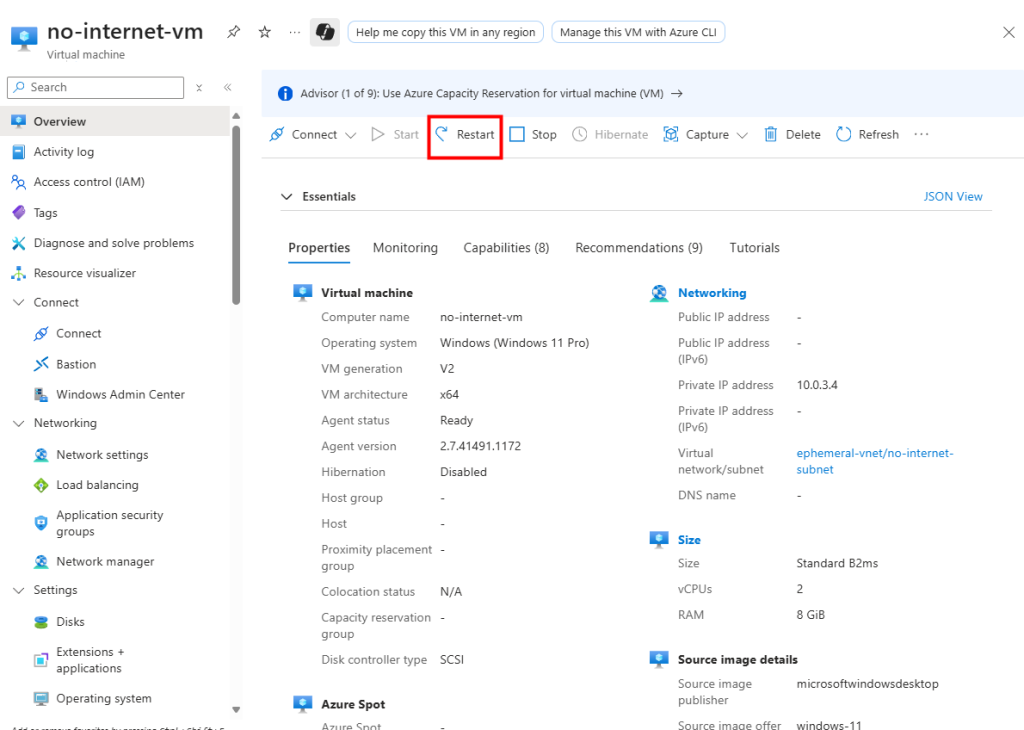
Mais après ce redémarrage, rien ne change côté accès Internet :
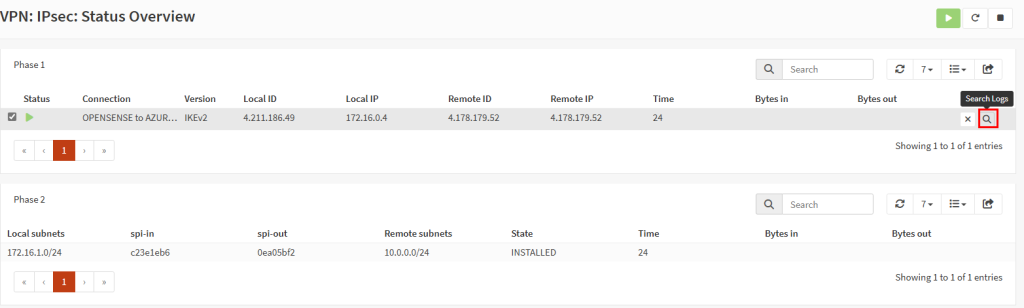
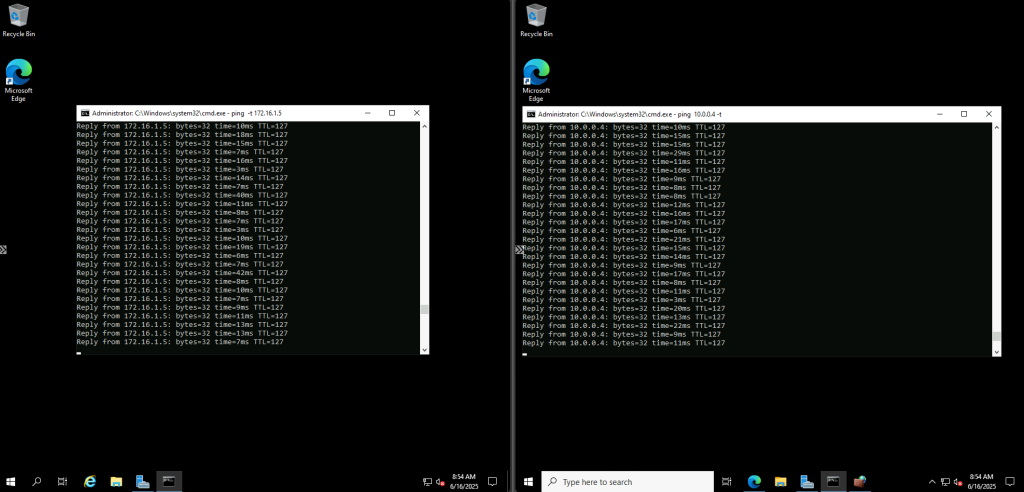
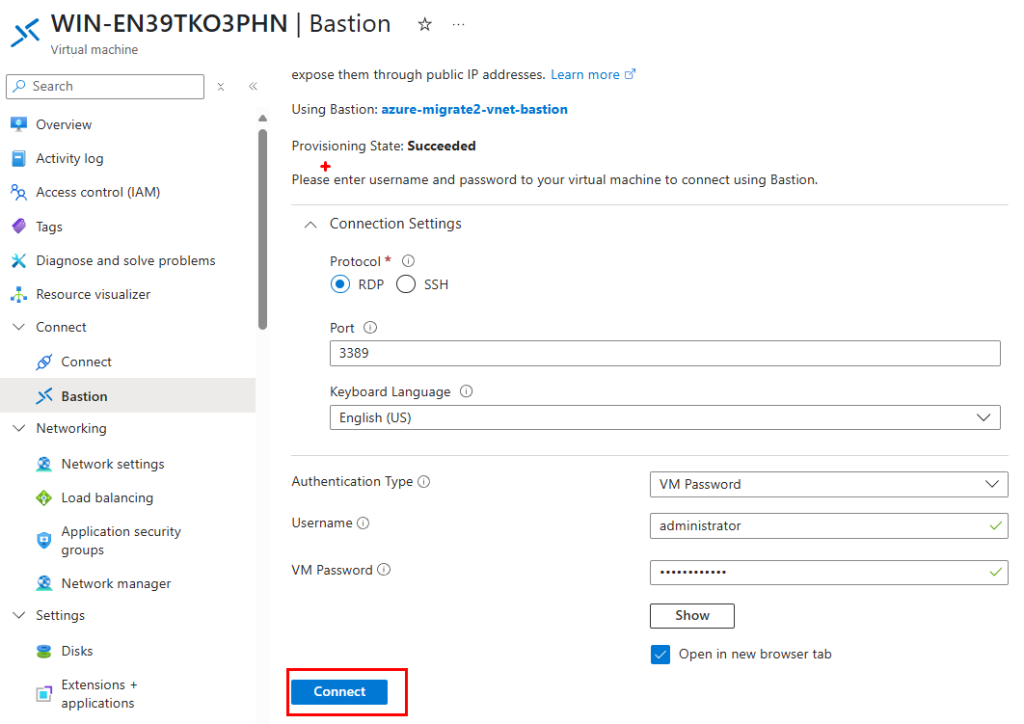
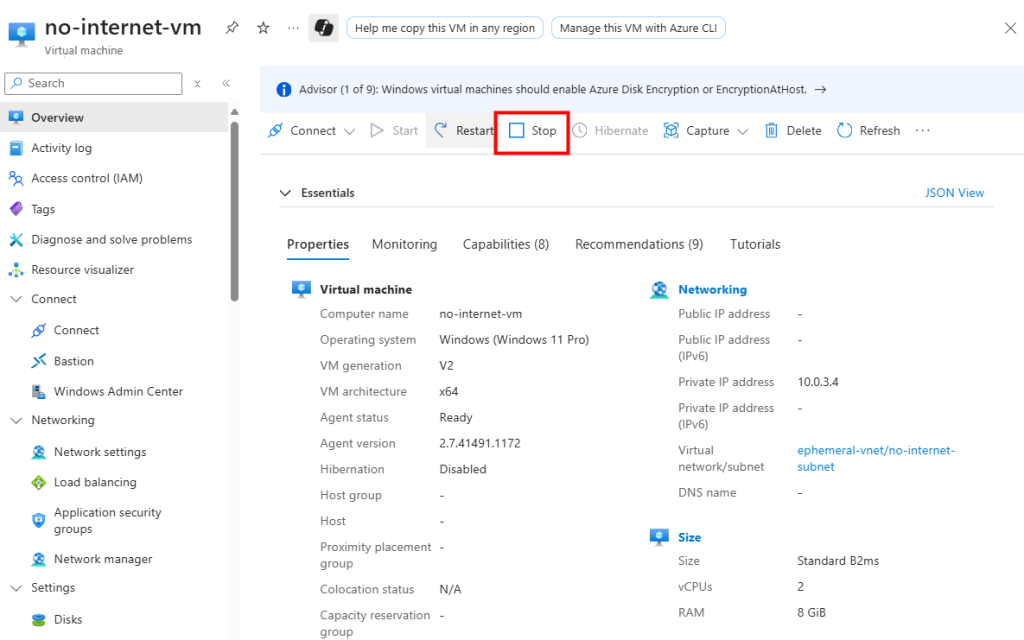
Après un arrêt complet puis un redémarrage manuel, la sortie vers Internet revient :
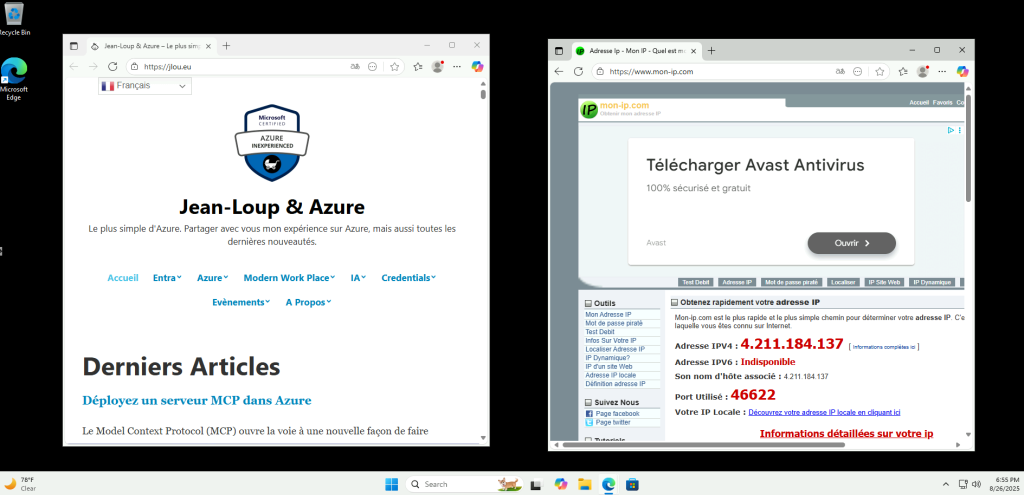
Cette fois, la VM a bien une IP publique éphémère pour sortir sur Internet :
Ce test nous montre l’impact de cette option sur les ressources externes accessibles à notre machine virtuelle. Continuons avec un test sur le comportement d’Azure Virtual Desktop dont les VMs seraient sur ce type de sous-réseau privé.
Test III – Connexion Azure Virtual Desktop depuis un sous-réseau privé :
Je dispose d’un environnement Azure Virtual Desktop contenant déjà plusieurs machines virtuelles dans le pool d’hôtes :
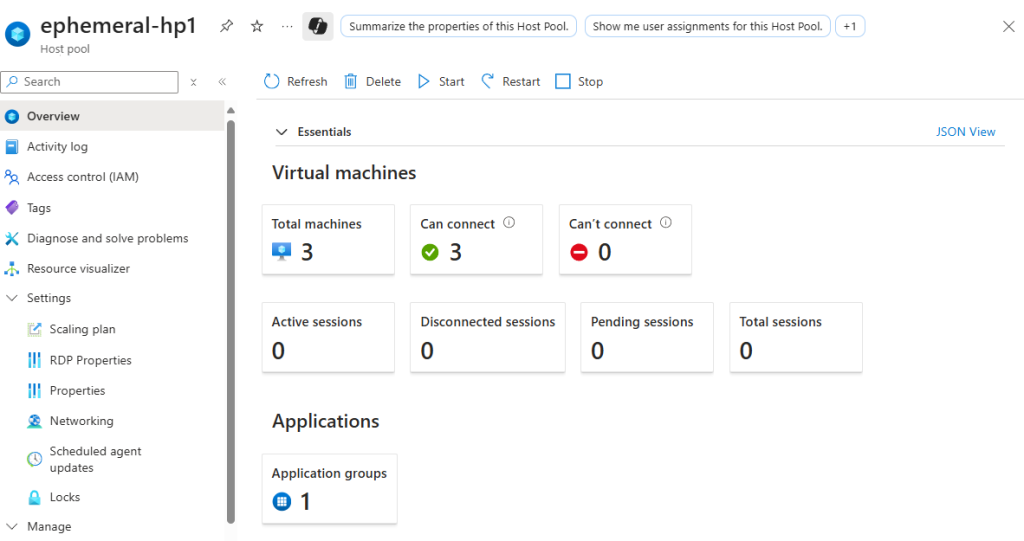
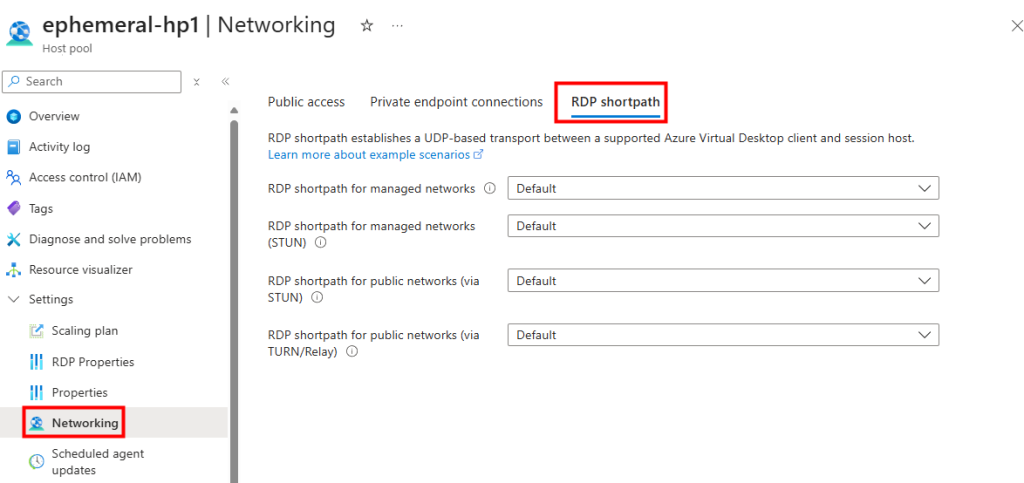
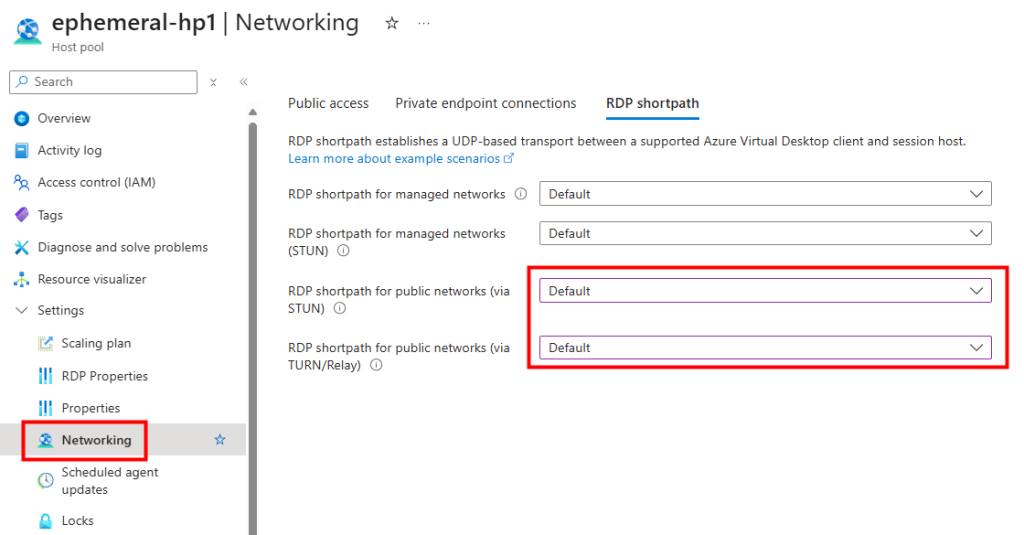
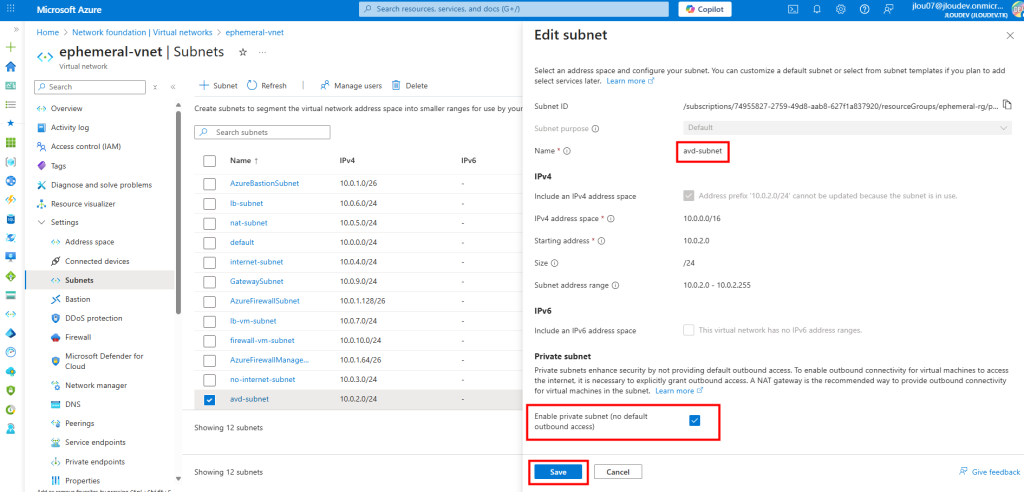
