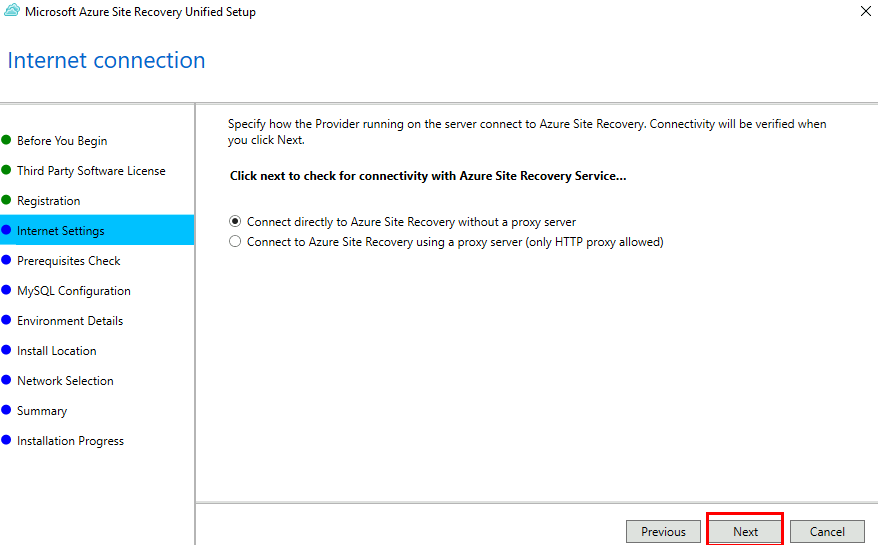
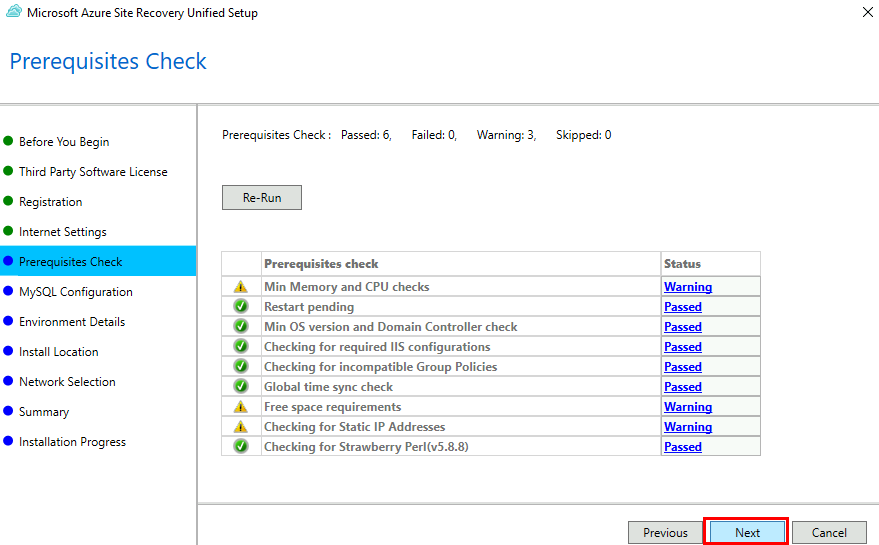
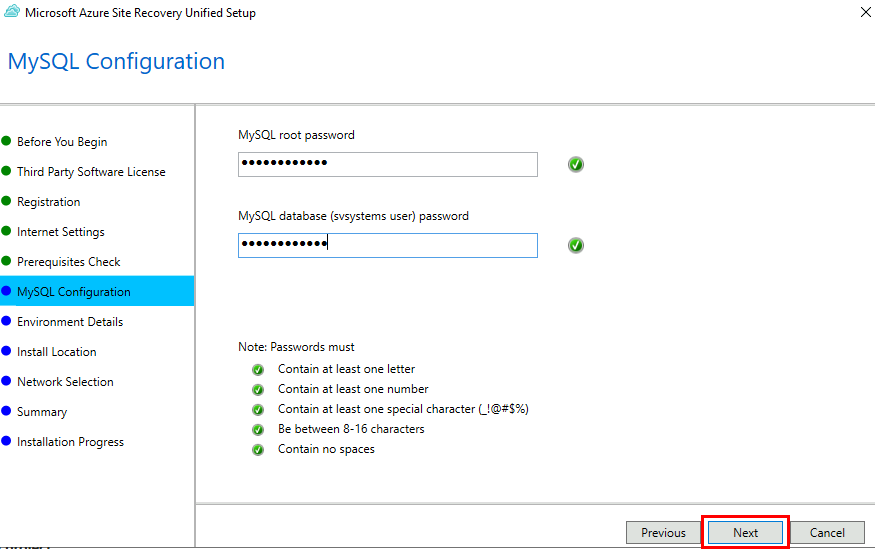
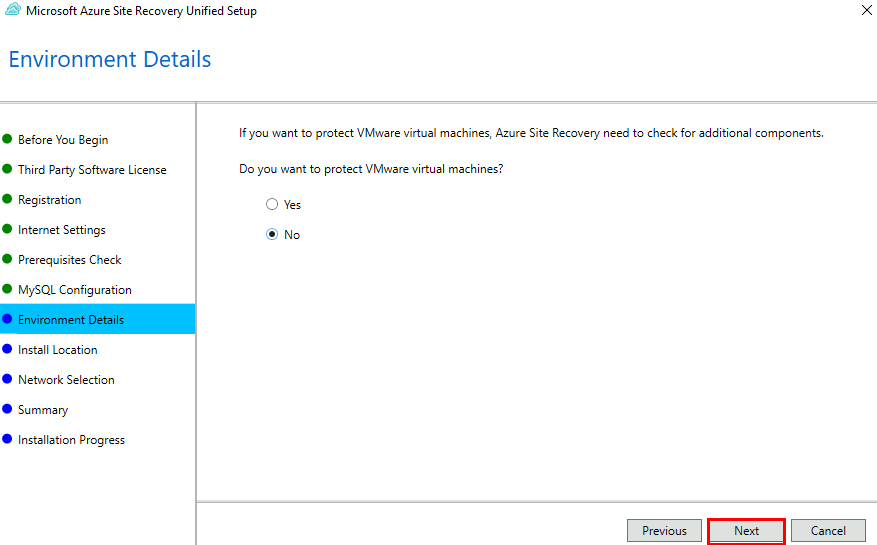
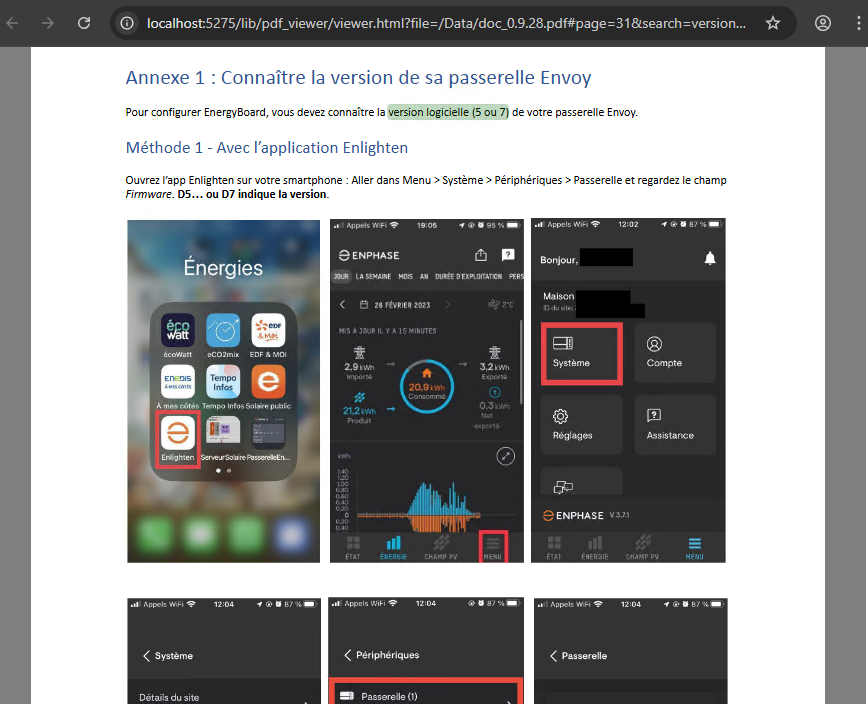
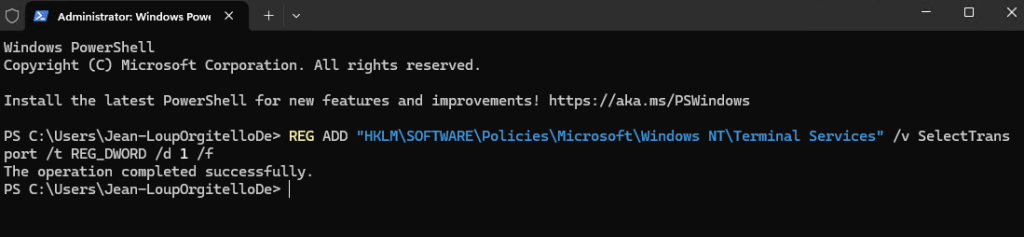
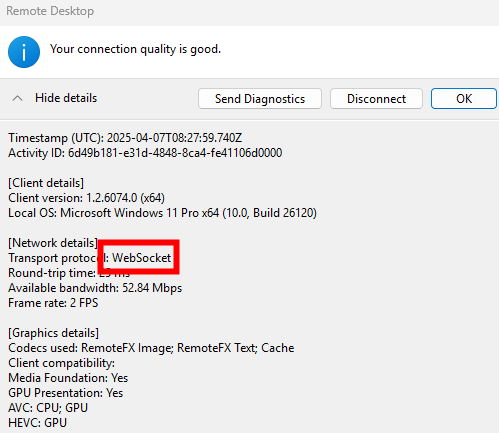
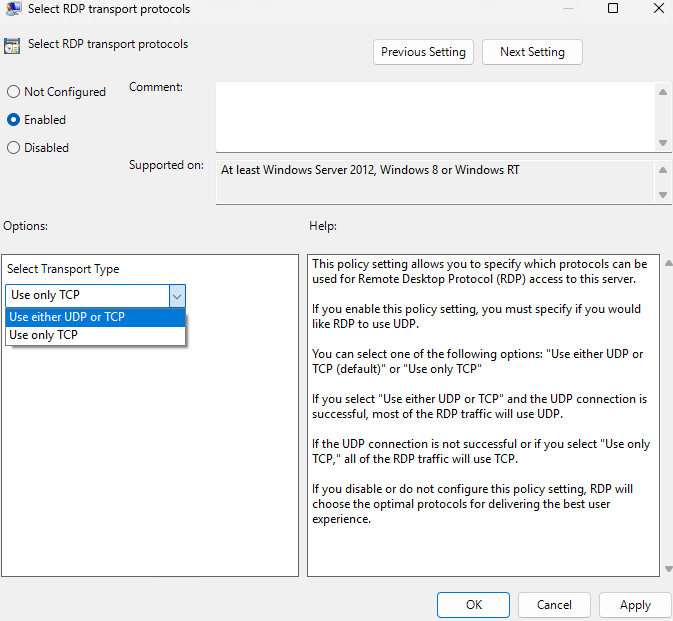
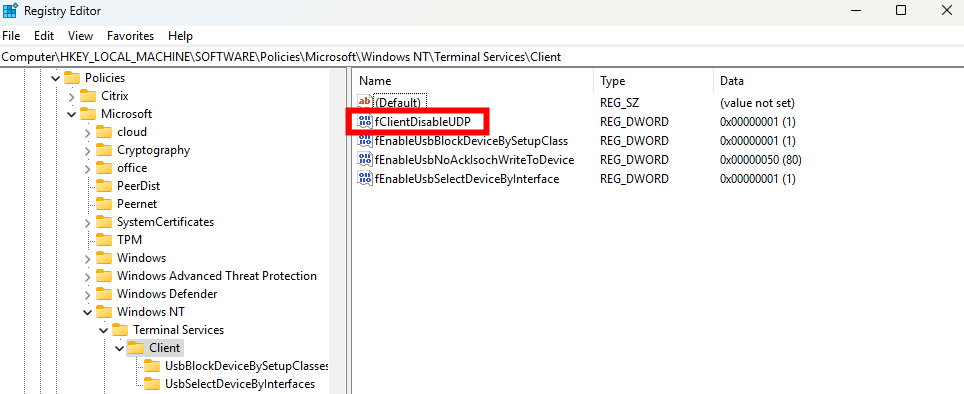
EnergyBoard peut être déployé aussi bien dans le cloud, via une machine virtuelle Azure, que sur un serveur local compact comme un Raspberry Pi 5. Dans les deux cas, il faudra passer par quelques manipulations en ligne de commande (installation de Node.js, configuration du service, ouverture des ports, etc.) pour lancer et sécuriser le serveur. Sur Azure, vous bénéficiez de la haute disponibilité sans contrainte matérielle, mais vous resterez cantonné aux appels API cloud.
Pour déployer EnergyBoard sur votre environnement (Machine virtuelle Azure ou Raspberry Pi 5), il vous faudra disposer de :
Une machine virtuelle Azure ou Raspberry Pi 5 en local
Un accès SSH à l’environnement
Installation de Teslamate réussie sur l’environnement
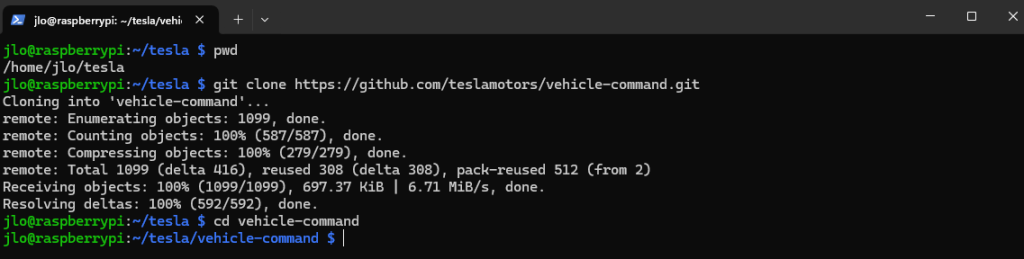
Avant de configurer EnergyBoard, commençons par copier les fichiers de l’application sur l’environnement.
Etape I – Transfert des fichiers EnergyBoard :
Créez un nouveau répertoire nommé energyboard dans le répertoire courant, puis déplacez-vous dans ce répertoire :
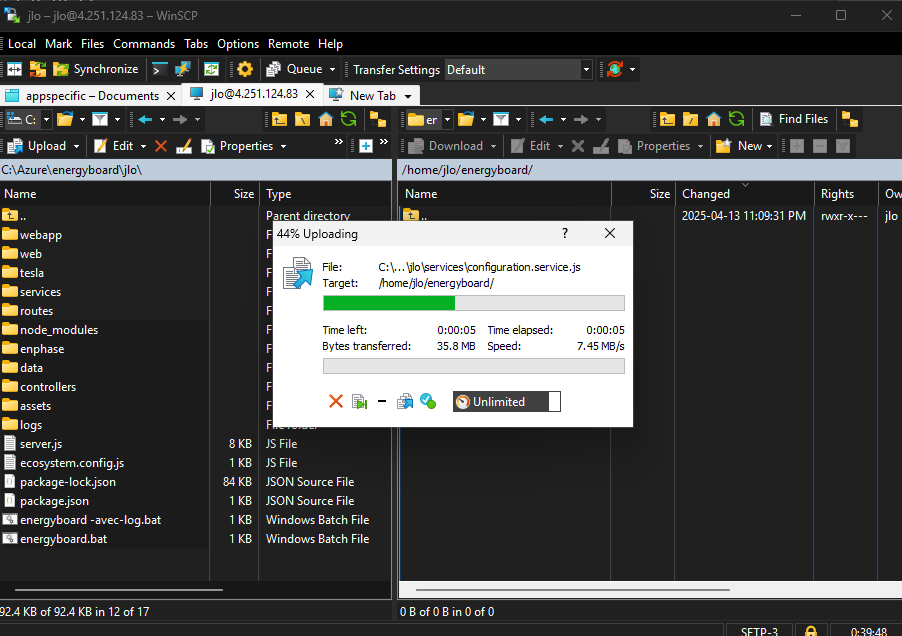
Utilisez des outils de transfert comme WinSCP, disponible à cette adresse :
Installez l’application WinSCP sur votre poste, puis authentifiez-vous à votre environnement via le protocol SFTP :
Copiez le contenu du fichier ZIP dans le dossier energyboard créé précédemment :
Avant de pouvoir démarrer l’application EnergyBoard, d’autres composants doivent être mis à jour sur notre environnement.
Etape II – Mise à jour de l’environnement :
Téléchargez et synchronisez la liste des paquets disponibles à partir des dépôts configurés sur votre environnement, permettant ainsi à apt de connaître les versions les plus récentes des logiciels et leurs dépendances avant une installation ou mise à jour :
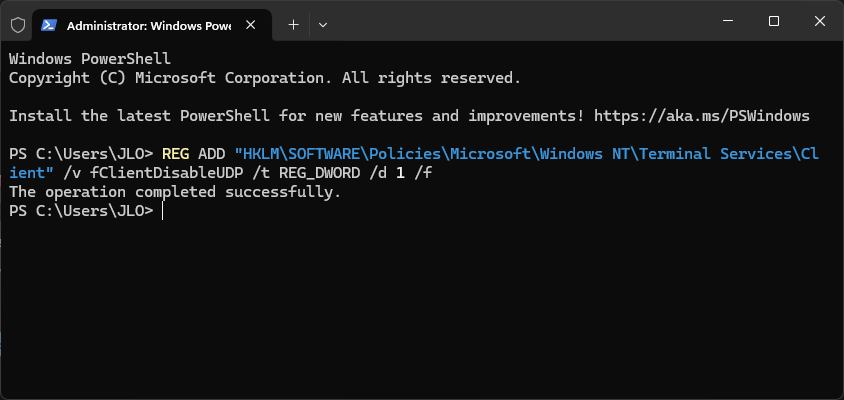
sudo apt update
Installez les 2 logiciels essentiels pour notre application EnergyBoard tournant sous JavaScript :
nodejs : C’est l’environnement d’exécution permettant d’exécuter du code JavaScript côté serveur.
npm (Node Package Manager) : C’est le gestionnaire de paquets associé à Node.js, qui facilite l’installation, la mise à jour et la gestion des modules et bibliothèques JavaScript.
sudo apt install nodejs npm
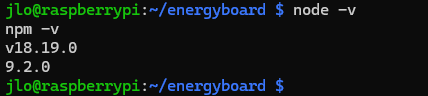
Affichez les versions installées :
node -v
npm -v
Installez également PM2. Ce dernier est un outil qui permet de gérer, superviser et redémarrer automatiquement vos applications Node.js en production.
sudo npm install -g pm2
Ensuite, passer la commande suivante :
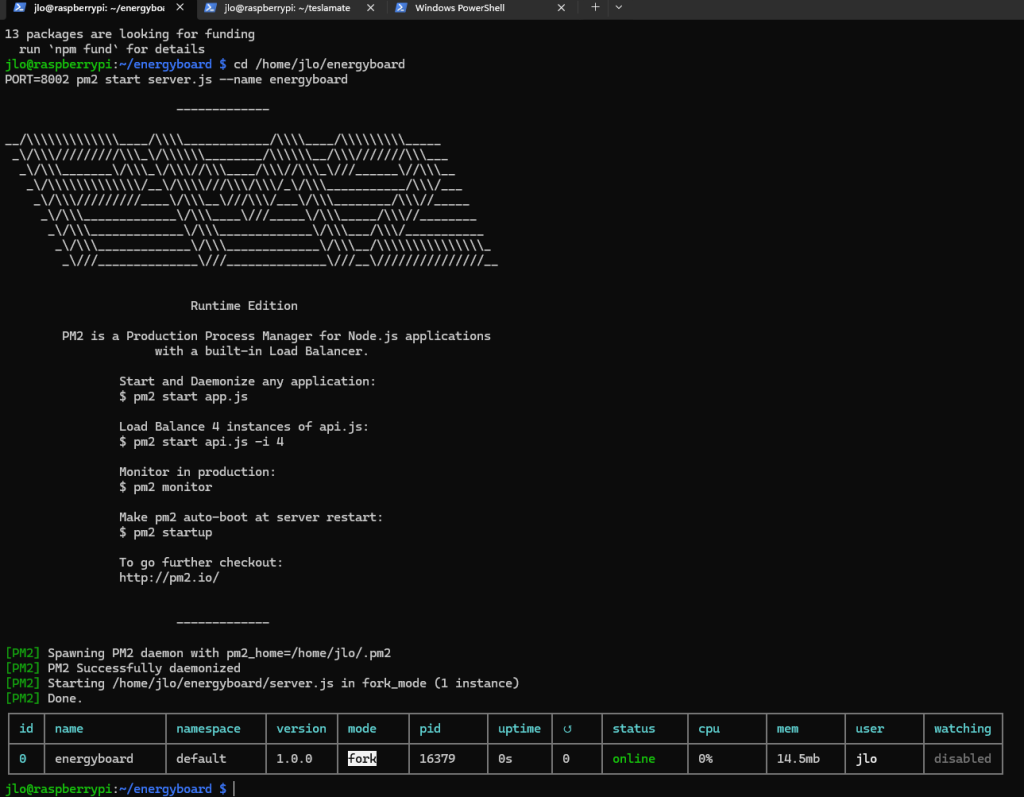
PORT=8002 pm2 start server.js --name energyboard
Celle-ci définit d’abord la variable d’environnement PORT sur 8002, puis lance le script server.js avec PM2, en lui attribuant le nom energyboard pour faciliter sa gestion (surveillance, redémarrage automatique, etc.) :
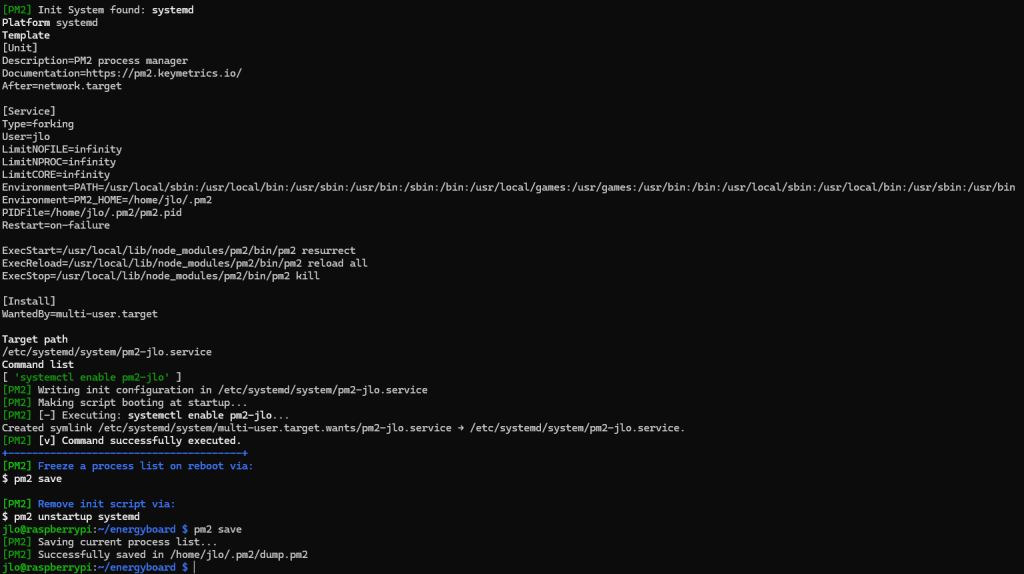
Configurez votre environnement pour démarrer automatiquement PM2 au démarrage de ce dernier :
pm2 startup
Enregistrez l’état actuel de vos applications surveillées par PM2 :
pm2 save
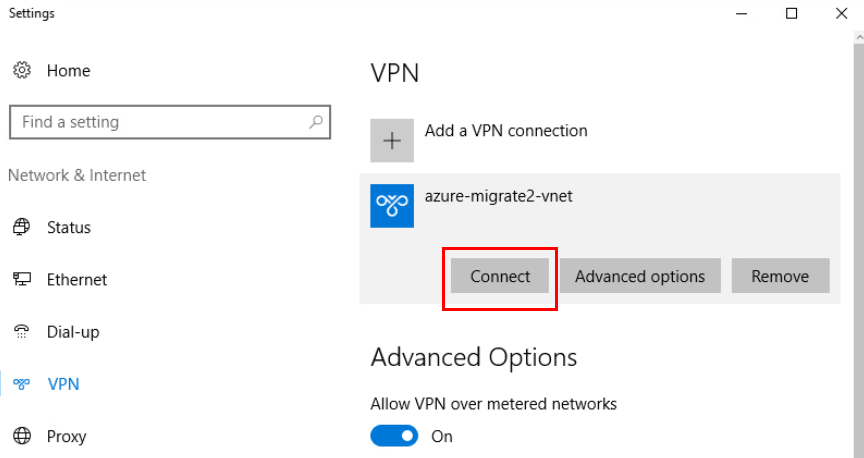
Ouvrez un navigateur internet afin d’accéder à votre application EnergyBoard :
http://4.251.124.83:8002/
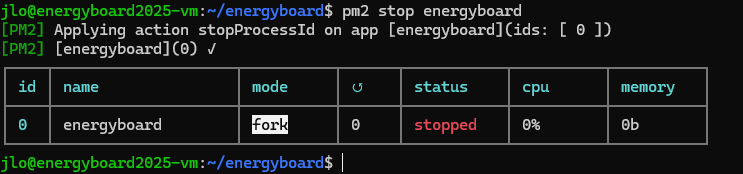
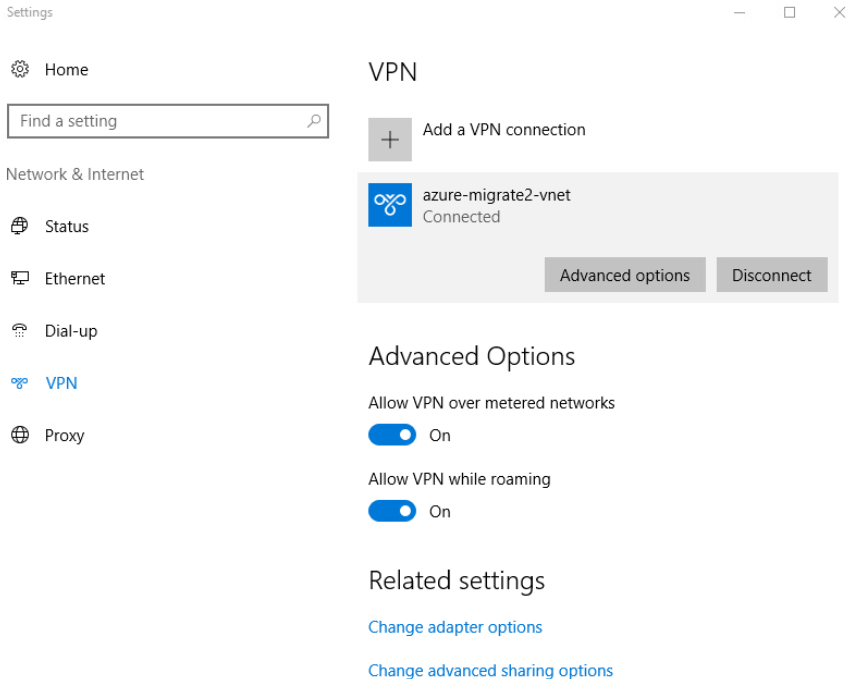
Si celle-ci démarre bien, retournez sur votre environnement pour arrêter l’application afin de terminer la configuration :
pm2 stop energyboard
Retournez sur WinSCP afin d’éditer le nouveau fichier de configuration, présent dans le dossier suivant :
energyboard/assets/conf/config.json
Double-cliquez pour modifier ce fichier :
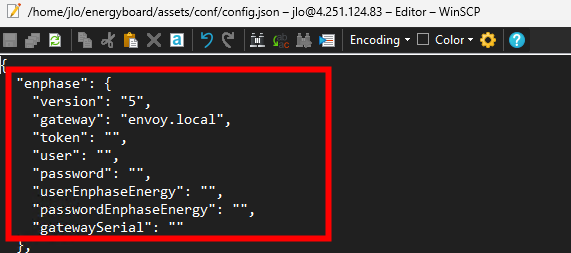
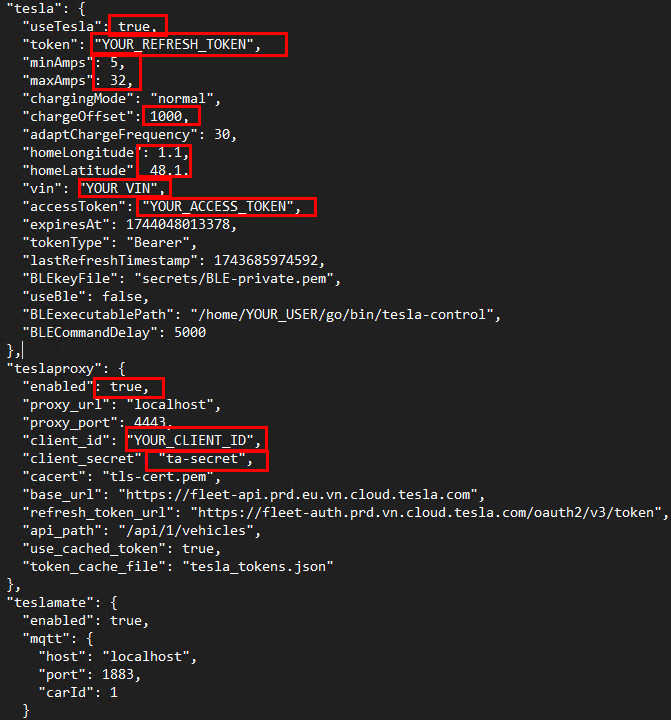
Configurez les éléments liés à votre installation Enphase :
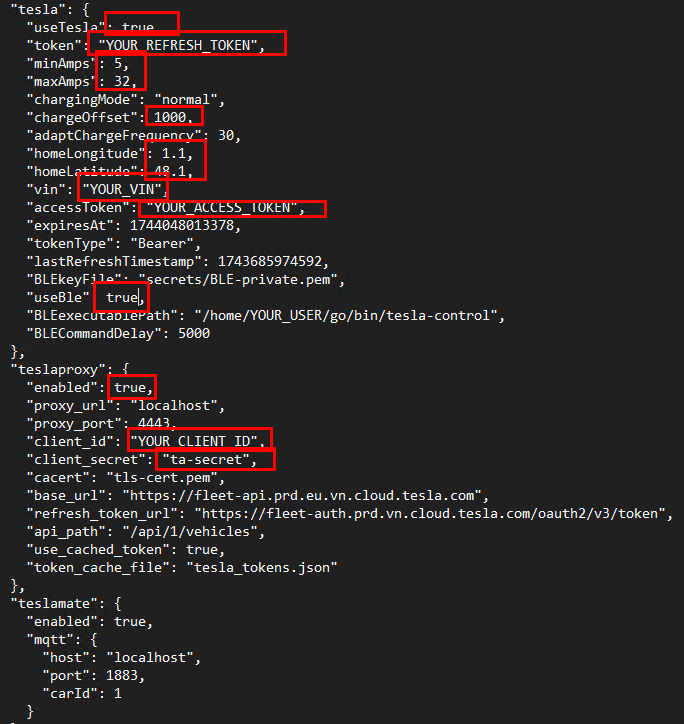
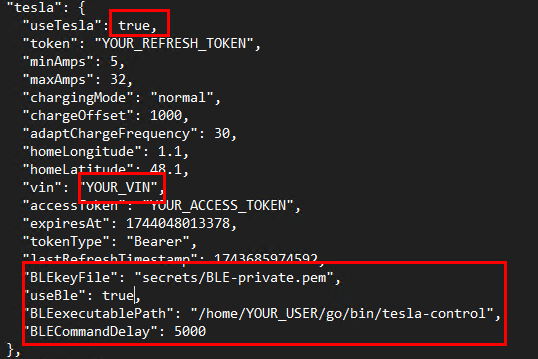
Si vous souhaitez communiquez à votre Tesla uniquement via BLE :
Suivez la procédure de configuration BLE
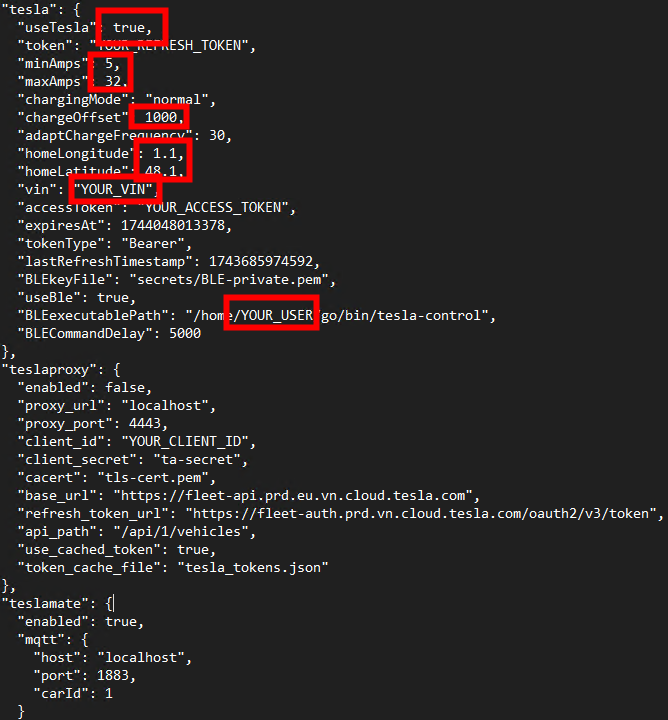
Configurez les éléments suivants :
Si vous souhaitez communiquez à votre Tesla uniquement via API :
Suivez la procédure de configuration API
Configurez les éléments suivants :
Si vous souhaitez communiquez à votre Tesla via API et BLE :
Suivez la procédure de configuration API
Suivez la procédure de configuration BLE
Configurez les éléments suivants :
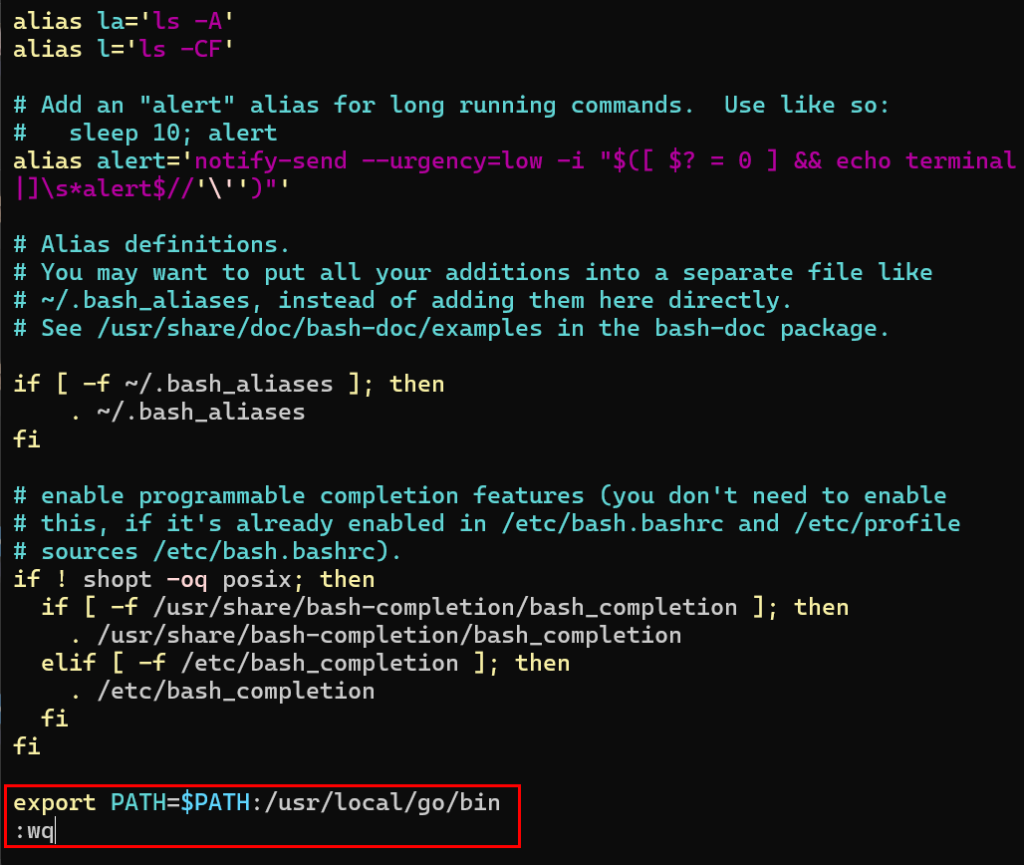
Pensez à sauvegarder le fichier de configuration via la commande suivante :
:wq
Redémarrer une fois les conteneurs Docker :
docker compose restart
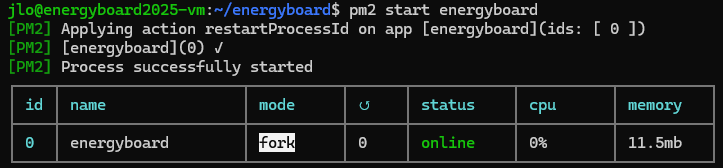
Démarrer l’application EnergyBoard :
pm2 start energyboard
Rouvrez un navigateur internet afin d’accéder à votre application EnergyBoard :
EnergyBoard est maintenant installé, vous pouvez passer à l’étape suivante, consistant à installer et configurer la liaison Bluetooth avec la Tesla. Cette dernière va nous permettre de :
Envoyer des ordres Tesla via BLE grâce l’’agent ‘application Tesla-command
Cette étape est probablement la plus délicate de tout le processus. Prenez le temps de bien respecter les différentes opérations pour assurer un enrôlement réussi de votre API auprès de chez Tesla.
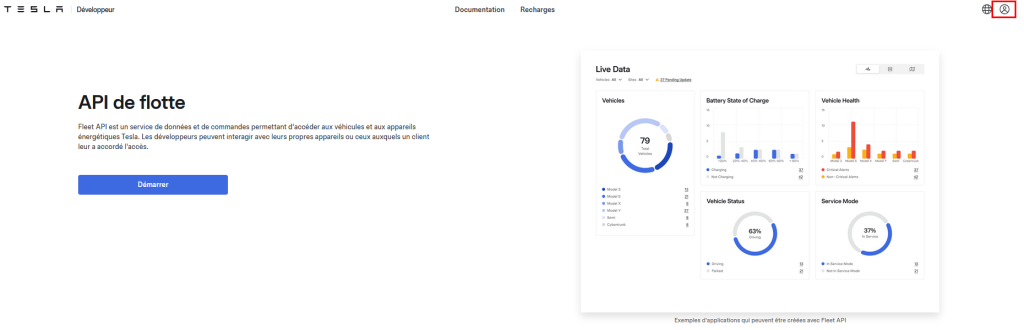
Qu’est-ce que Fleet API ?