J’ai donc modifié le sous-réseau AVD pour qu’il soit privé :
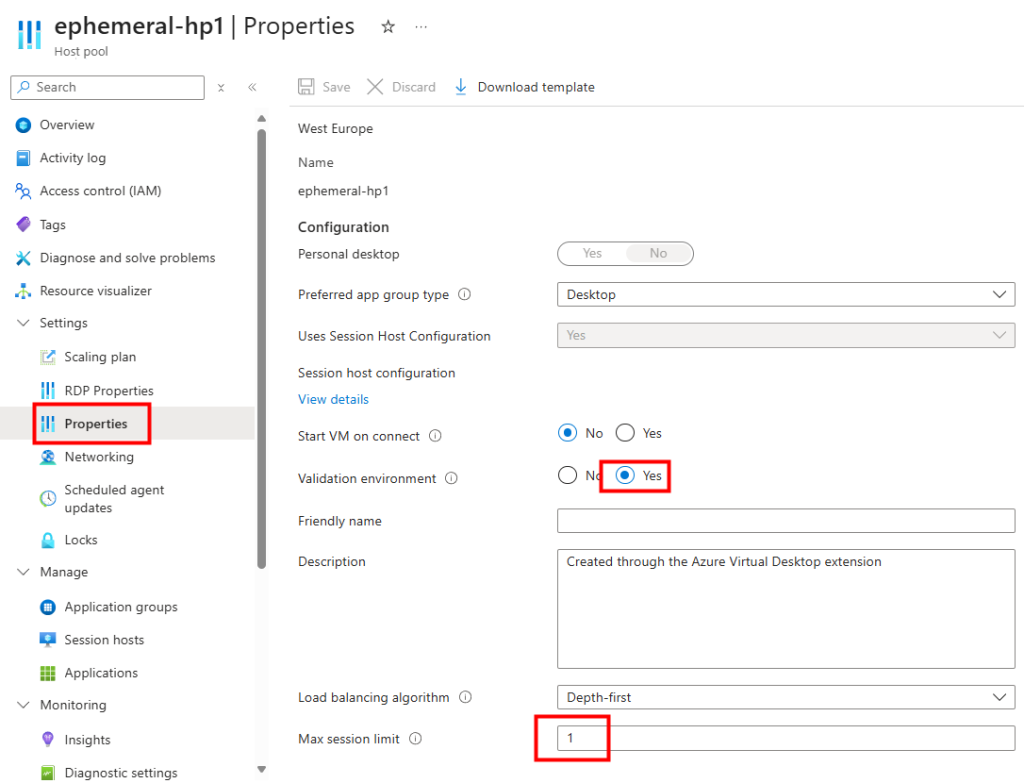
J’ai ajouté une nouvelle machine virtuelle via le plan de mise à l’échelle AVD :
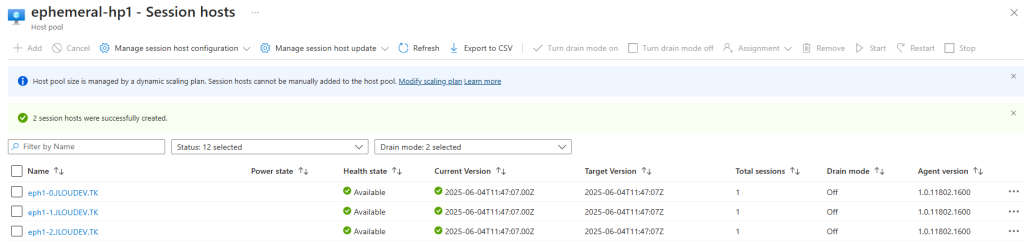
La création de la VM se déroule normalement et celle-ci apparaît :
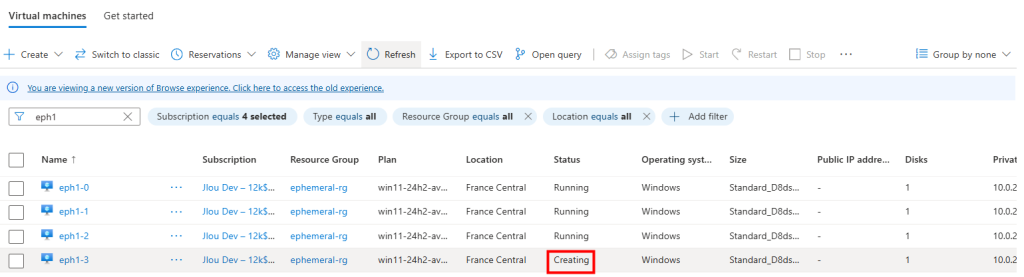
Mais, elle n’a jamais rejoint automatiquement mon Active Directory :
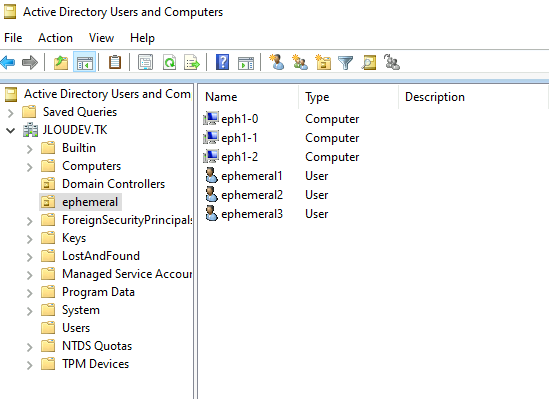
Et elle n’a pas non plus intégré le pool d’hôtes AVD :
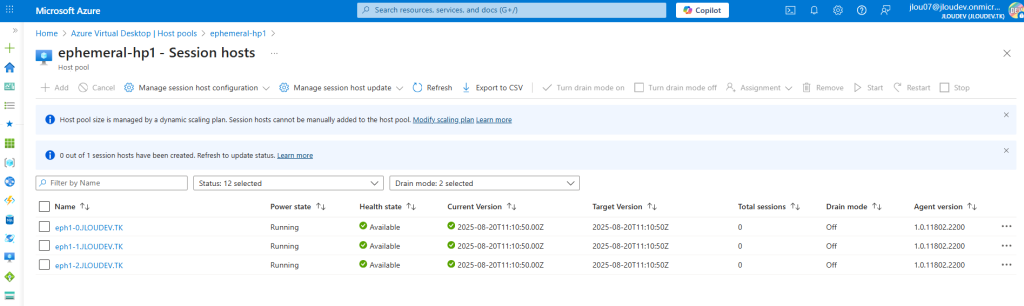
Enfin, au bout d’un certain temps, elle s’est même auto-supprimée :
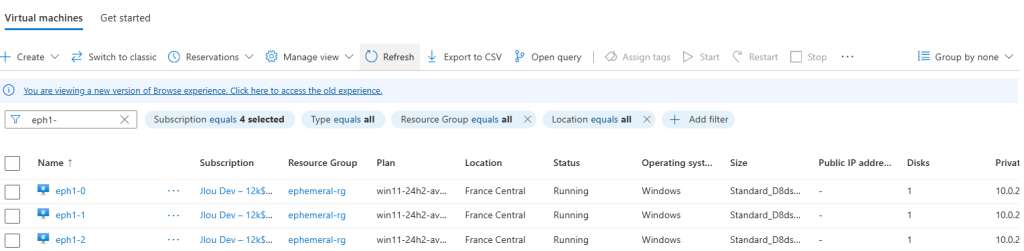
Ce test nous montre qu’un environnement Azure Virtual Desktop déployé après septembre 2025 nécessitera des ressources supplémentaires pour fonctionner correctement.
Continuons nos tests en appliquant les méthodes proposées par Microsoft pour compenser le changement à venir.
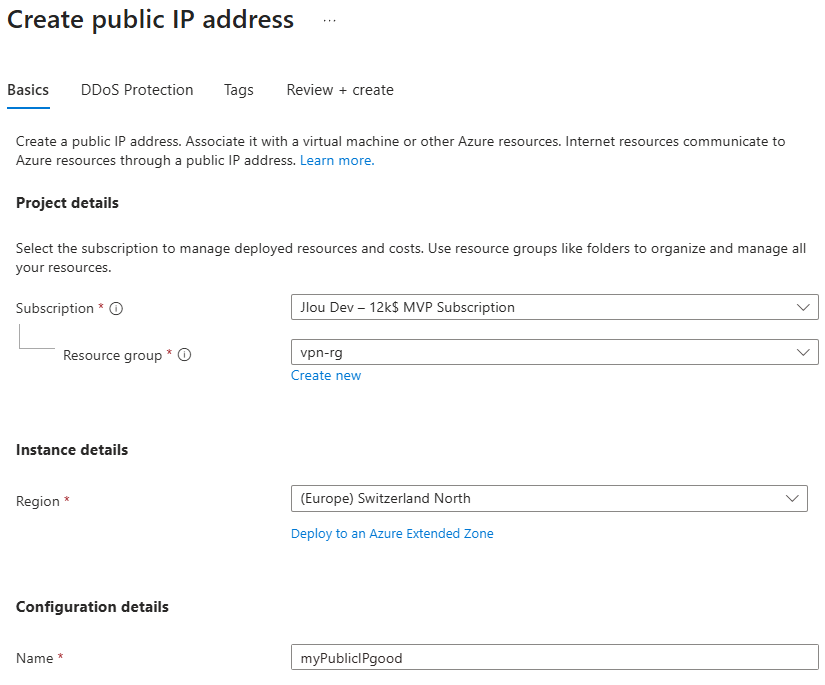
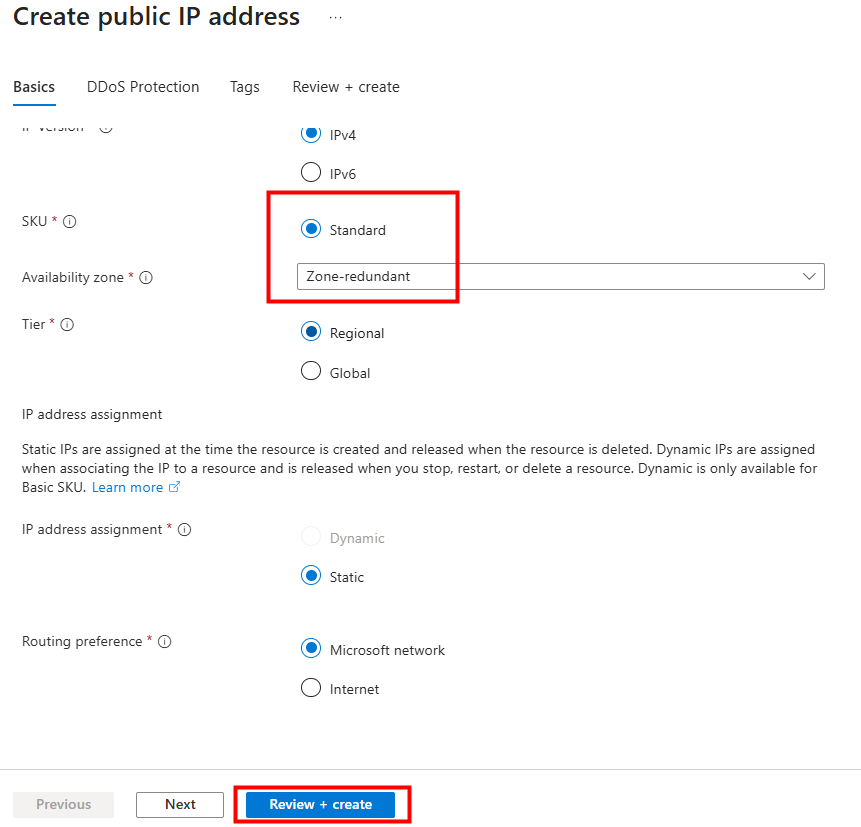
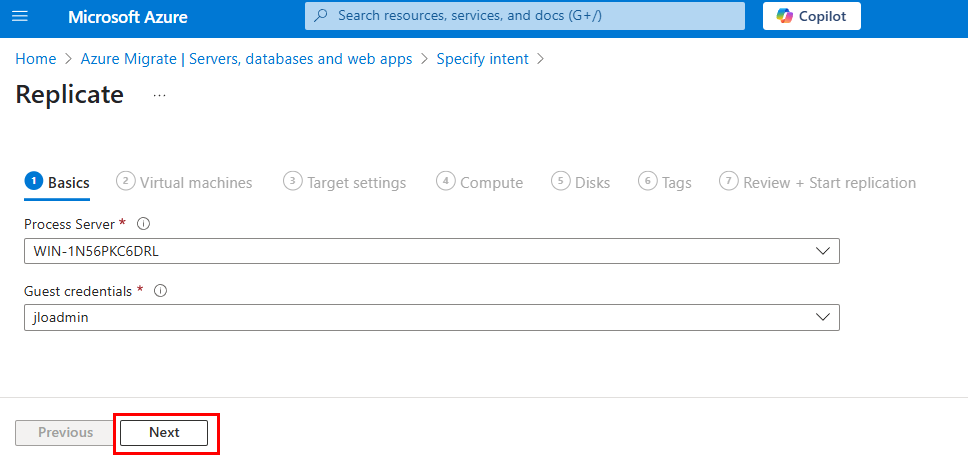
Test IV – Connexion internet avec une adresse IP publique :