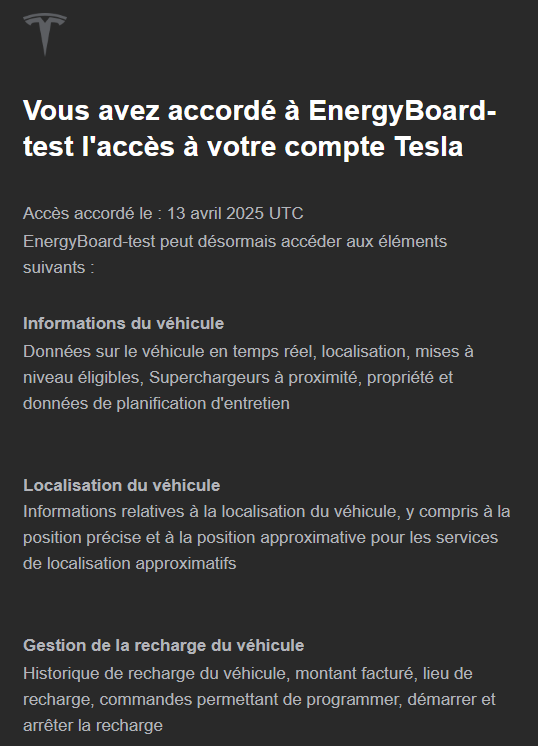
Fleet API est un service de données et de commande qui donne accès aux véhicules Tesla, à l’énergie et à d’autres types d’appareils. Les partenaires peuvent interagir avec leurs propres appareils ou avec les appareils auxquels un client leur a donné accès.
Suivez le processus d’intégration ci-dessous pour vous inscrire et obtenir une clé API afin d’interagir avec les points d’extrémité de l’API de Tesla. Les applications peuvent demander aux propriétaires des véhicules l’autorisation de consulter les informations du compte, d’obtenir l’état du véhicule ou même d’émettre des commandes à distance.
Les propriétaires de véhicules contrôlent les applications auxquelles ils accordent l’accès et peuvent modifier ces paramètres à tout moment.
Pour mettre en place une connexion API sur votre environnement (Azure ou Raspberry Pi 5), il vous faudra disposer de :
Un compte Tesla
Une machine virtuelle ou Raspberry Pi 5
Un accès SSH à votre environnement
Avant de créer notre application API chez Tesla, commençons par configurer Ngork.
Etape I – Configuration de Ngrok :
Pour pouvoir enregistrer notre application chez Tesla, nous allons avoir besoin d’un domaine internet pointant sur notre clef publique.
Ngrok est un outil de tunnellisation qui permet d’exposer de manière sécurisée un serveur local à Internet via une URL publique, sans avoir à configurer manuellement votre réseau ou à ouvrir des ports dans votre pare-feu.
Pour cela, rendez-vous sur le site de Ngrok, puis inscrivez-vous chez eux afin d’avoir un compte gratuit :
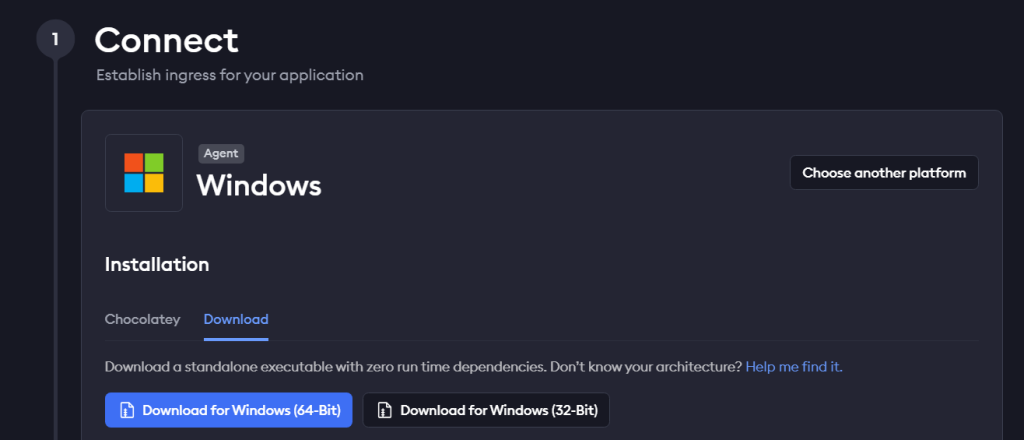
Sur leur site, téléchargez l’installateur de Ngrok selon votre OS :
Copiez la commande suivante affichée sous l’installateur pour finaliser la configuration de votre Ngrok :
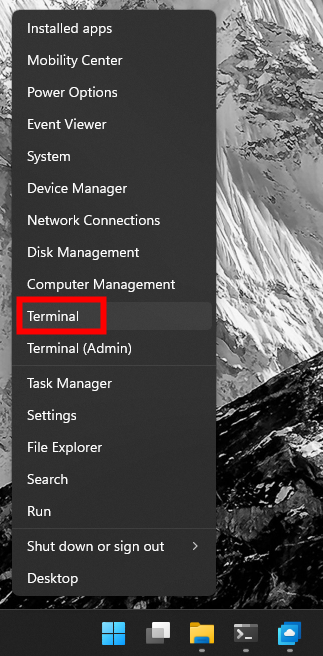
Depuis votre ordinateur, ouvrez Windows PowerShell :
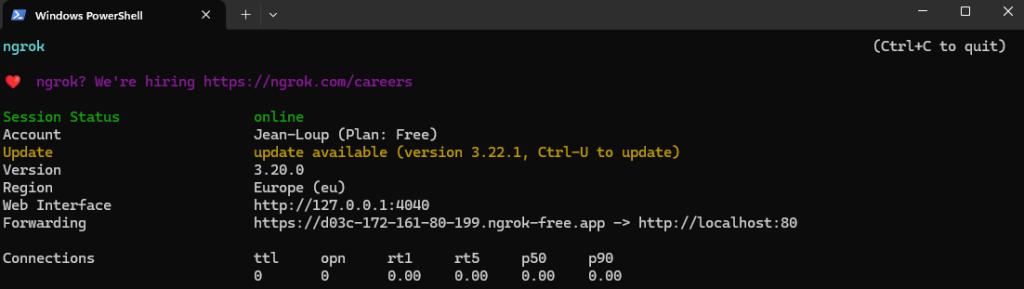
Lancez la commande précédemment copiée afin de terminer la configuration Ngrok :
Créez un tunnel ngrok sécurisé depuis Internet vers votre serveur local qui écoute sur le port 80, en générant une URL publique accessible depuis n’importe quel navigateur :
ngrok http http://localhost:80
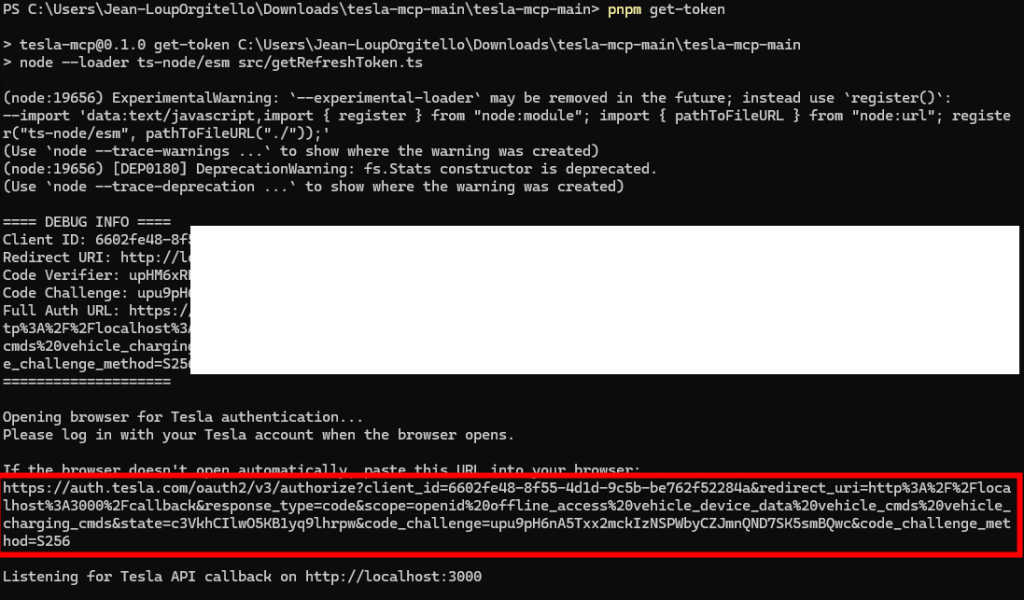
Copiez le nom de domaine commençant par httpset finissant par ngrok-fre.app. Ne fermez pas cette fenêtre tant que le processus d’enrôlement API pas entièrement fini :
Ngrok est maintenant correctement configuré. L’étape suivante consiste à enregistrer notre application chez Tesla.
Etape II – Création de l’application API chez Tesla :
Rendez-vous le portail Développeur de Tesla, accessible via l’URL Tesla suivante, puis cliquez en haut à droite :
Cliquez ici pour créer votre compte Développeur Tesla :
Créez un compte en renseignant les champs de base, puis cliquez sur Suivant :
Renseignez votre mail ainsi qu’un mot de passe fort, puis cliquez sur Suivant :
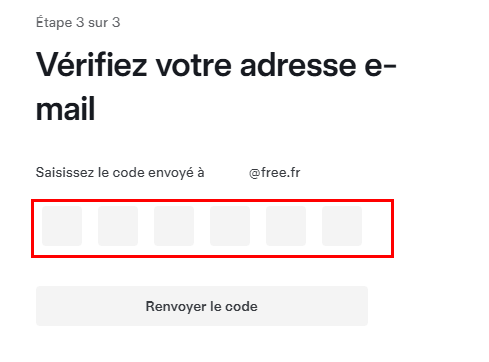
Vérifiez votre compte via la réception d’un code par email :
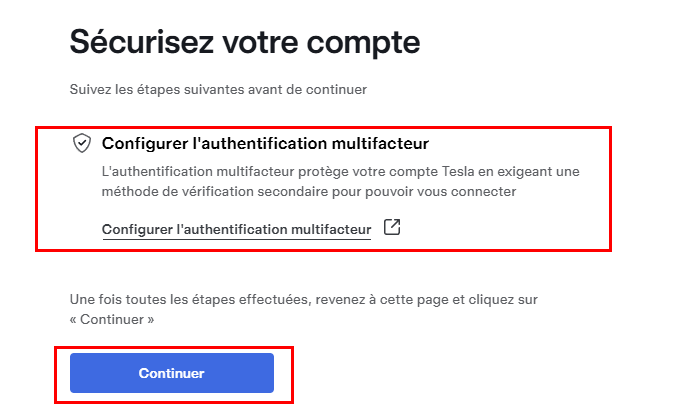
Cliquez sur le bouton de configuration de la 2FA pour sécuriser votre compte, puis cliquez sur Continuer une fois l’enrôlement de la 2FA terminé :
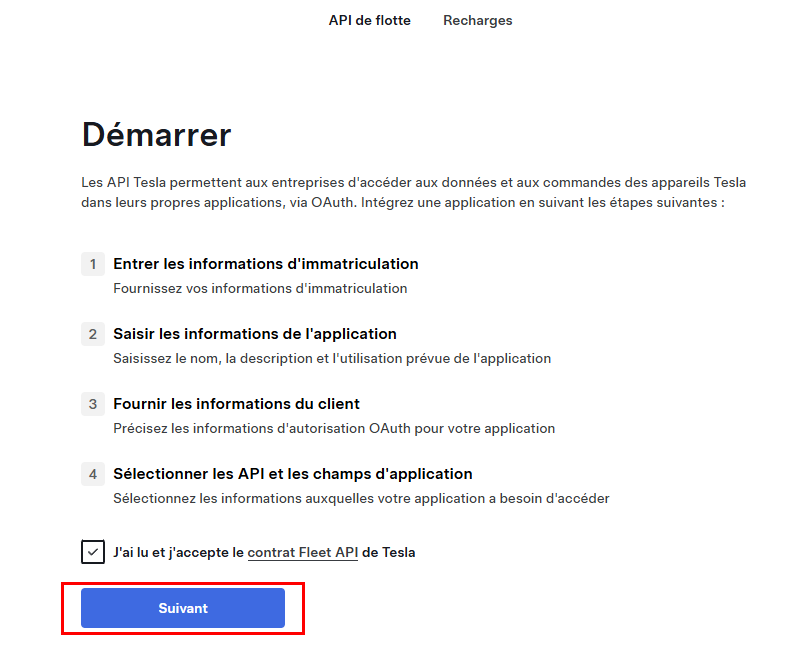
Acceptez les conditions, puis cliquez sur Suivant :
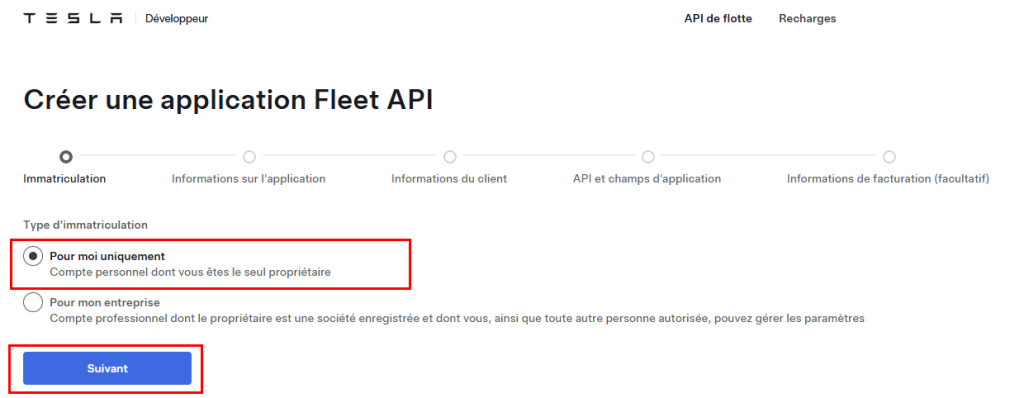
Choisissez le premier choix, puis cliquez sur Suivant :
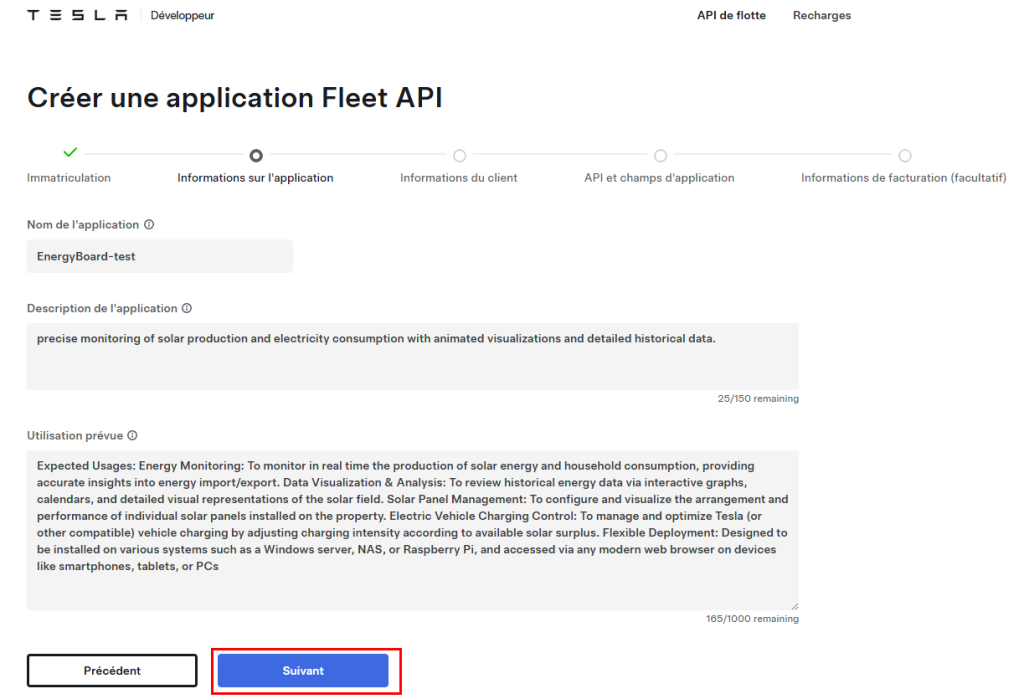
Renseignez tous les champs, puis cliquez sur Suivant :
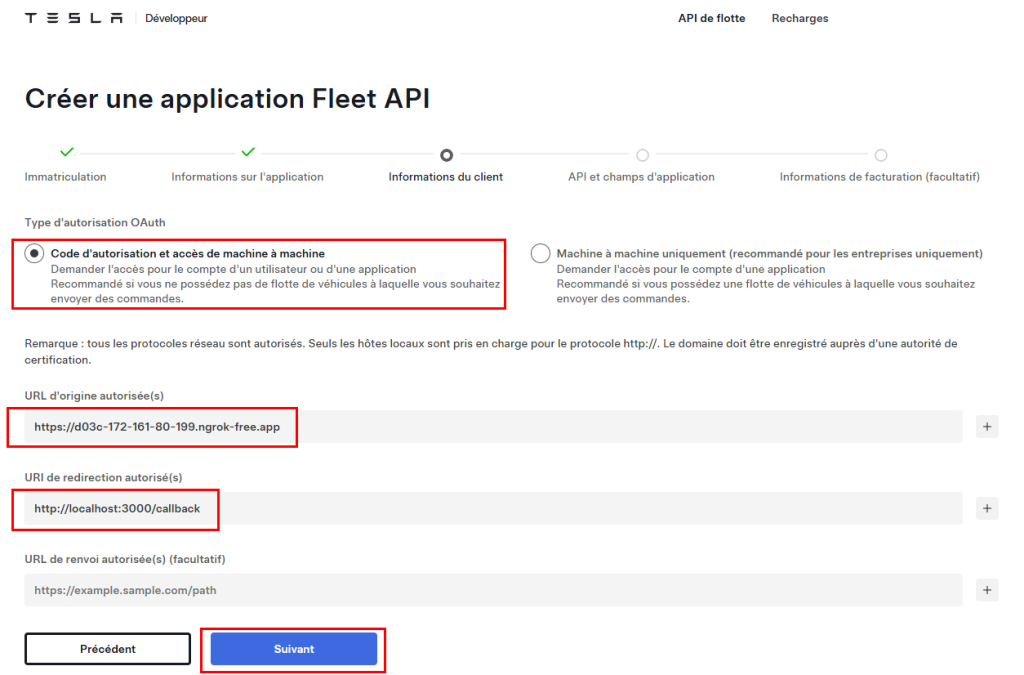
Reprenez l’URL publique donnée par Ngrok, ajoutez en URL de redirection celle en-dessous, puis cliquez sur Suivant :
http://localhost:3000/callback
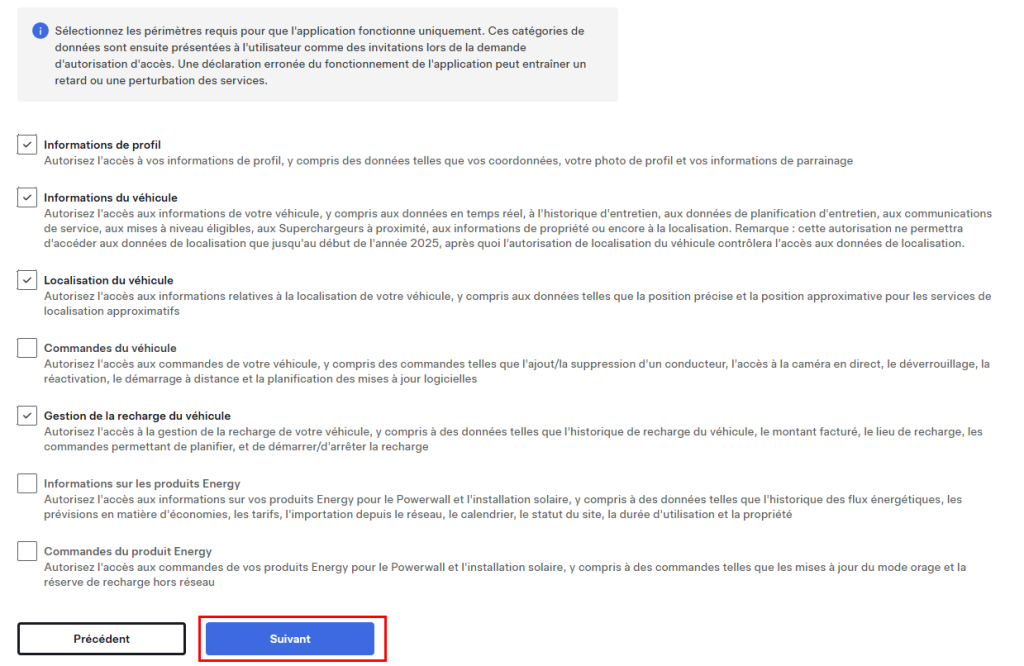
Cochez les cases suivantes, puis cliquez sur Suivant :
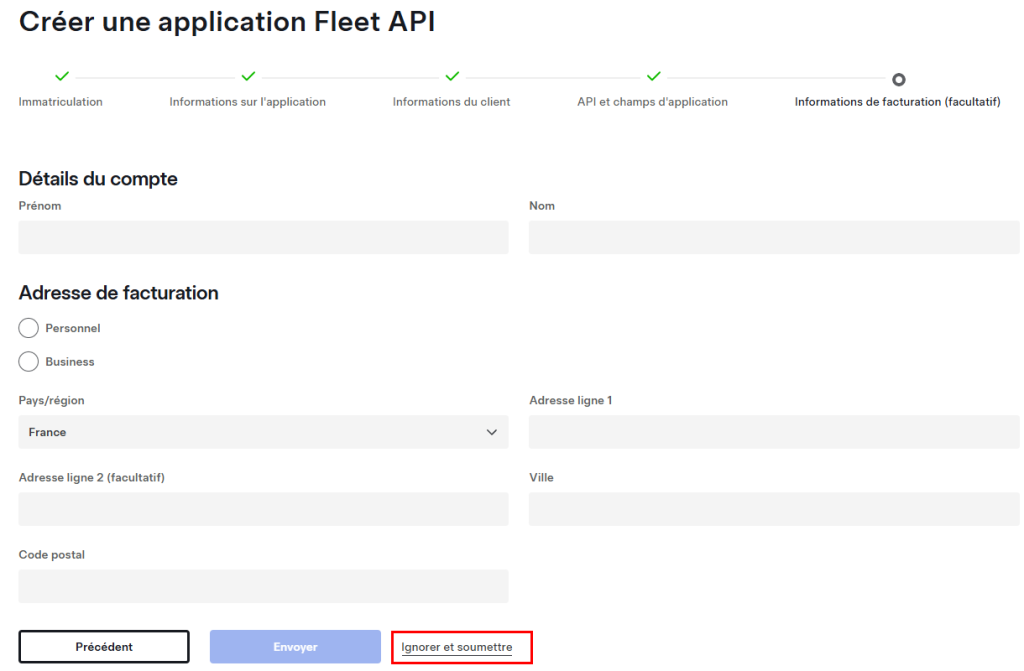
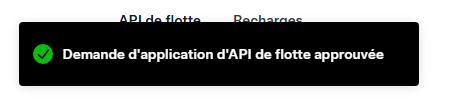
Cliquez sur Ignorer et soumettre :
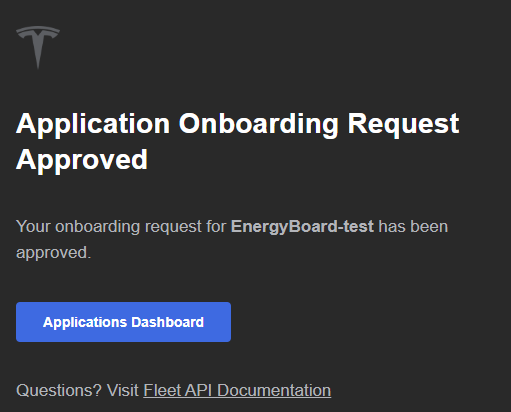
La notification Tesla vous indiquant un succès de l’approbation de votre application API Tesla apparaît alors :
Un email de confirmation vous est également envoyé :
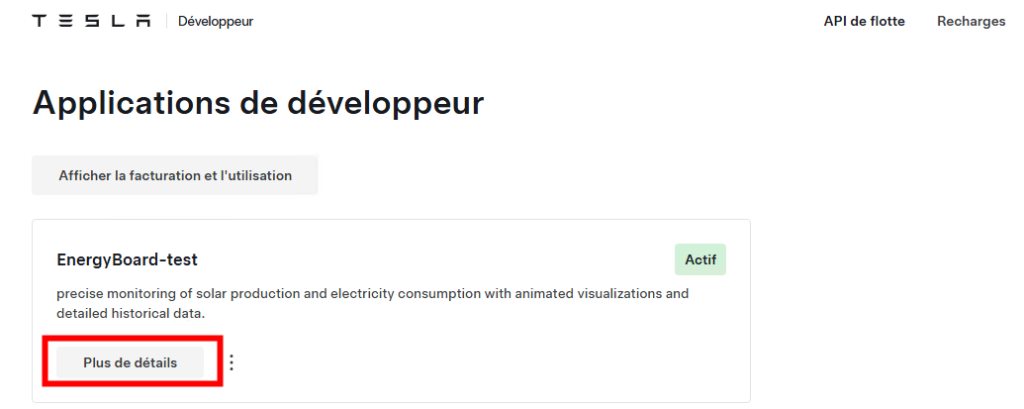
Votre application est immédiatement visible sur le portail de votre compte Développeur Tesla, cliquez-ici pour obtenir des informations techniques sur celle-ci :
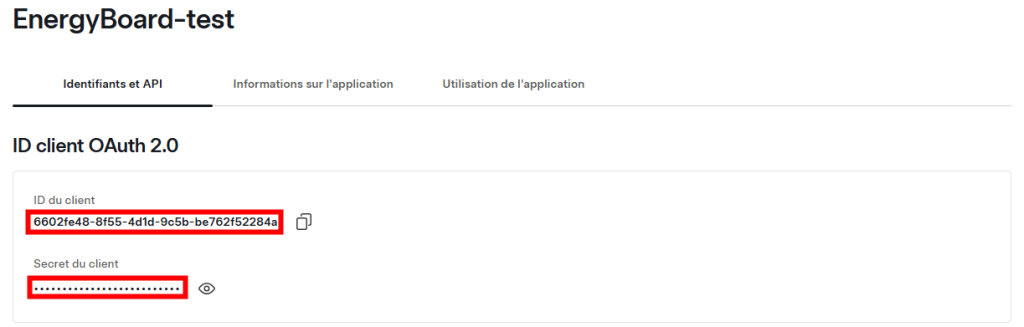
Copiez l’ID et le secret de votre application car nous nous en aurons besoin plus tard :
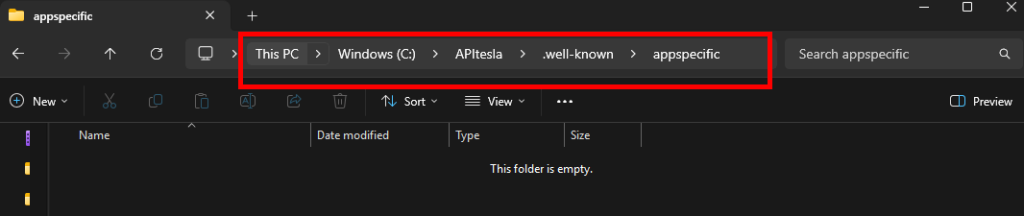
Nous avons besoin de mettre à disposition la clef publique Tesla que nous avons généré quelques étapes plus tôt.
Etape III – Exposition de la clef publique API Tesla :
Pour cela, sur votre poste local, créez une arborescence de dossiers dans le lieu de votre choix, tant que la fin fini comme ceci :
.well-known\appspecific\
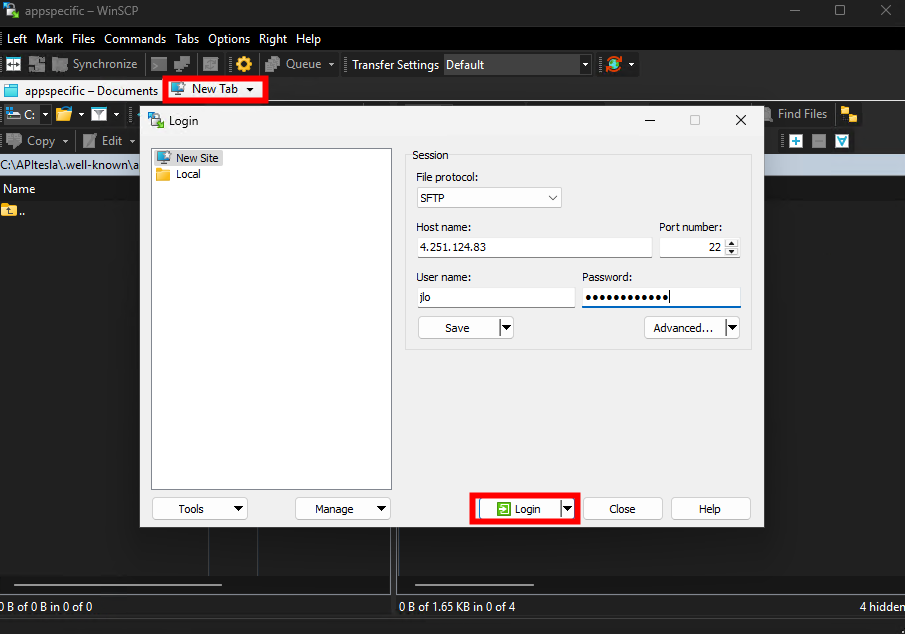
Ouvrez une session WinSCP vers votre environnement :
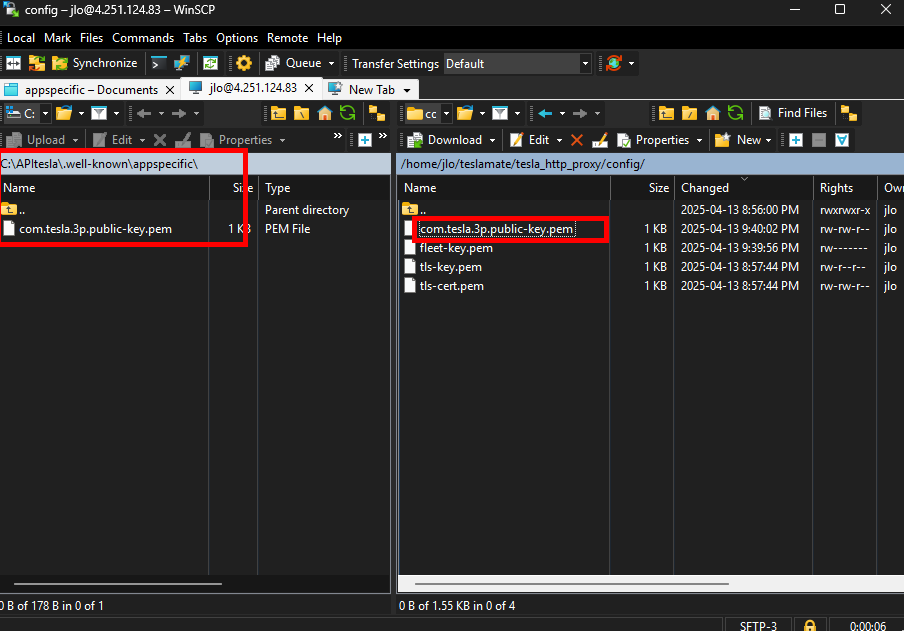
Récupérez la clef publique com.tesla.3p.public-key.pem générée précédemment afin de la placer dans le dossier créé sur votre poste local :
.well-known\appspecific\
Afin d’exposer cette clef publique, installez Python sur votre poste via l’URL officielle :
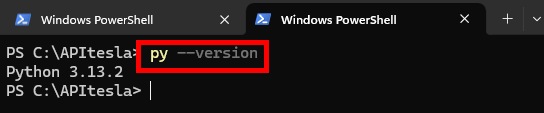
Ouvrez un nouvel onglet à Windows PowerShell, puis affichez la version de Python installée sur votre système
py --version
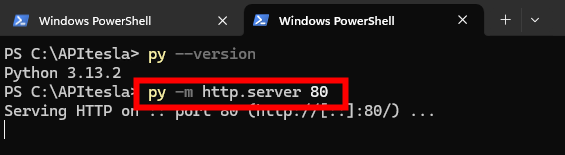
Utilisez Python pour démarrer le module intégré http.server sur le port 80
py -m http.server 80
Ne fermez pas cette fenêtre tant que le processus d’enrôlement API pas entièrement fini :
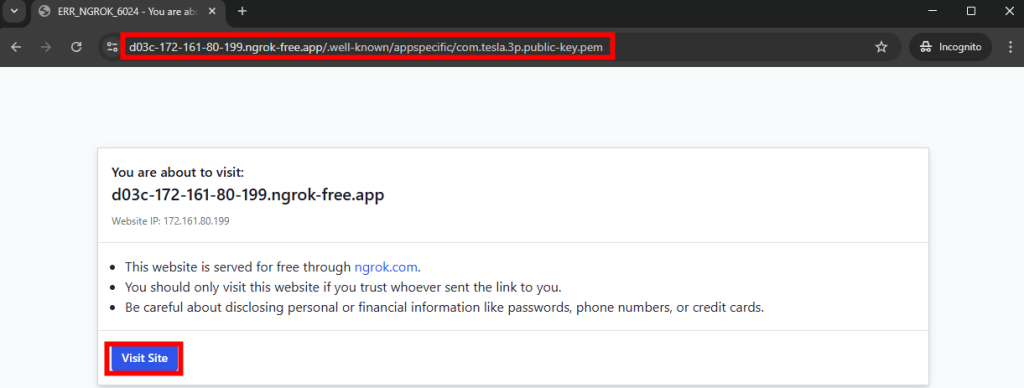
Depuis votre poste local, testez l’URL suivante afin de vérifier le bon téléchargement de votre clef publique API Tesla :
Cliquez sur le bouton suivant pour confirmer votre action :
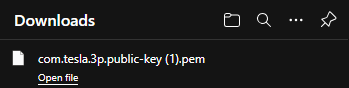
Constatez le téléchargement de votre clef publique sur votre poste local :
Nous sommes maintenant prêt à finaliser l’inscription de notre application chez Tesla.
Etape IV – Génération d’un token d’authentification partenaire :
Plusieurs requêtes API doivent être faites pour arriver au bout du processus. Pour cela, je vous conseille de passer par un outil local, comme Insomnia :
Insomnia REST est un client API (interface pour tester et déboguer des API) qui permet de créer, envoyer et gérer des requêtes HTTP et REST, ainsi que des requêtes GraphQL dans une interface graphique conviviale.
Chat GPT
Téléchargez la version selon votre OS :
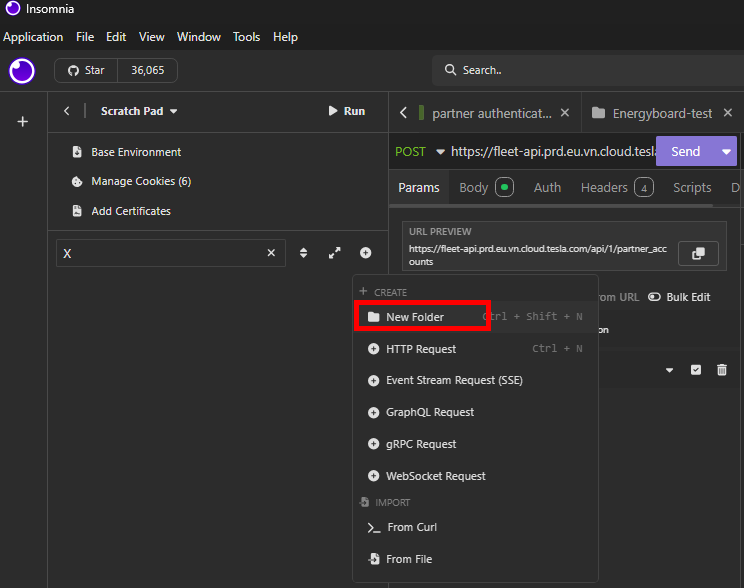
Une fois Insomnia installé, créez un nouveau dossier pour y mettre toutes vos requêtes API Tesla :
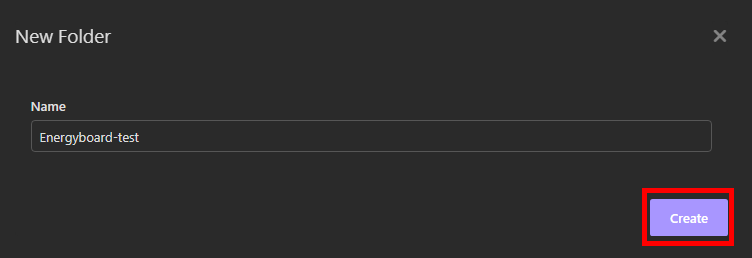
Nommez votre dossier Insomnia, puis cliquez sur Créer :
Sur votre dossier Insomnia, effectuez un clique droit afin d’importer une requête API :
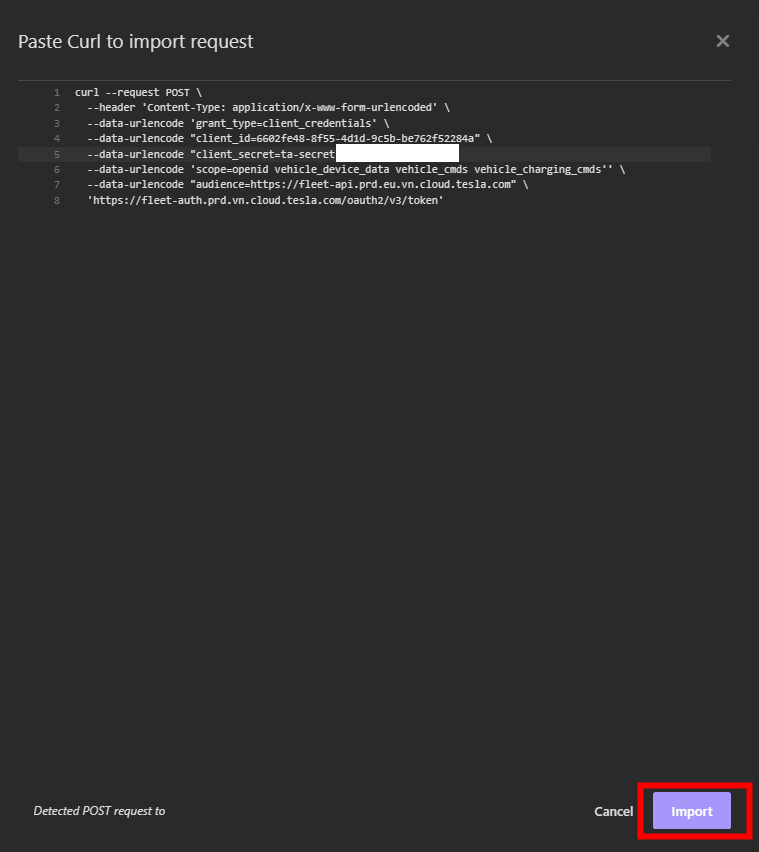
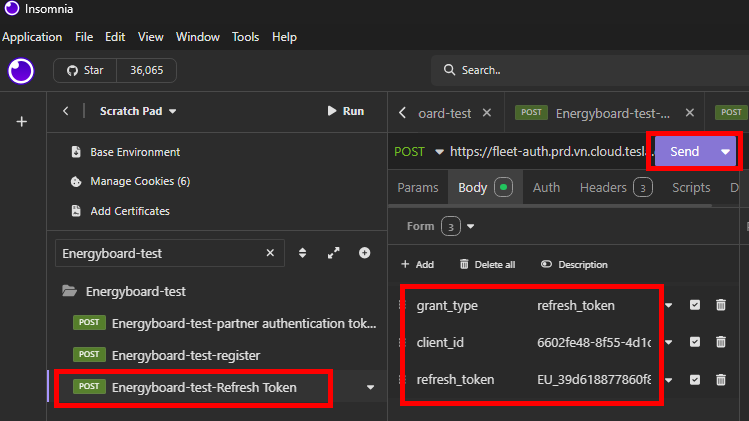
Collez le code ci-dessous en remplaçant en gras les valeurs par les vôtres, puis cliquez sur Importer :
Cette commande effectue une requête HTTP POST vers un endpoint OAuth2 afin d’obtenir un access token en utilisant le flux d’authentification client_credentials. Cela doit donner :
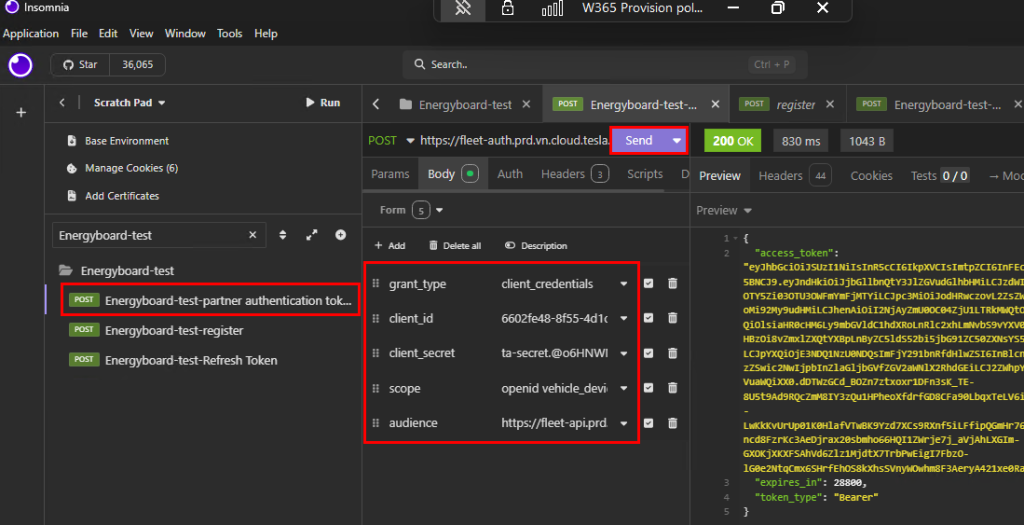
Nommez votre requête API pour plus de clarté, revérifiez tous les champs présent dans l’onglet Body, puis cliquez sur Envoyer :
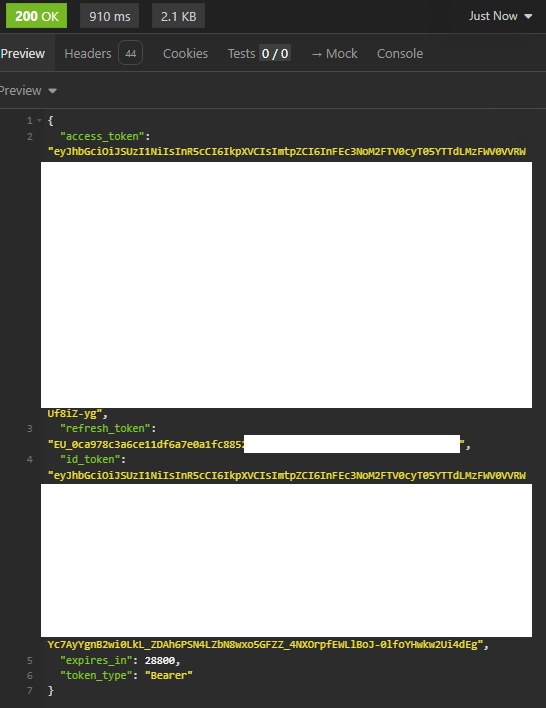
Copiez l’accès token généré par Tesla pour une utilisation ultérieure. Continuons avec l’enregistrement de notre nom de domaine temporaire généré par Ngrok.