Je recoche l’option Private subnet sur mon 2ᵉ sous-réseau :
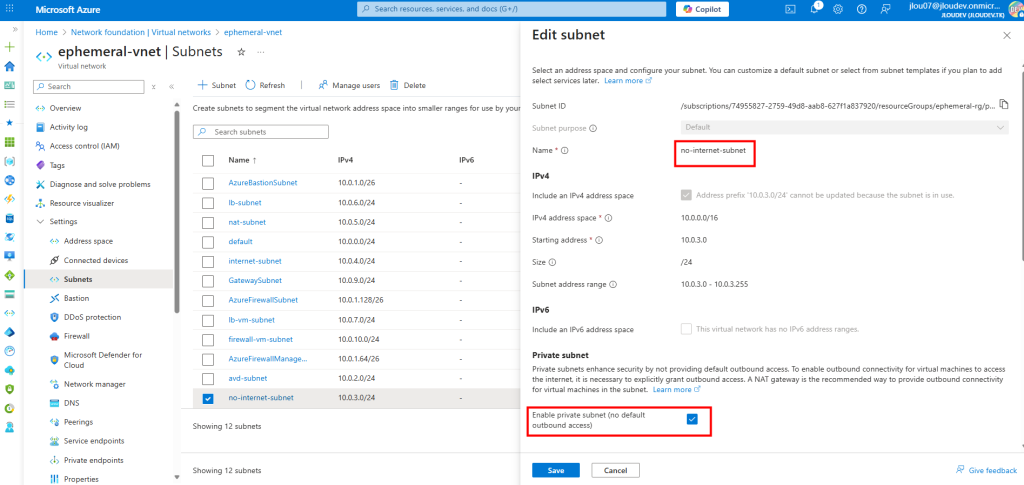
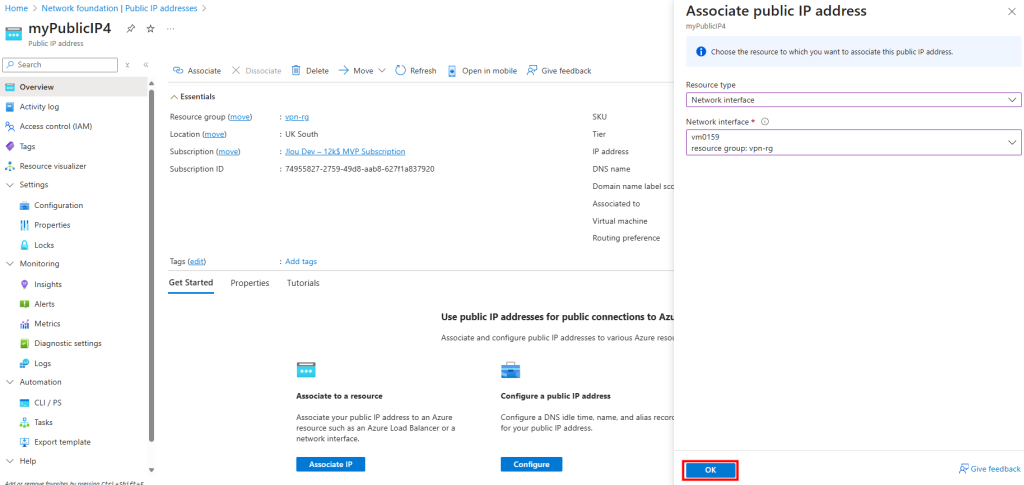
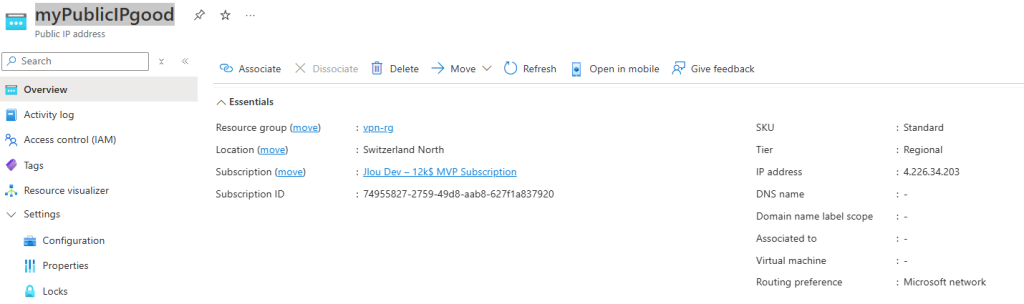
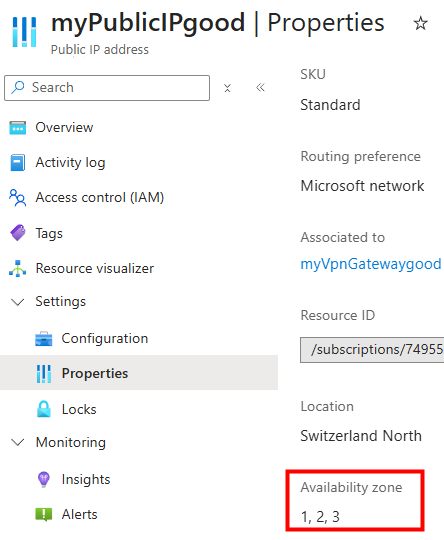
J’y crée une machine virtuelle, cette fois disposant d’une adresse IP publique associée :
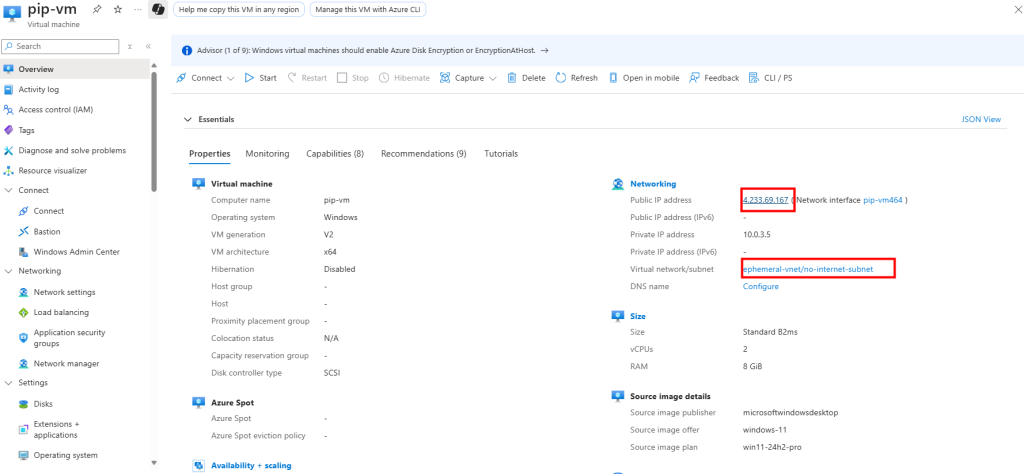
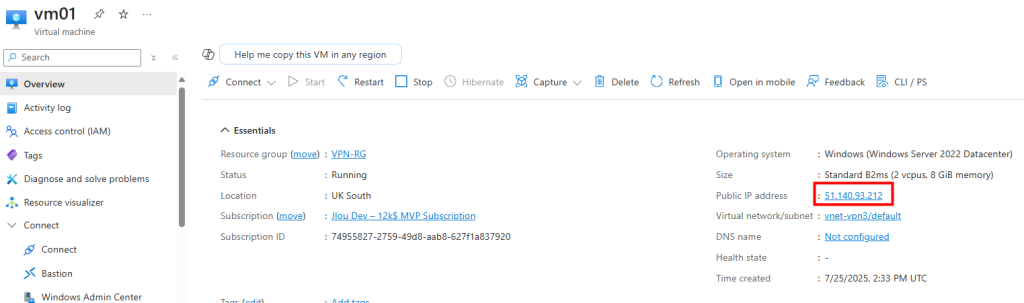
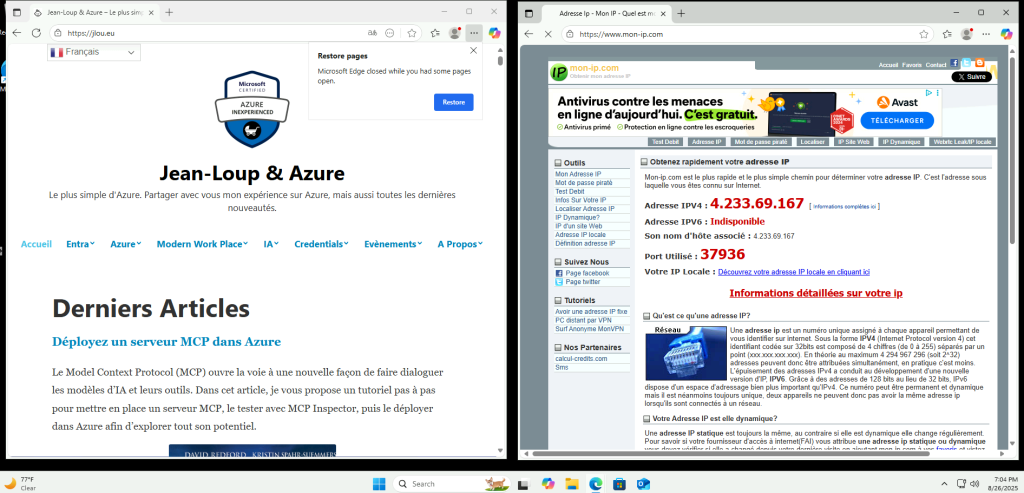
La VM a bien accès à Internet, et l’IP vue depuis l’extérieur correspond à l’IP publique de la machine virtuelle :
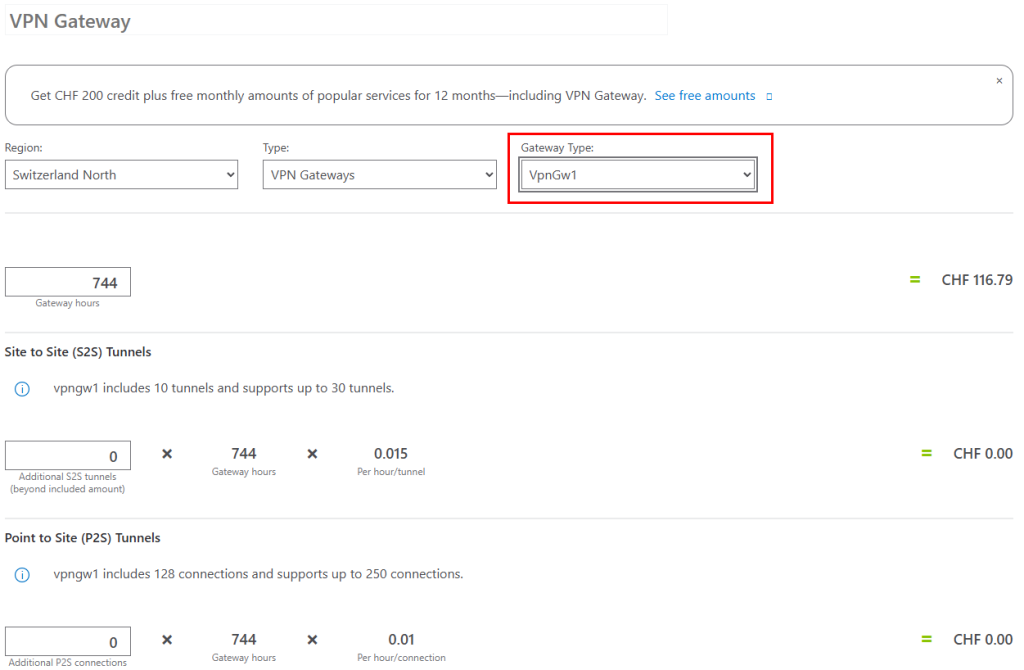
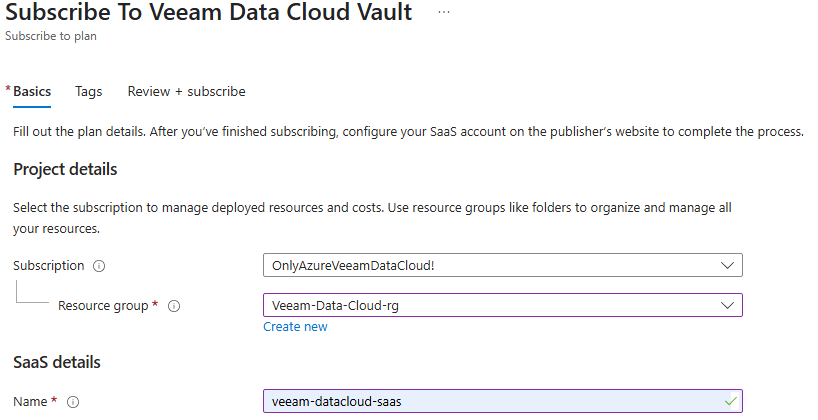
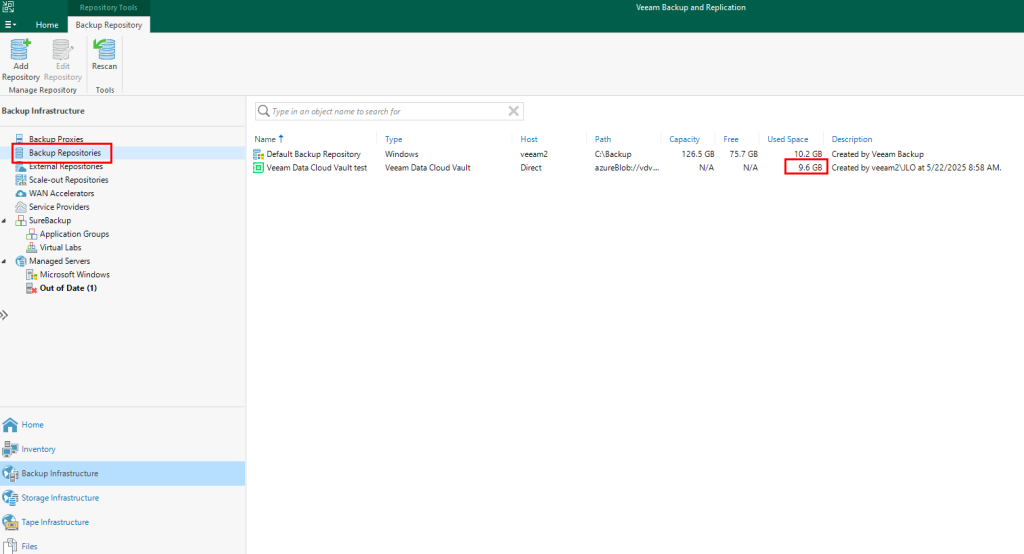
Voici le coût de cette IP publique dans le Azure Pricing Calculator :
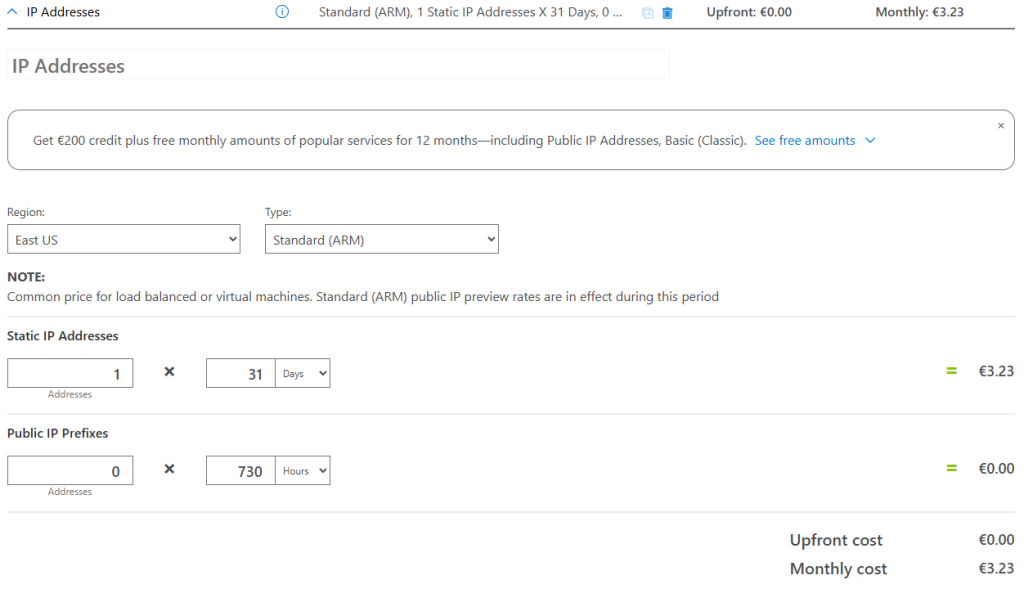
Il s’agit de la solution la plus économique pour retrouver un accès internet. Mais la question va se poser si un grand nombre de machines virtuelles existent. Si l’ajout d’une adresse IP publique sur une machine virtuelle n’est pas sans conséquence sur la sécurité.
Continuons avec le service Azure NAT Gateway.
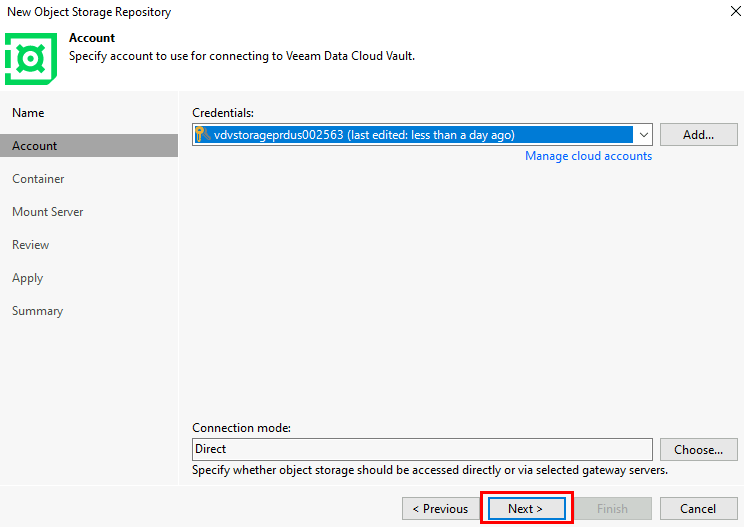
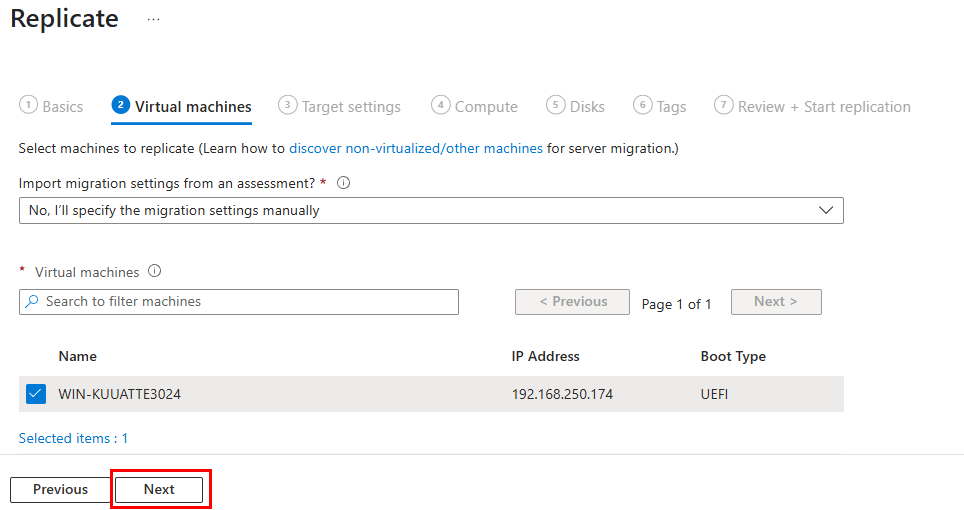
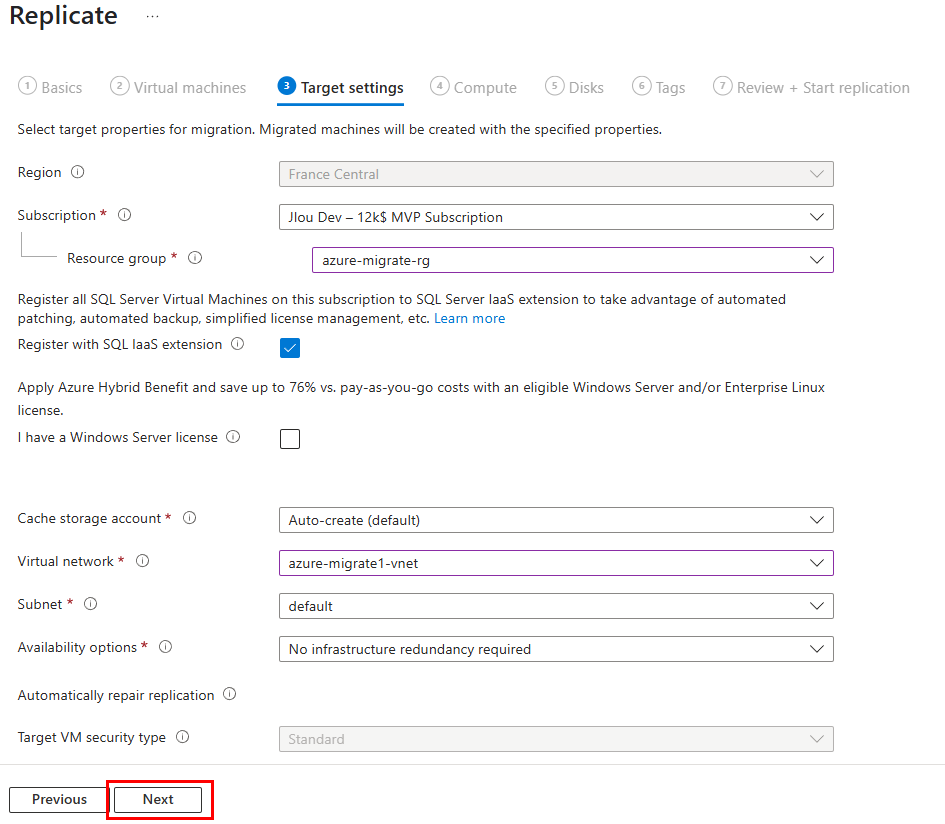
Test V – Connexion internet avec Azure NAT Gateway :
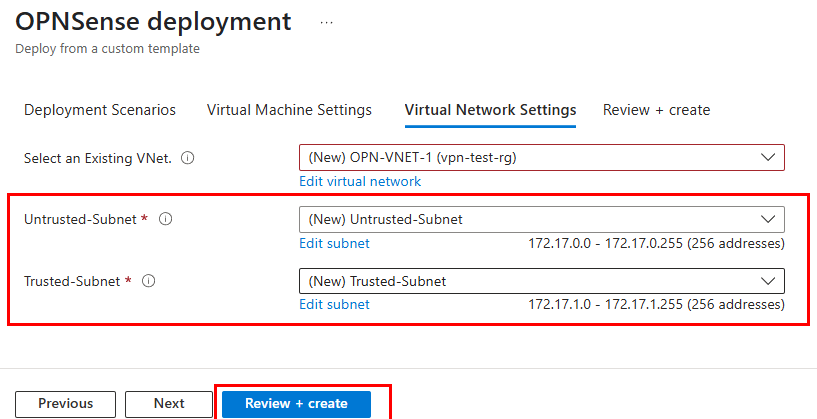
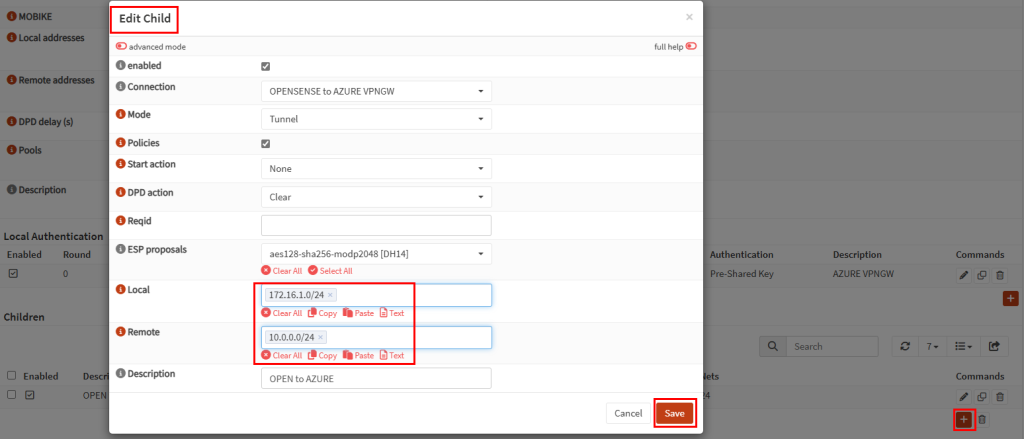
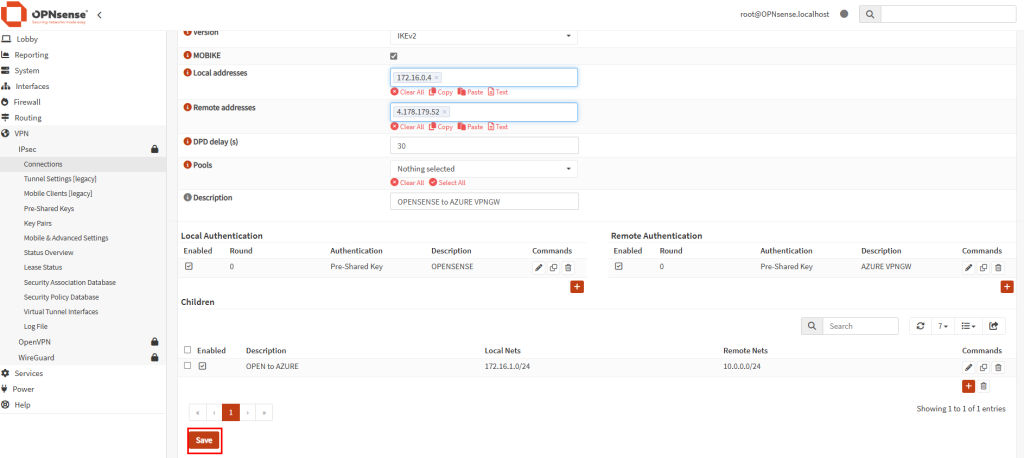
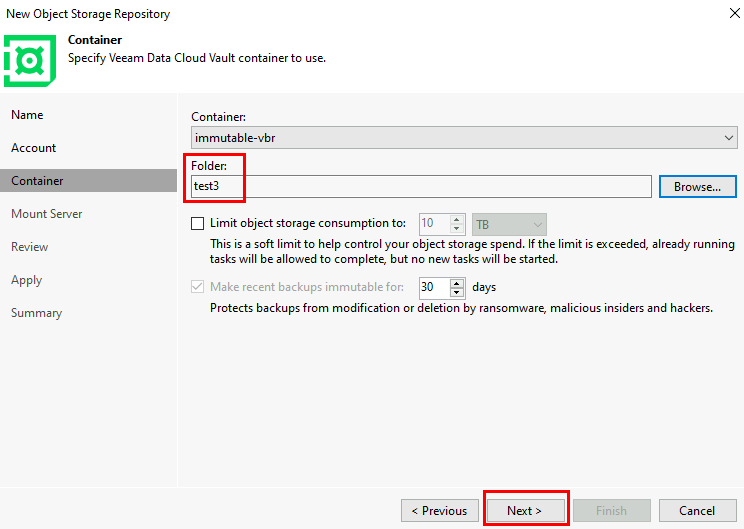
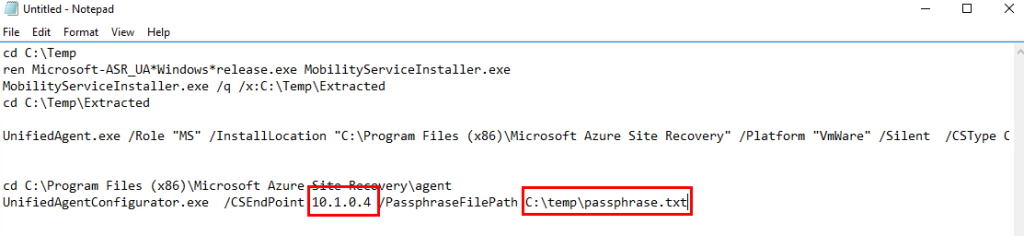
Je crée un 3ᵉ sous-réseau privé, dédié cette fois à un test avec NAT Gateway :
Je déploie un service NAT Gateway et je lui assigne une IP publique :
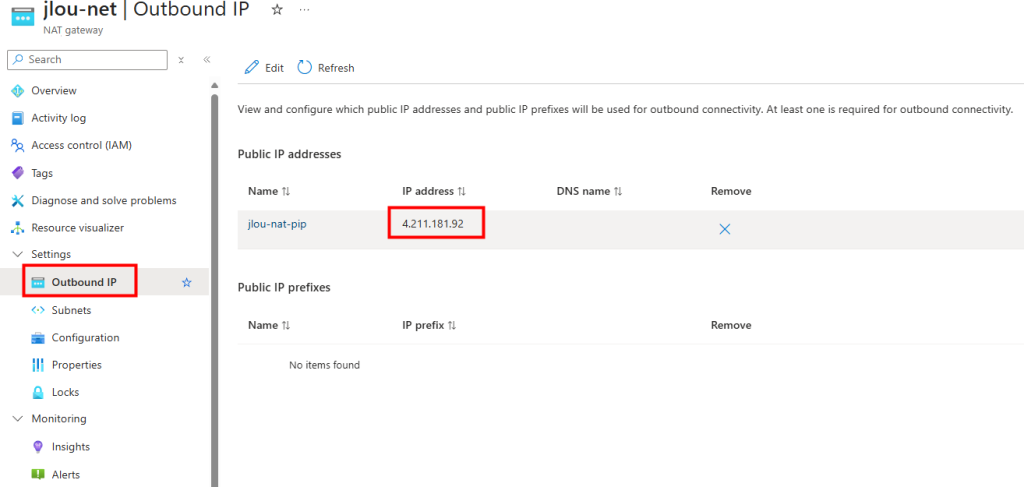
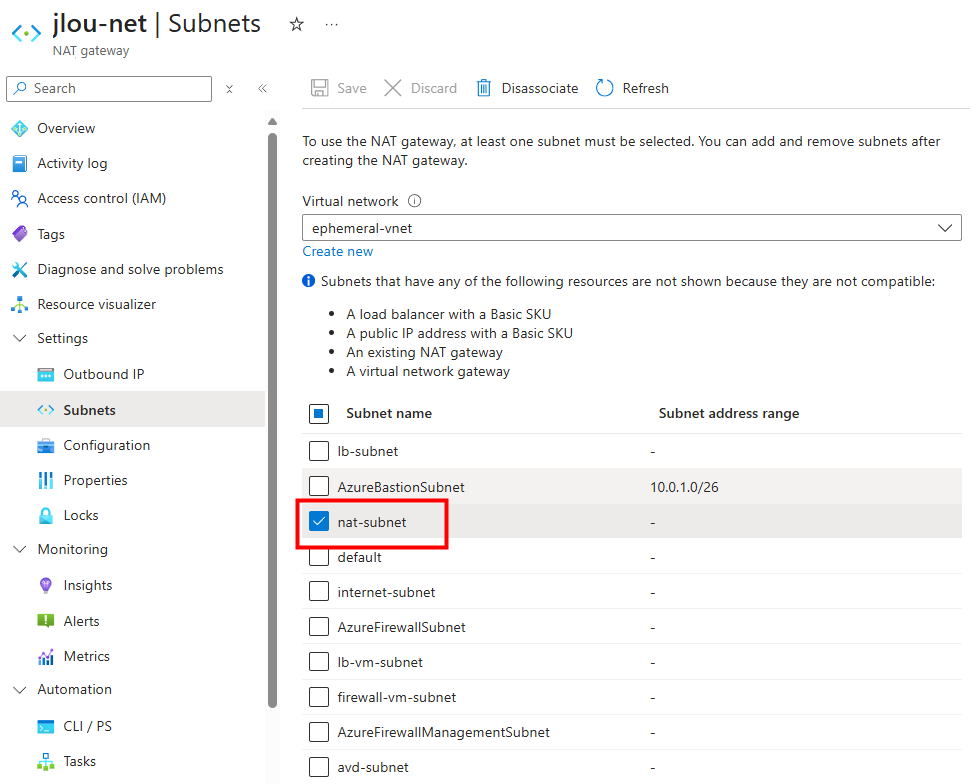
Le nouveau sous-réseau privé est bien associé au service NAT Gateway :
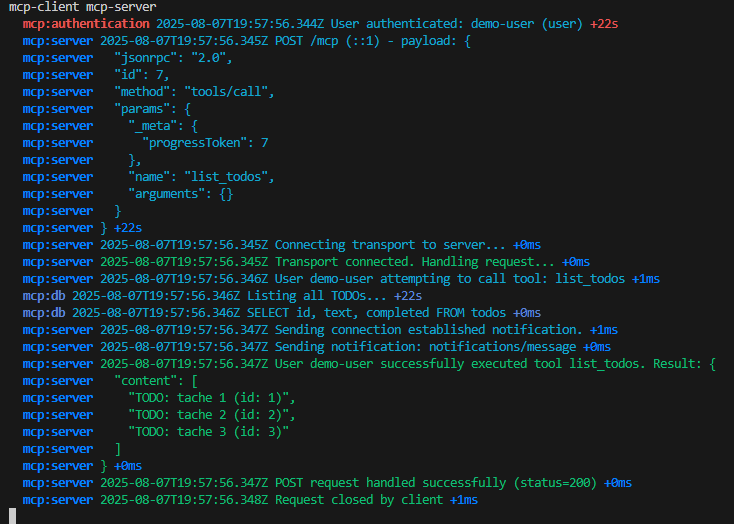
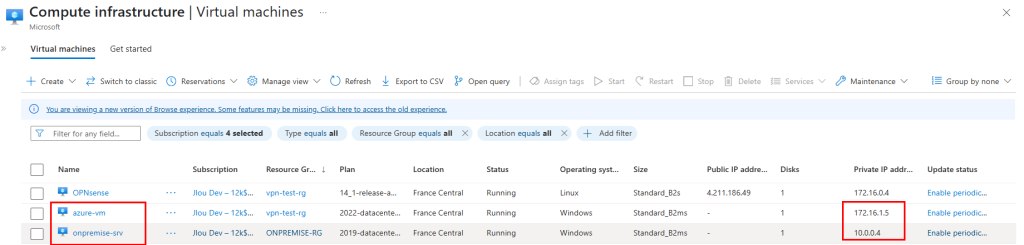
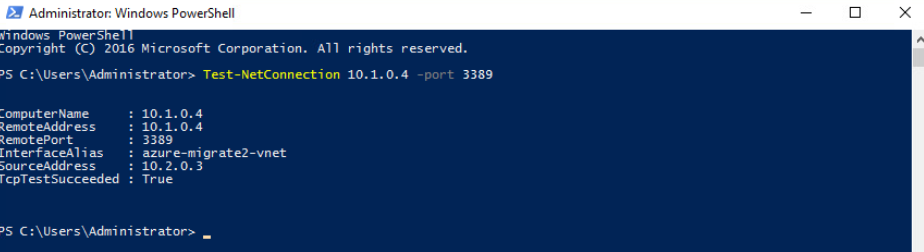
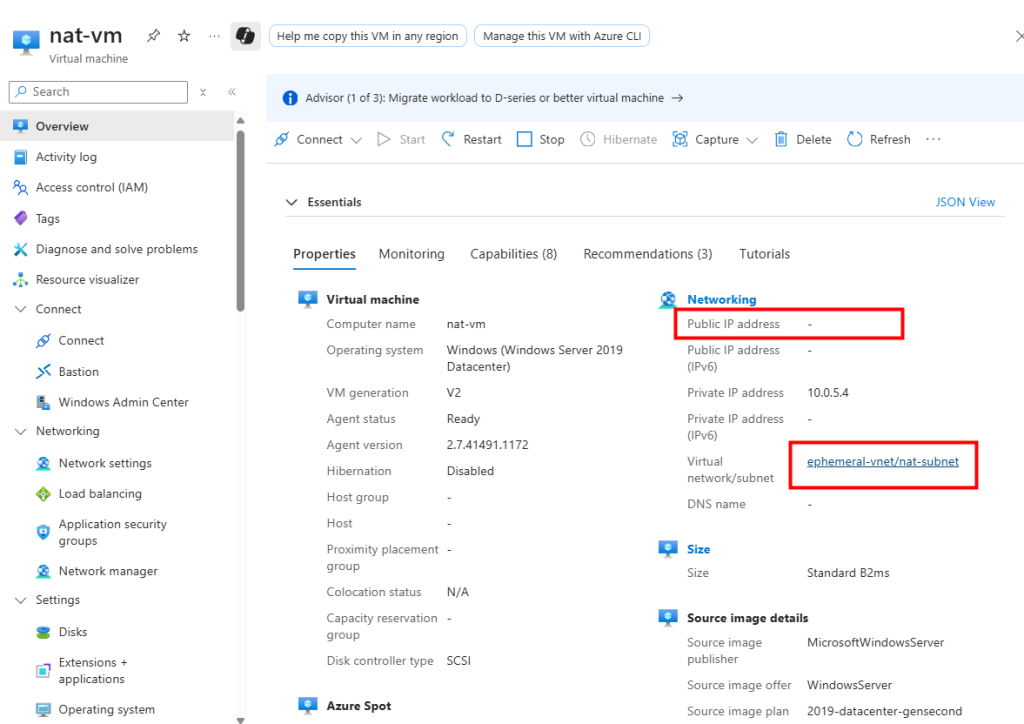
Je crée une VM dans ce 3ᵉ sous-réseau :
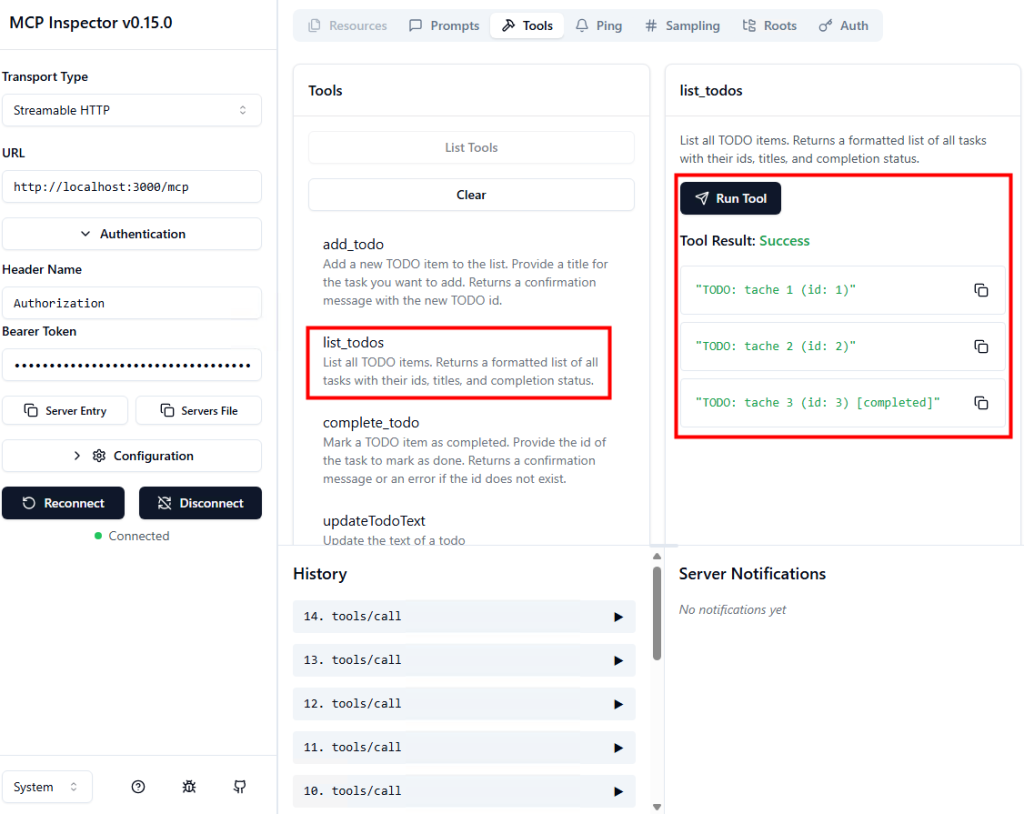
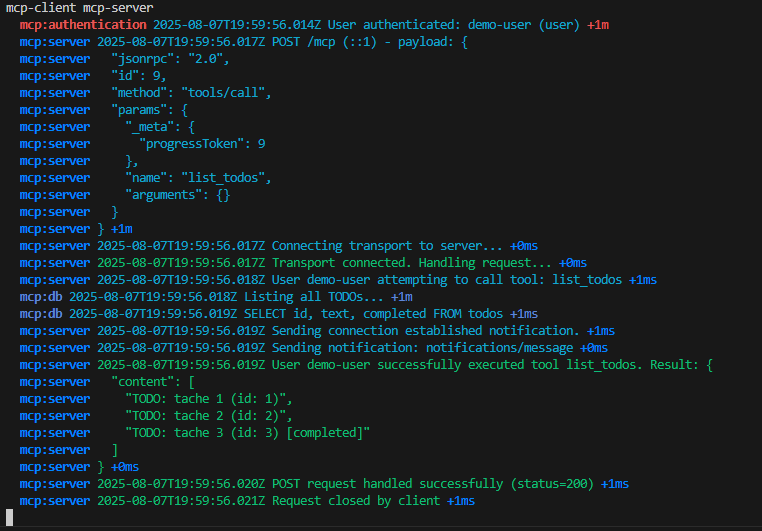
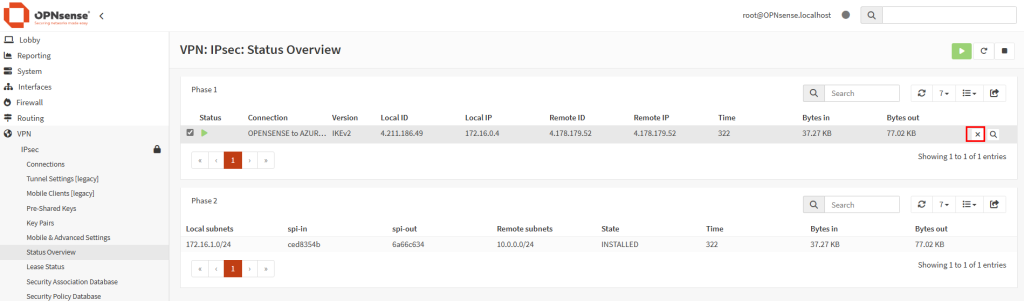
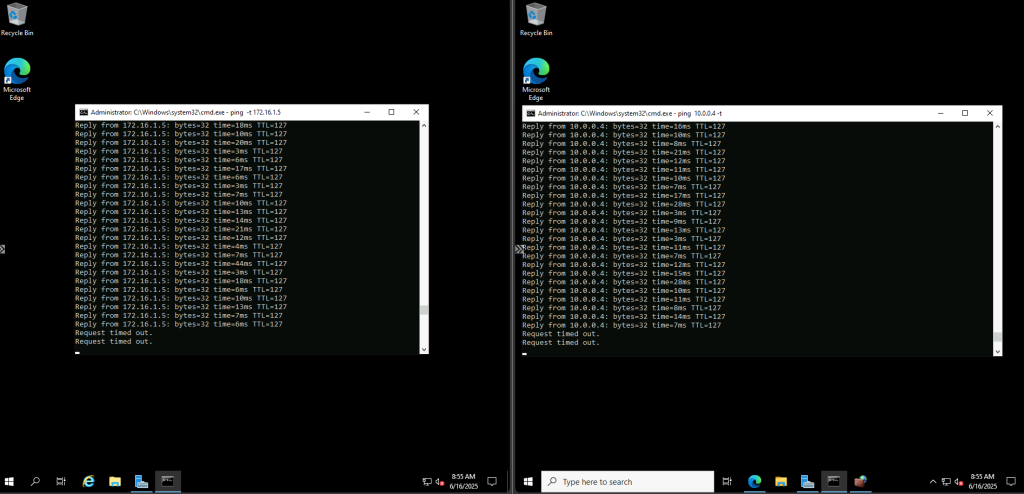
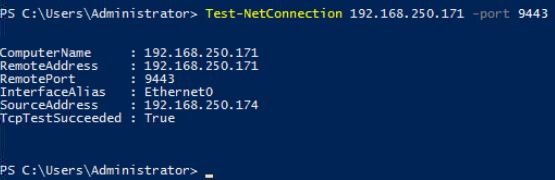
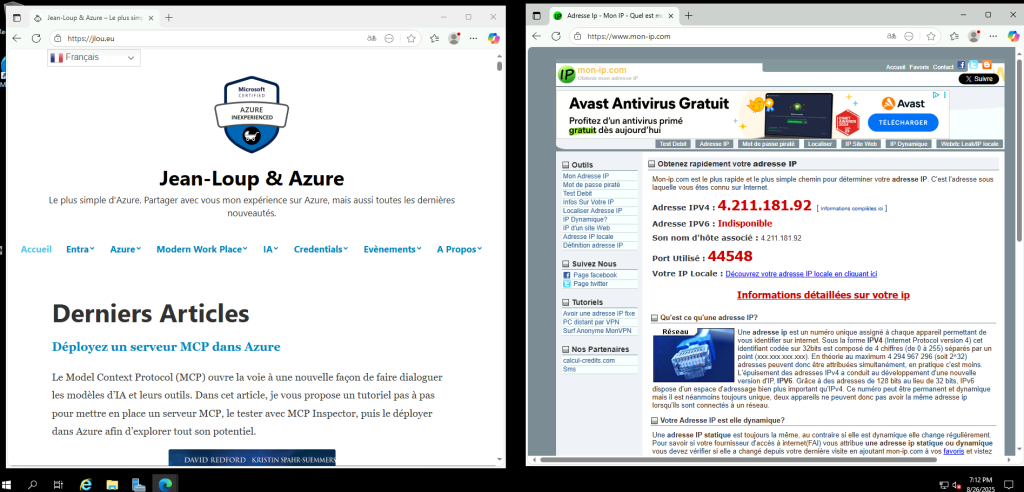