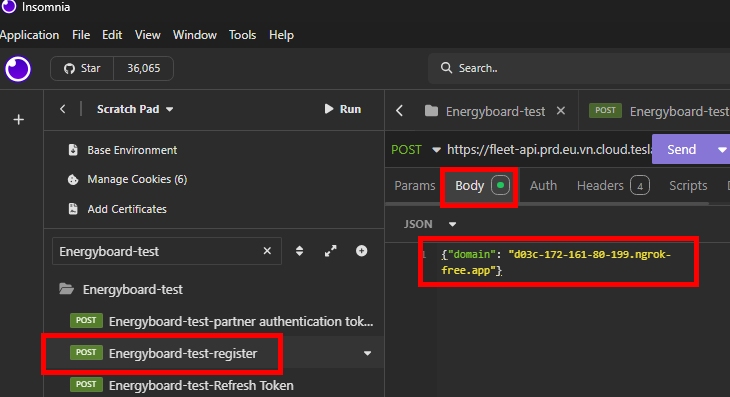
Etape V – Enregistrement d’un domaine chez Tesla :
Comme précédemment, effectuez un clique droit afin d’importer une nouvelle requête API :
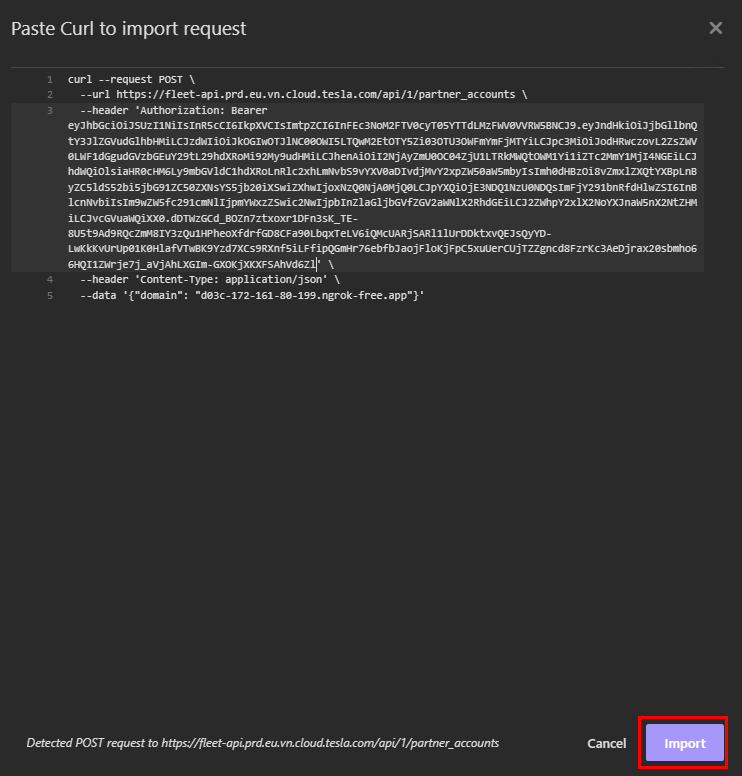
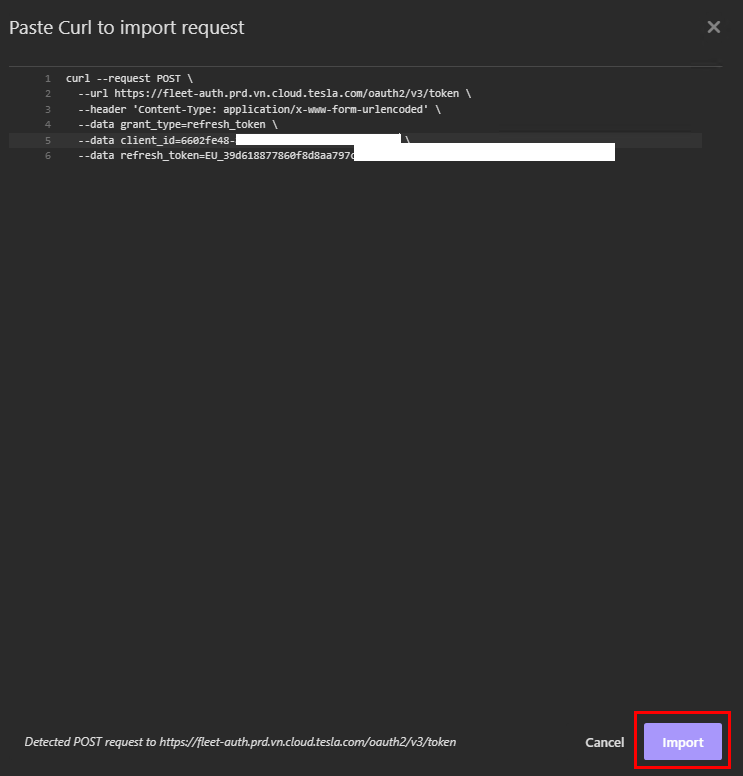
Collez le code ci-dessous en remplaçant en gras les valeurs par les vôtres, puis cliquez sur Importer :
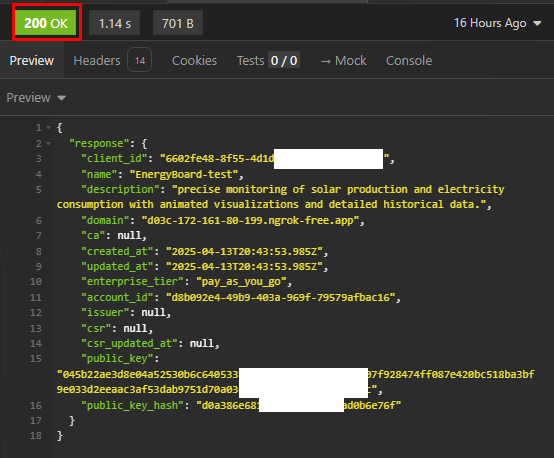
Cette commande effectue une requête HTTP POST vers l’API de la flotte de Tesla afin d’enregistrer ou de créer un compte partenaire avec un domaine spécifique. Cela doit donner :
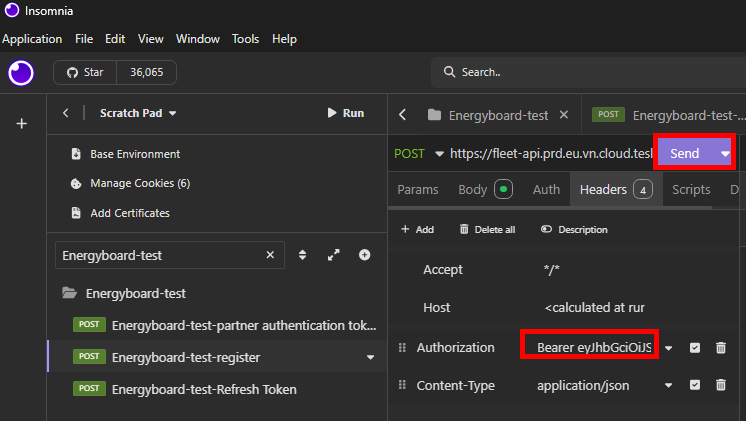
Nommez votre requête API pour plus de clarté, revérifiez tous les champs présent dans l’onglet Body :
Vérifiez également l’onglet Headers, puis cliquez sur Envoyer :
Constatez le succès de l’opération via le message suivant :
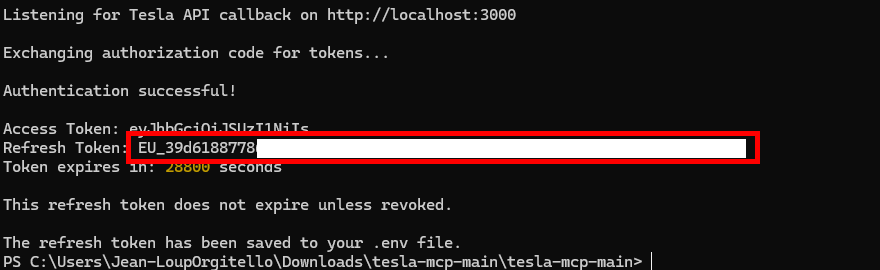
L’étape suivante consiste maintenant à récupérer un accès token et refresh token afin de pouvoir utiliser le proxy HTTP Tesla dans Energyboard.
Etape VI – Génération d’un refresh token :
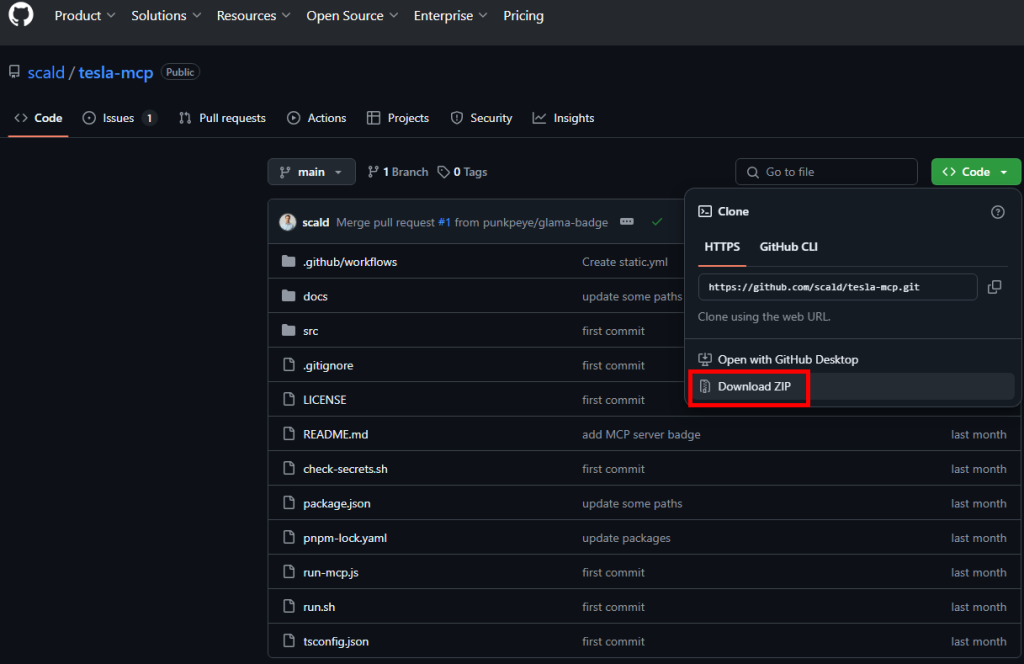
Pour cela, nous allons utiliser une autre application temporaire afin de capter facilement ces tokens. Rendez-vous sur la page GitHub suivante, puis lancez le téléchargement de l’archive ZIP :
Extrayez le contenu de l’archive ZIP dans le dossier de votre choix :
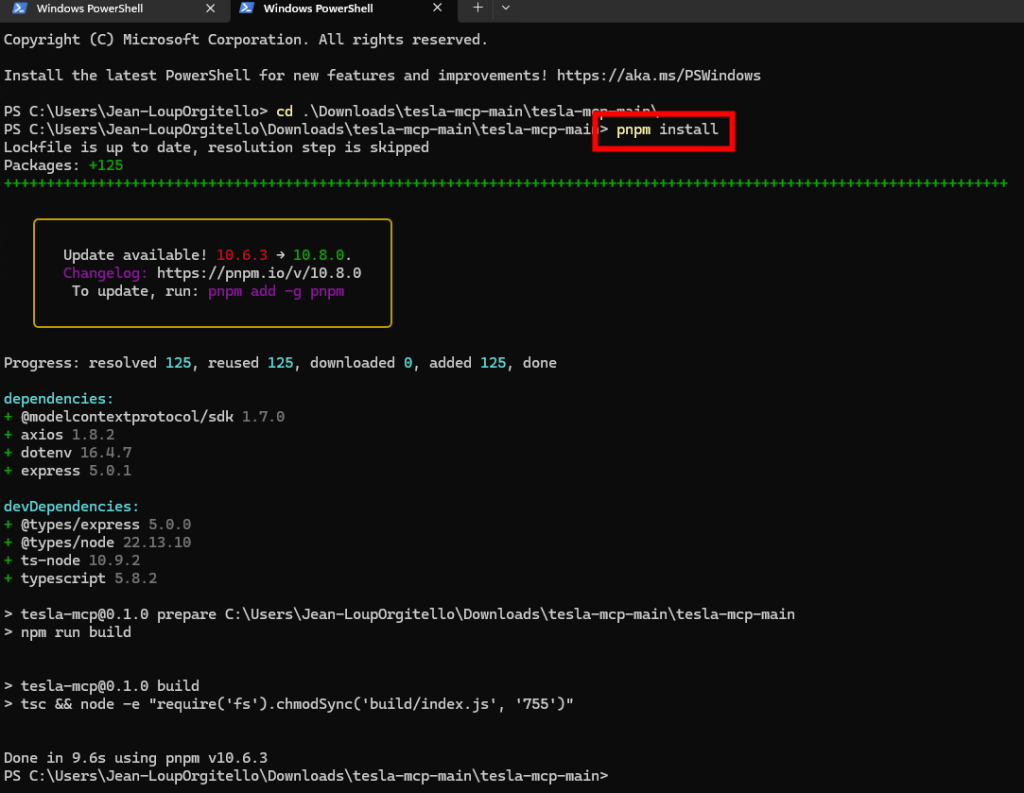
Ouvrez un onglet Windows PowerShell, positionnez-vous dans le dossier d’archive ci-dessous, puis lancez la commande suivante pour télécharger et installer toutes les dépendances répertoriées dans le fichier package.json du projet :
pnpm install
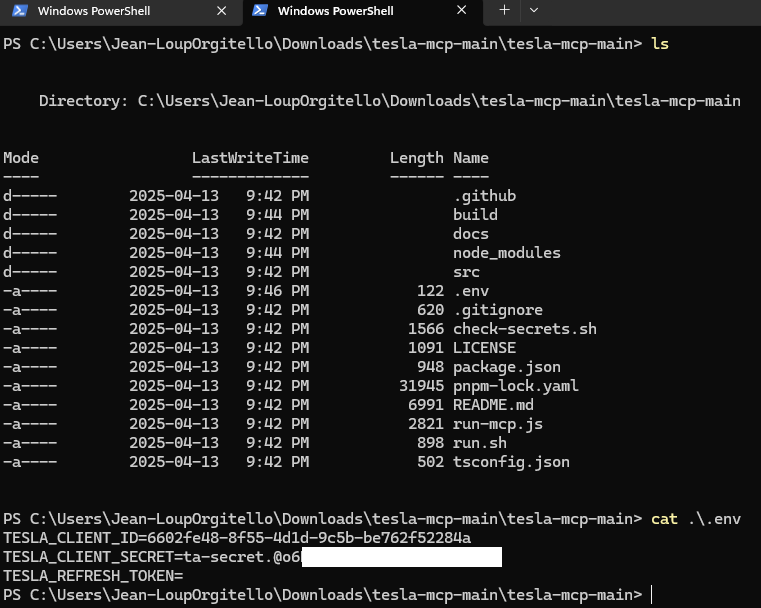
Créez un nouveau fichier .env à la racine de ce même dossier en y indiquant les deux informations présentes en gras :
Cette commande effectue une requête HTTP POST vers l’API de la flotte de Tesla afin d’enregistrer ou de créer un compte partenaire avec un domaine spécifique. Cela doit donner :
Nommez votre requête API pour plus de clarté, revérifiez tous les champs présent dans l’onglet Body, puis cliquez sur Envoyer :
Constatez le succès de l’opération via le message suivant :
L’enregistrement de l’application est maintenant terminée ! Il ne nous reste qu’à ajouter la clef virtuelle API sur notre Tesla.
Etape VIII – Enregistrement de la clef publique API sur la Tesla :
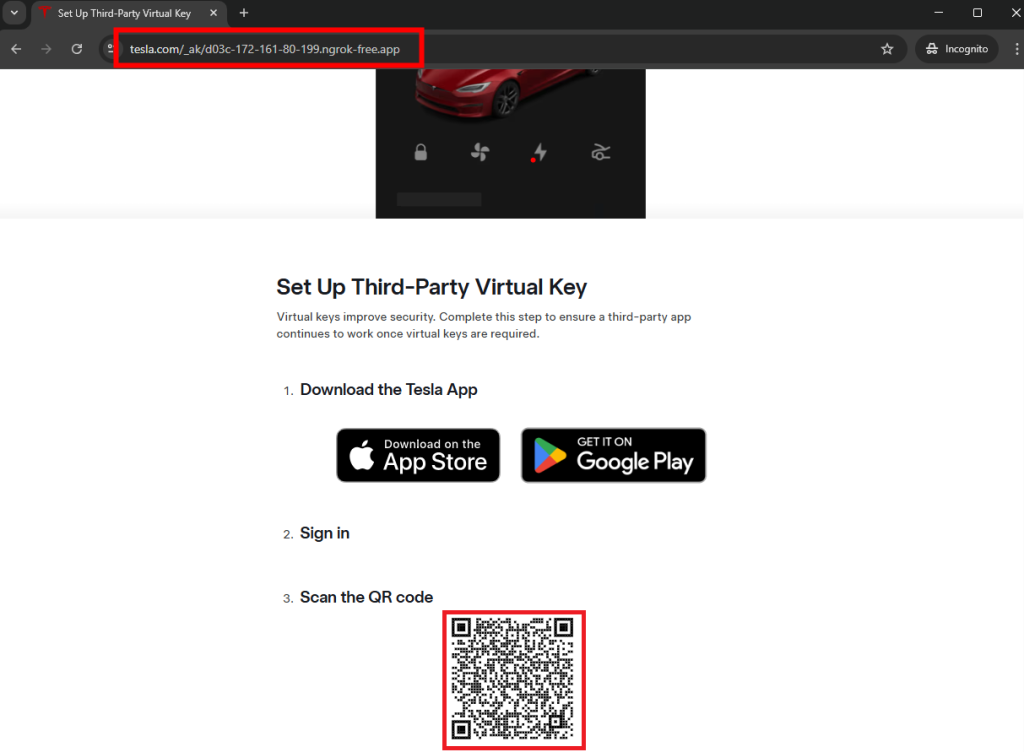
Pour cela, ouvrez la page suivante dans votre navigateur internet en remplaçant la valeur en gras par votre domaine Ngrok approuvé par Tesla :
https://tesla.com/_ak/YOUR_NGROK_DOMAIN
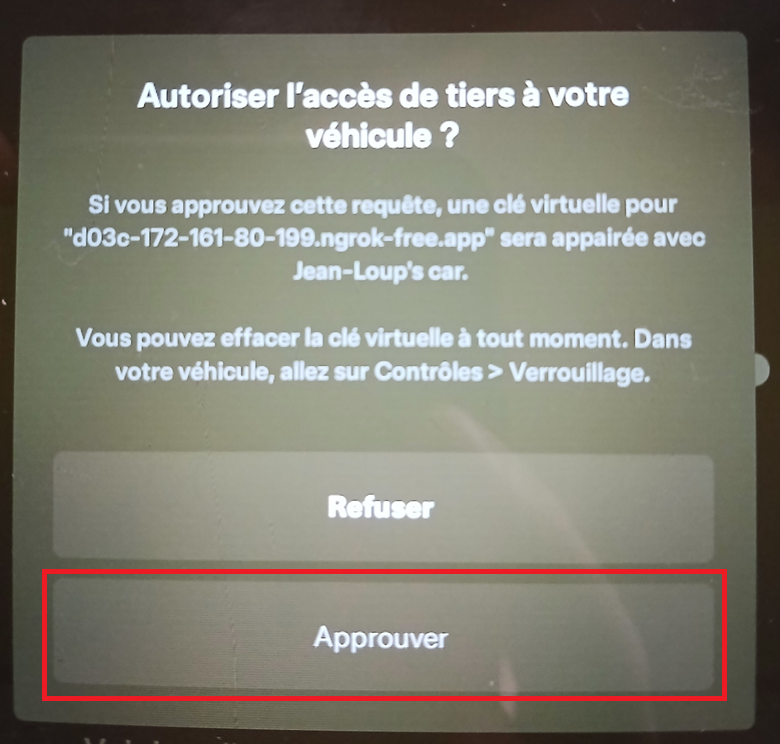
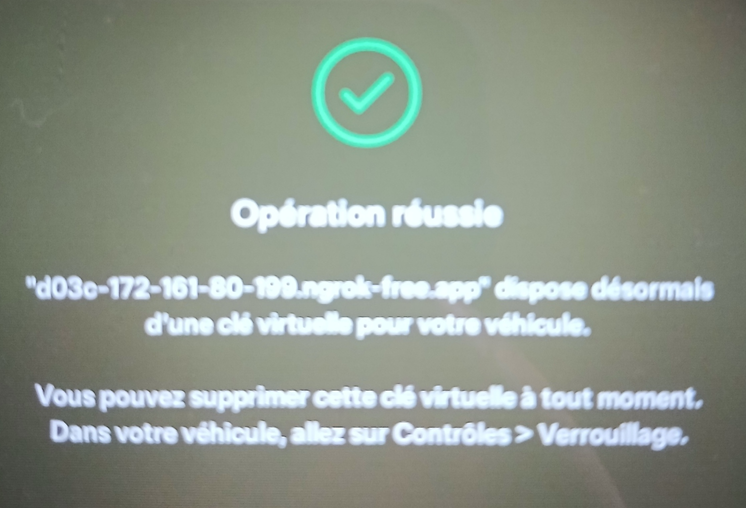
Depuis votre smartphone dans lequel installée l’application Tesla et agit déjà comme une clef de votre Tesla, scanner le QR en bas de votre page web :
L’application Tesla s’ouvre alors et vous demande d’autoriser l’application à votre véhicule, cliquez sur Approuver :
Un message d’opération réussie doit alors apparaître :
Votre Tesla est maintenant prête à recevoir des ordres via API. Il ne nous reste qu’à configurer Energyboard pour activer cette fonction.
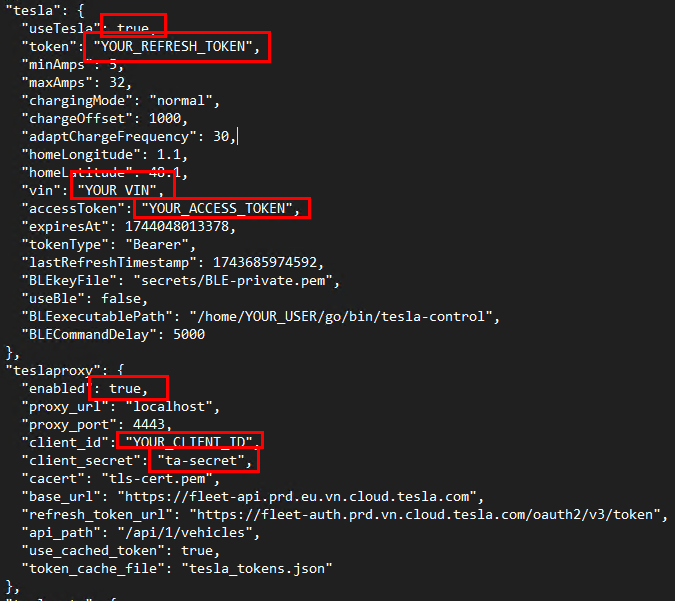
Etape IX – Configuration API pour Energyboard :
Renseignez les informations suivantes pour qu’Energyboard exploite le service de communication API avec la voiture Tesla :
Pensez à sauvegarder le fichier de configuration via la commande suivante :
:wq
Arrêter l’application Energyboard :
pm2 stop energyboard
Démarrer l’application Energyboard :
pm2 start energyboard
Conclusion
En conclusion, cette dernière étape d’enrôlement de la Fleet API Tesla clôt un parcours riche en découvertes et en défis techniques : de la configuration de Ngrok à la génération des tokens, en passant par l’exposition de votre clef publique et l’inscription de votre application, chaque phase a consolidé votre compréhension des protocoles OAuth2 et des bonnes pratiques de sécurité.
Grâce à ce processus, vous bénéficiez désormais d’une connexion API robuste, entièrement maîtrisée, qui permet à votre tableau de bord domotique de communiquer en toute confiance avec votre Tesla.
N’hésitez pas à revisiter chaque étape si besoin, et gardez à l’esprit que cet investissement initial ouvre la voie à de nombreuses automatisations avancées et à un suivi précis de vos usages énergétiques.
Félicitations pour votre persévérance et bon pilotage !
Le principe de la connexion BLE (Bluetooth Low Energy) repose sur l’établissement d’un canal de communication local, sécurisé et à faible consommation, permettant à un appareil externe (souvent via un outil ou une application personnalisée) d’envoyer des commandes directement au véhicule. Cette approche est idéale entre un véhicule Tesla et l’application EnergyBoard.
Voici les points essentiels à utiliser la liaison BLE sur un véhicule Tesla :
Communication à courte portée et faible consommation Le BLE est conçu pour des échanges de données sur de courtes distances, ce qui est idéal pour communiquer avec un véhicule à proximité (par exemple, lors de l’utilisation d’un smartphone ou d’un dispositif embarqué).
Découverte des services et appariement Le véhicule expose des services BLE spécifiques. L’outil (comme celui proposé dans le dépôt vehicle-command) scanne ces services et procède à un appariement ou à une authentification. Pour garantir la sécurité, cette phase d’appariement repose souvent sur l’échange de clés cryptographiques.
Authentification par échange de clés Afin de s’assurer que seules les requêtes authentifiées parviennent au véhicule, le mécanisme implique l’utilisation d’une paire de clés publique/privée. Par exemple, la commande tesla-control -vin YOUR_VIN -ble -key-file BLE-private.pem wake illustre comment une clé privée est utilisée pour signer ou authentifier une commande envoyée via BLE. Ce processus assure que seul un utilisateur autorisé peut exécuter des commandes sensibles (comme le réveil du véhicule, le verrouillage ou le démarrage de la charge).
Exécution des commandes Une fois la connexion établie et l’authentification réussie, l’appareil externe peut envoyer des commandes spécifiques (par exemple, pour réveiller le véhicule, obtenir son état, verrouiller/déverrouiller, etc.). Ces commandes sont interprétées par le système du véhicule et traduites en actions réelles.
Sécurité et contrôle L’utilisation du BLE dans ce contexte permet de limiter la portée de la communication et d’exploiter un protocole conçu pour être économe en énergie. De plus, la sécurisation par clé cryptographique protège contre toute tentative d’intrusion non autorisée.
En résumé, la connexion BLE sur une Tesla, telle qu’illustrée dans le projet vehicle-command, consiste à établir un lien local entre un appareil et le véhicule, authentifier cette communication via un échange de clés, puis permettre l’envoi de commandes sécurisées pour contrôler diverses fonctions du véhicule.
Ce mécanisme offre un moyen efficace et sûr de gérer certaines opérations du véhicule sans passer par les serveurs Tesla.
Quelles sont les différentes étapes pour faire fonctionner BLE ?
Voici la liste des étapes que nous allons faire ensemble :
Exécutez tesla-control en mode Bluetooth pour le véhicule identifié par le VIN afin de lancer la commande add-key-request en utilisant le fichier BLE-public.pem pour envoyer une requête d’ajout de clé associée à l’identité ou au rôle « owner » et à la clé identifiée par cloud_key :
Confirmez l’action d’association en couchant la carte NFC Tesla sur la console centrale de la voiture.
Etape IV – Test de la clef virtuelle BLE :
Pour tester le bon fonctionnement d’un ordre à la voiture, envoyez la commande de réveil au véhicule, en utilisant le fichier BLE-private.pem pour l’authentification.
tesla-control -vin YOUR_VIN -ble -key-file BLE-private.pem wake
L’absence de retour de la part de l’application équivaut à un succès de l’opération :
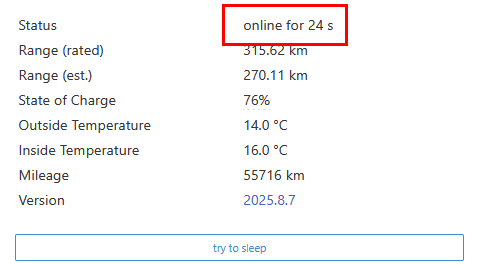
Dans votre navigateur internet, accédez à l’adresse http://ADRESSE_IP:4000 afin de constater une actualisation du statut de la voiture réveillée :
Testez au besoin d’autres commandes sur la Tesla parmi les commandes disponibles :
add-keyAdd PUBLIC_KEY to vehicle whitelist with ROLE and FORM_FACTOR
add-key-requestRequest NFC-card approval for a enrolling PUBLIC_KEY with ROLE and FORM_FACTOR
auto-seat-and-climateTurn on automatic seat heating and HVAC
autosecure-modelxClose falcon-wing doors and lock vehicle. Model X only.
body-controller-stateFetch limited vehicle state information. Works over BLE when infotainment is asleep.
charge-port-closeClose charge port
charge-port-open Open charge port
charging-scheduleSchedule charging to MINS minutes after midnight and enable daily scheduling
charging-schedule-addSchedule charge for DAYS START_TIME-END_TIME at LATITUDE LONGITUDE. The END_TIME may be on the following day.
charging-schedule-cancel Cancel scheduled charge start
charging-schedule-remove Removes charging schedule of TYPE [ID]
charging-set-ampsSet charge current to AMPS
charging-set-limit Set charge limit to PERCENT
charging-start Start charging
charging-stopStop charging
climate-offTurn off climate control
climate-on Turn on climate control
climate-set-temp Set temperature (Celsius)
driveRemote start vehicle
erase-guest-data Erase Guest Mode user data
flash-lights Flash lights
frunk-open Open vehicle frunk. Note that there's no frunk-close command!
getGET an owner API http ENDPOINT. Hostname will be taken from -config.
guest-mode-off Disable Guest Mode.
guest-mode-onEnable Guest Mode.
honk Honk horn
list-keysList public keys enrolled on vehicle
lock Lock vehicle
media-set-volume Set volume
media-toggle-playbackToggle between play/pause
ping Ping vehicle
post POST to ENDPOINT the contents of FILE. Hostname will be taken from -config.
precondition-schedule-addSchedule precondition for DAYS TIME at LATITUDE LONGITUDE.
precondition-schedule-remove Removes precondition schedule of TYPE [ID]
product-info Print JSON product info
remove-key Remove PUBLIC_KEY from vehicle whitelist
rename-key Change the human-readable metadata of PUBLIC_KEY to NAME, MODEL, KIND
seat-heaterSet seat heater at POSITION to LEVEL
sentry-modeSet sentry mode to STATE ('on' or 'off')
session-info Retrieve session info for PUBLIC_KEY from DOMAIN
software-update-cancel Cancel a pending software update
software-update-startStart software update after DELAY
stateFetch vehicle state over BLE.
steering-wheel-heaterSet steering wheel mode to STATE ('on' or 'off')
tonneau-closeClose Cybertruck tonneau.
tonneau-open Open Cybertruck tonneau.
tonneau-stop Stop moving Cybertruck tonneau.
trunk-closeCloses vehicle trunk. Only available on certain vehicle types.
trunk-move Toggle trunk open/closed. Closing is only available on certain vehicle types.
trunk-open Open vehicle trunk. Note that trunk-close only works on certain vehicle types.
unlock Unlock vehicle
valet-mode-off Disable valet mode
valet-mode-onEnable valet mode
wake Wake up vehicle
windows-closeClose all windows
windows-vent Vent all windows
Testez au besoin d’autres commandes sur votre Tesla via BLE :
Votre Tesla est maintenant prête à recevoir des ordres via BLE. Il ne nous reste qu’à configurer EnergyBoard pour activer cette fonction.
Etape V – Configuration BLE pour EnergyBoard :
Renseignez les informations suivantes pour qu’EnergyBoard exploite le service de communication BLE avec la voiture Tesla :
Pensez à sauvegarder le fichier de configuration via la commande suivante :
:wq
Arrêter l’application EnergyBoard :
pm2 stop energyboard
Démarrer l’application EnergyBoard :
pm2 start energyboard
La connexion Bluetooth entre EnergyBoard et la Tesla est maintenant fonctionnelle. Si vous le souhaitez, vous pouvez passer à l’étape facultative suivante, consistant à configurer le lien API entre EnergyBoard et le serveurs Tesla. Ce dernier va nous permettre de :
Envoyer des ordres Tesla via API grâce au conteneur Proxy HTTP quand la liaison Bluetooth n’est pas disponible.
Installer Teslamate se fait en quelques commandes simples, à l’image d’un projet DIY accessible à tous. Teslamate, un datalogger open-source, récupère en local les données de votre Tesla (trajets, consommations, charge…) et les présente via une interface web riche en graphiques et statistiques.
L’ensemble tourne sur Docker, ce qui évite d’installer manuellement chaque composant, et reste sécurisé tant qu’il n’est pas exposé à l’extérieur par défaut. Le mode opératoire décrit ci-dessous est inspiré de celui déjà disponible à cette adresse.
Pour installer Teslamate sur votre environnement (machine virtuelle Azure ou Raspberry Pi 5), il vous faudra disposer de :
Une machine virtuelle Azure ou Raspberry Pi 5
Un accès SSH à votre environnement
Avant d’installer Teslamate, commençons par mettre à jour notre environnement.
Etape I – Mise à jour de l’environnement :
Une fois connecté en SSH à votre environnement (Azure ou Raspberry Pi 5), effectuez les commandes suivantes, une par une, afin de préparer ce dernier
Téléchargez et exécutez automatiquement le script d’installation de Docker depuis le site officiel :
curl -sSL https://get.docker.com | sh
Ajoutez l’utilisateur spécifié au groupe « docker » pour permettre l’exécution des commandes Docker sans utiliser sudo :
sudo usermod -aG docker VOTRE_NOM_UTILISATEUR
Rechargez les paramètres de groupe de l’utilisateur dans la session en cours afin d’appliquer la nouvelle appartenance au groupe « docker » :
newgrp docker
Lancez un conteneur de test (hello-world) pour vérifier que Docker est correctement installé et opérationnel :
docker run hello-world
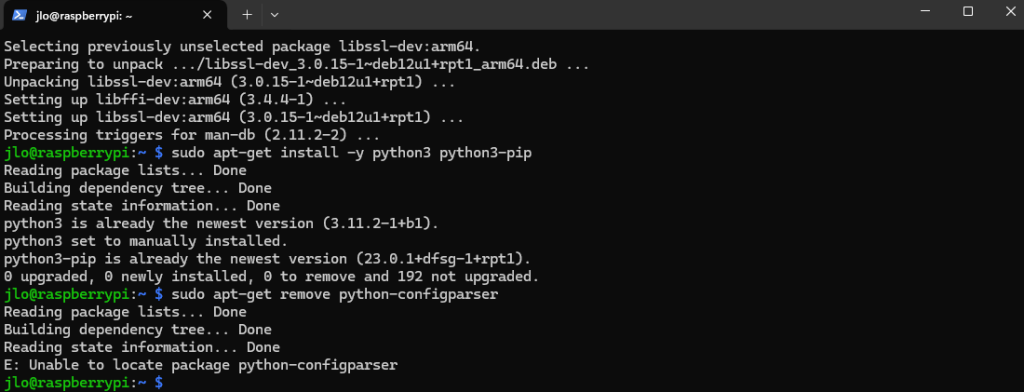
Installez les bibliothèques de développement libffi et libssl, nécessaires pour certaines compilations et dépendances, notamment pour des outils Python :
sudo apt-get install -y libffi-dev libssl-dev
Installez Python 3 ainsi que pip, le gestionnaire de paquets pour Python 3 :
sudo apt-get install -y python3 python3-pip
Désinstallez le paquet python-configparser, souvent redondant ou source de conflits avec la version intégrée dans Python 3 :
sudo apt-get remove python-configparser
Etape II – Installation de Teslamate :
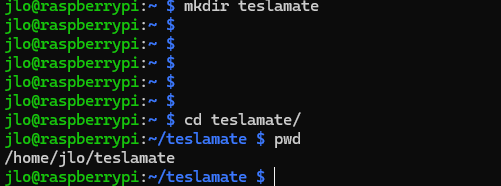
Créez un nouveau répertoire nommé teslamate dans le répertoire courant, puis déplacez-vous dans celui-ci :
mkdir teslamate
cd teslamate/
Créez le fichier docker-compose.yml depuis l’éditeur de texte vi pour permettre son édition :
vi docker-compose.yml
Dans l’éditeur de texte vi, appuyez sur la touche i pour passer en mode édition, puis collez le manifeste ci-dessous. Avant de le copier, pensez à modifier les secrets suivants :
Secretkey de ENCRYPTION_KEY par 12 caractères ou plus, pour sécuriser votre connexion. Utilisez si besoin Key Generator.