Les tests montrent que la VM utilise bien l’adresse IP publique du NAT Gateway pour sortir sur Internet :
Je reproduis ensuite ce même test sur le sous-réseau dédié à Azure Virtual Desktop :
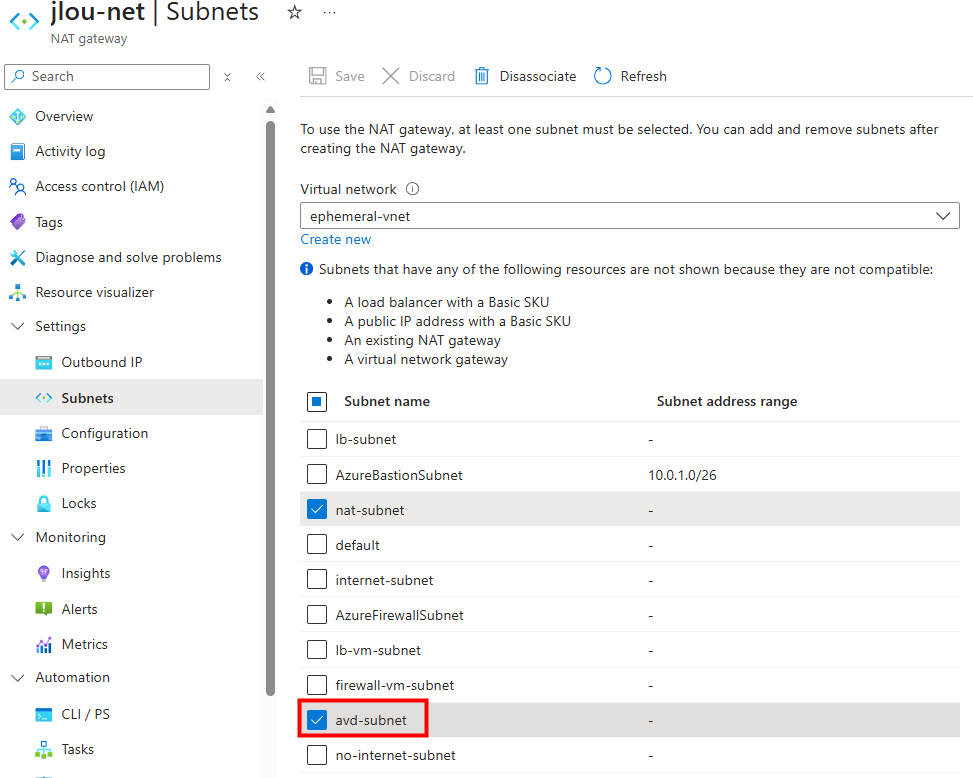
Je lance la création d’une 4ᵉ VM AVD :
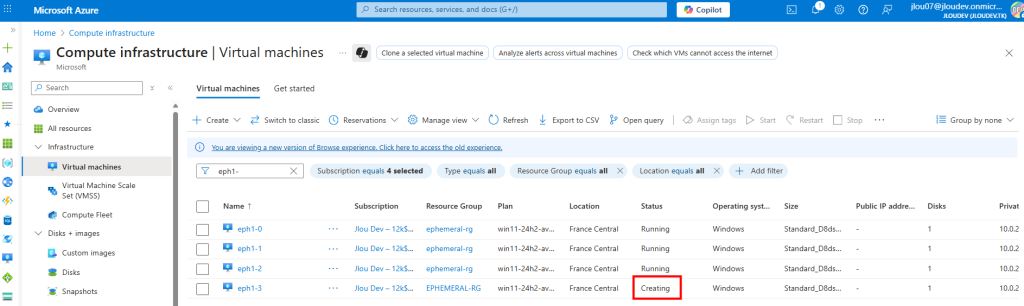
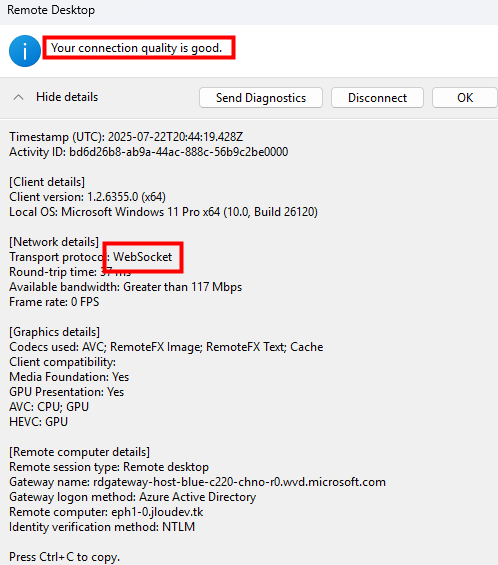
Cette fois, la VM rejoint correctement mon Active Directory :
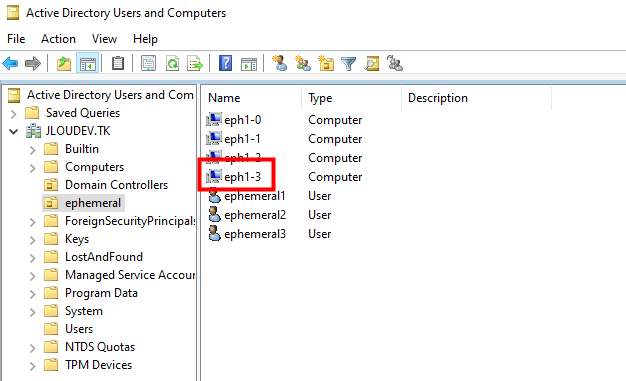
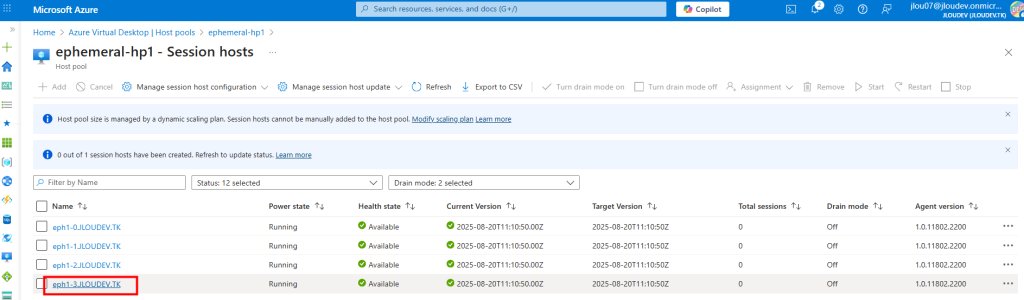
Elle est aussi intégrée automatiquement au host pool d’AVD, et devient accessible :
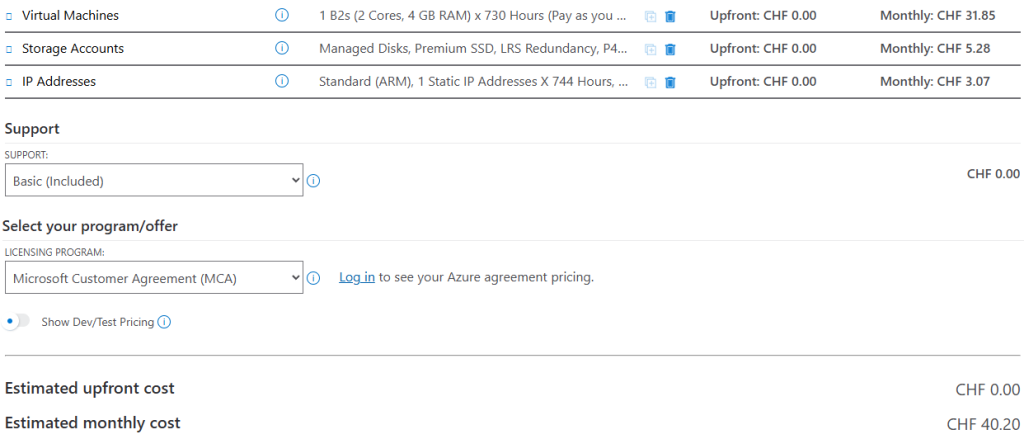
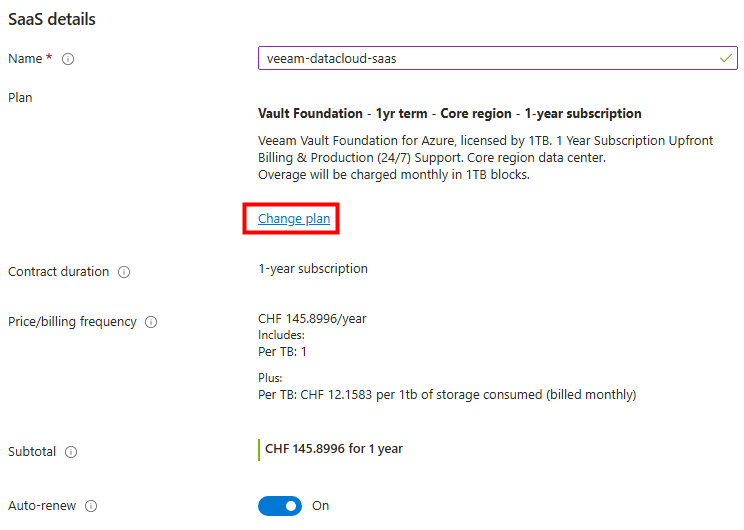
Voici le coût estimé par Azure Pricing Calculator pour un service NAT Gateway et son IP publique :
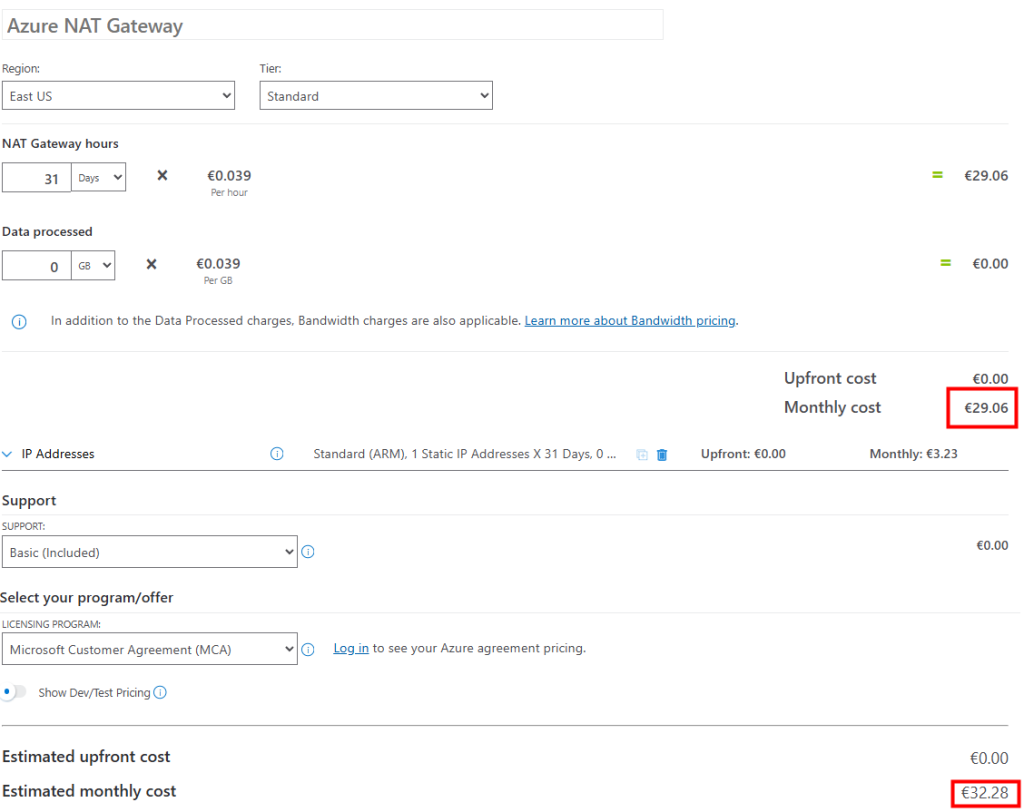
L’Azure NAT Gateway est un service géré qui permet aux machines virtuelles dans un sous-réseau privé de sortir sur Internet de manière sécurisée, performante et scalable.
Continuons avec le service Azure Firewall.
Test VI – Connexion internet avec Azure Firewall :
Je crée un 4ᵉ sous-réseau privé dédié cette fois à un test avec Azure Firewall :