Mot de passe de DATABASE_PASS (à 3 endroits) par le mot de passe de votre choix.
Une fois le manifeste collé, appuyez sur Echap pour quitter le mot édition de vi, puis sauvegardez votre fichier avec la commande suivante, suivie de la touche Entrée :
:wq
Etape III – Création de certificats pour Tesla Proxy :
Sous le dossier teslamate, créez arborescence suivante, puis déplacez-vous-y :
mkdir ./tesla_http_proxy
mkdir ./tesla_http_proxy/config
cd tesla_http_proxy/config/
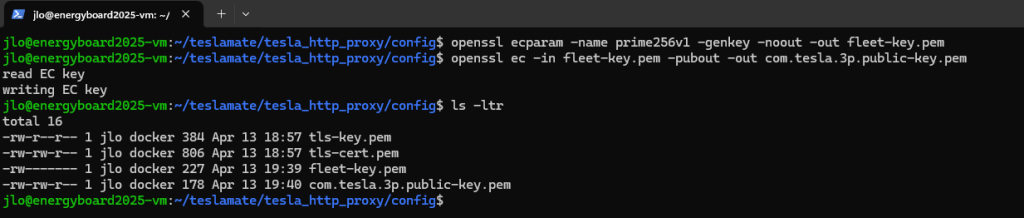
Créez un certificat auto-signé à l’aide d’OpenSSL :
Modifiez les permissions des fichiers PEM pour que le propriétaire et le groupe puissent le lire et l’écrire (6), tandis que les autres utilisateurs n’ont qu’un droit de lecture (4) :
sudo chmod 664 *.pem
Générez une clé privée, avec sa clef publique, pour assurer une authentification des commandes via API émises vers la Tesla :
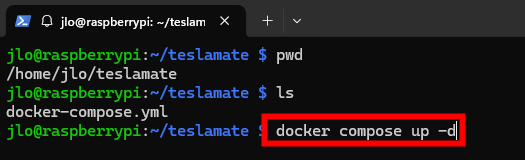
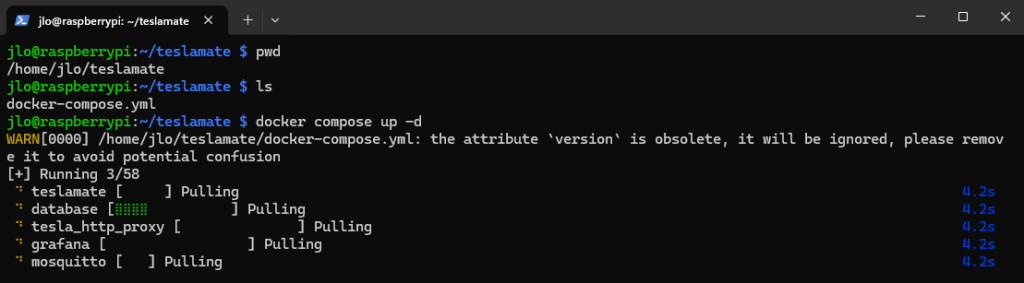
Depuis le dossier teslamate, démarrez en mode détaché (en arrière-plan) tous les services définis dans le fichier docker-compose.yml :
docker compose up -d
Docker commence par télécharger toutes les images nécessaires aux services définis dans votre fichier docker-compose.yml, afin de s’assurer qu’elles soient disponibles localement pour créer et démarrer les conteneurs :
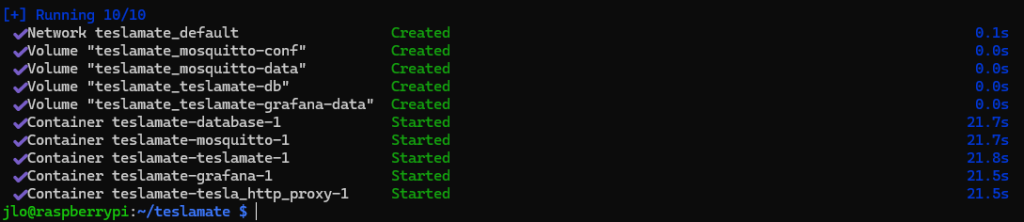
Attendez et vérifiez le bon démarrage de tous les conteneurs :
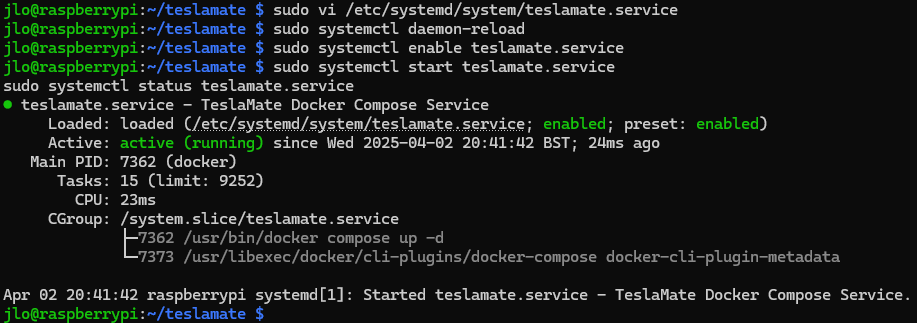
Ouvrez le fichier de configuration du service Systemd, nommé teslamate.service, dans l’éditeur de texte vi avec des privilèges administrateur afin de définir comment lancer, arrêter et gérer le service Teslamate.
sudo vi /etc/systemd/system/teslamate.service
En mode édition, collez le code suivant afin d’automatiser la gestion de Teslamate en s’assurant que Docker est prêt avant de lancer l’ensemble des conteneurs en cas de problème, en n’oubliant pas de modifier USER par votre nom d’utilisateur :
[Unit]
Description=TeslaMate Docker Compose Service
Requires=docker.service
After=docker.service
[Service]
WorkingDirectory=/home/USER/teslamate
ExecStart=/usr/local/bin/docker compose up -d
ExecStop=/usr/local/bin/docker compose down
Restart=always
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
Appuyez sur Echap pour quitter le mot édition, puis sauvegardez votre fichier avec la commande suivante, suivie de la touche Entrée :
:wq
Demandez à systemd de recharger tous ses fichiers de configuration :
sudo systemctl daemon-reload
Configurez systemd pour démarrer automatiquement le service Teslamate au prochain démarrage du système, en créant les liens symboliques nécessaires dans les répertoires d’unités.
sudo systemctl enable teslamate.service
Démarrez et affichez l’état actuel du service Teslamate :
sudo systemctl start teslamate.service
sudo systemctl status teslamate.service
Listez l’ensemble des conteneurs Docker qui sont actuellement en cours d’exécution, en affichant des informations telles que l’ID du conteneur, l’image utilisée, l’état, les ports exposés et le nom du conteneur :
docker ps
Etape V – Configuration de Teslamate :
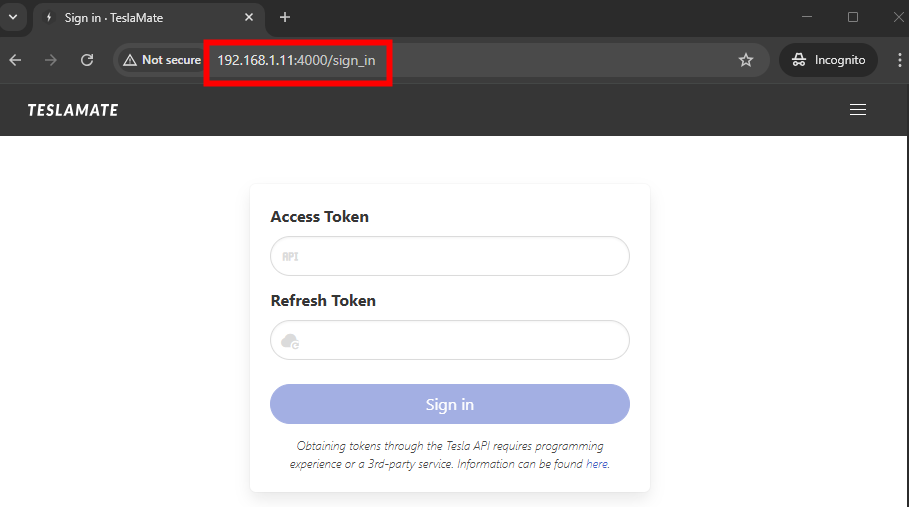
Dans votre navigateur internet, accédez à l’adresse http://ADRESSE_IP:4000 :
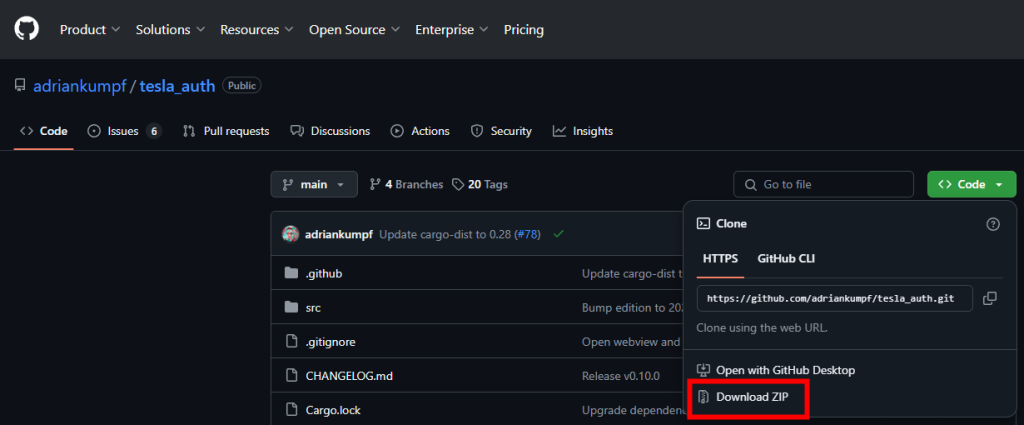
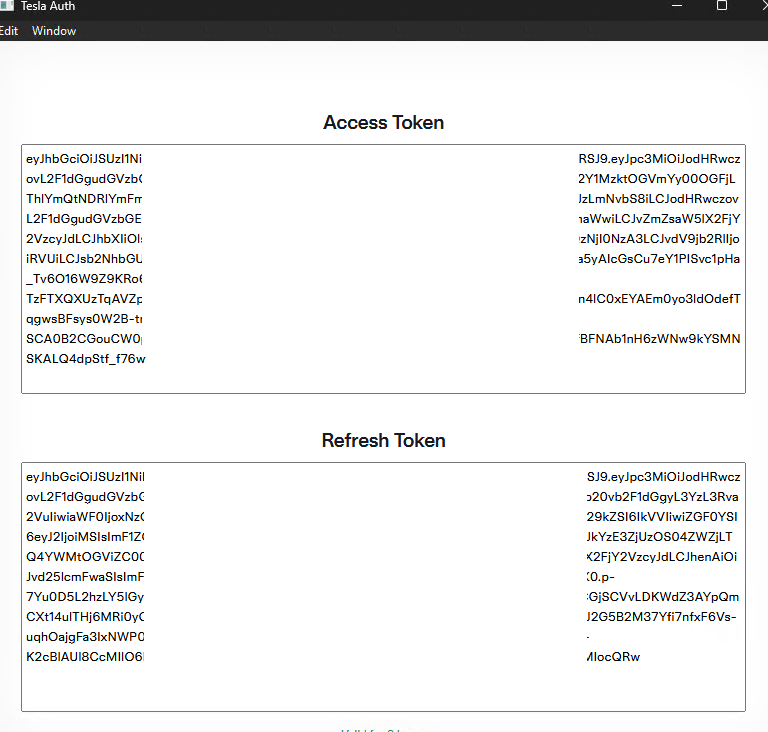
Pour générer les tokens, utilisez un outil comme tesla_auth, téléchargeable sur GitHub :
Lancez l’exécutable tesla_auth.exe, puis authentifiez-vous avec votre compte Tesla :
Entre le code de votre méthode 2FA,si cette dernière est configurée :
Copiez les deux tokens affichés dans l’application tesla_auth :
Les access tokens servent à authentifier et autoriser directement l’accès aux API et ressources protégées (et sont généralement de courte durée).
Les refresh tokens permettent d’obtenir de nouveaux access tokens lorsque ceux-ci expirent, assurant ainsi une continuité de session sans nécessiter une réauthentification manuelle.
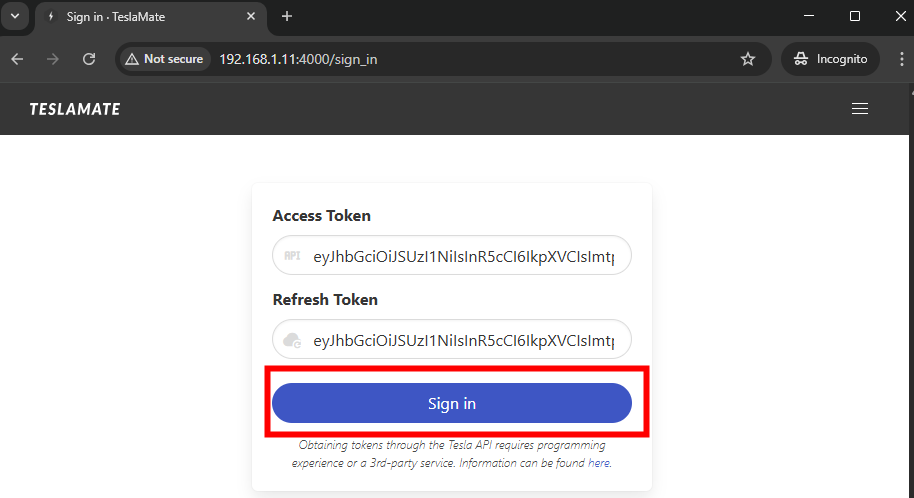
Collez dans Teslamate les 2 tokens, puis cliquez-ici pour vous authentifier :
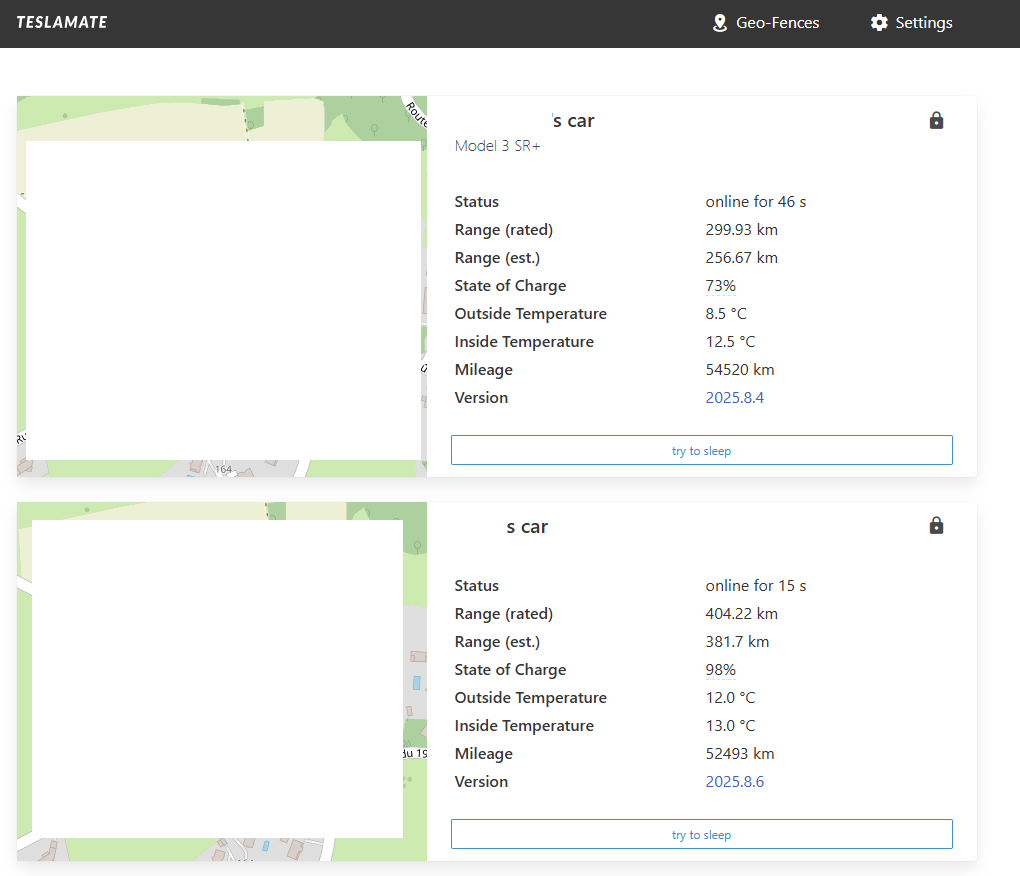
Si l’accès est confirmé, Teslamate devrait alors vous afficher la ou les voitures Tesla rattachées à votre compte Tesla :
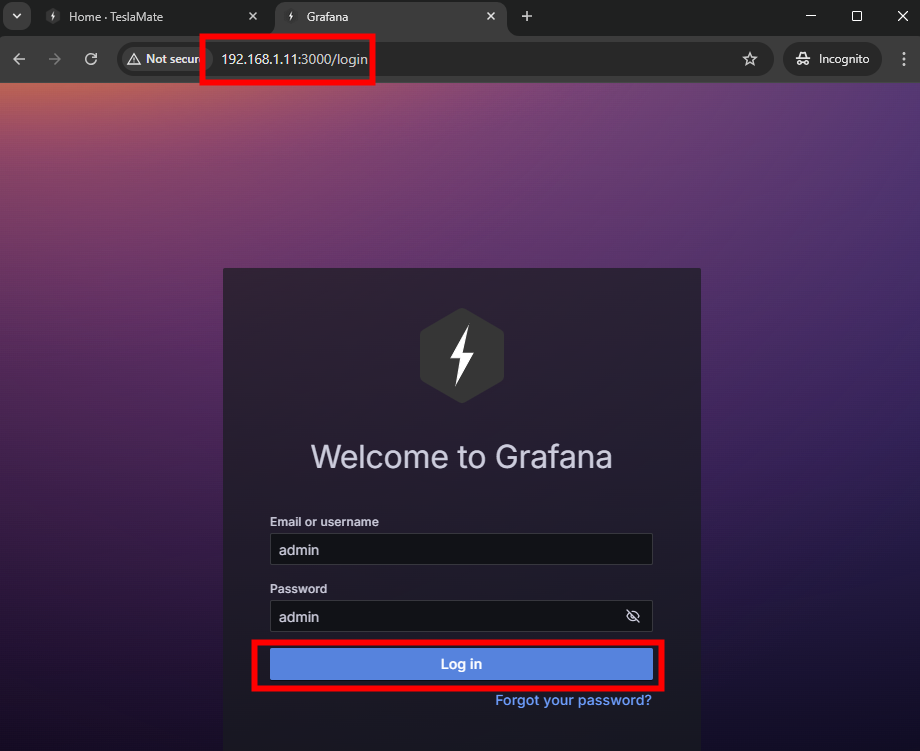
Bonus : accédez à votre tableau de bord Teslamate via l’adresse http://ADRESSE_IP:3000, dont les identifiants par défaut sont admin/admin :
Une fois connecté pour la première fois, personnalisez le mot de passe de votre compte admin :
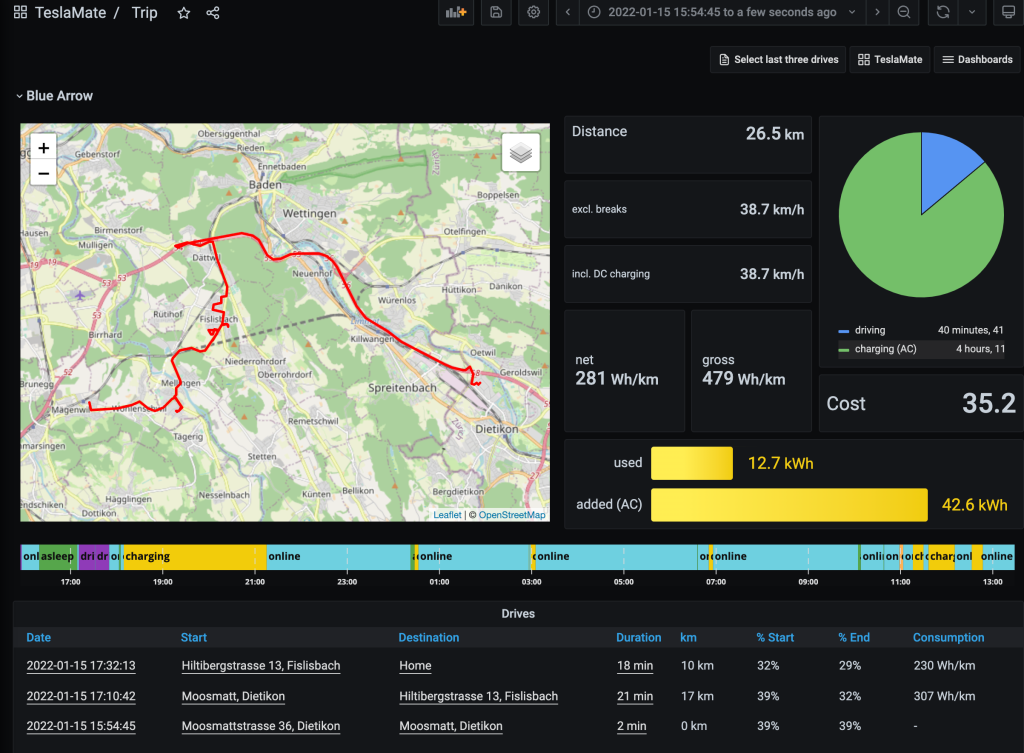
Une grande quantité de tableaux de bord y sont disponibles :
Teslamate est maintenant installé, vous pouvez passer à l’étape suivante, consistant à installer et configurer EnergyBoard. Ce dernier va nous permettre de :
Remonter les informations liées à la production solaire Enphase
Remonter les informations liées à la charge Tesla
Envoyer des ordres Tesla via BLE grâce l’application Tesla-control
Envoyer des ordres Tesla via API grâce au conteneur Tesla Proxy HTTP
Installer EnergyBoard sur une machine virtuelle Azure présente plusieurs atouts : vous vous affranchissez des contraintes liées à un serveur dédié ou à un Raspberry Pi, et bénéficiez de la scalabilité et de la haute disponibilité du cloud. En contrepartie, le pilotage Bluetooth local n’est pas possible depuis Azure, ce qui vous limite aux seuls appels API Tesla pour la gestion du véhicule.
Cette architecture cloud peut toutefois s’avérer très intéressante pour centraliser votre dashboard et automatiser les mises à jour, à condition de prévoir l’ouverture des ports nécessaires (HTTP/8002, TCP…) afin de relayer les requêtes vers votre passerelle Enphase, qui elle reste sur votre réseau domestique.
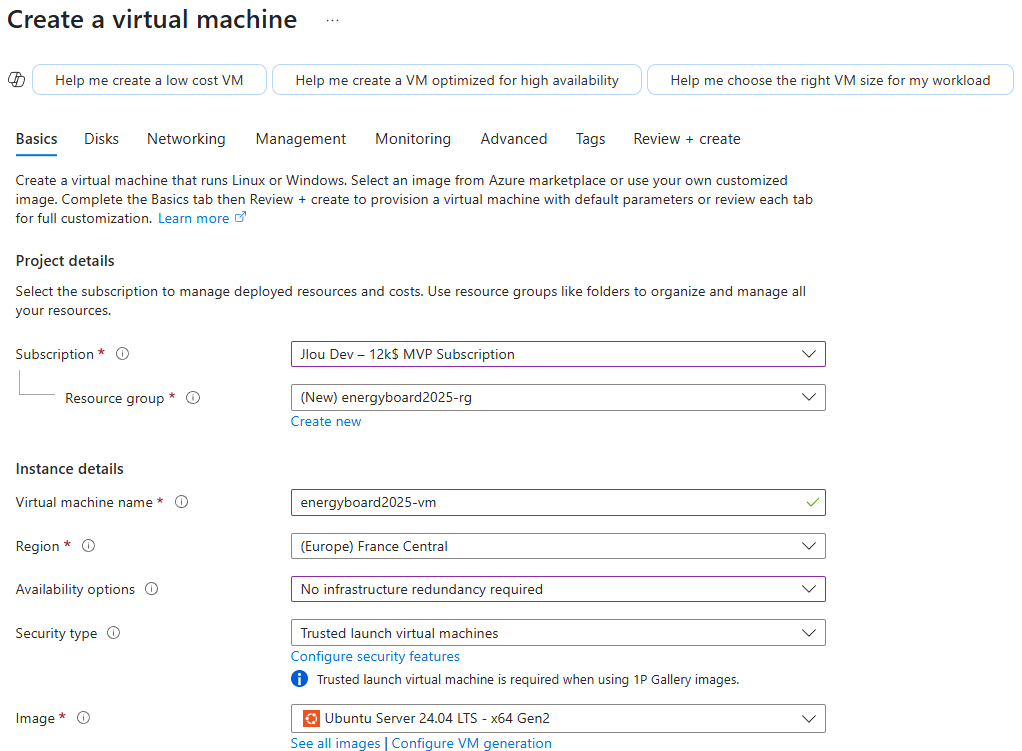
Pour installer votre application EnergyBoard sur Azure, il vous faudra disposer de :
Un tenant Microsoft
Une souscription Azure valide
Commençons par créer la machine virtuelle Linux.
Etape I – Création de la machine virtuelle Linux :
Depuis le portail Azure, commencez par rechercher le service des machines virtuelles :
Cliquez-ici pour créer votre machine virtuelle :
Renseignez tous les champs, en prenant soin de bien sélectionner les valeurs suivantes :
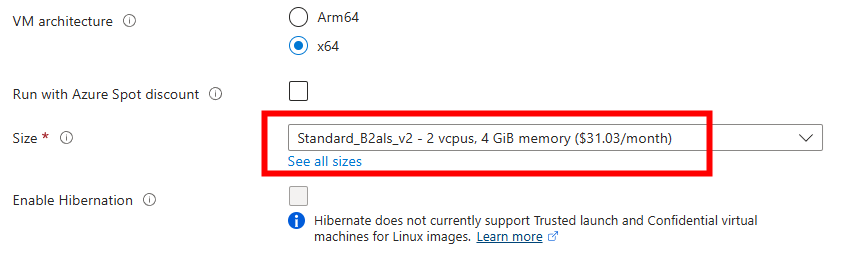
Choisissez une taille de machine virtuelle de petite puissance :
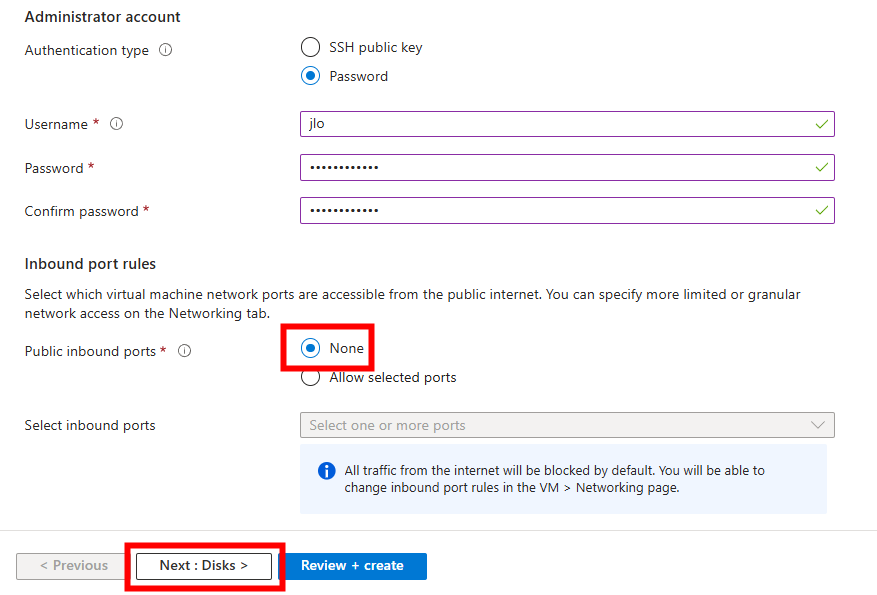
Renseignez les informations d’administration, puis cliquez sur Suivant :
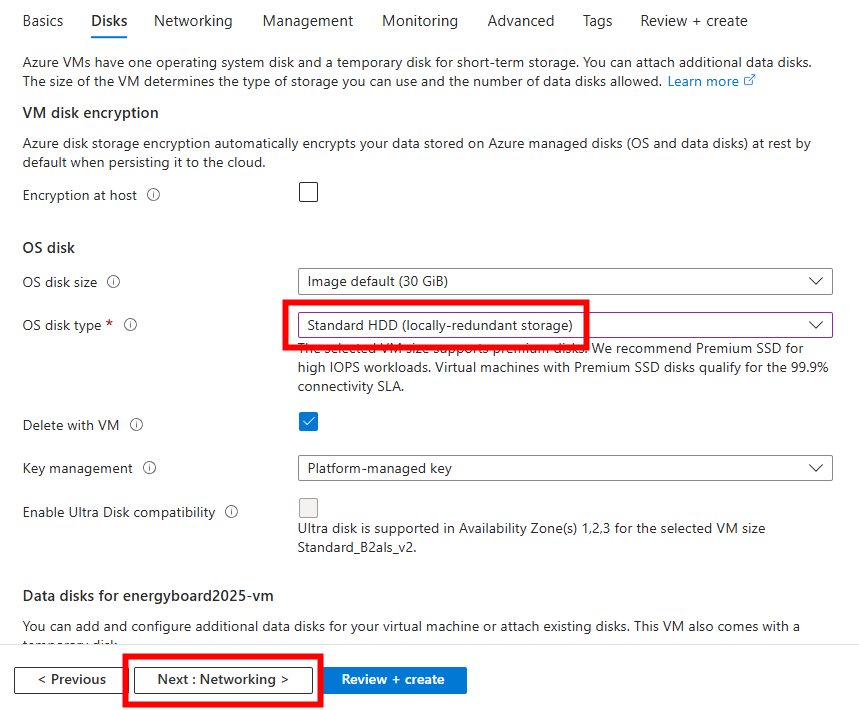
Adaptez la performance du disque, puis cliquez sur Suivant :
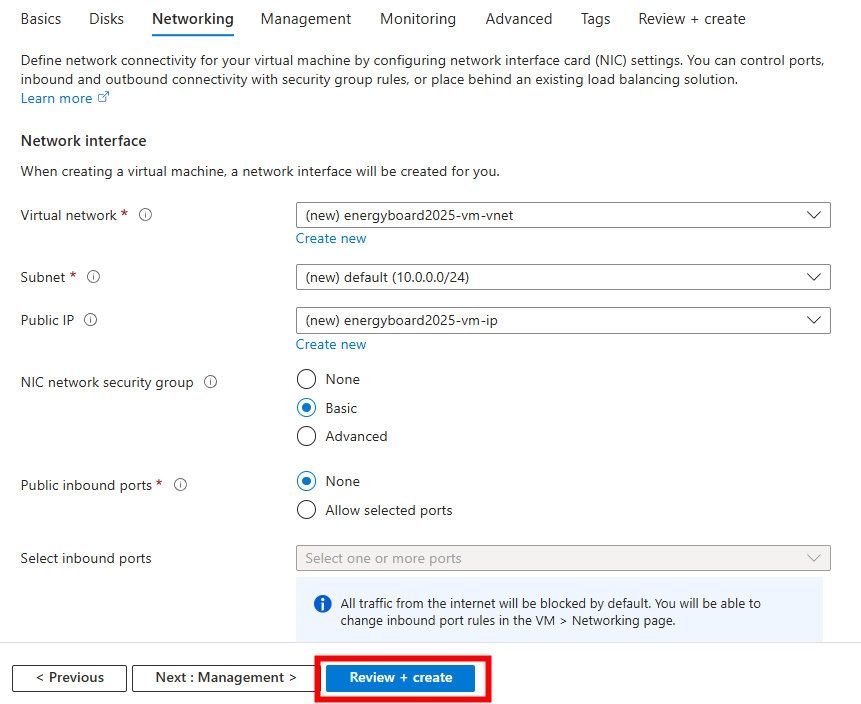
Conservez les options réseaux, puis lancez la validation Azure :
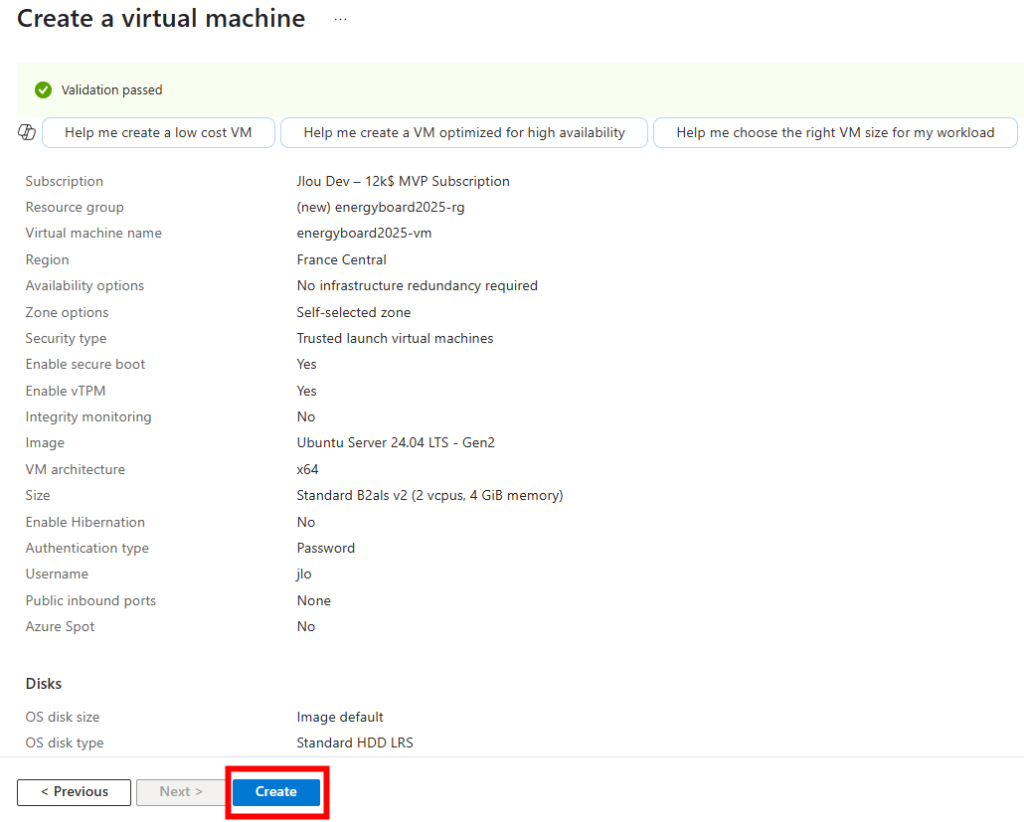
Une fois la validation réussie, lancez la création des ressources Azure :
Quelques minutes plus tard, cliquez-ici pour voir votre machine virtuelle :
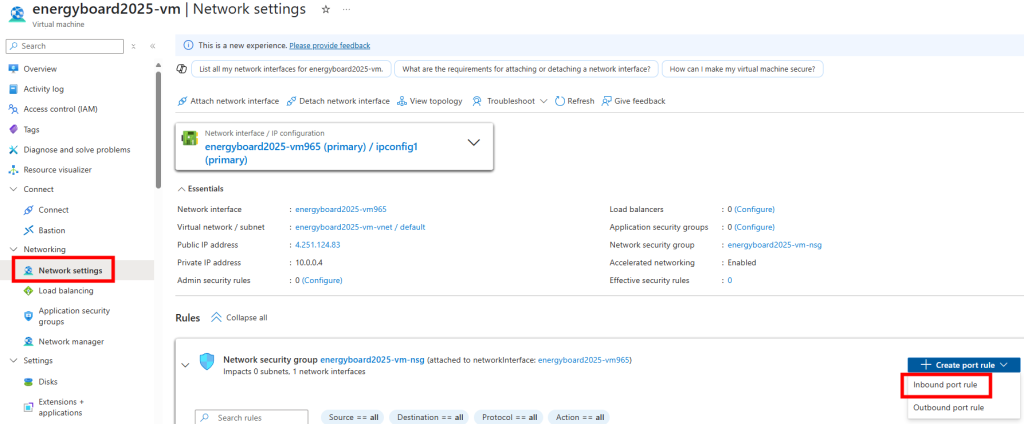
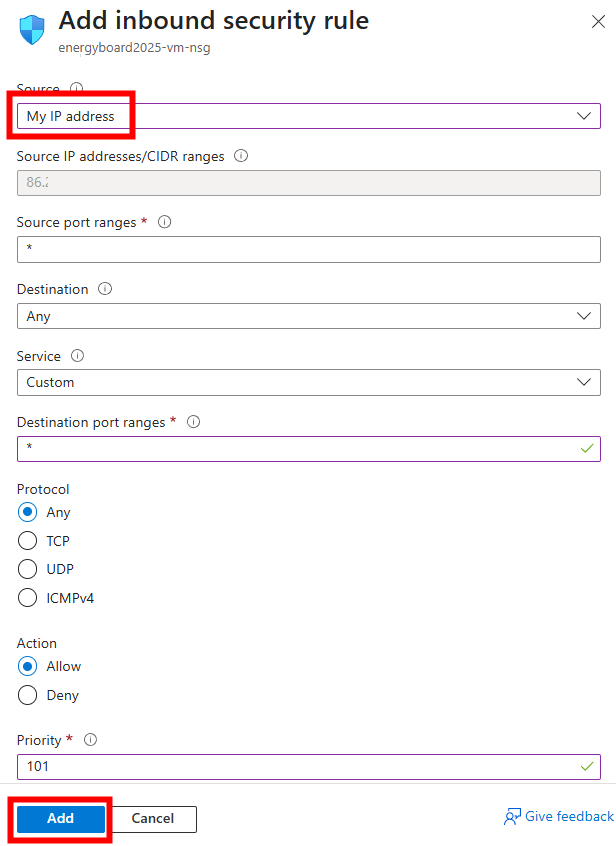
Ensuite, cliquez-ici pour déployer une règle entrante de réseau :
Ajoutez la configuration suivante pour autoriser les connexions depuis votre adresse IP publique, visible sur cette page, puis cliquez sur Ajouter :
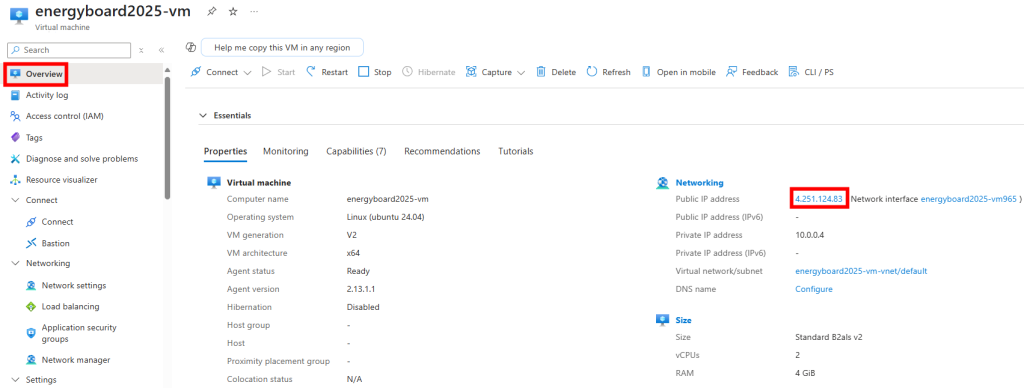
Retournez sur la page principale de votre machine virtuelle afin de copier l’adresse IP publique de celle-ci :
Depuis votre ordinateur, ouvrez Windows PowerShell :
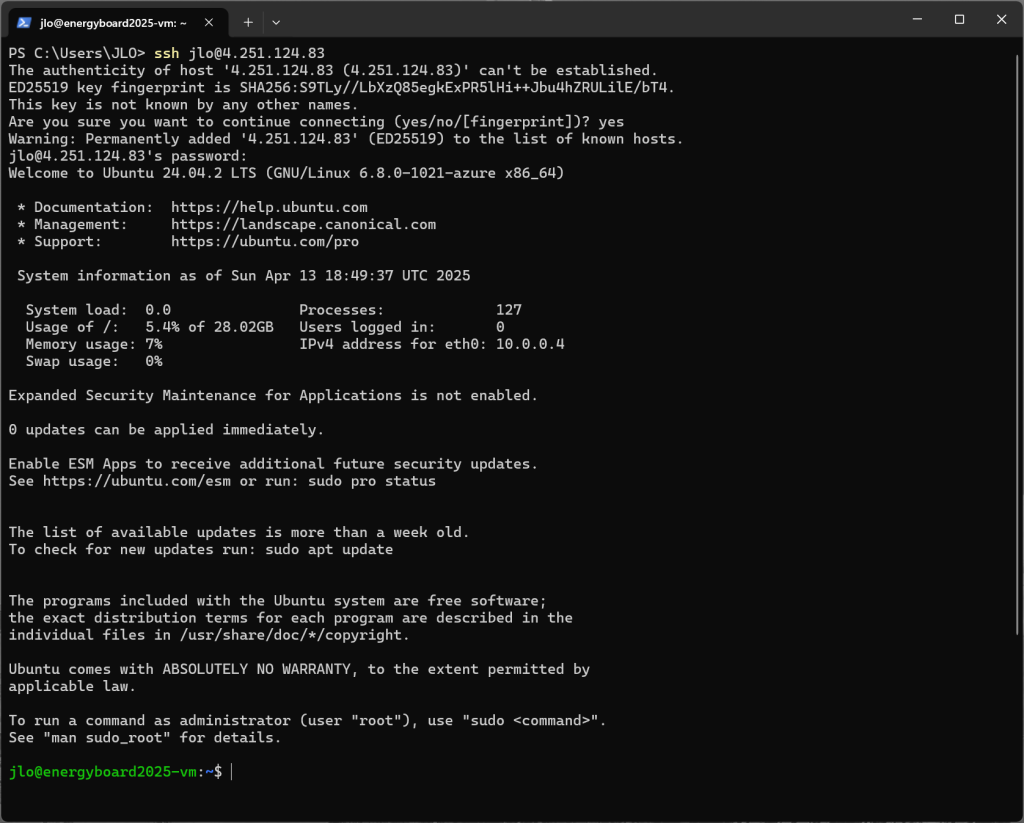
Connectez-vous en SSH à votre machine virtuelle Azure via son adresse IP publique précédemment copiée :
ssh VOTRE_NOM_UTILISATEUR@ADRESSE_IP_PUBLIQUE
Une fois connecté à votre machine virtuelle Azure, vous pouvez passer à l’étape suivante, consistant à installer et déployer Teslamate. Ce dernier va nous permettre de :
Stocker les données MQTT émises par la voiture Tesla
Consulter les données MQTT depuis EnergyBoard
Envoyer des ordres API via l’agent Proxy HTTP (facultatif)
Installer EnergyBoard sur un Raspberry Pi 5 offre l’avantage d’un serveur compact, économe en énergie et directement relié à votre installation 100% locale : vous avez accès nativement au Bluetooth local pour piloter votre Tesla et la passerelle Enphase sans passer par le cloud. Cette approche vous garantit une réactivité maximale et un contrôle complet de votre infrastructure.
Pour écrire cet article, j’ai donc acheté ce kit de démarrage Raspberry Pi 5 de 8Go, dont il en existe beaucoup sur internet :
Le mode opératoire décrit ci-dessous est inspiré de celui déjà disponible à cette adresse :
Pour installer l’application EnergyBoard sur votre Raspberry Pi 5, il vous faudra disposer de :
Un Raspberry Pi 5
Un poste local connecté en réseau au Raspberry Pi 5
Une connexion internet
une carte Micro-SD (dans le kit Raspberry Pi 5 acheté était fournie une carte Micro-SD de 64 Go avec un adaptateur USB-A/C)
Commençons par préparer l’OS du Raspberry Pi 5 à l’aide de notre poste local.
Etape I – Préparation de l’OS du Raspberry Pi 5 :
Branchez l’adaptateur contenant la carte Micro-D sur un port USB-A/C de votre poste local.
Sur votre poste, téléchargez le gestionnaire d’image OS pour Raspberry Pi depuis la page officielle :
Lancez l’exécutable téléchargé afin de l’installer l’outil de gestion d’image OS sur votre poste :
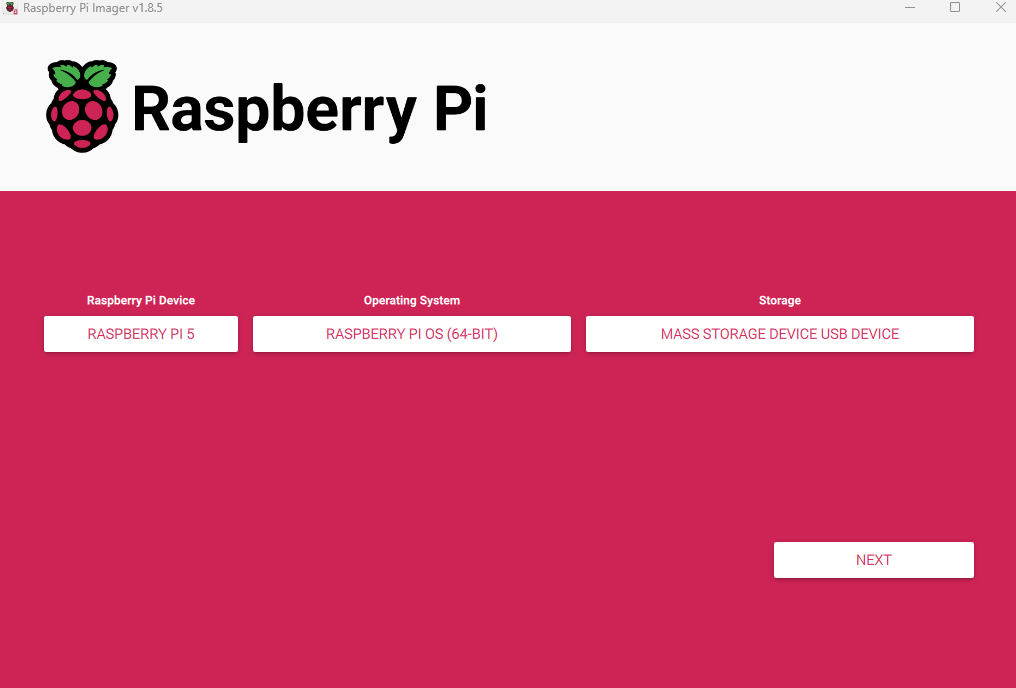
Une fois l’outil Raspberry Pi Image installé, lancez celui-ci, renseignez les 3 informations comme ceci, puis cliquez sur Suivant :
Cliquez sur le bouton suivant afin de personnaliser quelques réglages :
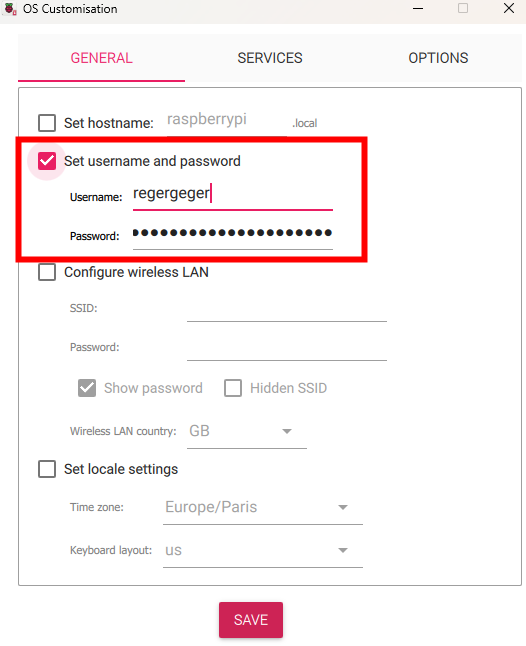
Sur le premier onglet, définissez le compte administrateur de votre choix, et si besoin la configuration wifi à utiliser :
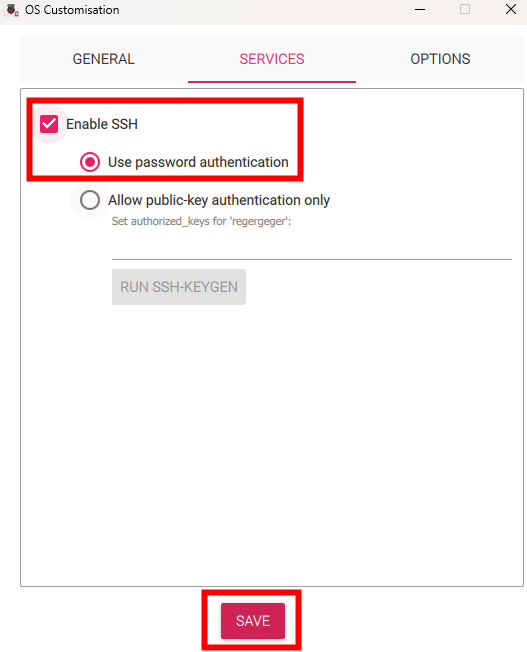
Sur le second onglet, autorisez l’accès SSH (protocole qui permet d’établir une connexion chiffrée pour accéder et administrer un système à distance), puis cliquez sur Sauvegarder :
Cliquez cette fois sur Oui :
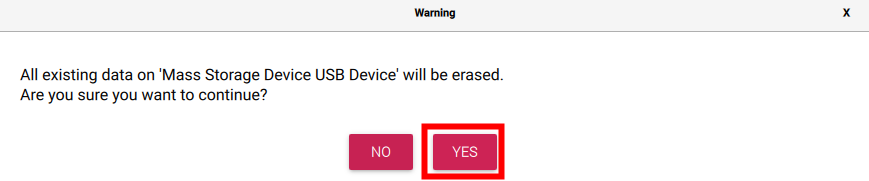
Confirmez l’écrasement des données en cliquant sur Oui :
Le traitement d’écriture sur la carte Micro-SD commence alors :
Attendez la fin des phases d’écriture et de vérification de la carte Micro-SD :
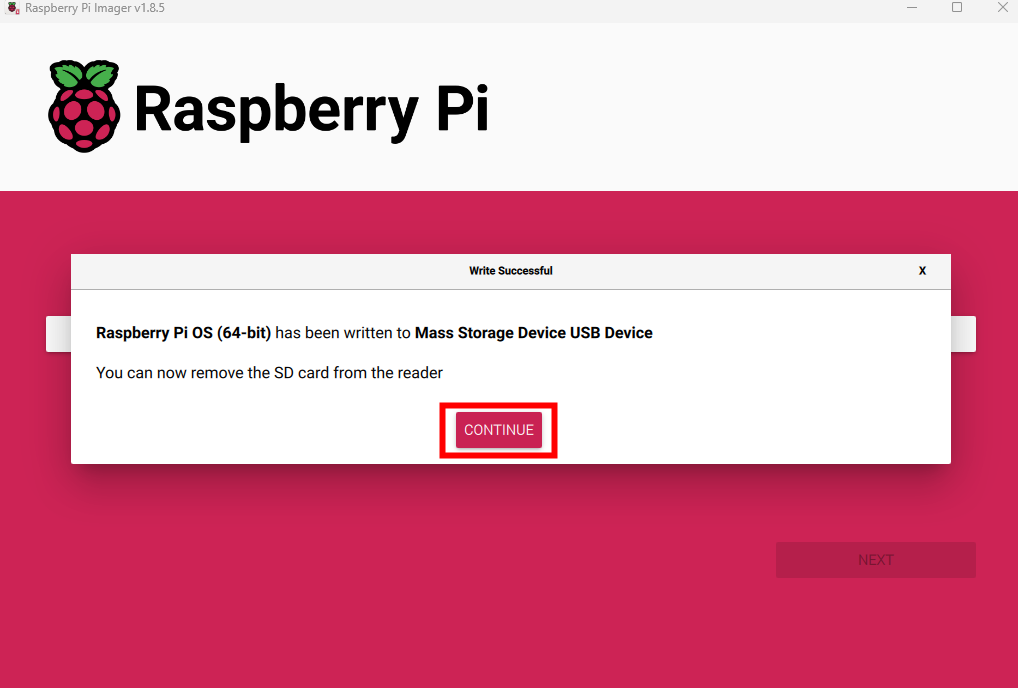
Une fois le processus terminé, retirer la carte Micro-SD, puis cliquez sur Continuez :
Insérer la carte Micro-SD dans votre Raspberry Pi 5, puis démarrez ce dernier.
En fonction de votre moyen de connexion de votre Raspberry Pi 5, ce dernier devrait disposer d’une adresse IP locale attribuée automatiquement par votre box (cette information est à vérifier et à obtenir sur la page de configuration réseau de votre box internet) :
Depuis votre ordinateur, ouvrez Windows PowerShell :
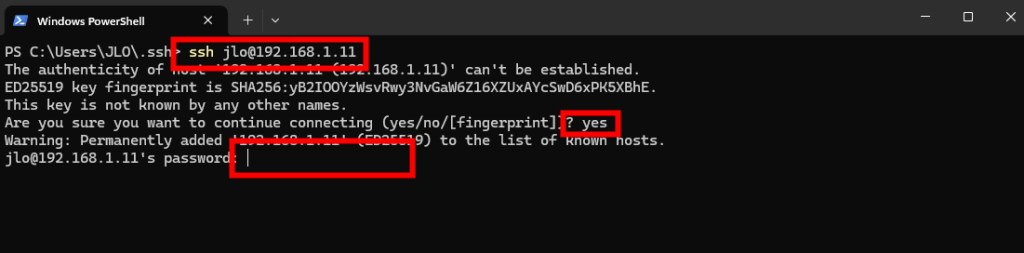
Connectez-vous en SSH à votre Raspberry Pi 5 via son adresse IP locale :
ssh VOTRE_NOM_UTILISATEUR@ADRESSE_IP_LOCALE
Une fois connecté à votre Raspberry Pi 5, vous pouvez passer à l’étape suivante, consistant à installer et déployer Teslamate. Ce dernier va nous permettre de :
Stocker les données MQTT émises par la voiture Tesla
Consulter les données MQTT depuis EnergyBoard
Envoyer des ordres API via l’agent Proxy HTTP (facultatif)
Comment exploiter GitHub Copilot pour améliorer sa pratique du code et élargir ses compétences, même sans être un expert ? Voir peut-on utiliser GitHub Copilot même si on n’est pas développeur du tout ? Pour ma part en tant que néophyte du dev, j’ai découvert qu’en posant les bonnes questions et en affinant peu à peu mes demandes, GitHub Copilot devient un véritable partenaire de réflexion dans le développement.
Ces dernières années nous ont appris que le dialogue constant avec l’IA permet de résoudre des problèmes concrets plus rapidement, tout en apprenant de nouvelles notions. Le potentiel est immense : c’est un formidable tremplin pour repousser ses limites et explorer de nouveaux horizons.
Pour ma part, je ne suis pas développeur de métier, et pour autant, j’ai toujours eu envie d’optimiser le rendement de mon installation photovoltaïque. Ayant des panneaux solaires depuis déjà plusieurs années, il était plus que temps pour moi de revoir mon taux très bas d’indépendance énergétique :
Qu’est-ce que le taux indépendance énergétique ?
Le taux d’indépendance énergétique est un indicateur qui mesure la part de votre consommation électrique totale couverte par votre propre production photovoltaïque, sans recours au réseau .
Concrètement, on le calcule ainsi :
Autoconsommation = part de votre production solaire que vous consommez directement
Indépendance énergétique = part de votre consommation qui vient de votre propre production
Exemple : si vous consommez 30 kWh sur une journée et que vous avez utilisé 20 kWh de votre production solaire, alors votre taux d’indépendance est de 66,7%.
Comment améliorer son taux d’indépendance énergétique ?
Voici plusieurs leviers pour augmenter un taux d’indépendance énergétique :
Stocker l’énergie
Installer une batterie domestique pour conserver le surplus de production et l’utiliser en soirée ou la nuit.
Piloter la recharge de votre véhicule électrique.
Utiliser un chauffe-eau ou un chauffe-eau thermodynamique asservi au surplus photovoltaïque.
Réduire et optimiser votre consommation
Améliorer l’isolation (toit, murs, fenêtres) pour limiter le besoin de chauffage et de climatisation.
Remplacer les équipements par des modèles à haute efficacité (LED, électroménager classé A+++).
Débrancher les veilleuses et appareils en veille qui continuent de consommer.
Déplacer les usages vers les heures de production
Programmer les gros consommateurs (lave-linge, lave-vaisselle, machine à café) en pleine journée.
Piloter intelligemment les consommateurs.
Qu’est-ce que EnergyBoard ?
EnergyBoard est une application web open-source développée à l’origine par Zzzzz avec le soutien de Mathieu3878 pour le code et de SolarFan pour la documentation et la traduction.
Elle a pour but de compléter et d’améliorer l’application officielle d’Enphase, Enlighten. Cette application :
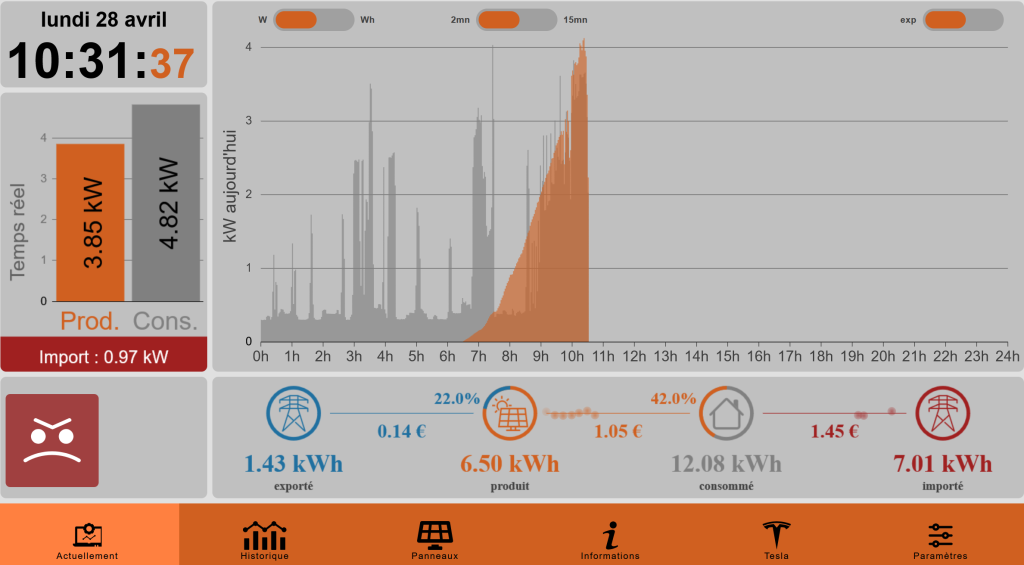
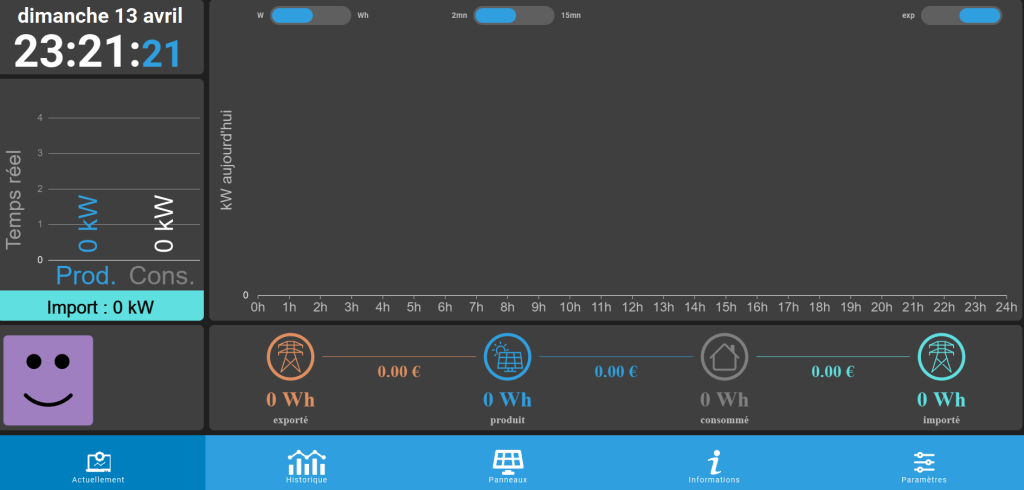
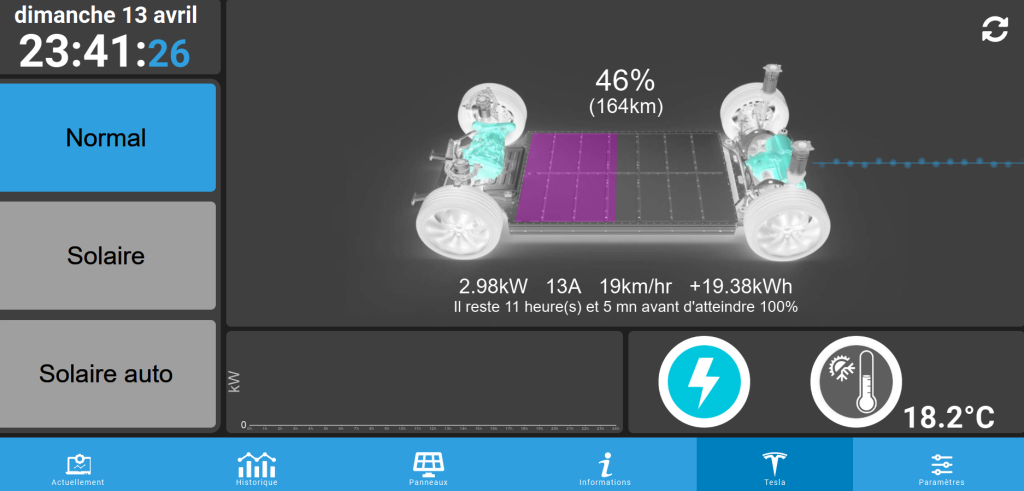
Affiche en temps réel la production photovoltaïque, la consommation du foyer, ainsi que l’énergie importée ou exportée ,
Propose des animations de flux, des courbes d’historique (2 s, 1 min, jour, mois, année) et un calendrier annuel,
Fournit des analyses avancées (météo annuelle de production, taux d’indépendance énergétique, taux d’autoconsommation) ,
Permet de piloter la charge d’une Tesla selon le surplus solaire ou des modes programmables.
En résumé, EnergyBoard transforme votre installation PV en dashboard intelligent, pour maximiser l’autoconsommation, visualiser vos données en live et automatiser vos recharges électriques. Voici quelques liens :
Tout fonctionnait parfaitement… jusqu’à ce que Tesla modifie son API…
Quel est le rapport avec GitHub Copilot ?
Comme Tesla avait modifié en 2024 le fonctionnement de ses API, EnergyBoard n’était plus en mesure de communiquer directement la voiture, et donc piloter la recharge dynamique.
Souhaitant réinstaurer le lien entre EnergyBoard et la voiture Tesla, et plutôt que de repartir de zéro, je me suis tourné vers l’intelligence artificielle : GitHub Copilot pour suggérer des bouts de code, et ChatGPT pour m’expliquer certaines notions, comme par exemple la gestion des tokens, la mise en place de proxys, l’orchestration de conteneurs et la sécurisation des secrets…
Grâce à à ces deux IAs, j’ai pu :
Interfacer la nouvelle Fleet API de Tesla et gérer les différents tokens.
Ajouter une couche de communication directe en Bluetooth entre l’application EnergyBoard et la voiture Tesla.
Gérer les retours de données de la Tesla provenant de 3 sources distinctes :
API (Serveurs Tesla + Voiture)
MQTT (Push Serveurs Tesla)
Bluetooth (Voiture)
Ajouter un journal événements précis concernant les actions Tesla déclenchées par l’application.
Ajouter d’autres interfaces avec des applications tierces :
L’intelligence artificielle m’a donc servi de copilote technique, accélérant ma montée en compétences sur l’authentification, la gestion des secrets et les patterns d’architecture, tout en me permettant de rester productif même sans être développeur expert.
Et maintenant ?
Suite aux retours et aux tests, dans la version 0.9.37, est introduit la prise en charge native des appels Bluetooth pour piloter la Tesla en local.
Cette approche est non seulement plus simple à configurer (plus besoin de relayer systématiquement toutes les requêtes via l’API Tesla cloud), mais elle permet aussi une mise en place et des temps de réponse beaucoup plus rapides dans un environnement réseau 100% local.
Et si l’on souhaite quand même communiquer par API ?
Si l’on souhaite aussi communiquer via l’API cloud, j’ai créé une version alternative d’EnergyBoard, capable de gérer à la fois les appels Bluetooth et les requêtes API. Le processus d’installation et d’enrôlement API est un peu complexe et nécessite du matériel adapté (clé Bluetooth, token Tesla, configuration réseau, etc.), mais tout est détaillé dans les articles ci-dessous, organisés en sections :
Chacun de ces articles vous guide pas à pas, du déploiement sur Raspberry Pi, ou sur une machine virtuelle Azure, ou jusqu’à la mise en service des connexions Bluetooth et API Tesla.
J’ai pris un immense plaisir à explorer cette passerelle entre intelligence artificielle et code : passer de simples idées à une application à nouveau fonctionnelle m’a non seulement permis d’élargir mes compétences bien au-delà de mon profil « IT généraliste ».
Que vous soyez néophyte ou développeur aguerri, je vous encourage vivement à vous lancer : GitHub Copilot et ChatGPT sont des alliés formidables pour vous guider, vous faire gagner un temps précieux et vous aider à comprendre des concepts qui paraissent souvent abstraits.
Au-delà du projet EnergyBoard, ces outils nous offrent une véritable boîte à outils cognitive, capable de nous accompagner dans tous nos domaines de prédilection. Alors, pourquoi ne pas embarquer votre prochain challenge sous le bras et laisser l’IA vous copiloter vers l’innovation ?
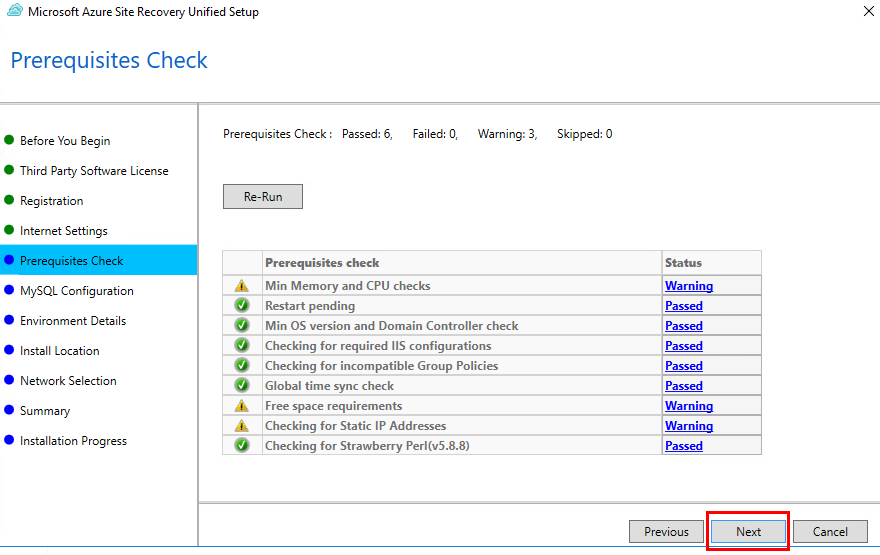
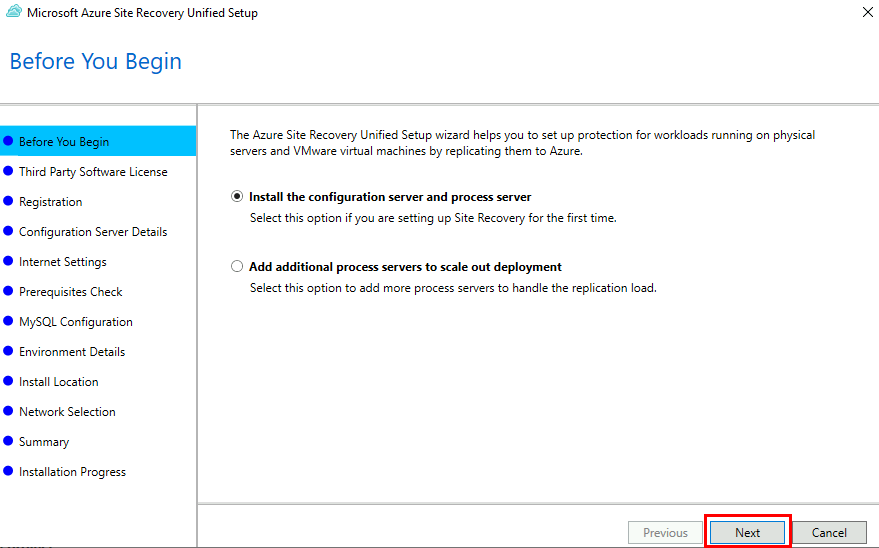
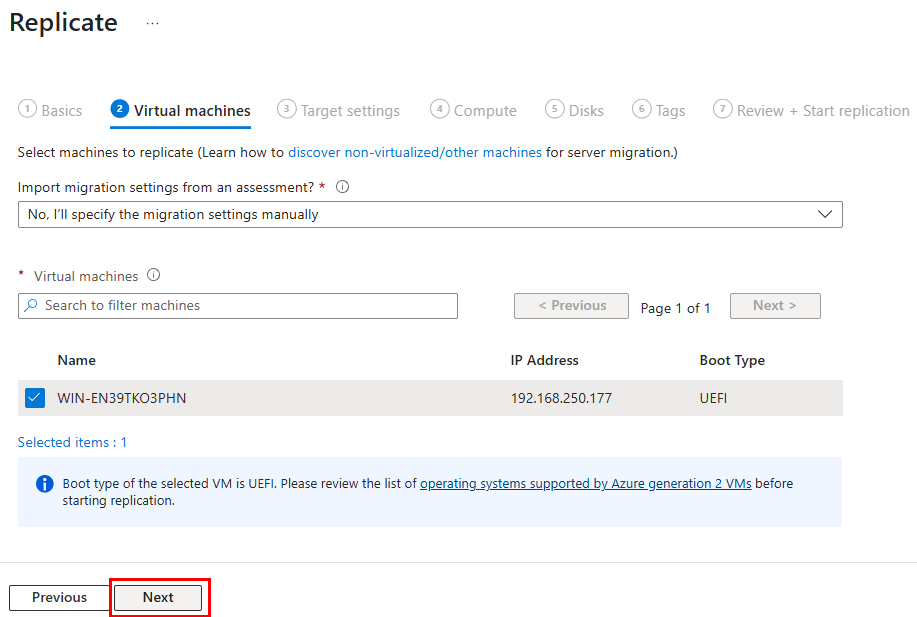
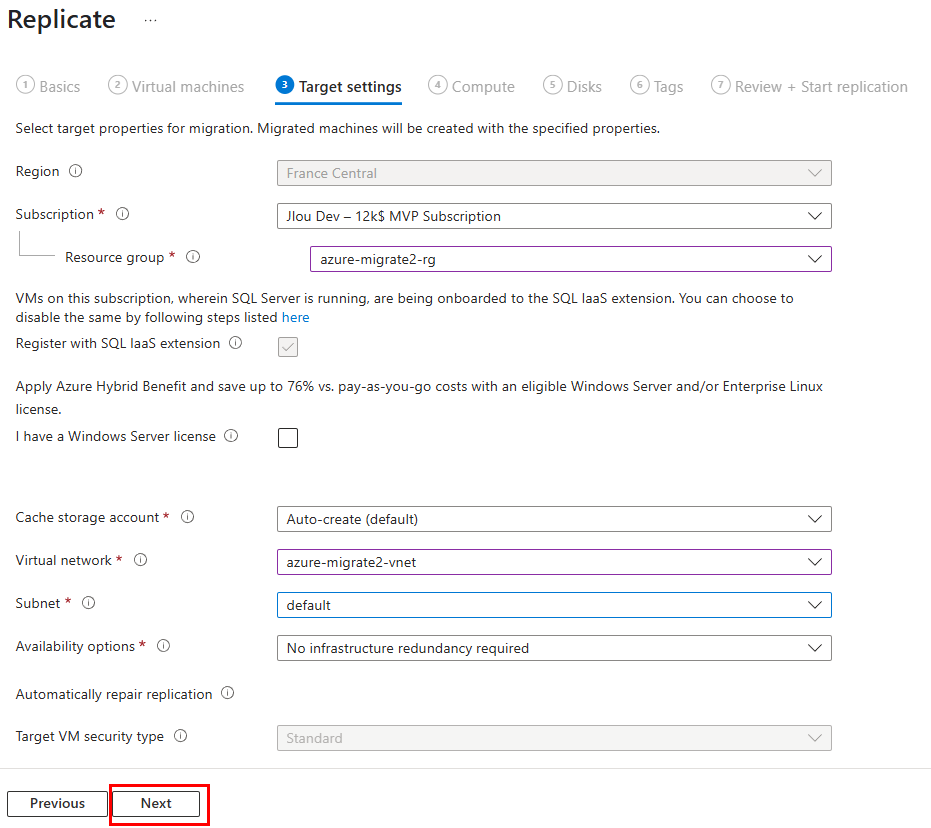
Réussir la migration d’une infrastructure IT nécessite un objectif clair, un plan d’action, des moyens humains et matériels, et …. , du temps devant soi. Mais il arrive que la migration ne soit pas un parcours de santé, mais plutôt jonché de contraintes impactant les stratégies décidés avant. Par exemple, que doit-on faire si la migration de VMs doit se faire finalement sans aucun accès au niveau hyperviseur ?
Différentes approches de migration ?
Lors d’une migration vers le cloud, plusieurs approches coexistent : le « lift-and-shift » (reprise à l’identique), la replatforming ou refactoring (adaptation partielle) et la reconstruction totale accompagnée de modernisation.
Si le lift-and-shift est souvent privilégié pour sa rapidité de mise en œuvre, il n’exploite pas pleinement les services cloud-native et peut engendrer un surcoût opérationnel à long terme.
À l’inverse, la refonte ou la reconstruction des applications, en recourant par exemple aux microservices, au serverless ou aux bases de données managées, permet d’améliorer la scalabilité, la résilience et l’agilité, tout en optimisant les coûts à terme.
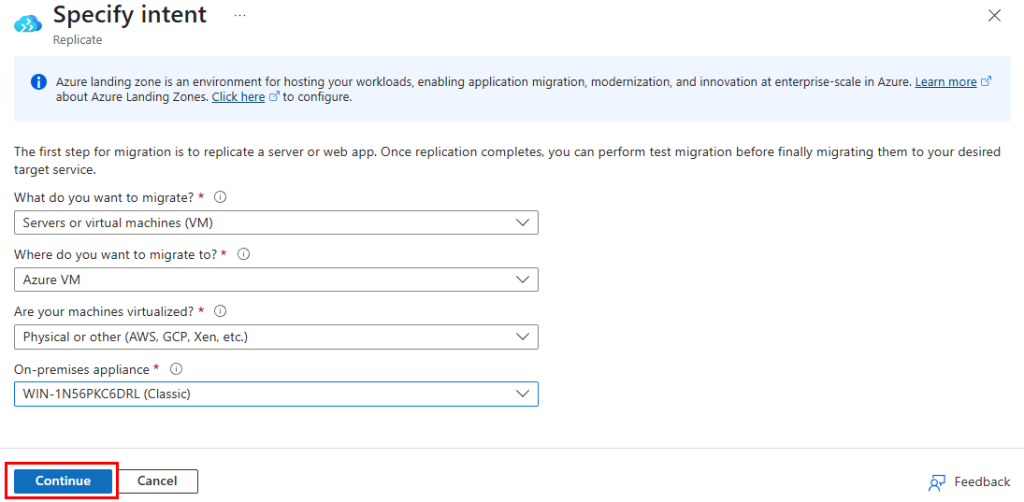
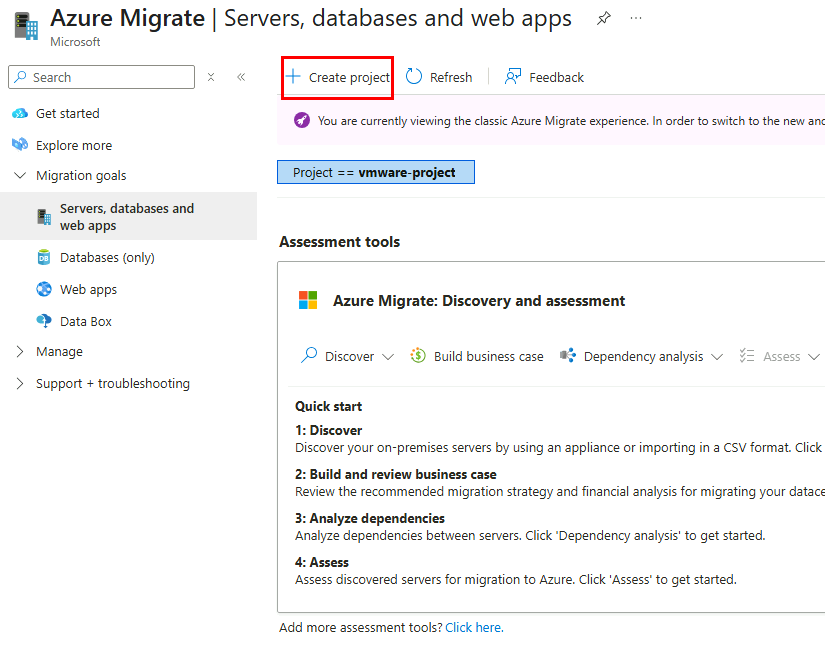
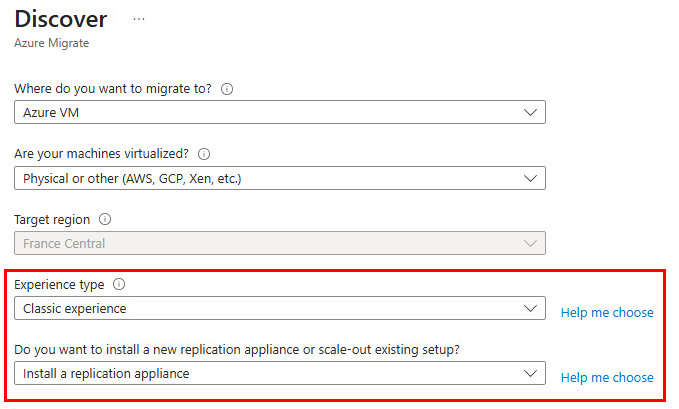
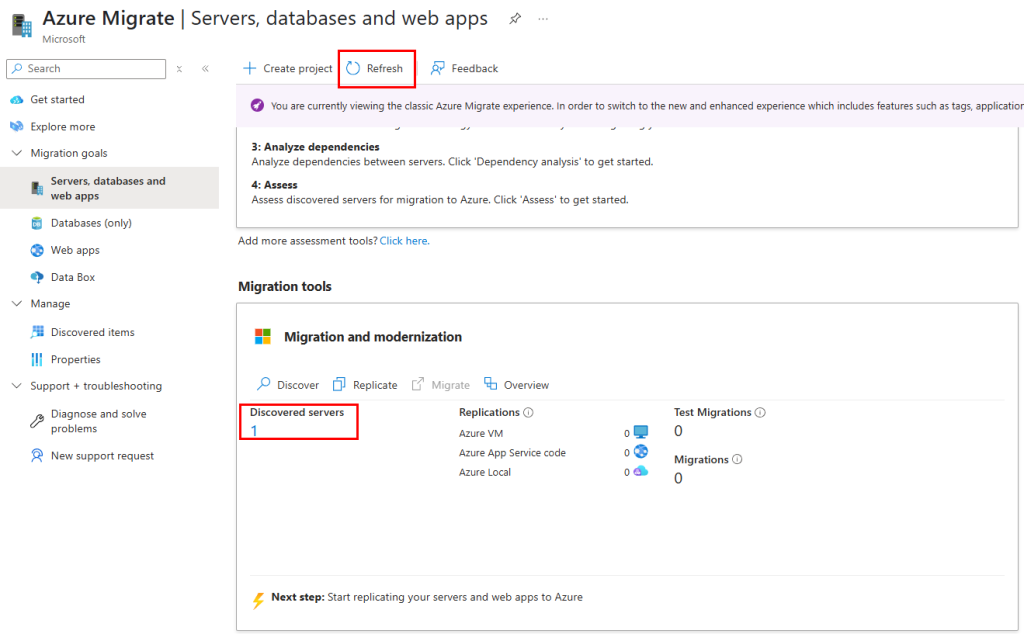
Azure Migrate ?