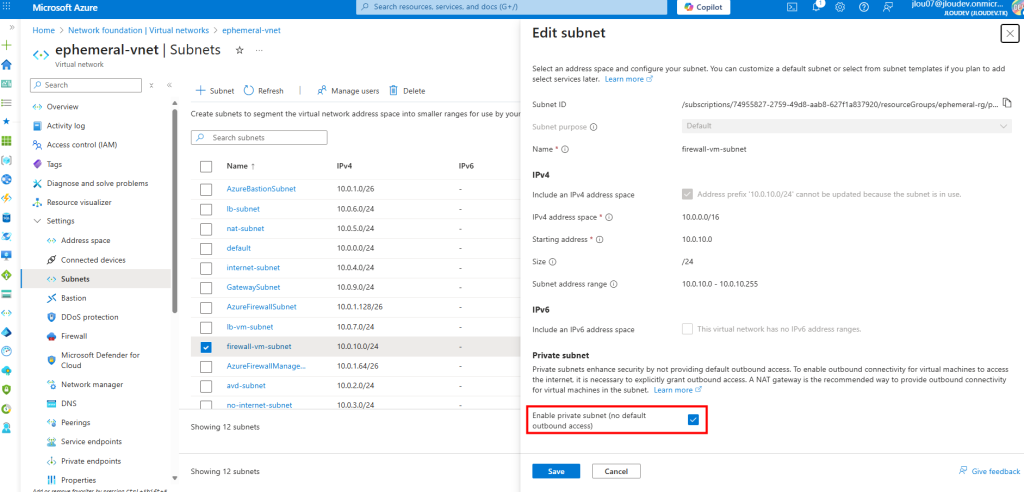
Je crée aussi le sous-réseau spécifique réservé au service Azure Firewall :
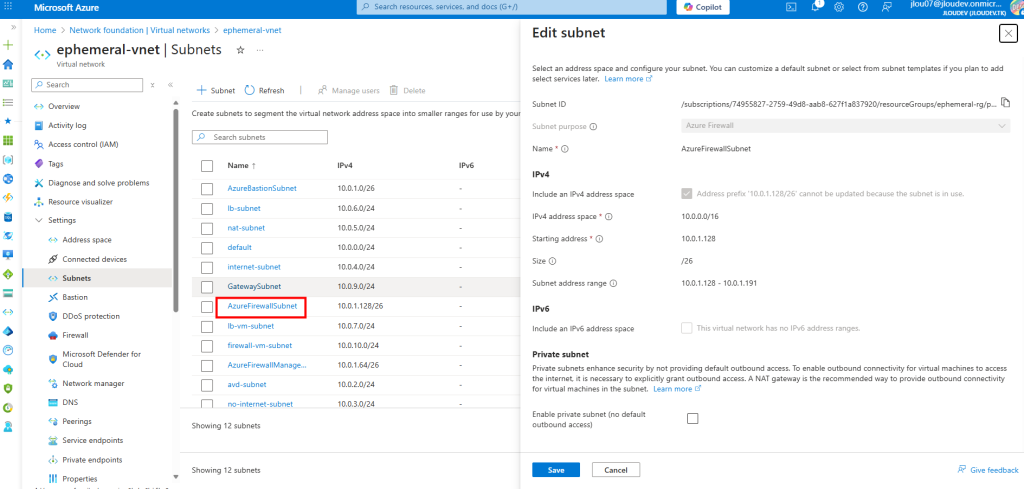
Je déploie un Azure Firewall en SKU Basique pour ce test :
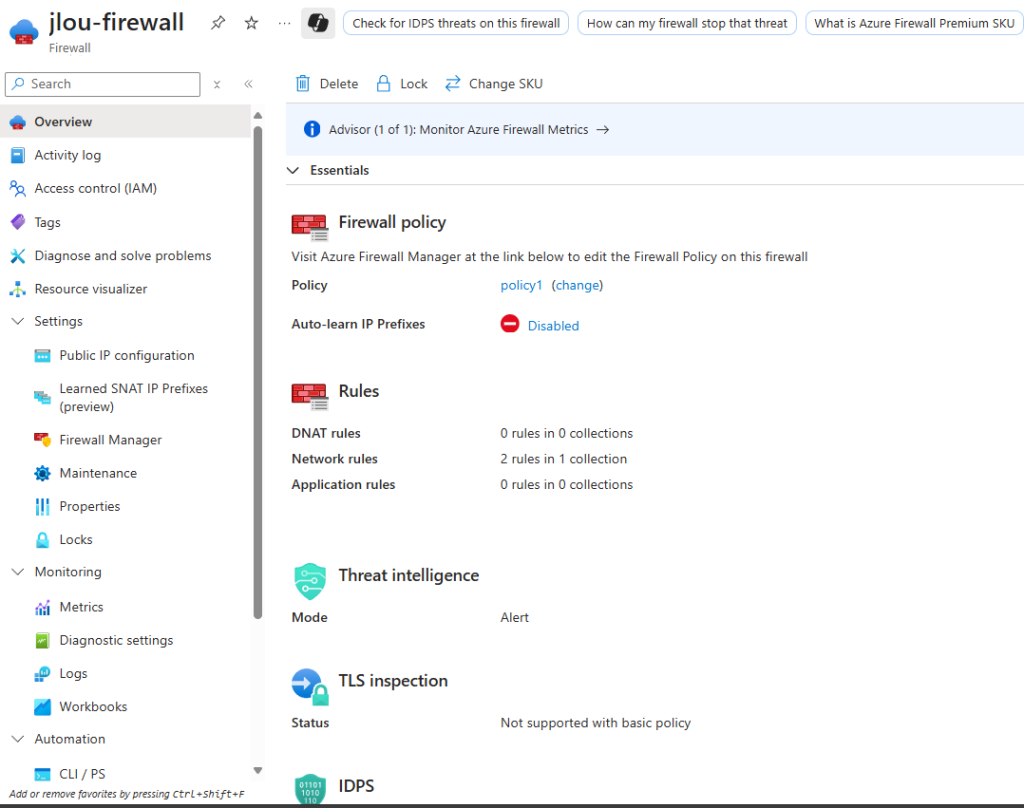
Deux adresses IP publiques sont automatiquement créées pour le Firewall :
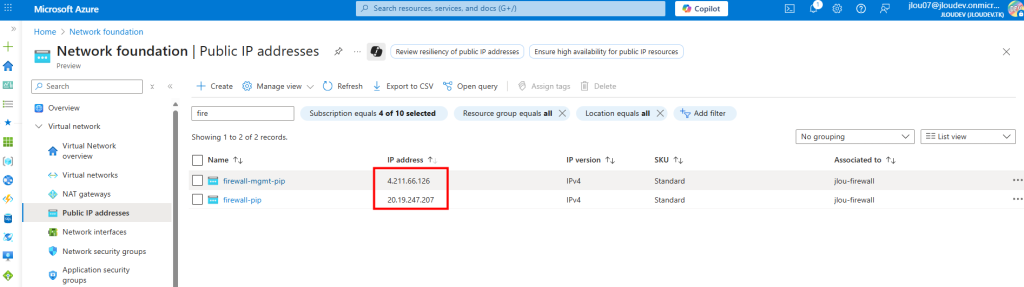
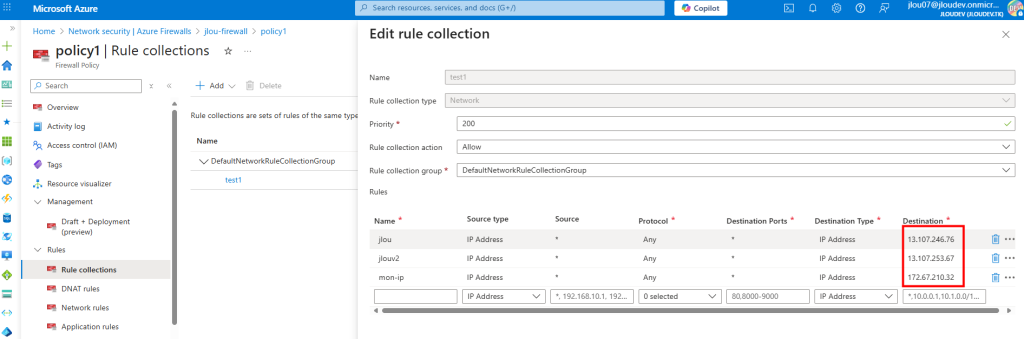
Je configure une Firewall Policy avec plusieurs règles et adresses IPs cibles :
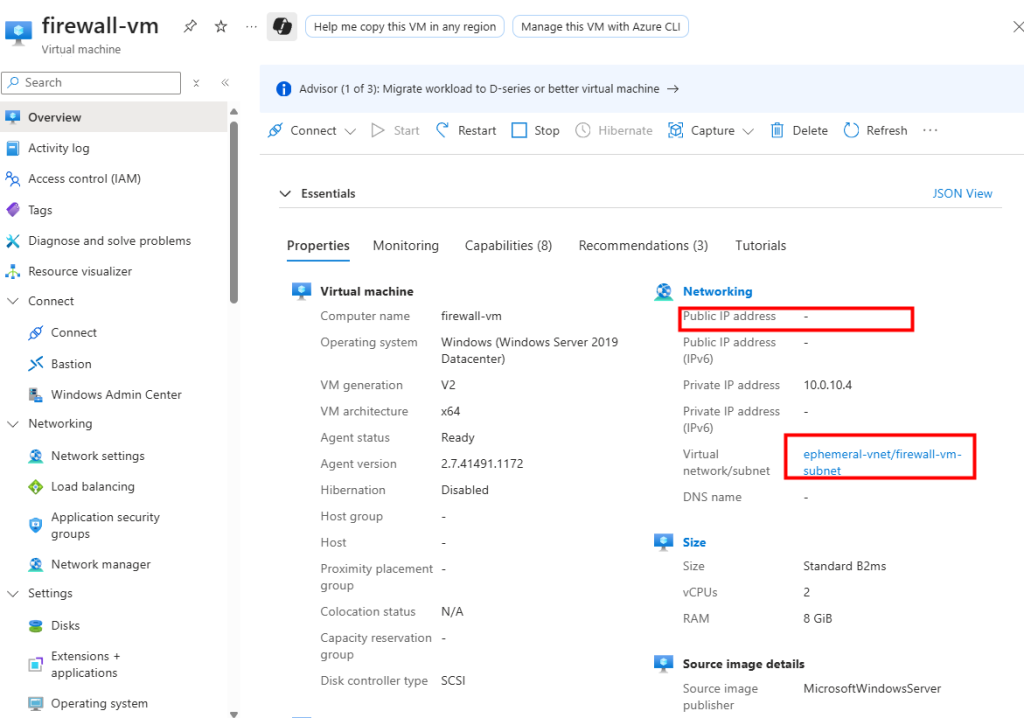
Je crée une nouvelle machine virtuelle sur ce nouveau sous-réseau privé :
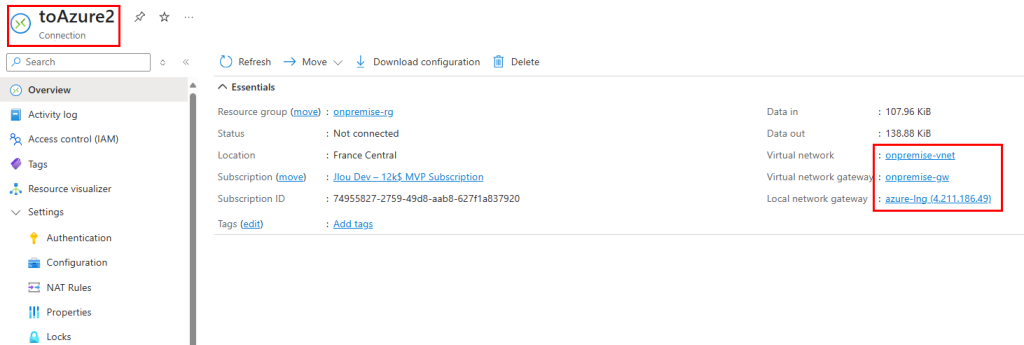
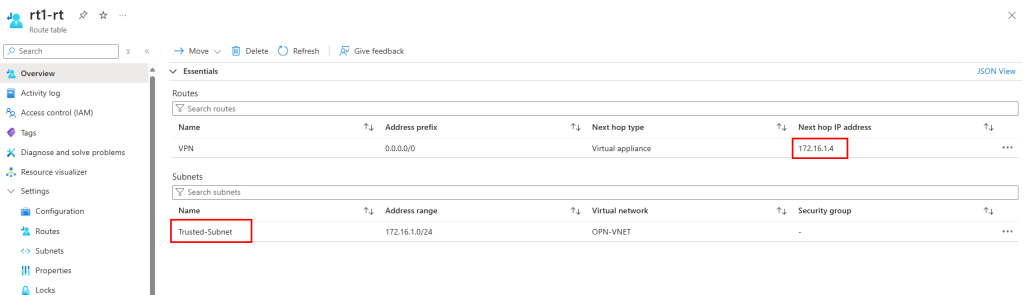
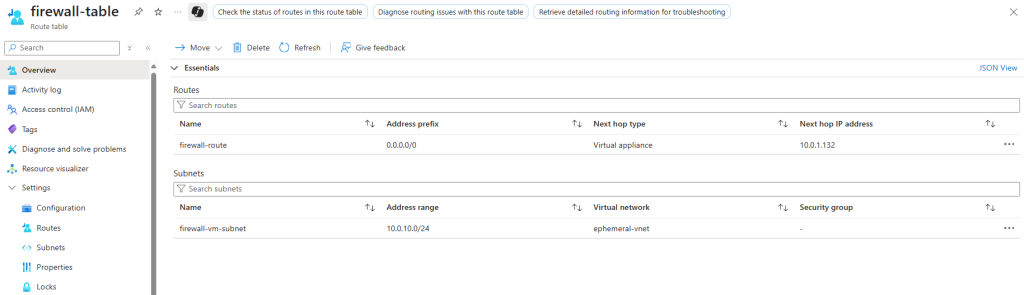
Enfin je crée une table de routage associée à mon sous-réseau virtuel de test, dont le prochain saut envoie tout le trafic sortant vers l’adresse IP privée de mon Firewall Azure :
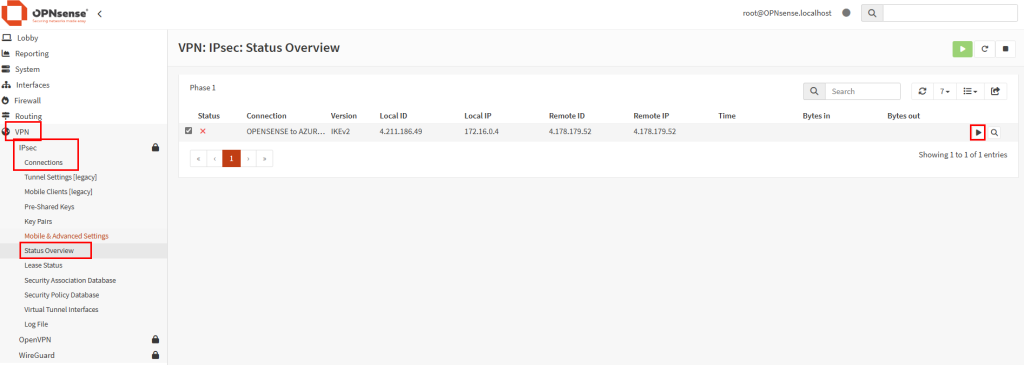
Les tests montrent que la sortie Internet se fait bien via l’IP publique de l’Azure Firewall :

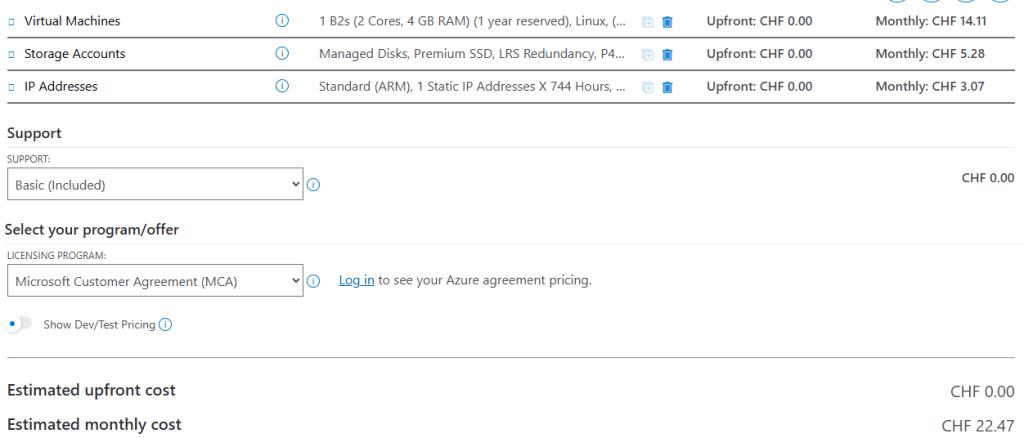
Voici le coût estimé par Azure Pricing Calculator pour un service Azure Firewall et ses deux adresses IP publiques :