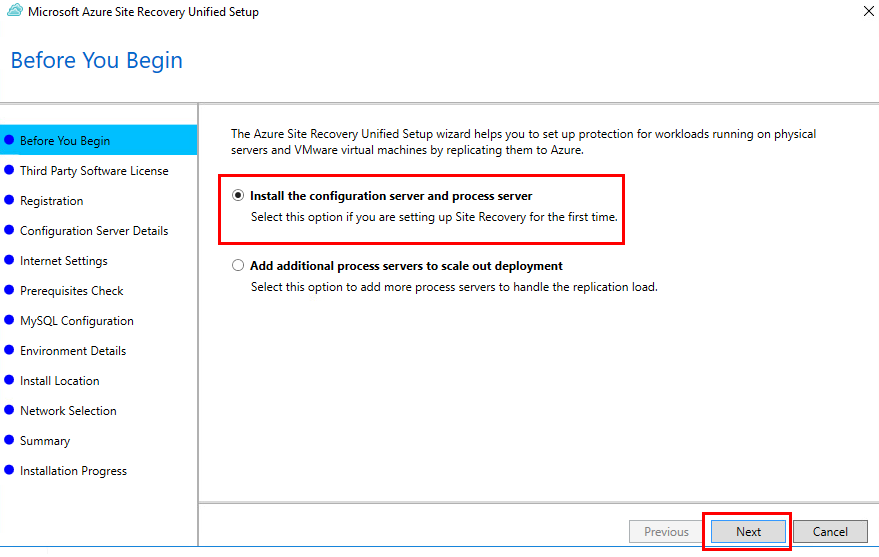
Bien entendu, dans certains scénarios, notamment lorsqu’on fait face à des délais serrés, à des contraintes budgétaires ou à un manque de compétences, il est nécessaire de migrer en priorité les machines virtuelles existantes « telles quelles ».
On opte alors pour un lift-and-shift à l’aide d’outils comme Azure Migrate ou Azure Site Recovery, qui répliquent les VM sans toucher au code ni à l’architecture.
Pour vous donner un peu de matière, un ancien article parlant d’Azure Migrate vous détaille toutes les grandes étapes.
Mais que faire si l’accès à l’hyperviseur est restreint ?
Toutefois, si aucun niveau d’accès la couche hyperviseur n’est possible, la migration vers Azure s’en trouve alors un peu plus compliquée.
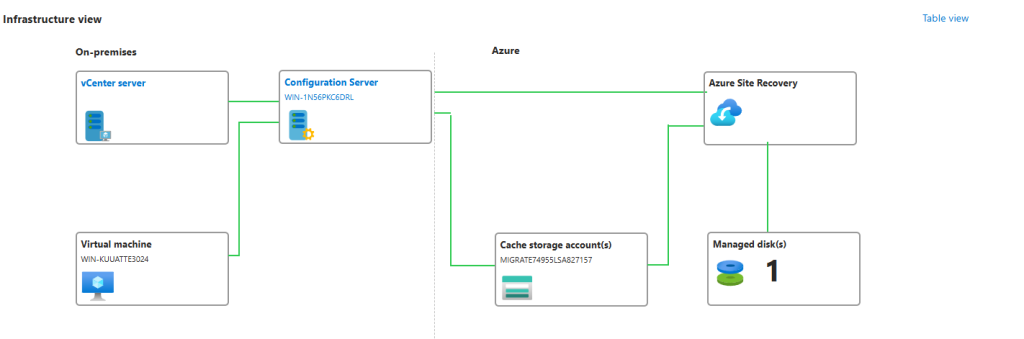
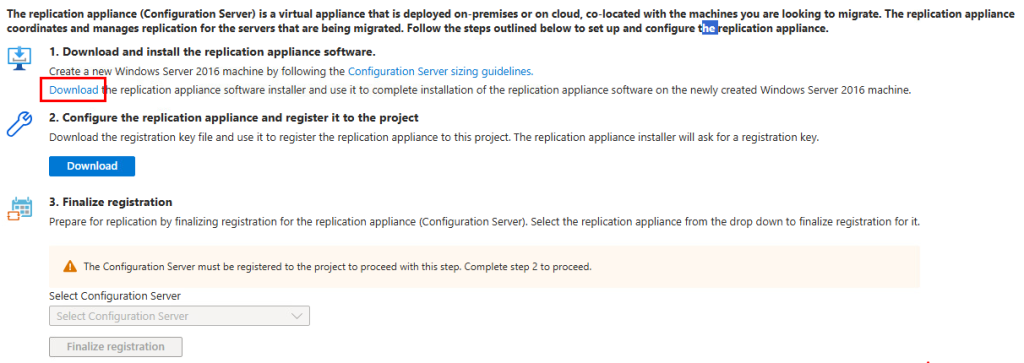
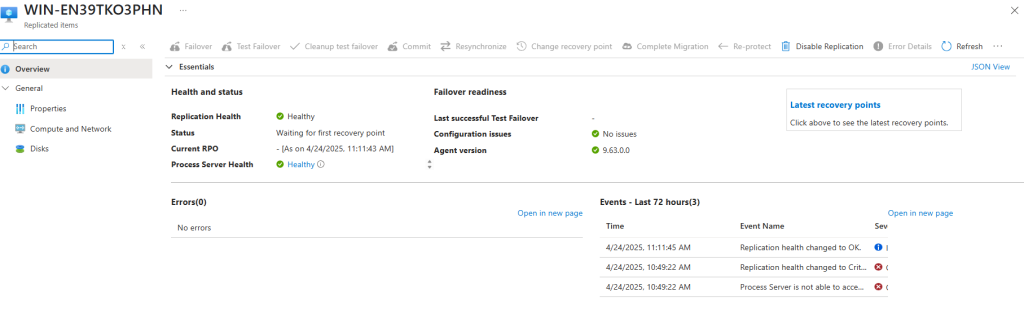
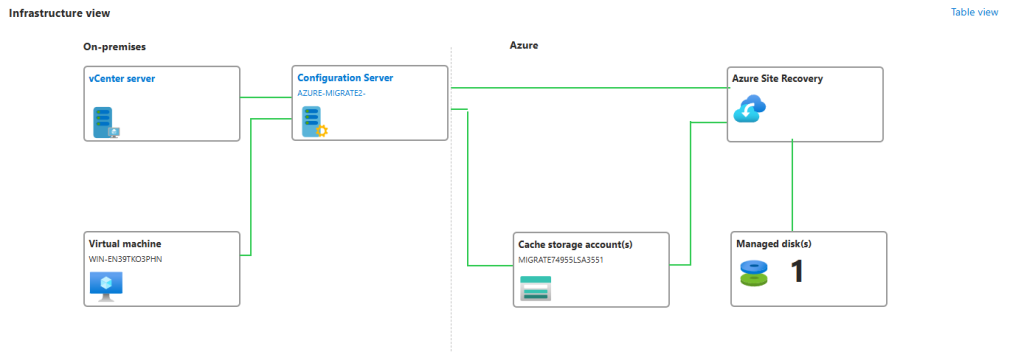
Dans le cadre d’Azure Migrate (et plus précisément du service de réplication Azure Site Recovery), on rencontre 2 rôles clés au sein de l’appliance de réplication déployée :
Serveur de traitement :
Installé par défaut sur le serveur de configuration, il reçoit les données de réplication envoyées par le Mobility Service installé sur vos machines sources.
Il optimise ces flux en effectuant de la mise en cache, de la compression et du chiffrement, puis les transmet vers votre compte de stockage Azure.
Serveur de cible principale :
N’est utilisé que lors du failback (reprise sur site) des machines dès lors qu’elles ont été basculées vers Azure.
Il reçoit alors les données répliquées en provenance d’Azure, reconstitue les disques (VHD/VMDK) et les écrit sur votre infrastructure on-premises pour restaurer les VM sur site.
En synthèse, le Process Server gère l’envoi optimisé des données vers Azure, tandis que le Master Target Server gère la réception et la restauration de ces mêmes données lors d’un retour en local.
En voyant cette excellente vidéo en mode tutoriel, je trouvais intéressant de tester par moi-même ce cas de figure, en partant d’un environnement VMware vers Azure, sans pouvoir utiliser l’accès hyperviseur.
Cet article est donc divisé en 2 démonstrations quasi-identiques :
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
Etape 0 – Rappel des prérequis :
Afin de réaliser nos 2 tests de migration, nous allons avoir besoin de :
Un tenant Microsoft actif
Une souscription Azure valide
Un environnement hypervisé (Hyper-V ou VMware)
Commençons par effectuer l’exercice de migration en partant du principe que nous pouvons déployer une machine virtuelle jouant le rôle de d’appliance de réplication sur VMware.
Test I – Appliance de réplication VMware :
Sur votre console hyperviseur, créez une machine virtuelle de type Windows Serveur afin d’y installer par la suite notre appliance de réplication :
Connectez-vous à celle-ci avec un compte administrateur local :
Si besoin, installez un navigateur internet récent :
Connectez-vous au portail Azure, puis recherchez le service Azure Migrate :
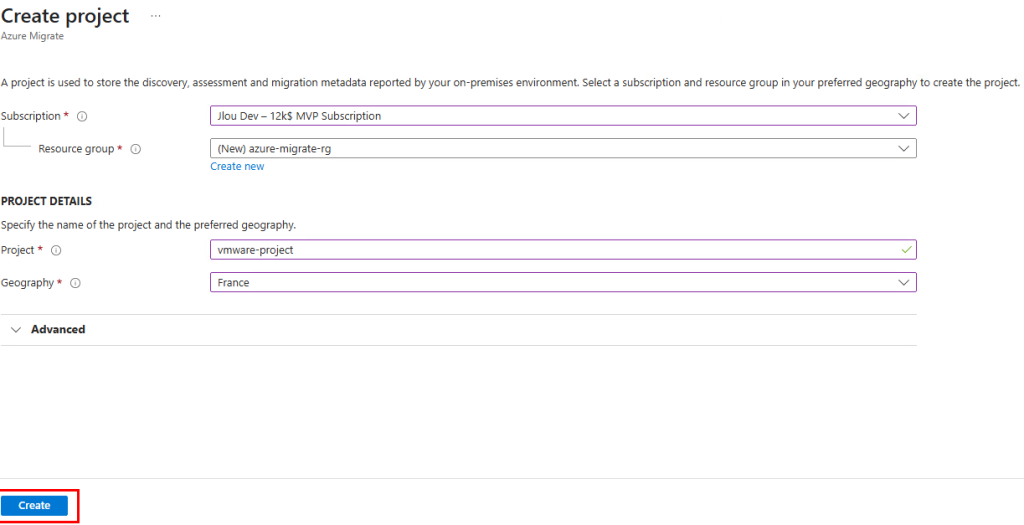
Cliquez-ici pour commencer un nouveau projet de migration :
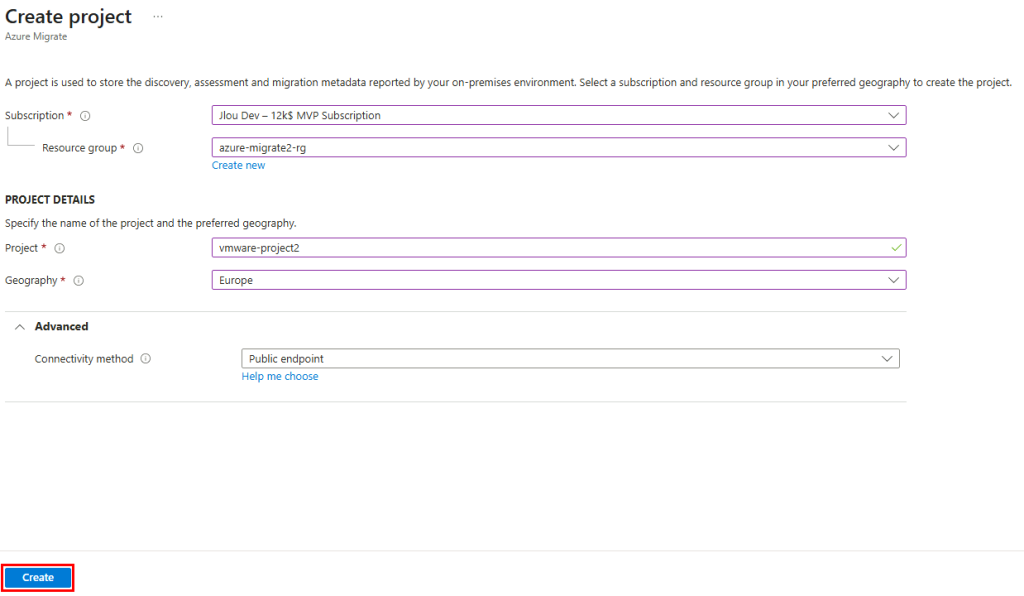
Cliquez-ici pour créer le projet de migration :
Renseignez les toutes informations demandées, puis cliquez sur Créer :
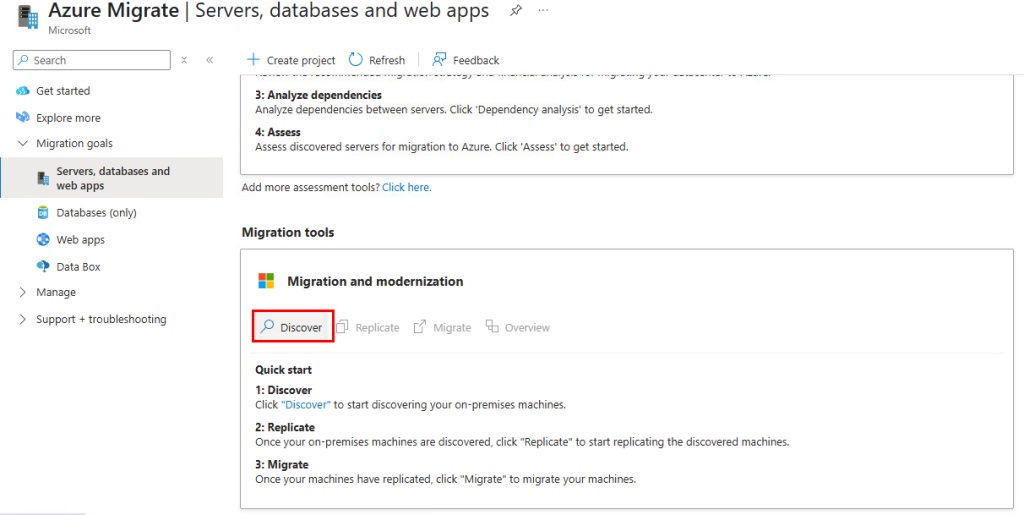
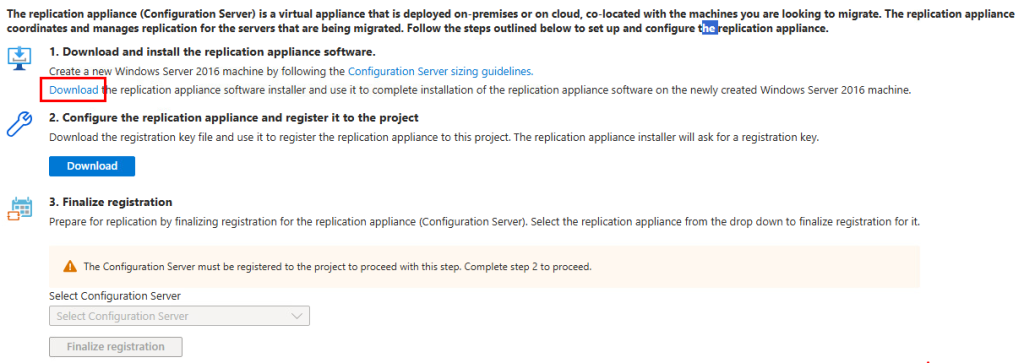
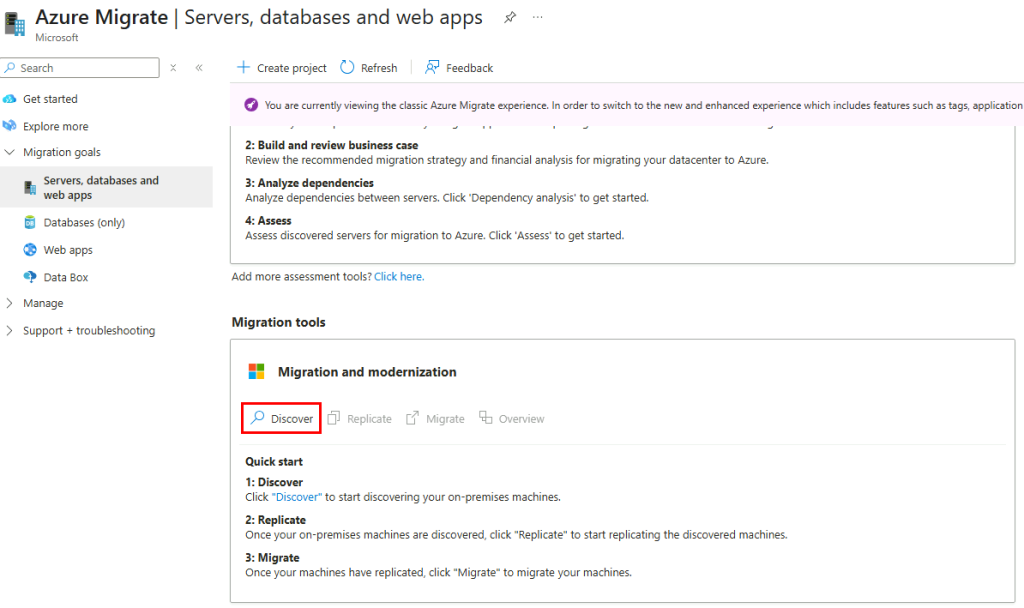
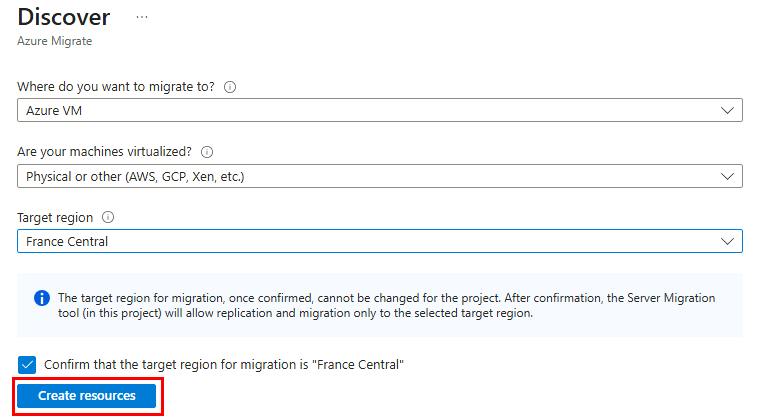
Cliquez sur Découvrir afin d’installer l’appliance de réplication :
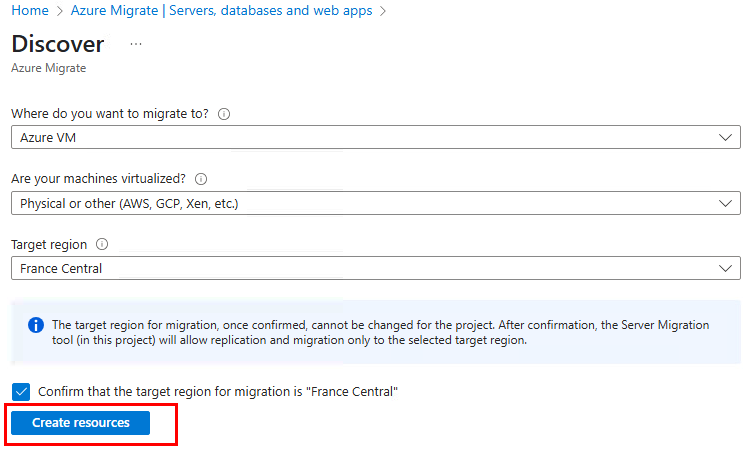
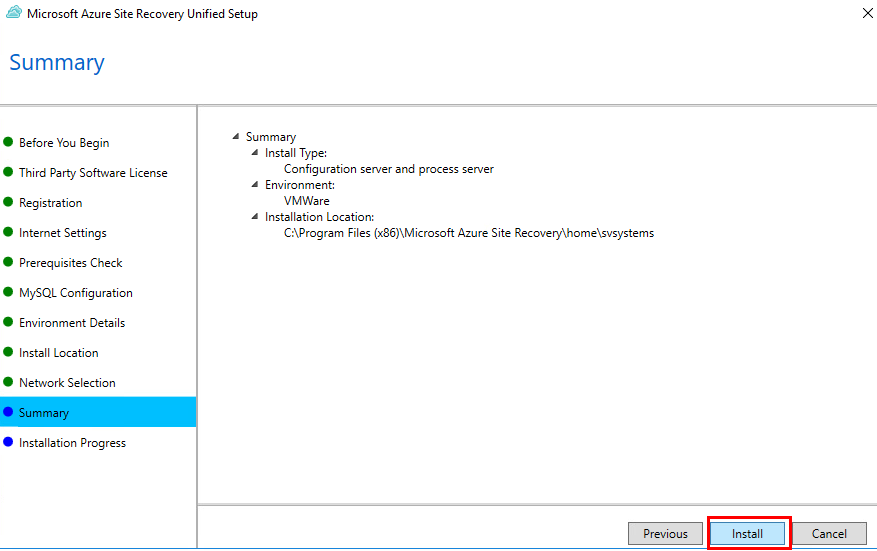
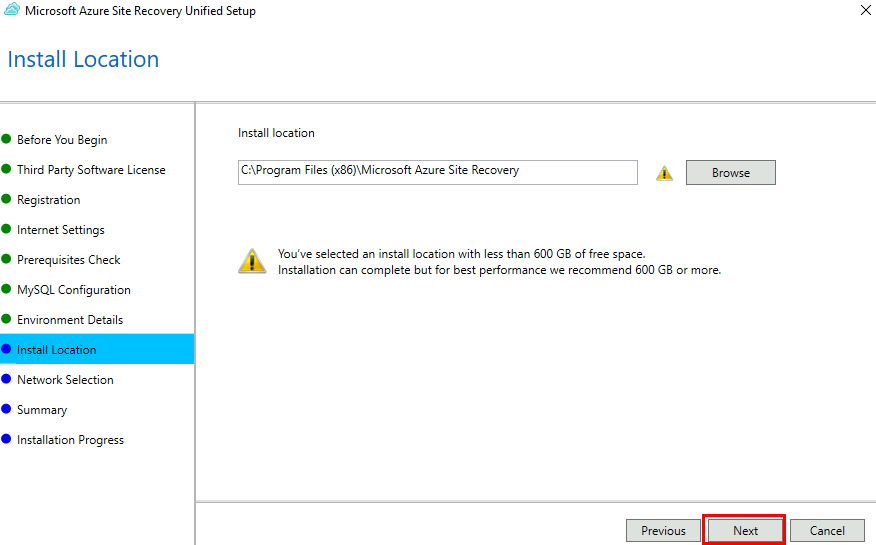
Renseignez tous les champs, puis cliquez sur Créer les ressources :
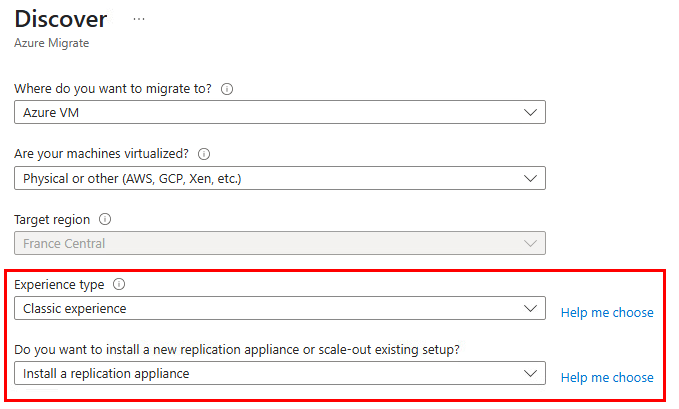
Conservez les options suivantes :
Cliquez sur le bouton suivant afin de télécharger l’installeur de l’appliance de réplication :
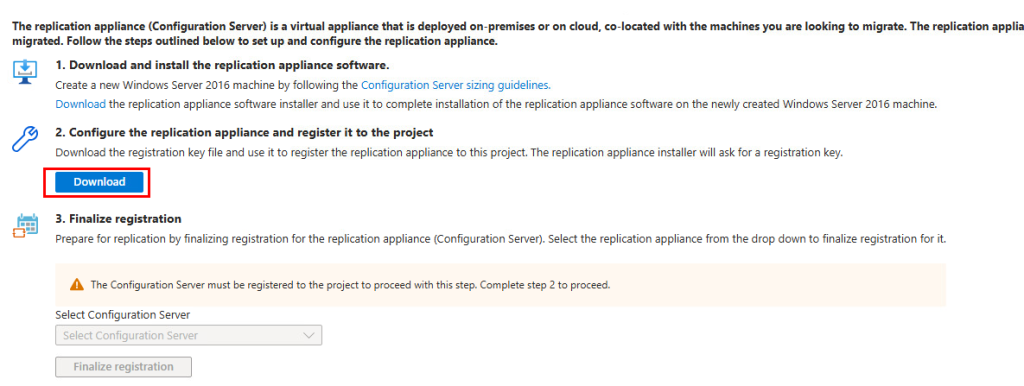
Cliquez également sur le bouton suivant afin de sauvegarder la clef utilisée par l’appliance de réplication pour s’enrôler au coffre Azure Recovery :
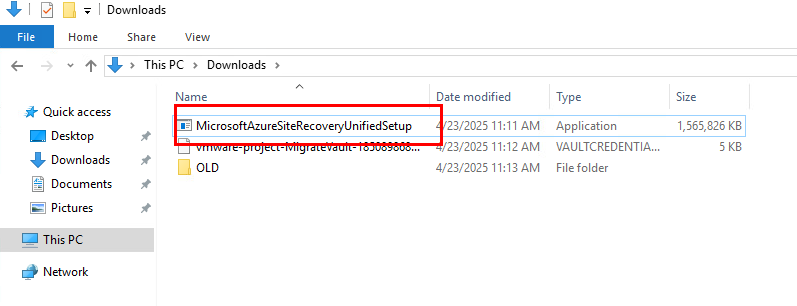
Lancez l’installeur de l’appliance de réplication :
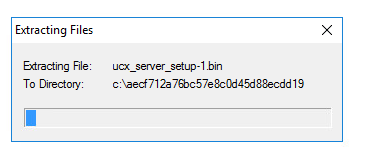
Attendez quelques minutes la fin de la décompression :
Conservez ce choix, puis cliquez sur Suivant :
Acceptez les termes et conditions, puis cliquez sur Suivant :
Rechercher le fichier clef, puis cliquez sur Suivant :
Conservez ce choix, puis cliquez sur Suivant :
Attendez que tous les contrôles soit effectués, puis cliquez sur Suivant :
Définissez un mot de passe pour la base de données MySQL, puis cliquez sur Suivant :
Si cela est votre cas, cochez cette case, puis cliquez sur Suivant :
Cliquez sur Suivant :
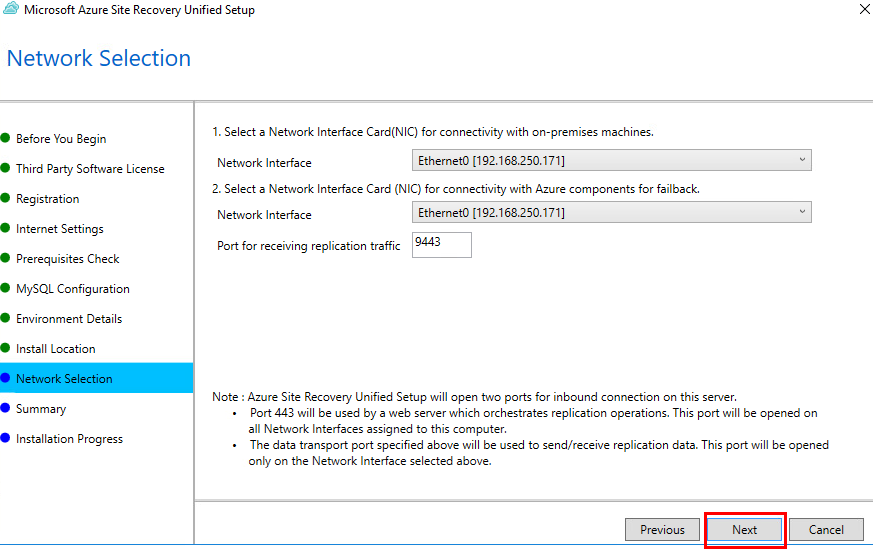
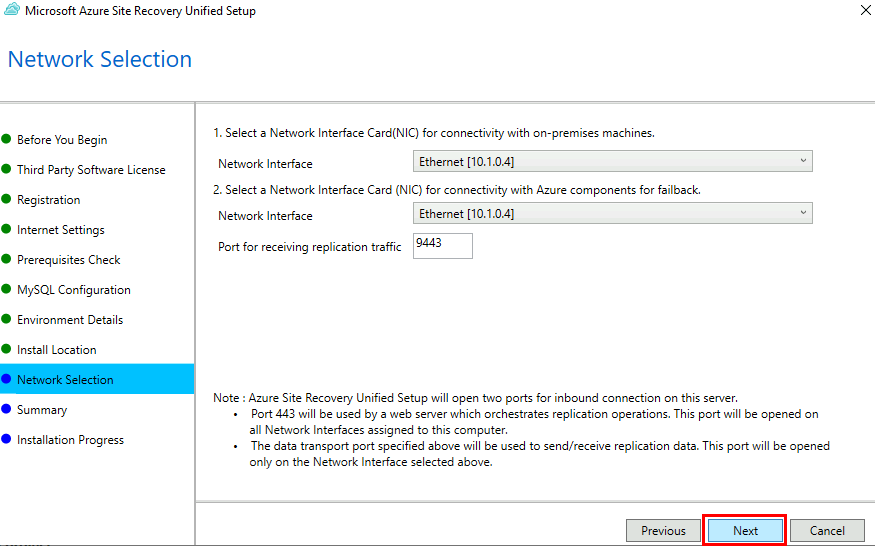
Définissez les 2 liaisons réseaux, puis cliquez sur Suivant :