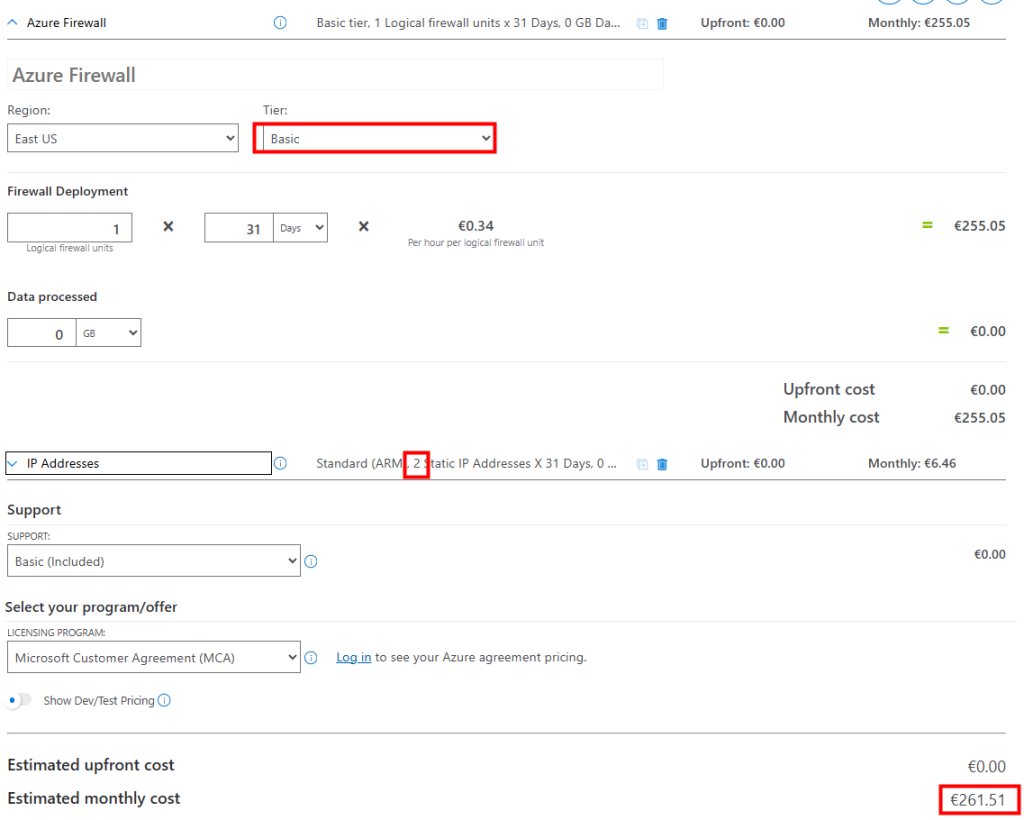
L’Azure Firewall a un rôle différent d’un NAT Gateway : ce n’est pas juste de la connectivité sortante, c’est une véritable appliance de sécurité managée par Microsoft. Mais d’autres appliances tierces auraient elles-aussi pu faire l’affaire.
Terminons avec un Équilibreur de charge Azure.
Test VII – Connexion internet avec Azure Load Balancer :
Je crée un 5ᵉ sous-réseau privé, cette fois pour tester Azure Load Balancer :
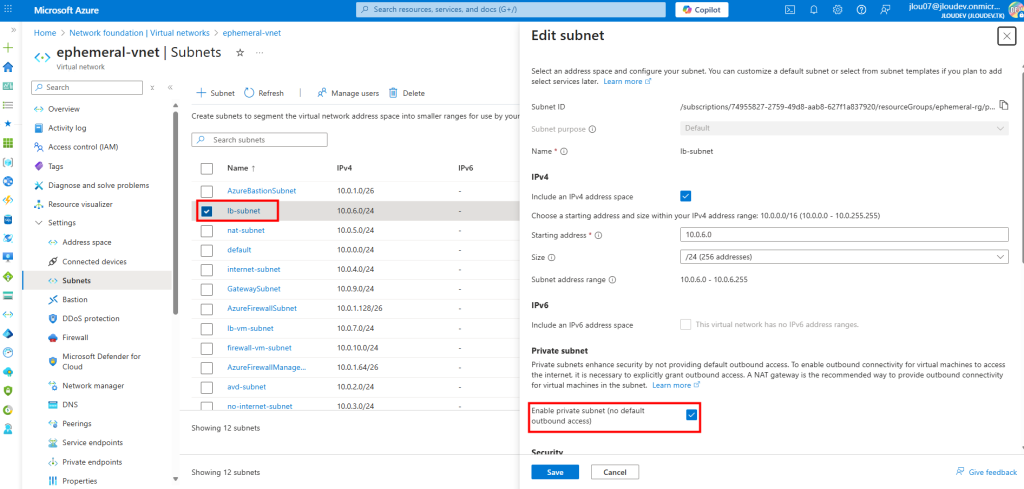
Je crée une nouvelle VM dans ce nouveau sous-réseau privé :
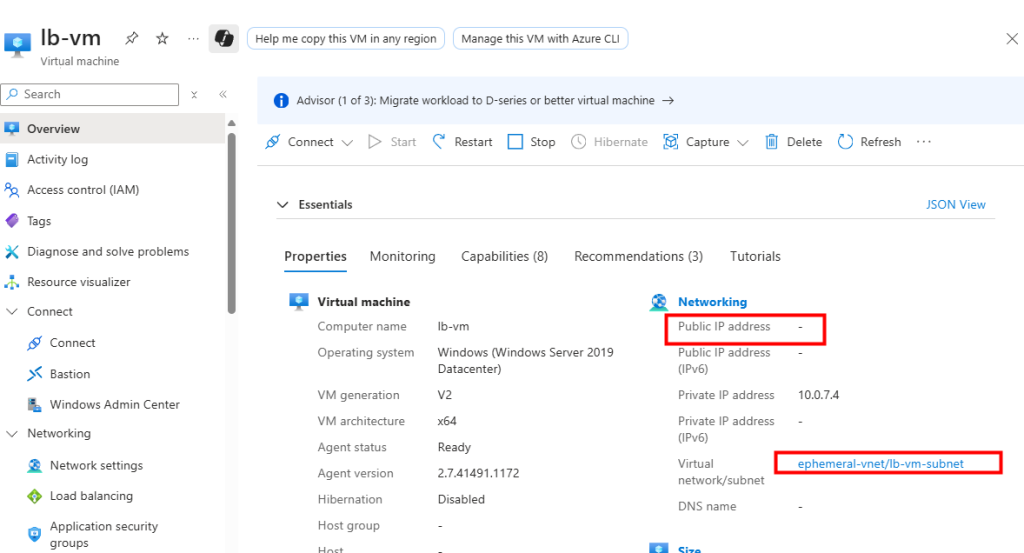
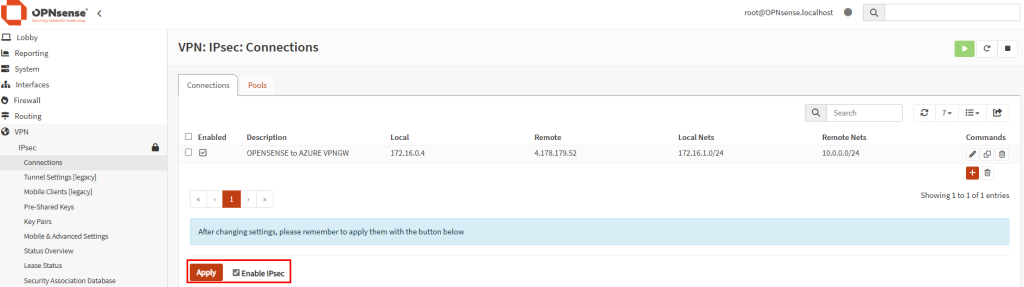
Je déploie un Équilibreur de charge et lui associe une IP publique :
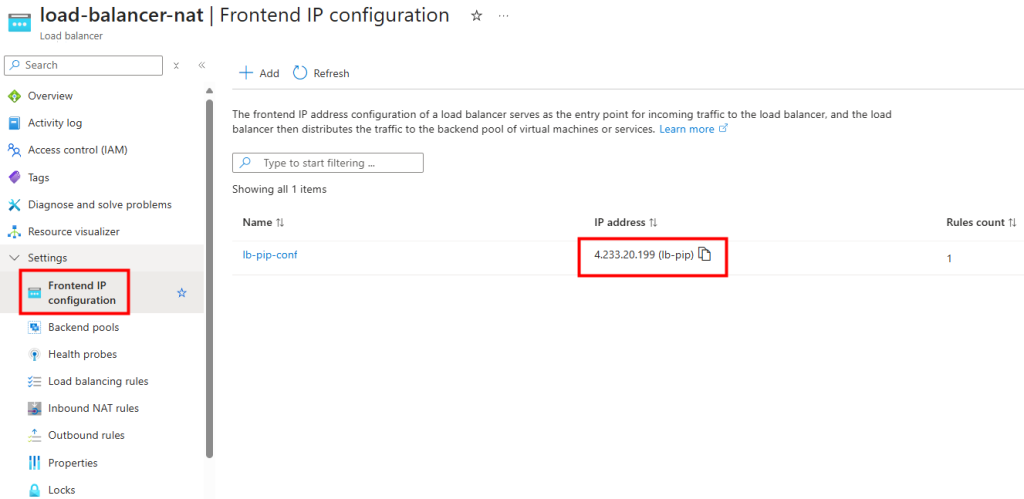
La VM est ajoutée au backend pool :
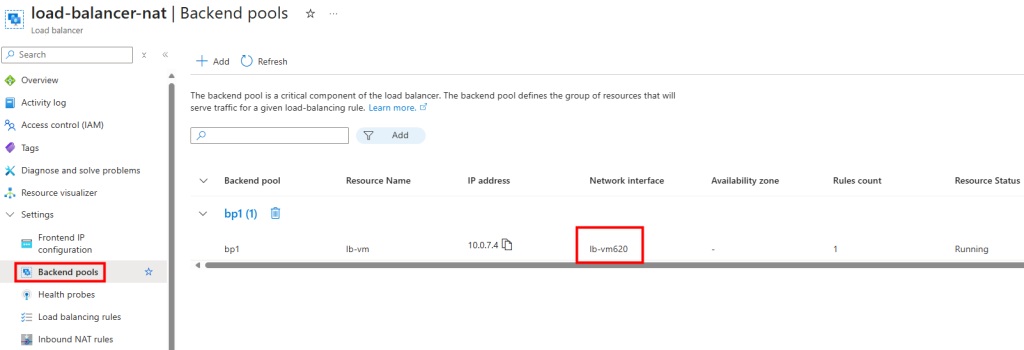
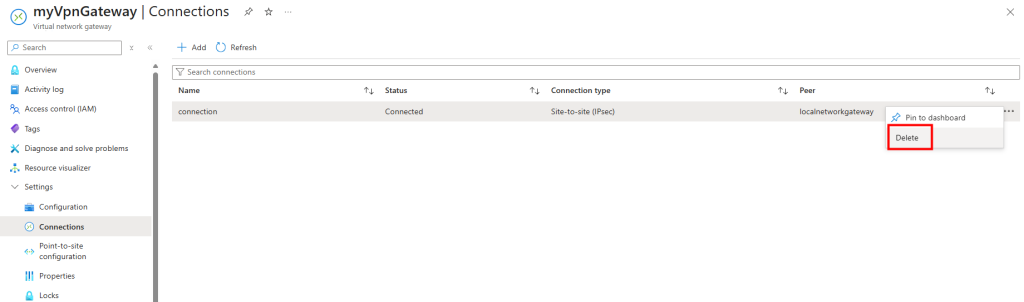
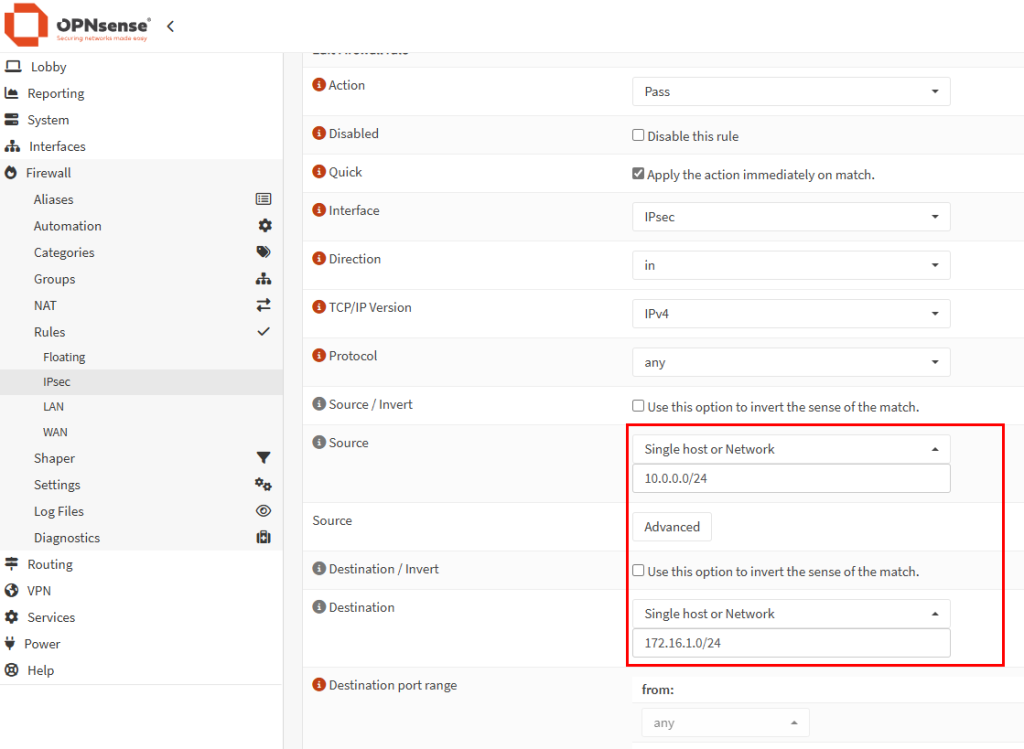
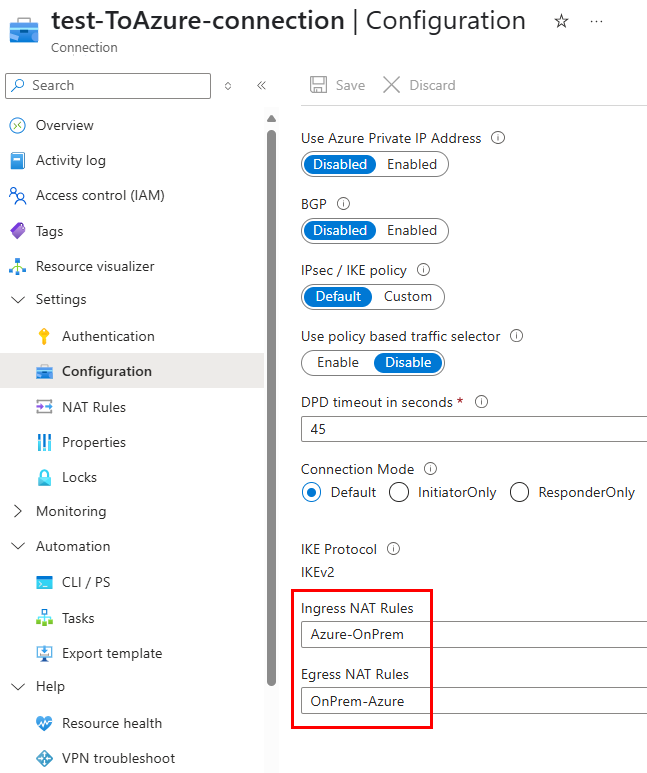
Je configure une règle SNAT de sortie sur l’Équilibreur de charge :
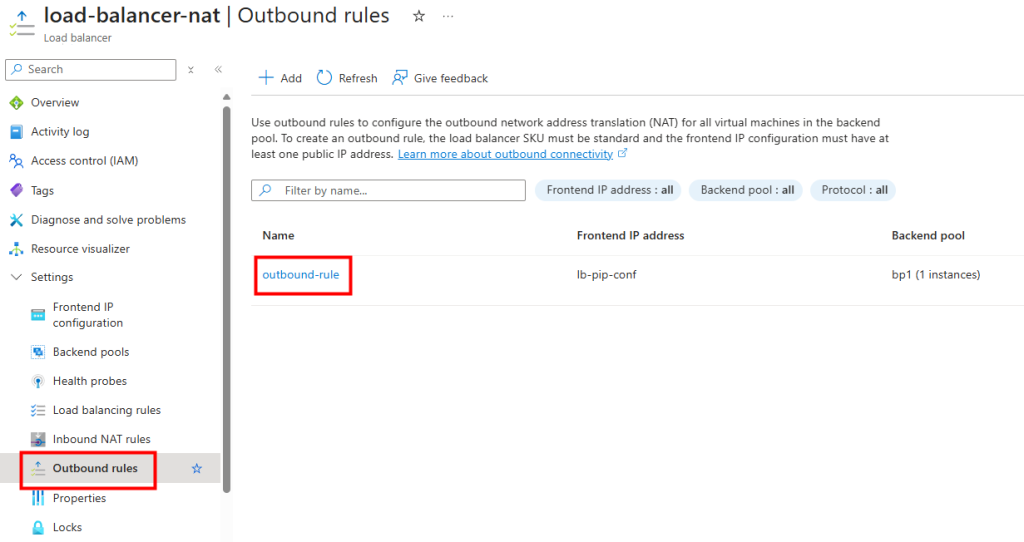
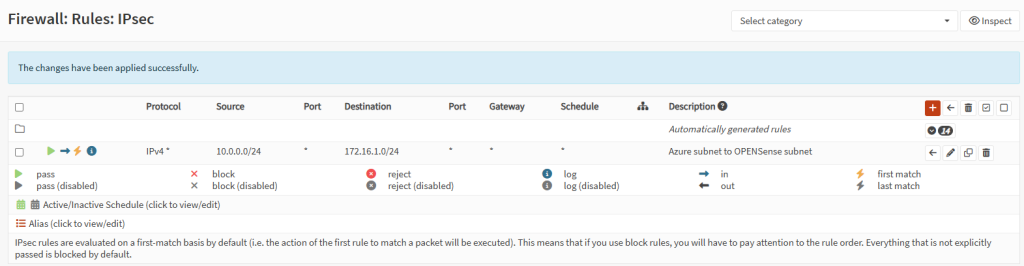