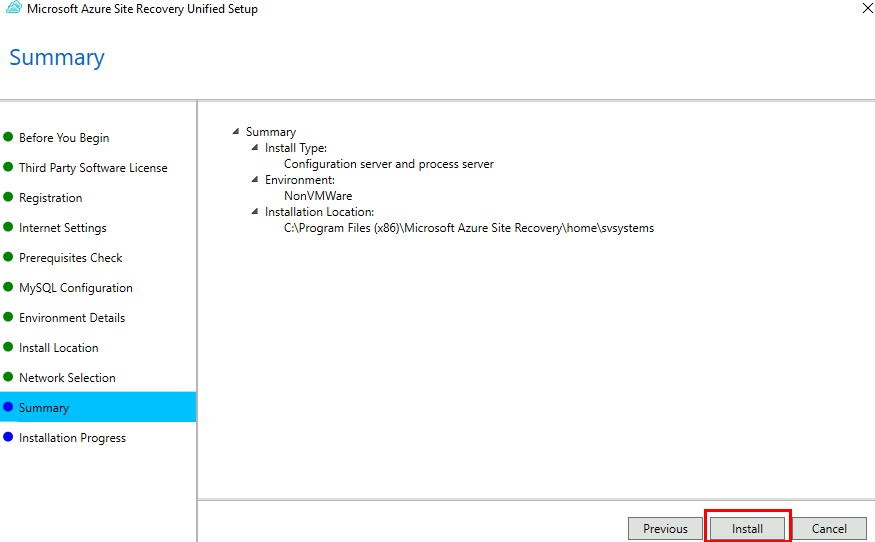
Cliquez sur Installer :
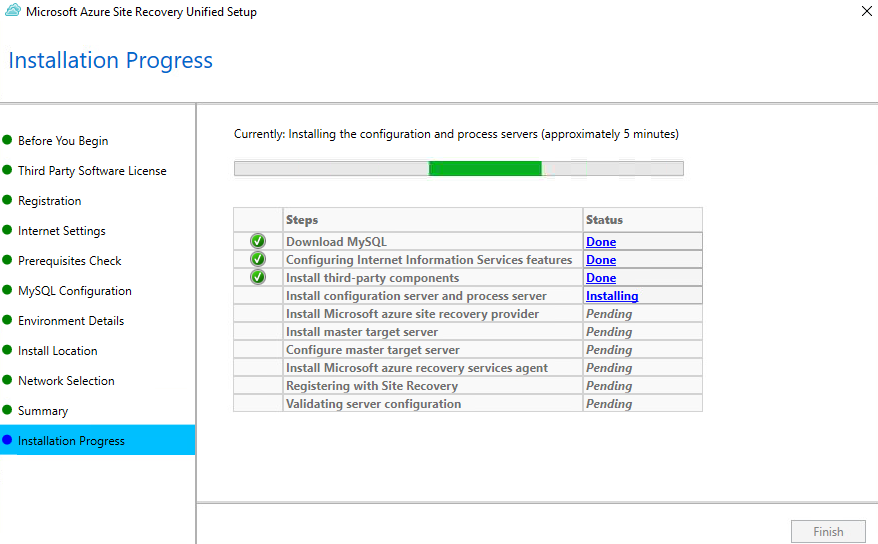
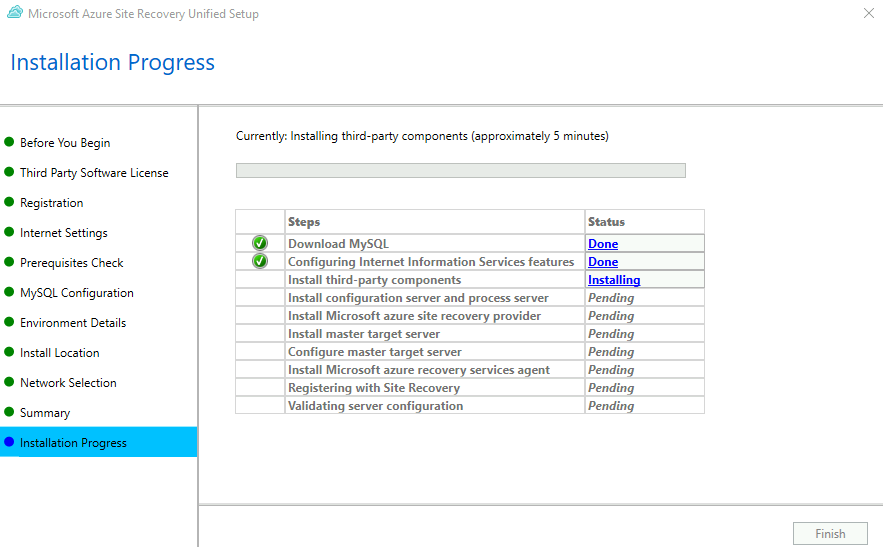
Attendez environ 10 minutes la fin de l’installation de l’appliance de réplication :
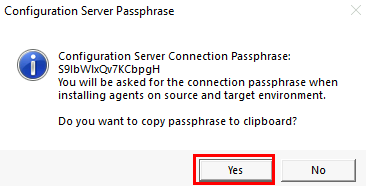
Cliquez sur Oui :
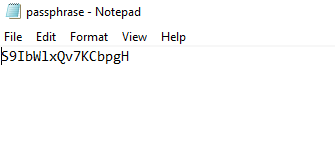
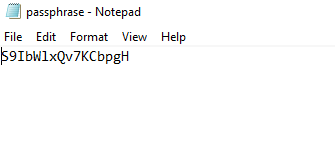
Collez cette passphrase dans un fichier texte, puis sauvegardez-le :
Une fois l’installation réussie, cliquez sur Terminer :
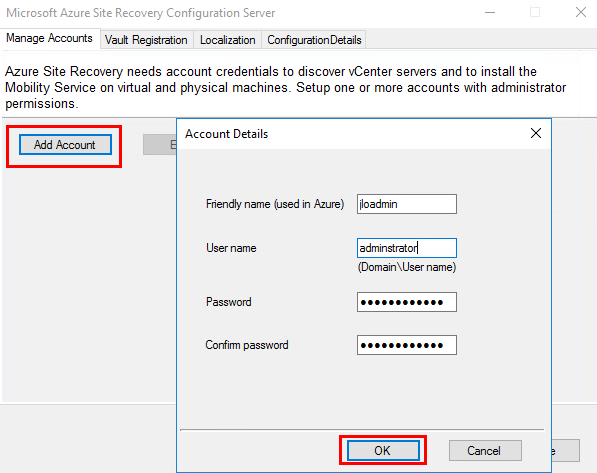
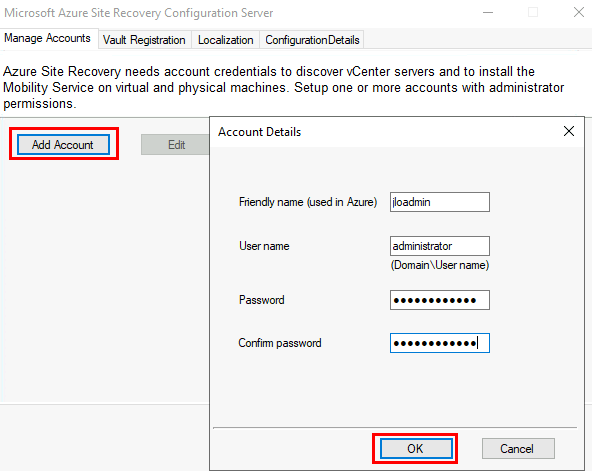
L’outil de configuration d’Azure Site Recovery s’ouvre automatiquement, ajoutez-le ou les comptes administrateur de vos machines devant être migrées dans le cloud Azure :
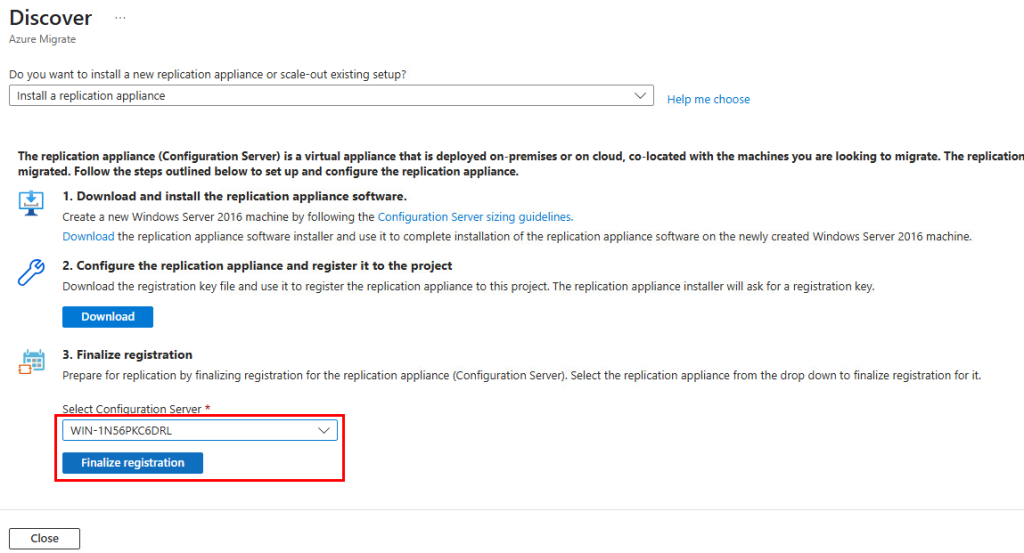
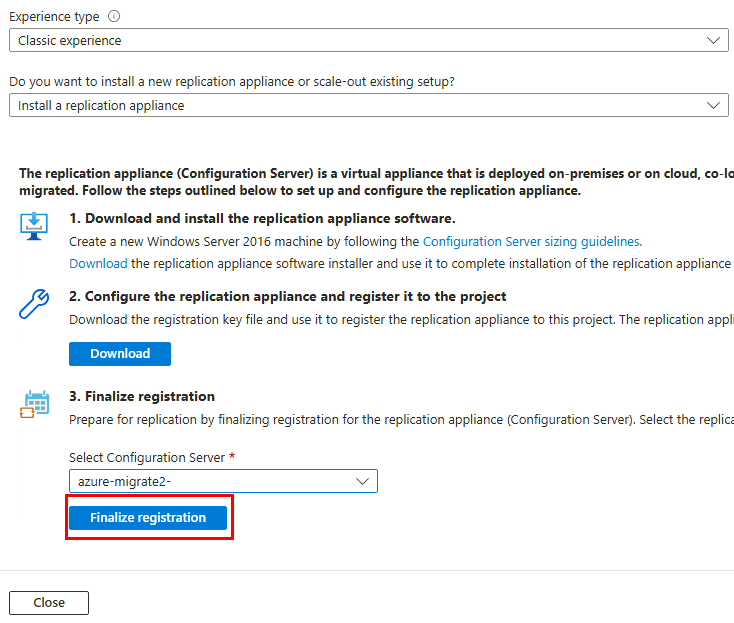
Retournez sur le portail Azure, rafraîchissez la page précédente, puis cliquez ici pour finaliser le processus d’enregistrement de l’appliance de réplication :
Attendez le succès de l’opération via la notification suivante :
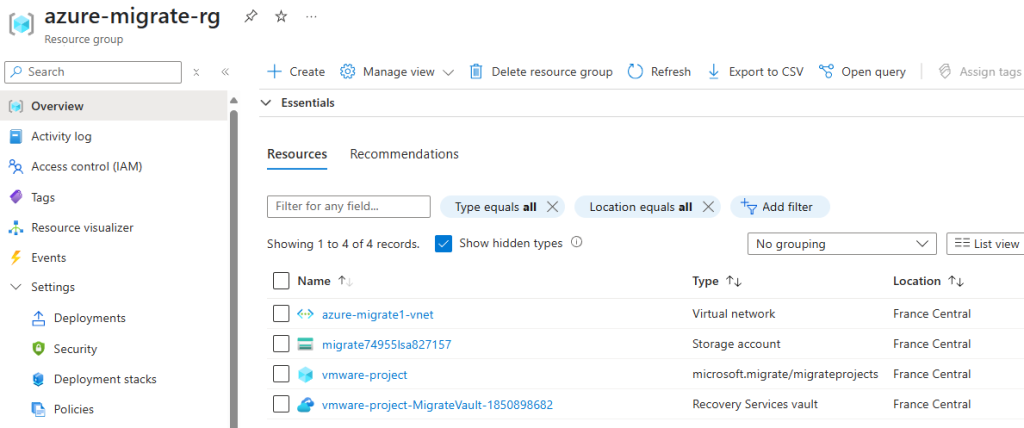
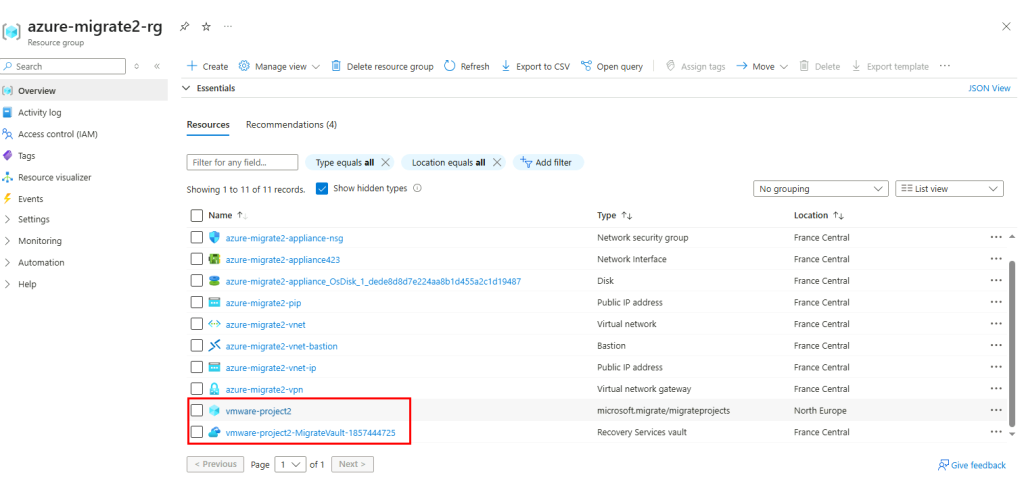
Constatez la création de ressources dans le groupe de ressources précédemment défini :
Retournez sur l’appliance de réplication, rendez-vous dans le dossier suivant, puis copiez l’exécutable ci-dessous :
Créez un dossier partagé réseau sur votre appliance de réplication, puis collez-y l’exécutable précédemment copié ainsi que le fichier texte contenant la passphrase :
Retournez sur la console hyperviseur, puis connectez-vous à la machine virtuelle devant être migrée vers Azure :
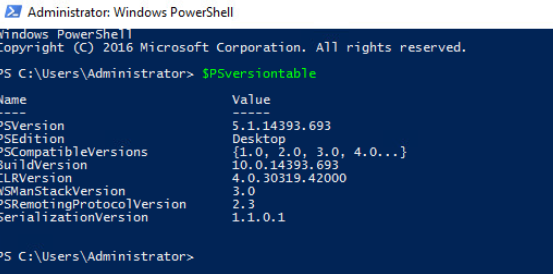
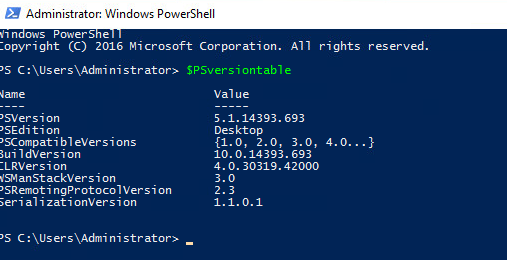
Sur cette machine virtuelle à migrer, vérifiez la version de PowerShell installée (min 5.1) grâce à la commande suivante :
$PSversiontable
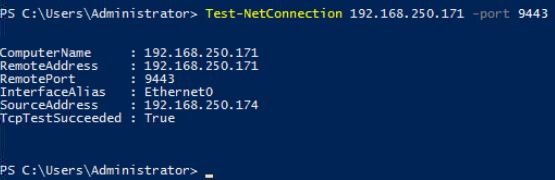
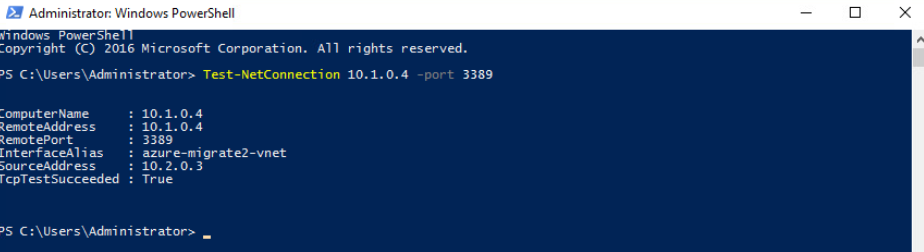
Toujours depuis votre machine virtuelle à migrer, vérifiez la connexion sur le port 9443 vers votre appliance de réplication :
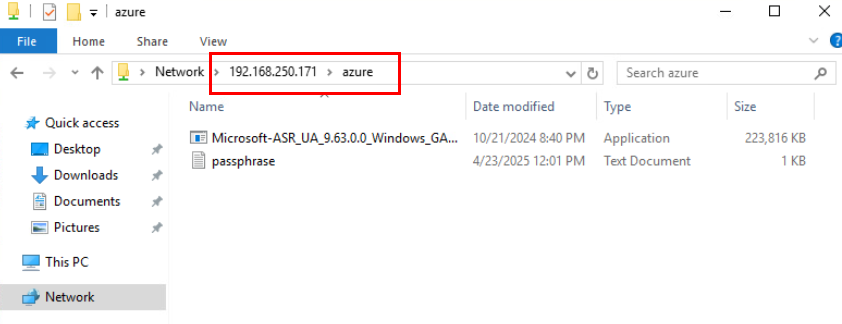
Toujours depuis votre machine virtuelle à migrer, ouvrez le dossier partagé réseau de votre appliance de réplication de réplication :
Copiez les fichiers dans un nouveau répertoire local sur votre machine virtuelle à migrer :
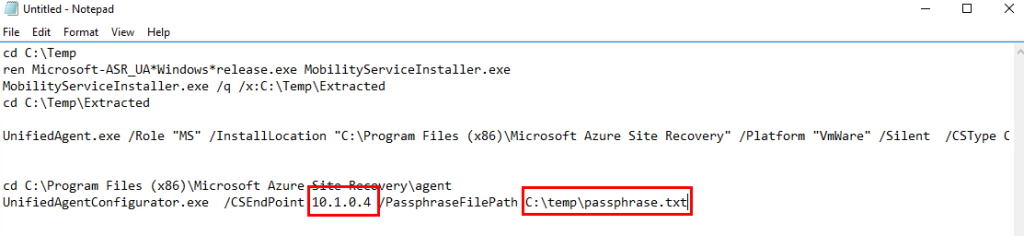
Ouvrez un éditeur de texte afin de reprendre et préparer les commandes suivantes :
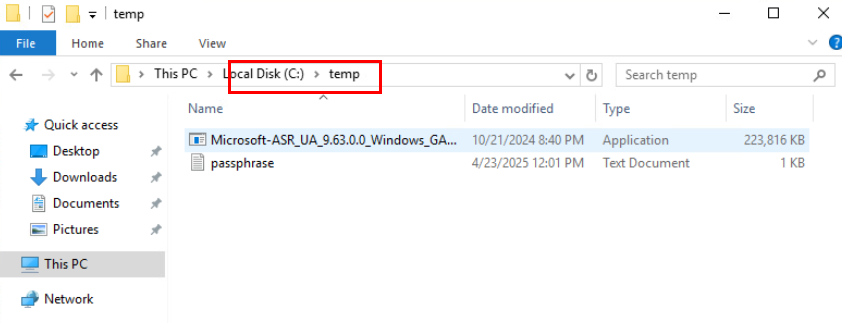
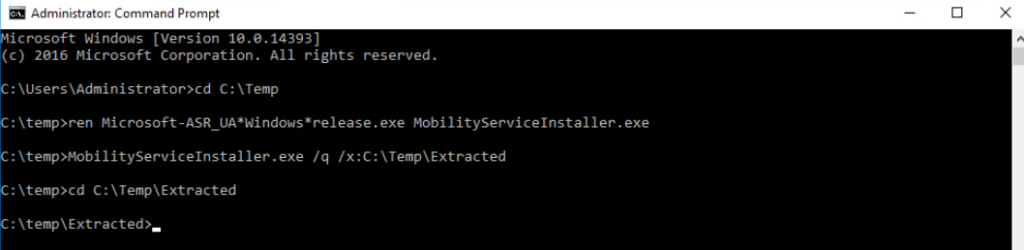
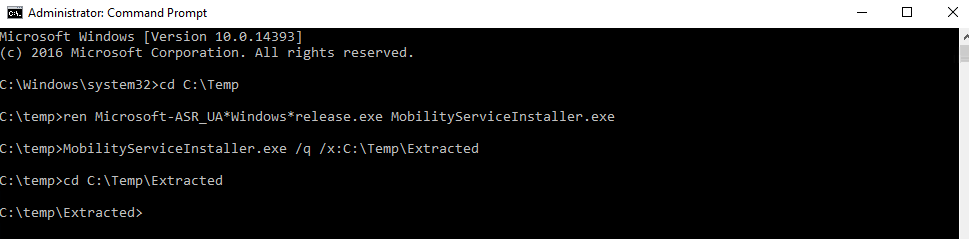
cd C:\Temp
ren Microsoft-ASR_UA*Windows*release.exe MobilityServiceInstaller.exe
MobilityServiceInstaller.exe /q /x:C:\Temp\Extracted
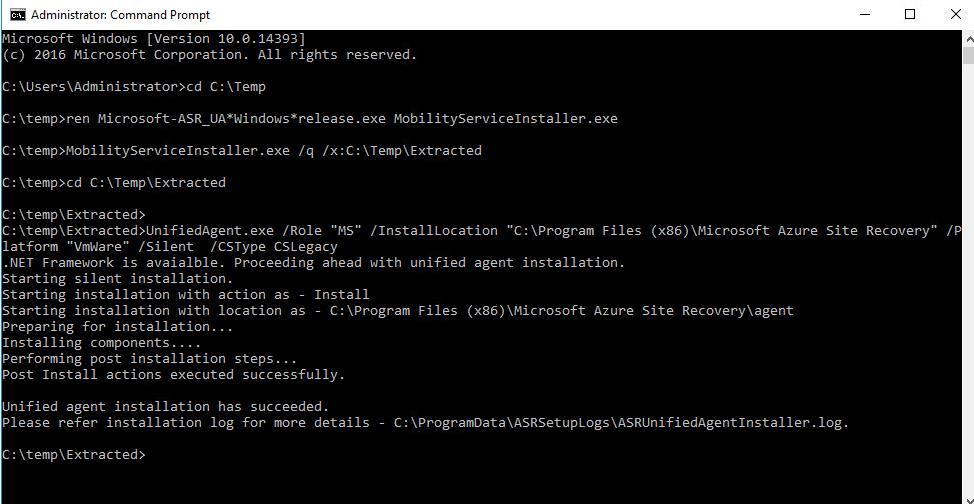
cd C:\Temp\Extracted
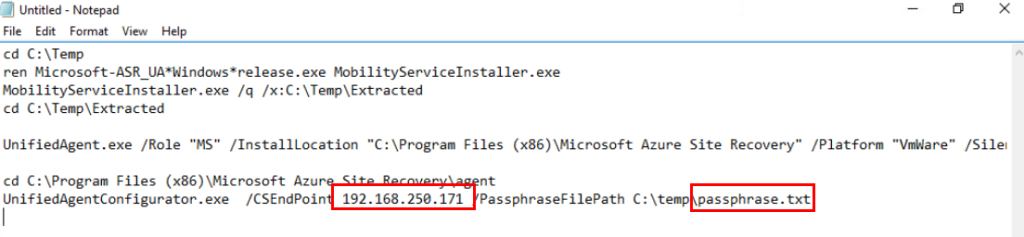
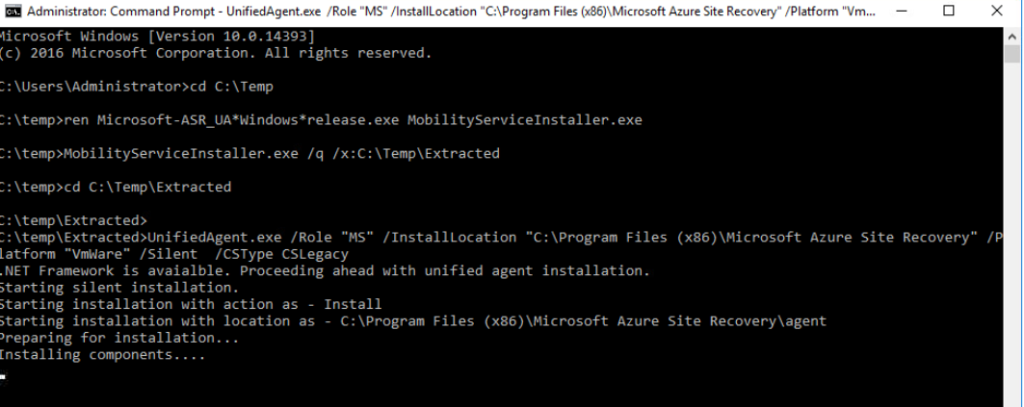
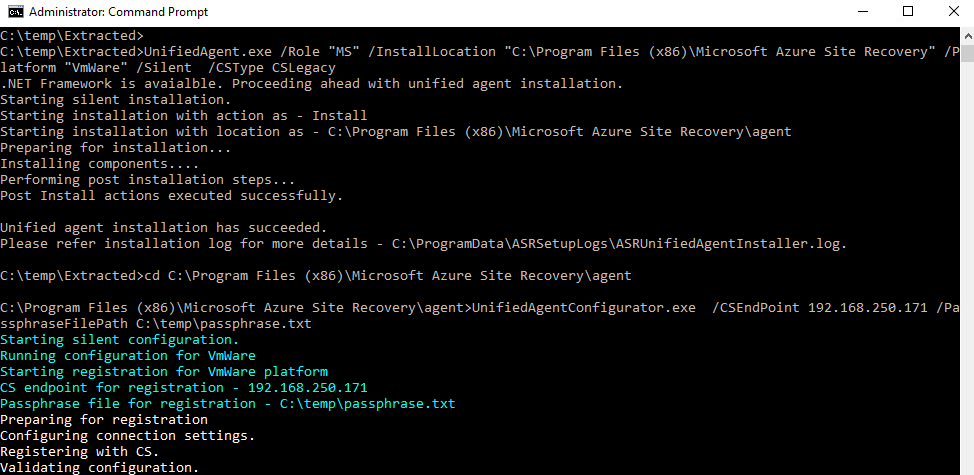
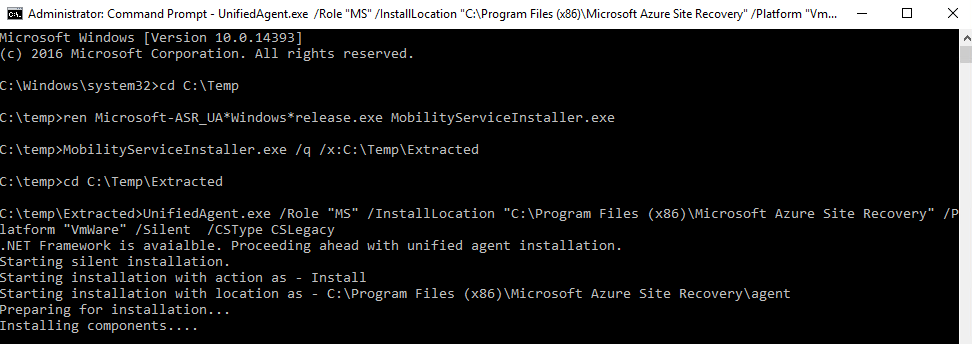
UnifiedAgent.exe /Role "MS" /InstallLocation "C:\Program Files (x86)\Microsoft Azure Site Recovery" /Platform "VmWare" /Silent /CSType CSLegacy
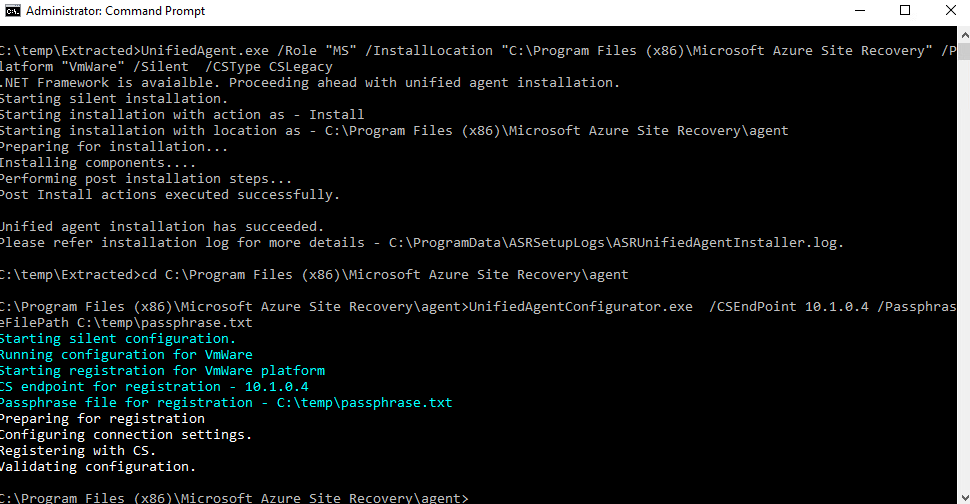
cd C:\Program Files (x86)\Microsoft Azure Site Recovery\agent
UnifiedAgentConfigurator.exe /CSEndPoint <CSIP> /PassphraseFilePath <PassphraseFilePath>
Modifiez les valeurs en rouge par l’adresse IP de votre appliance de réplication et le chemin du fichier contenant la passphrase :
Ouvrez l’invite de commande en mode administrateur, puis exécutez les commandes suivantes pour copier le programme d’installation sur le serveur à migrer :
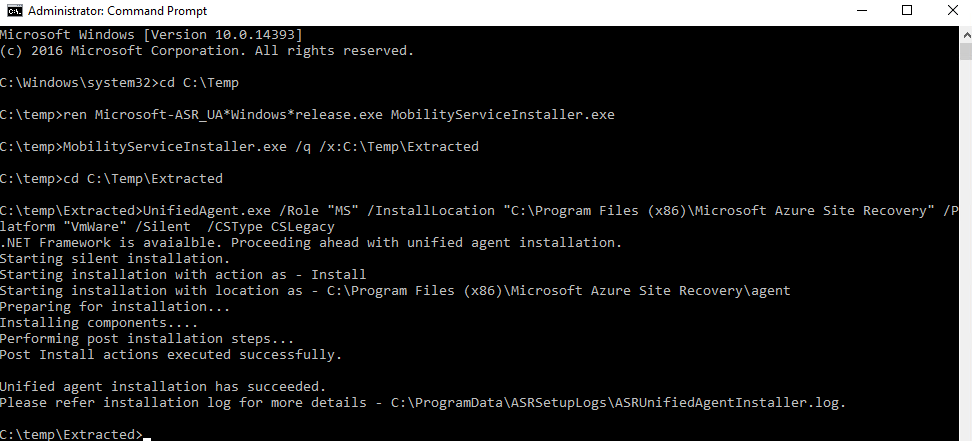
Exécutez cette commande pour installer l’agent :
Exécutez ces commandes pour enregistrer l’agent auprès du serveur de configuration :
Avant de continuer, vérifiez le succès des opérations :
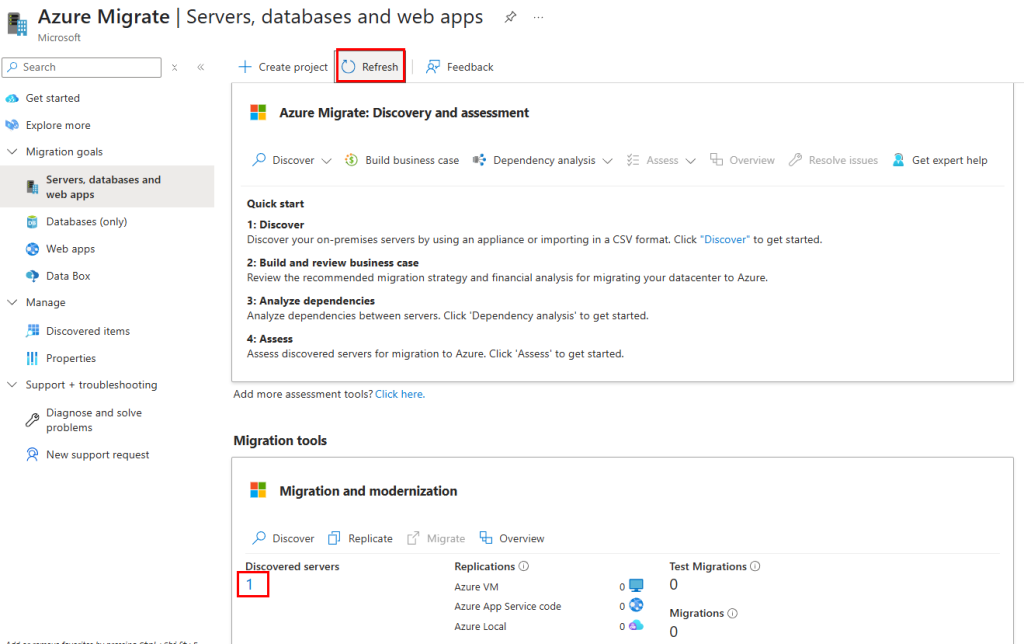
Retournez sur le projet Azure Migrate, puis cliquez sur Rafraîchir afin de voir apparaître la machine virtuelle à migrer :
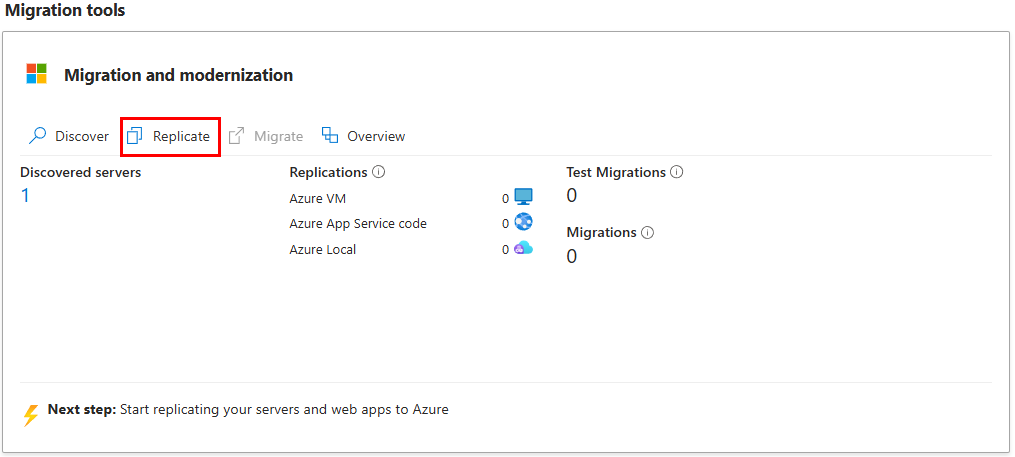
Cliquez ensuite sur Répliquer :
Renseignez toutes les champs, puis cliquez sur Continuer :
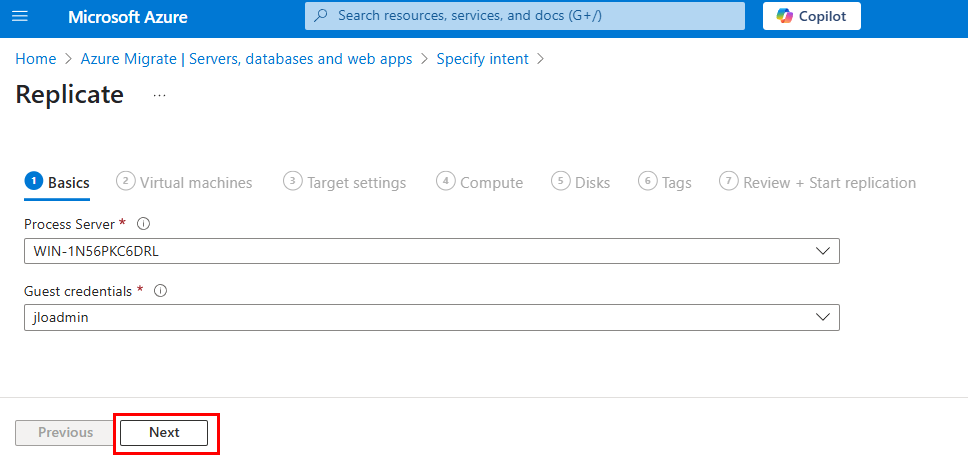
Sélectionnez les informations d’identification à utiliser pour installer à distance le service de mobilité sur les machines à migrer, puis cliquez sur Suivant :
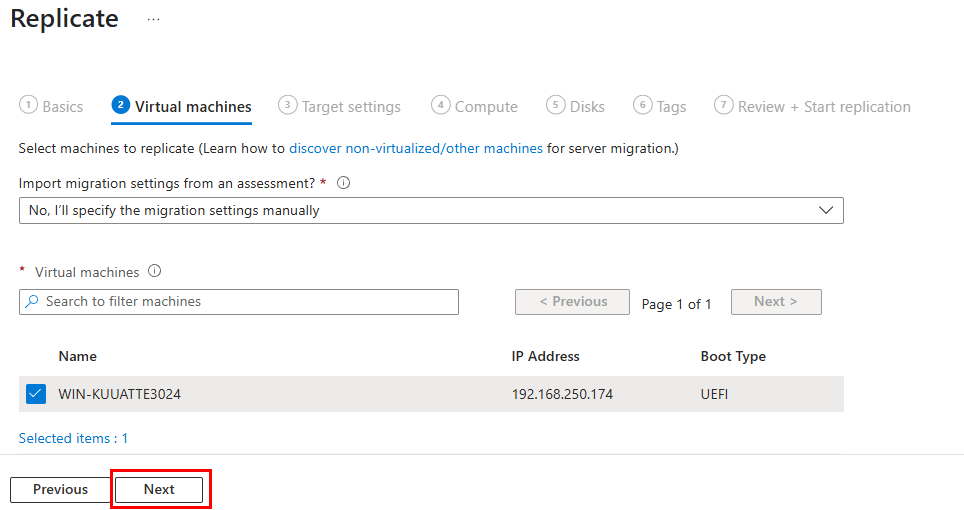
Sélectionner les machines à migrer, puis cliquez sur Suivant :
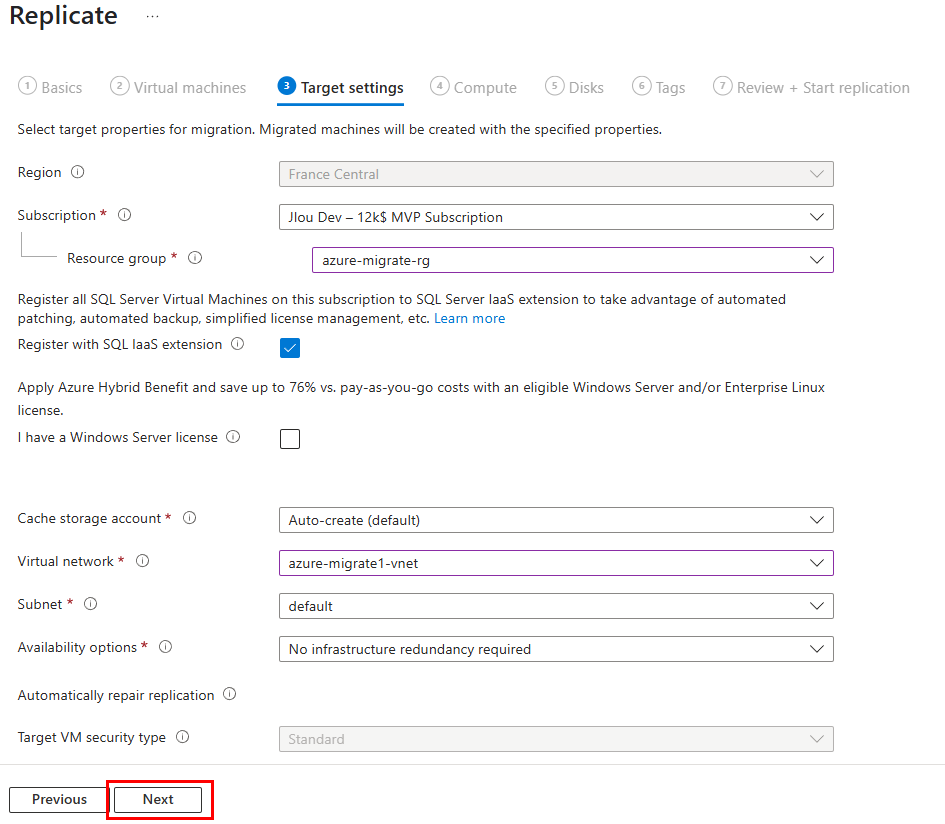
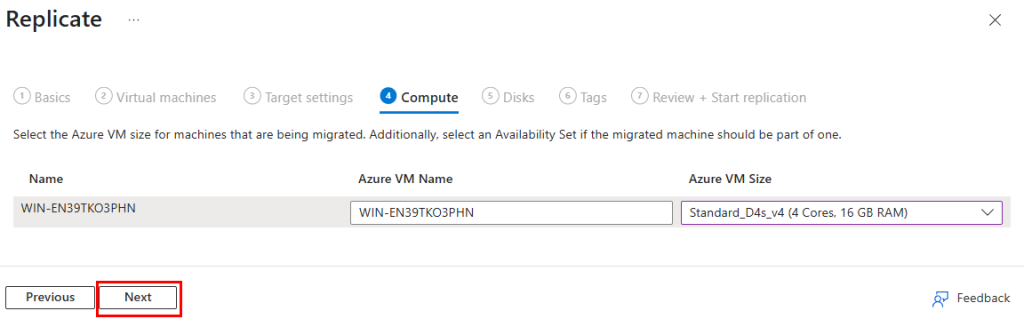
Sélectionnez les propriétés cibles pour la migration. Les machines migrées seront créées avec les propriétés spécifiées, puis cliquez sur Suivant :
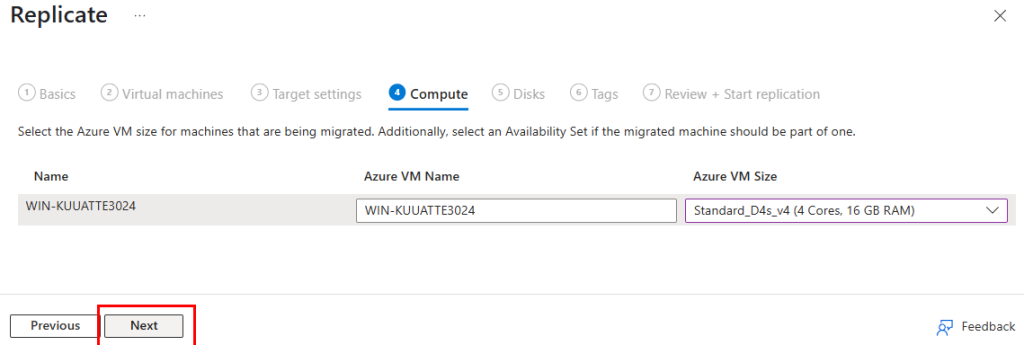
Sélectionnez la taille de la VM Azure pour les machines à migrer, puis cliquez sur Suivant :
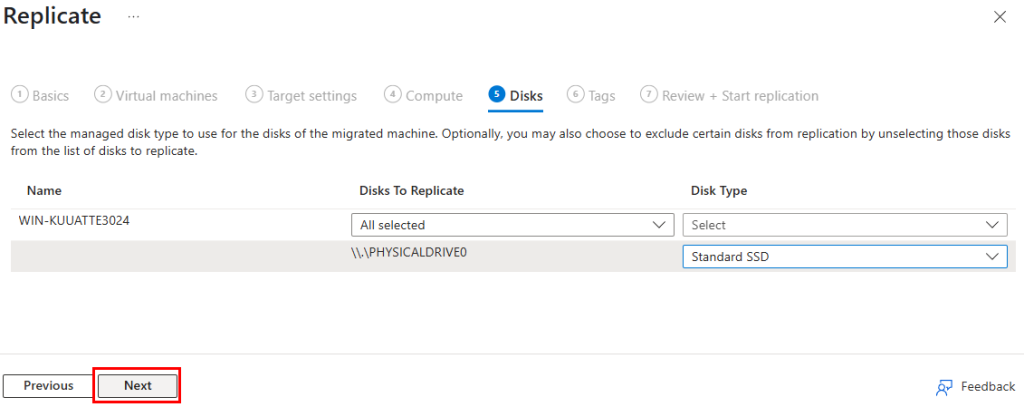
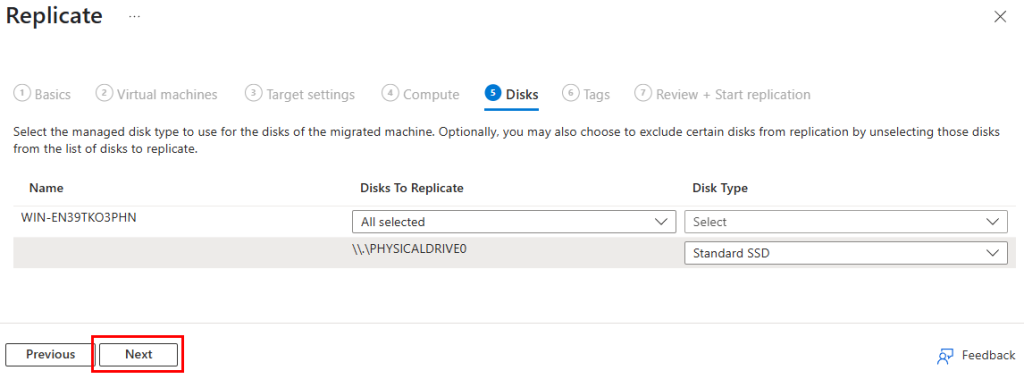