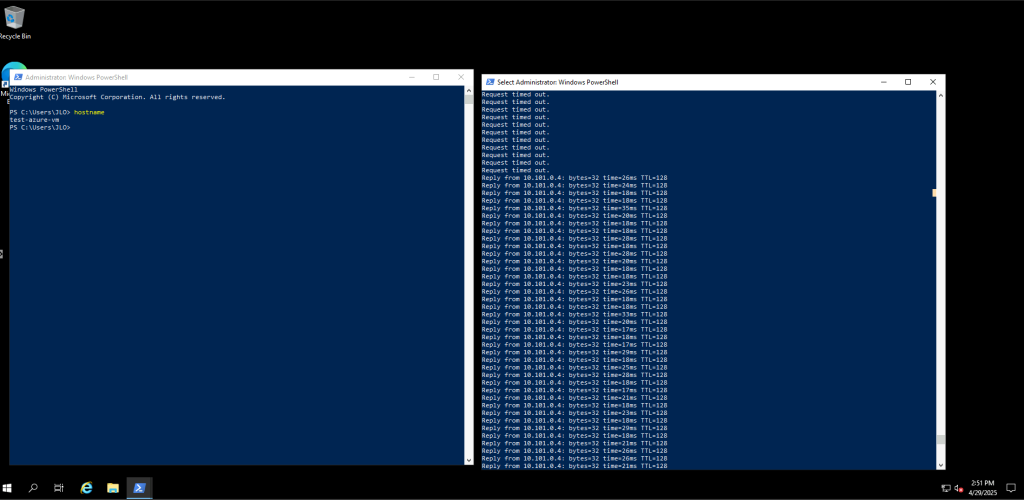
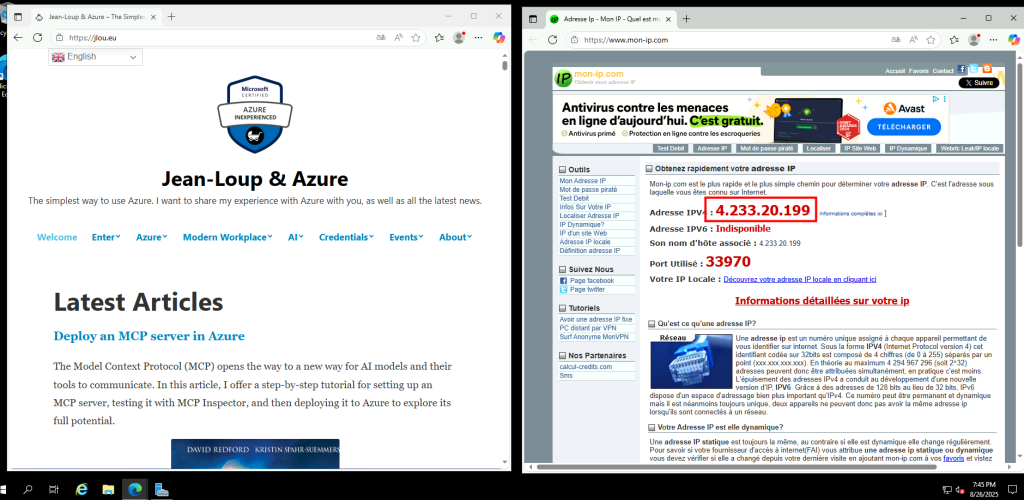
En me connectant à la VM, je constate que la sortie Internet se fait bien via l’IP publique de l’Équilibreur de charge :
Voici le coût estimé par Azure Pricing Calculator pour un Équilibreur de charge et son adresse IP publique :
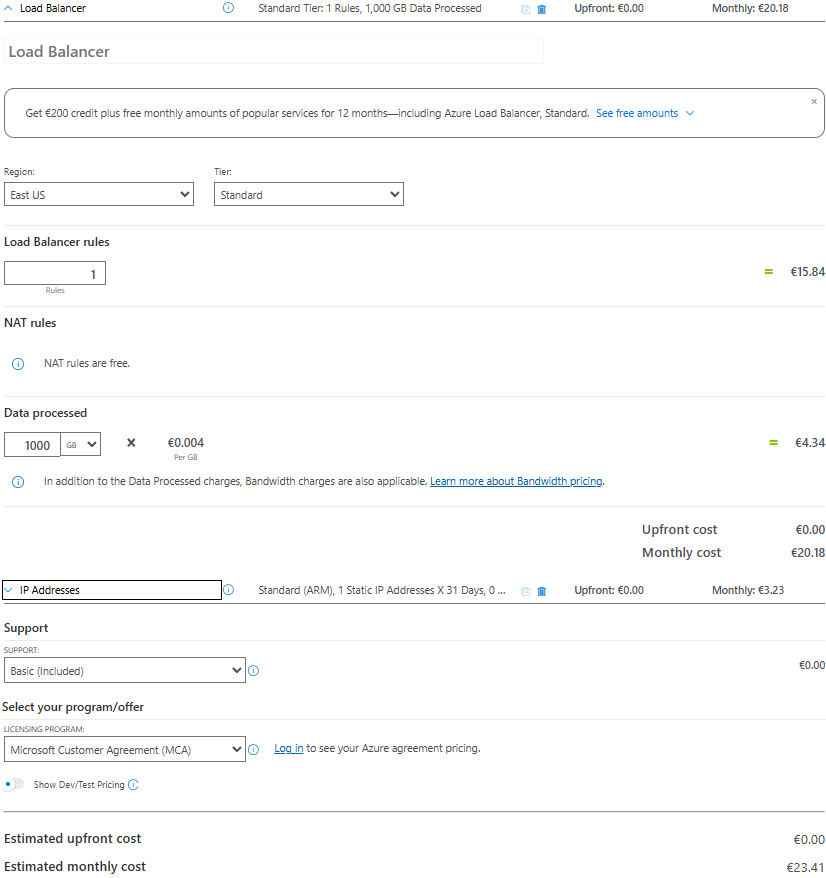
Ce service permet aux VM backend de sortir vers Internet sans IP publique dédiée, mais il est limité pour les gros volumes de connexions (NAT Gateway est plus adapté).
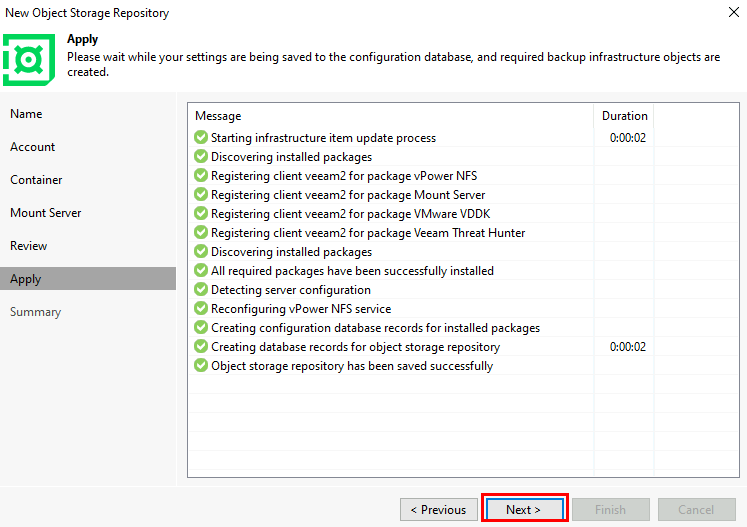
Conclusion
La fin de l’Accès sortant par défaut marque une étape clé dans la maturité du cloud Azure. Fini les “raccourcis” implicites : désormais, chaque sortie vers Internet devra être pensée, tracée et gouvernée.
Ce changement n’est pas une contrainte, mais une opportunité :
- Opportunité de renforcer la sécurité en éliminant des flux fantômes.
- Opportunité d’améliorer la stabilité et la prévisibilité des intégrations.
- Opportunité de consolider vos architectures autour de designs réseau clairs, basés sur NAT Gateway, Azure Firewall ou un Équilibreur de charge.