Sélectionnez le type de disque à utiliser pour les machines à migrée, puis cliquez sur Suivant :
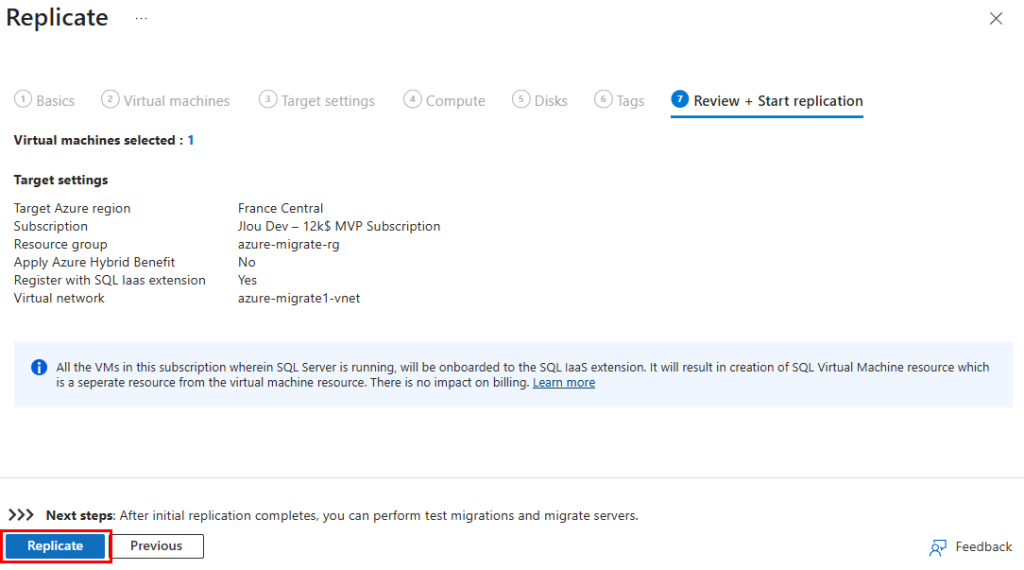
Lancez la réplication en cliquant sur Répliquer :
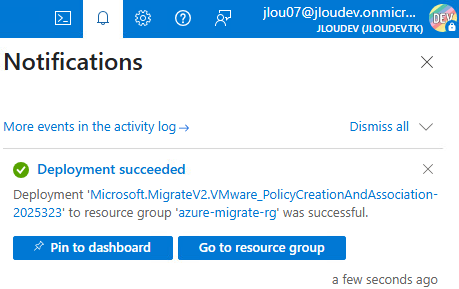
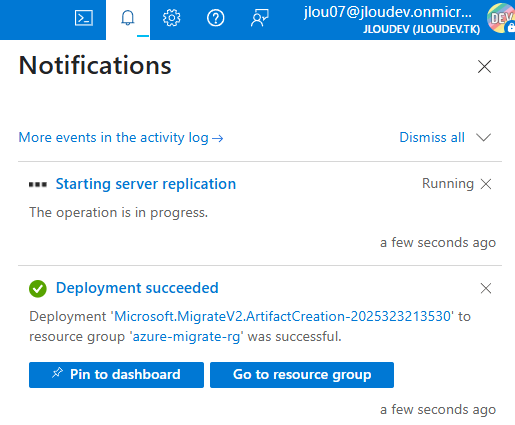
Les notifications suivantes apparaissent alors :
Des ressources Azure liées au projet de migration sont alors créées :
Le compte de stockage commence à recevoir les premières données liées à la réplication :
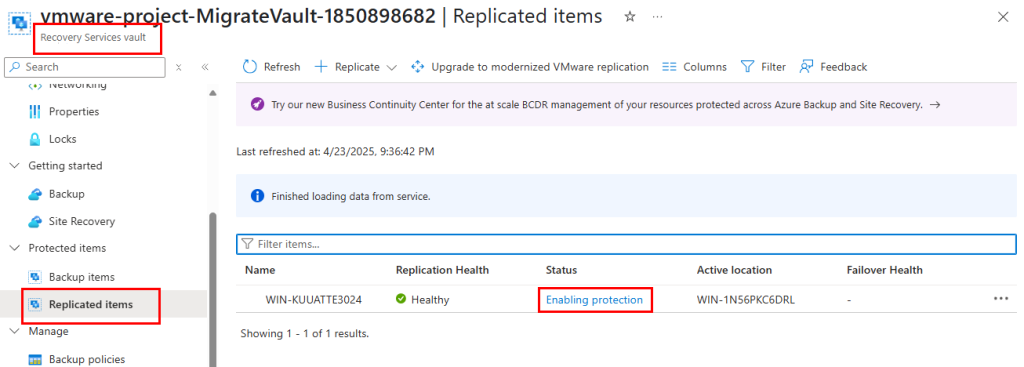
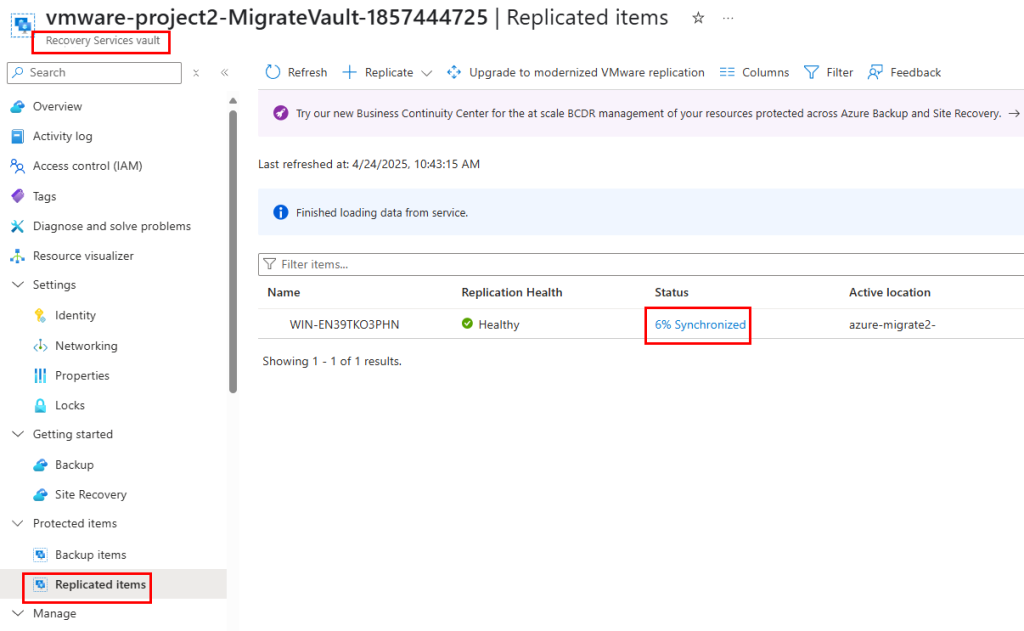
Dans le coffre Recovery, la réplication commence elle-aussi à être visible :
Environ 1 heure plus tard, celle-ci est terminée :
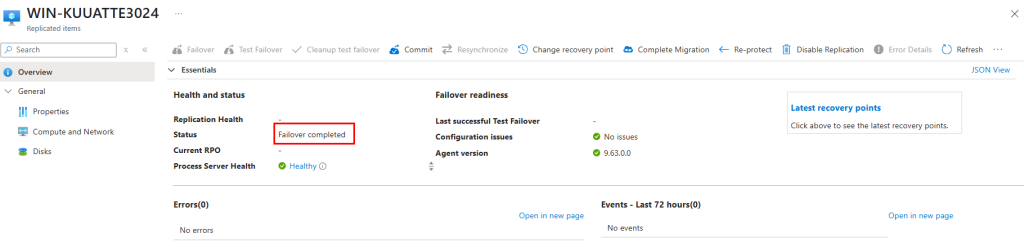
Un clic sur la machine virtuelle à migrer nous affiche le schéma de réplication des données :
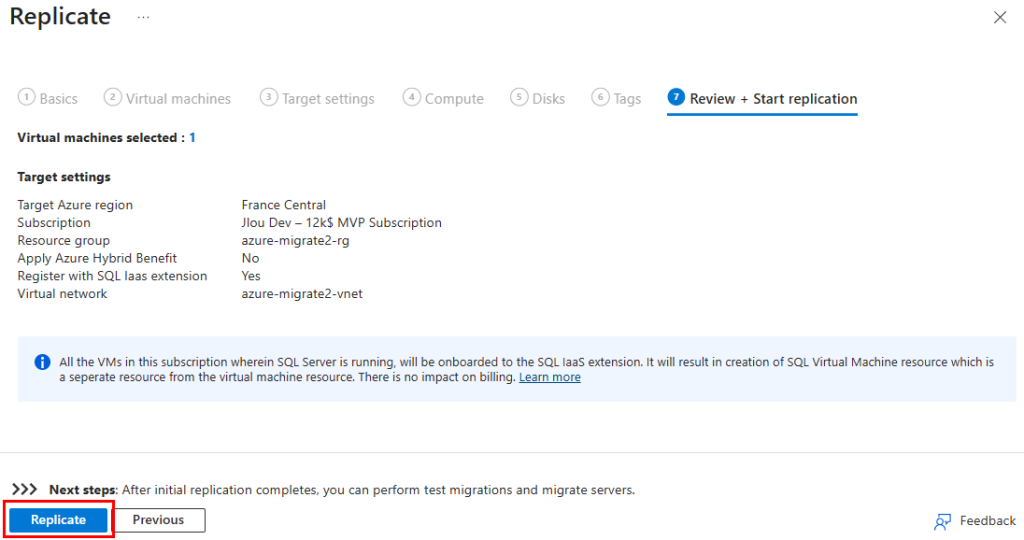
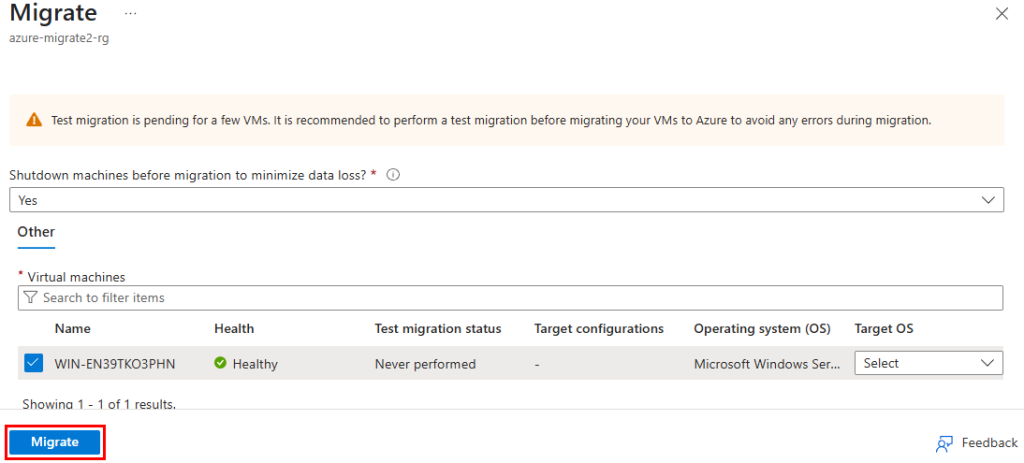
Si tout est OK, retournez sur le projet de migration, actualiser si nécessaire afin de pouvoir cliquer sur Migrer :
Définissez la destination cible, puis cliquez sur Continuer :
Cochez la machine virtuelle à migrer, puis cliquez sur Migrer :
La notification suivante apparaît :
Quelques secondes plus tard, celle-ci affiche le succès du déclenchement de la migration :
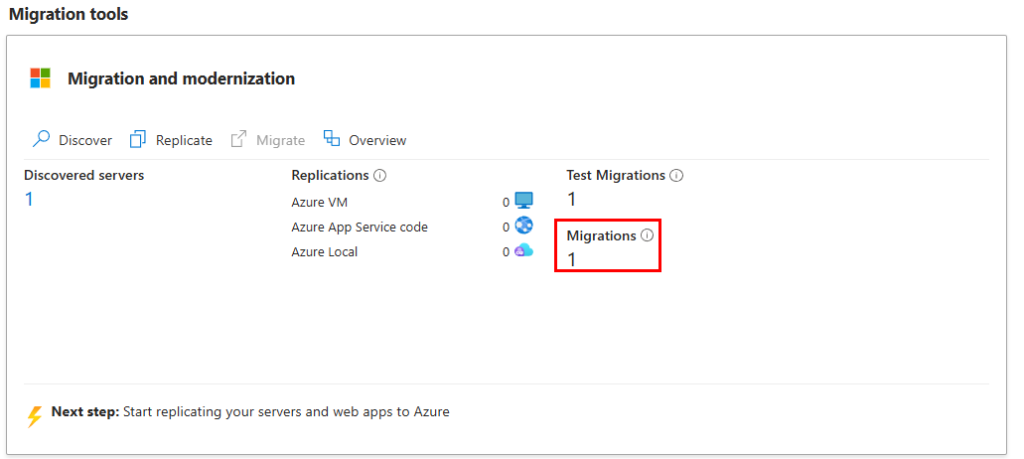
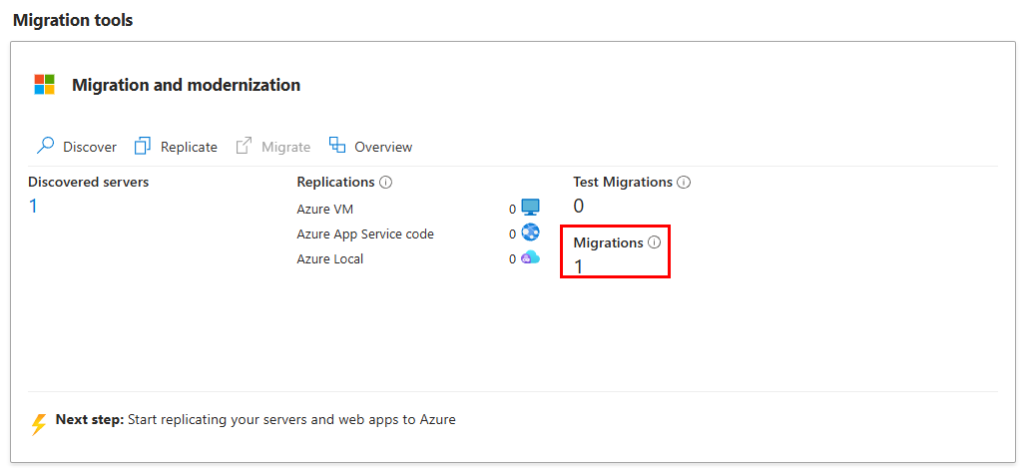
Cette migration est visible sur notre projet Azure Migrate :
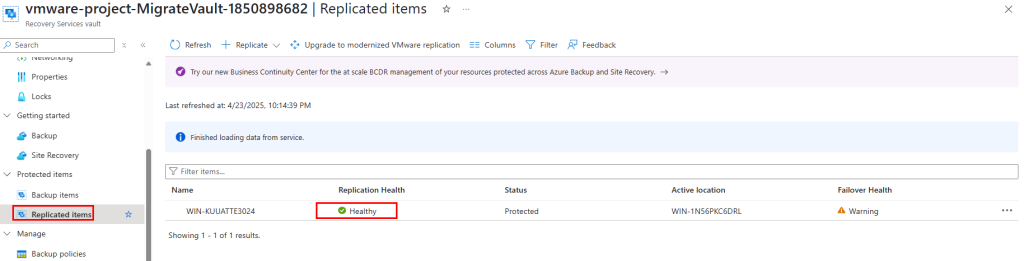
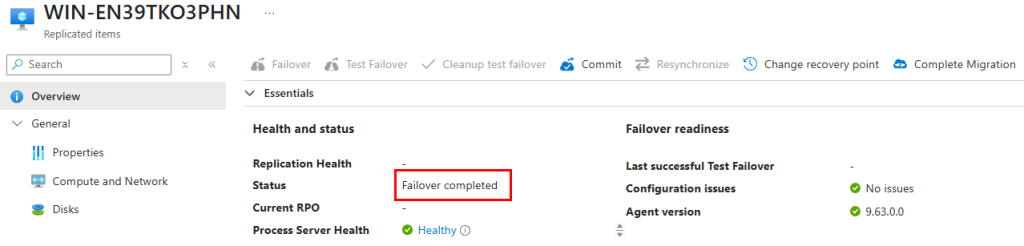
Le coffre Recovery nous indique que la migration est terminée :
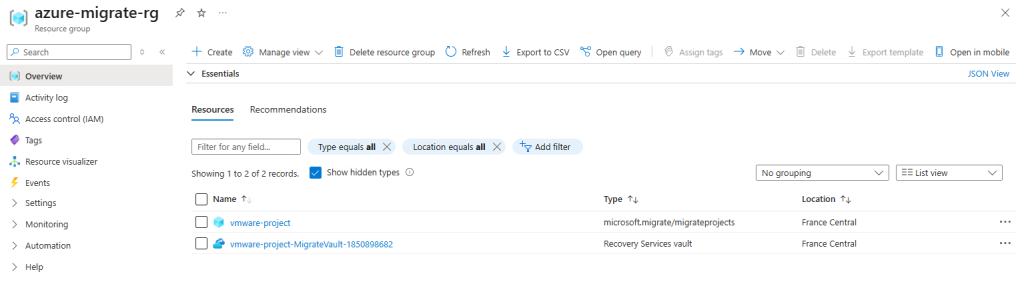
Le groupe de ressources Azure contient alors de nouvelles ressources créées lors de la migration :
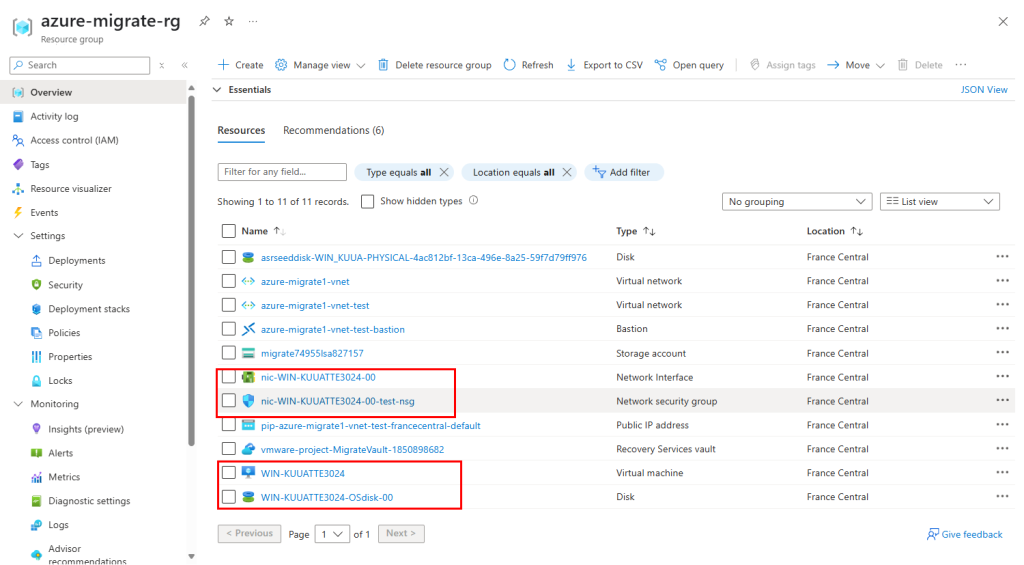
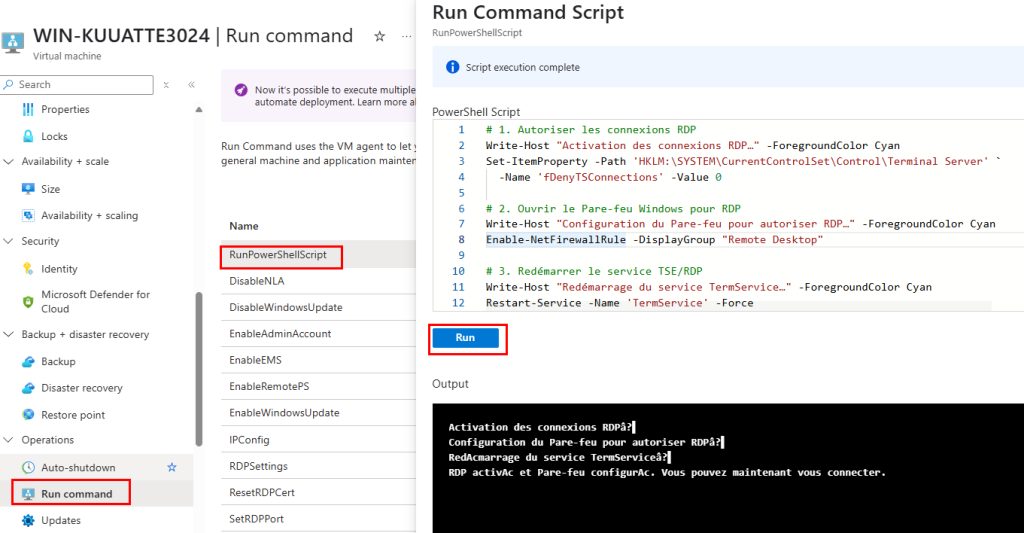
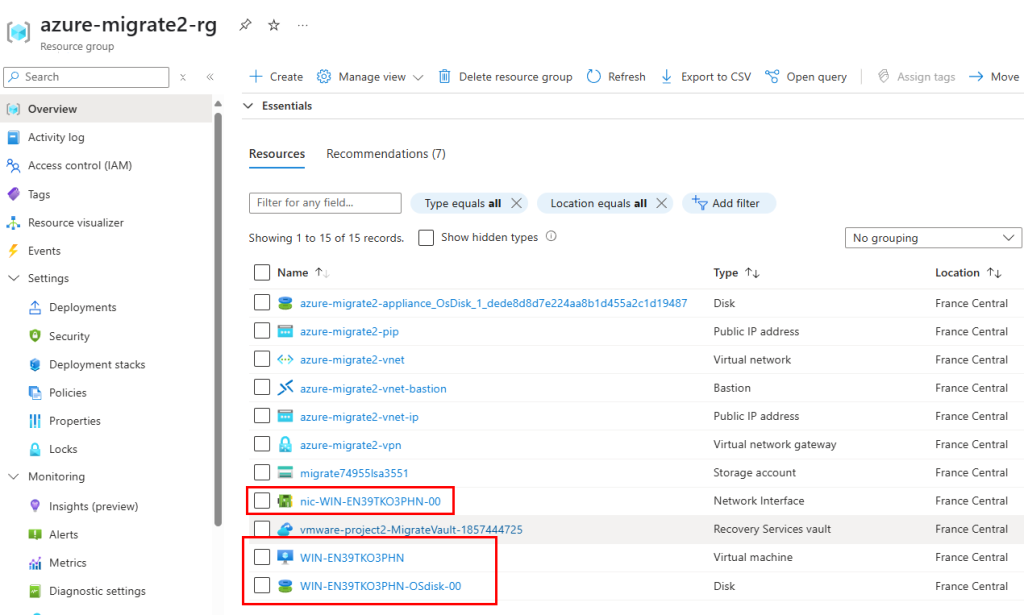
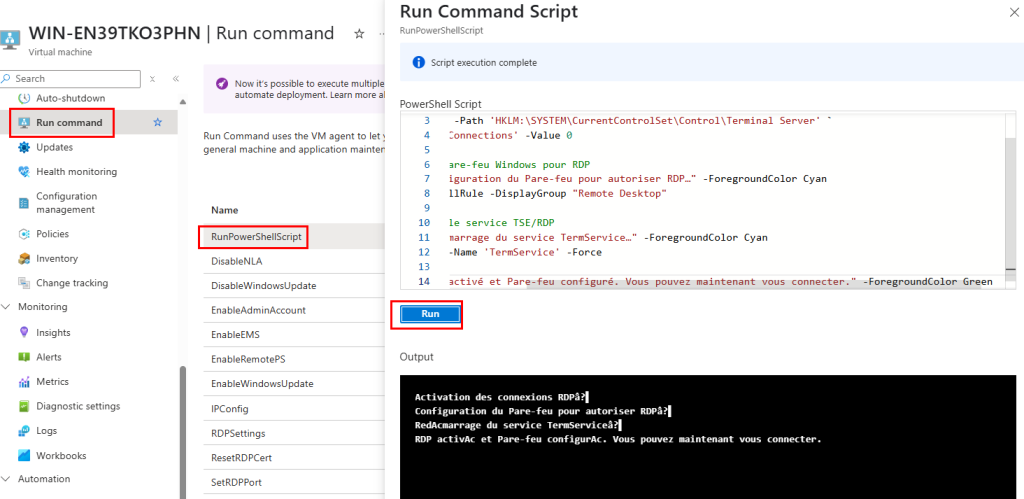
Afin de pouvoir nous connecter à la machine virtuelle via Azure Bastion, copiez les commandes suivantes depuis la page Azure de votre machine virtuelle migrée :
# 1. Autoriser les connexions RDP
Write-Host "Activation des connexions RDP…" -ForegroundColor Cyan
Set-ItemProperty -Path 'HKLM:\SYSTEM\CurrentControlSet\Control\Terminal Server' `
-Name 'fDenyTSConnections' -Value 0
# 2. Ouvrir le Pare-feu Windows pour RDP
Write-Host "Configuration du Pare-feu pour autoriser RDP…" -ForegroundColor Cyan
Enable-NetFirewallRule -DisplayGroup "Remote Desktop"
# 3. Redémarrer le service TSE/RDP
Write-Host "Redémarrage du service TermService…" -ForegroundColor Cyan
Restart-Service -Name 'TermService' -Force
Write-Host "RDP activé et Pare-feu configuré. Vous pouvez maintenant vous connecter." -ForegroundColor Green
Collez ces commandes, puis lancez celles-ci :
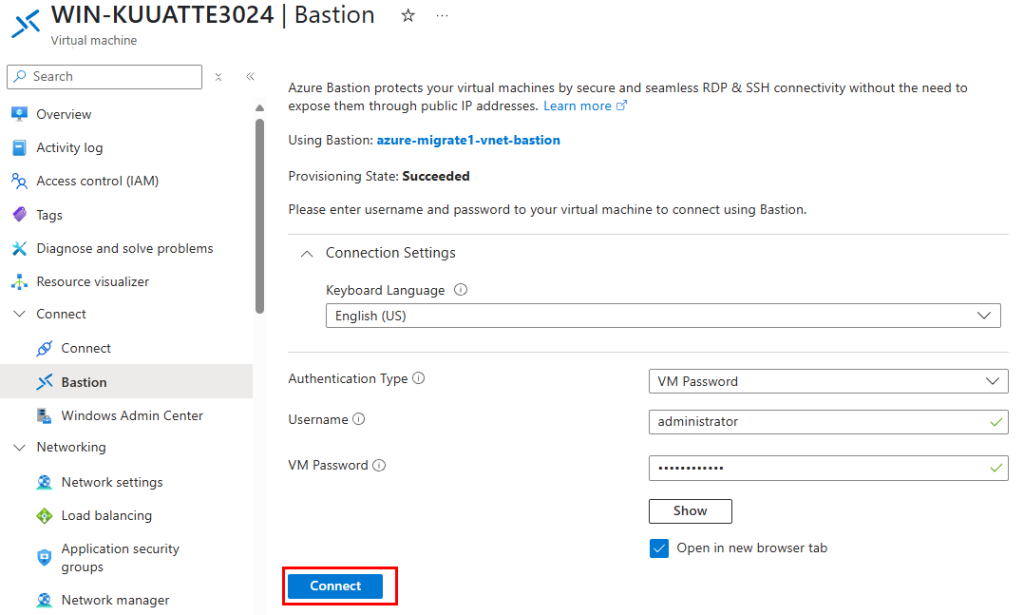
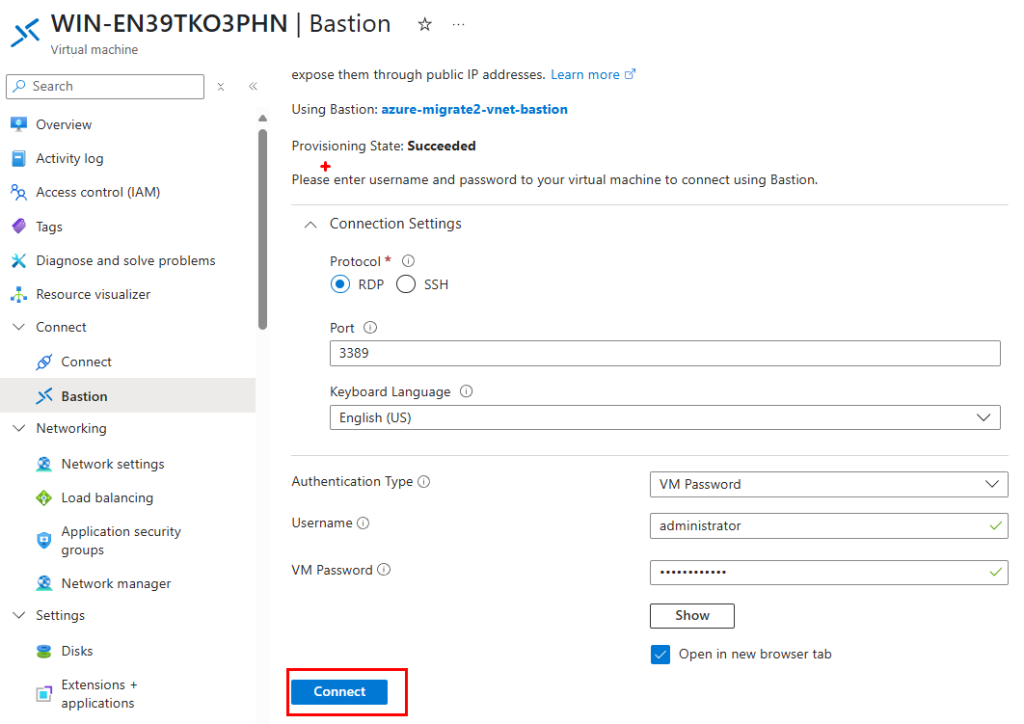
Ensuite, connectez-vous à votre machine virtuelle migrée via Azure Bastion :
Constatez l’ouverture de session Windows sur votre machine virtuelle migrée :
La migration de notre machine virtuelle hébergée sur VMware vers Azure s’est déroulée avec succès.
Continuons l’exercice de migration en partant cette fois du principe que nous ne pouvons pas créer une machine virtuelle jouant le rôle d’appliance de réplication sur l’hyperviseur, et que celle-ci doit donc alors être obligatoirement déployée sur Azure.
Test II – Appliance de réplication sur Azure :
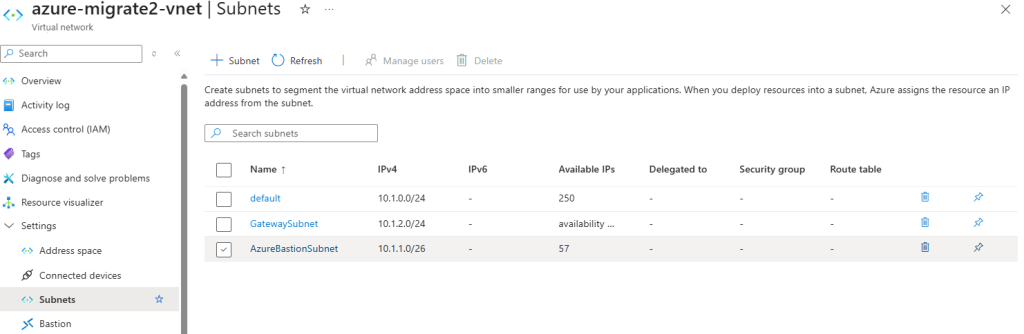
Pour cette approche, commencez par créer un réseau virtuel Azure comprenant plusieurs sous-réseaux virtuels :
Un sous-réseau dédié à l’appliance de réplication.
Un sous-réseau dédié à Azure Bastion.
Un sous-réseau dédié à la passerelle VPN, pour connecter notre machine virtuelle à migrer à notre appliance de réplication hébergée sur Azure.
Créez une machine virtuelle ayant pour futur rôle l’appliance de réplication :
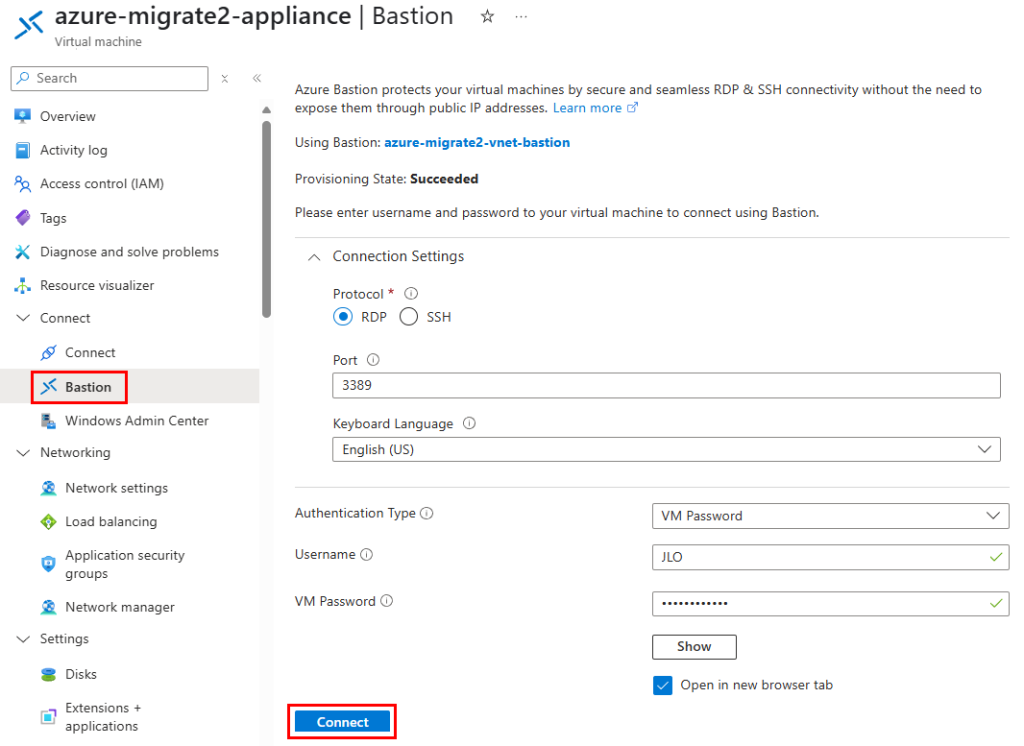
Connectez-vous à celle-ci via Azure Bastion :
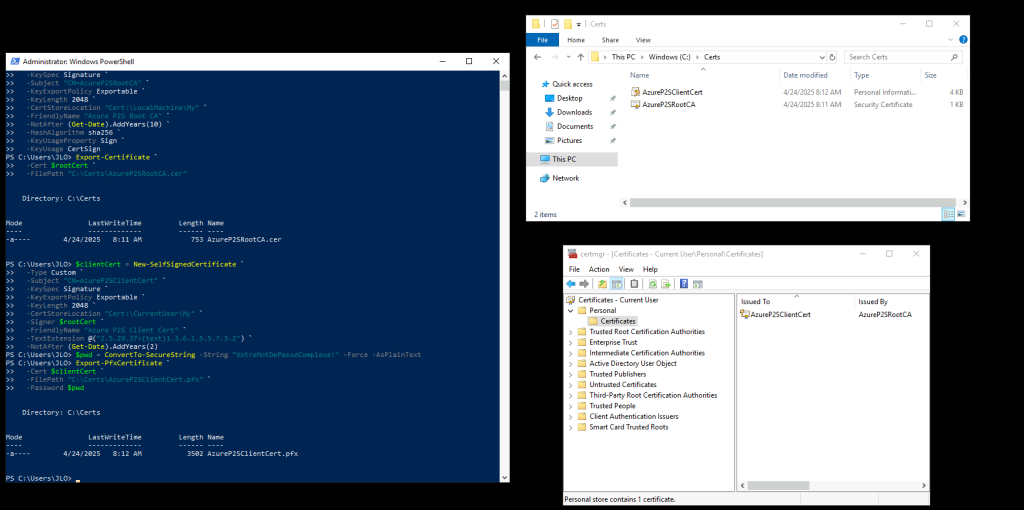
Afin de connecter par la suite la machine virtuelle à migrer à l’appliance de réplication Azure, via une connexion Point à Site, des certificats sont nécessaires pour l’authentification IKEv2.
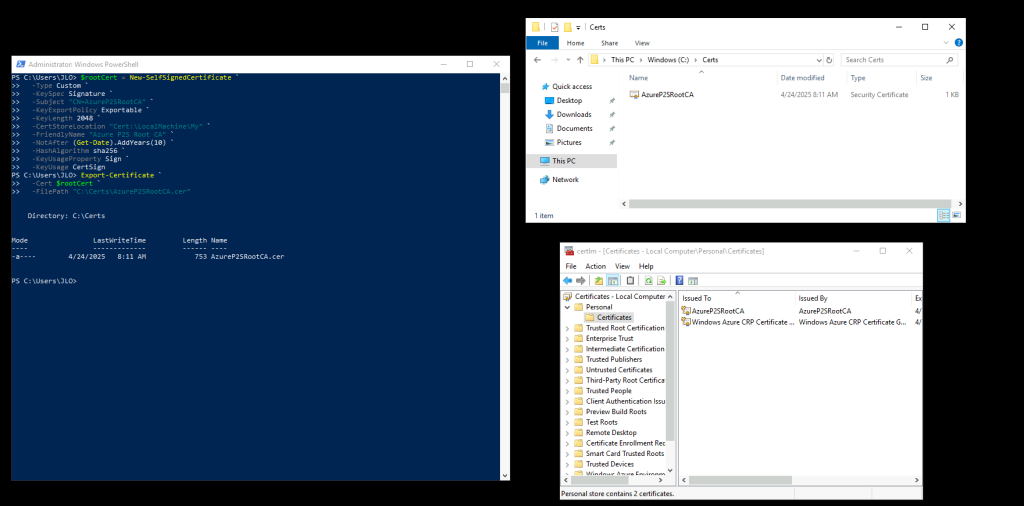
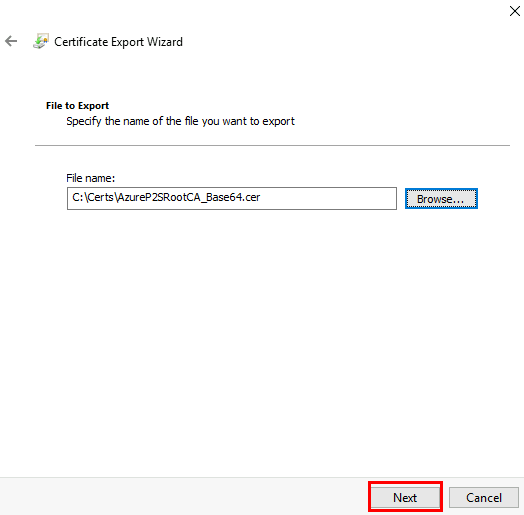
Pour cela, depuis l’appliance de réplication Azure, générez et exportez les certificats :
Un certificat racine auto-signé (à exporter en .cer pour Azure)
Un certificat client signé par ce root (à exporter en .pfx pour votre machine cliente)
Sur votre appliance de réplication Azure, ouvrez une fenêtre PowerShell, puis lancez le script suivant pour générer le certificat racine :
Ouvrez le gestionnaire des certificats utilisateurs afin de constater sa présence :
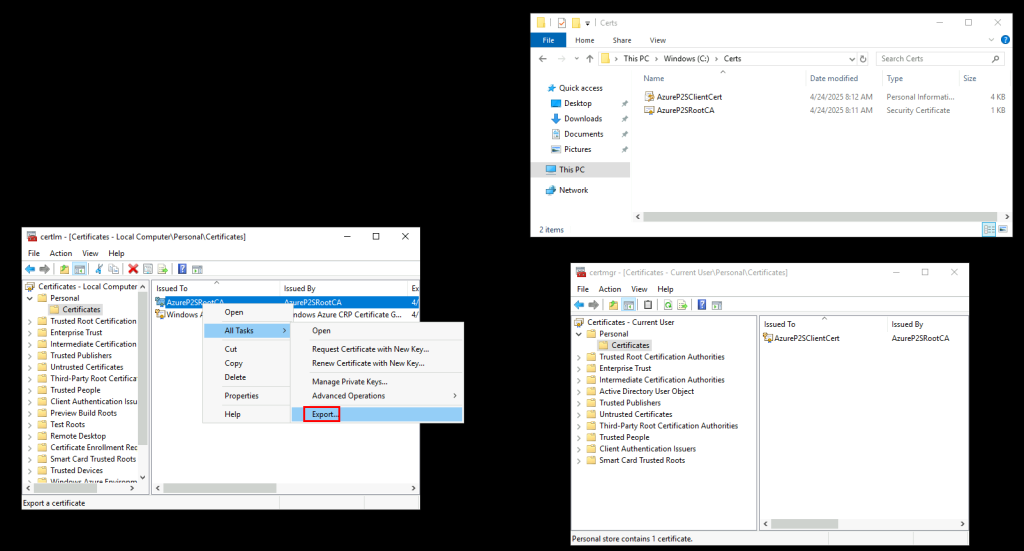
Afin d’enregistrer les données du certificat public dans Azure, exportez ce dernier depuis le gestionnaire des certificats utilisateurs :
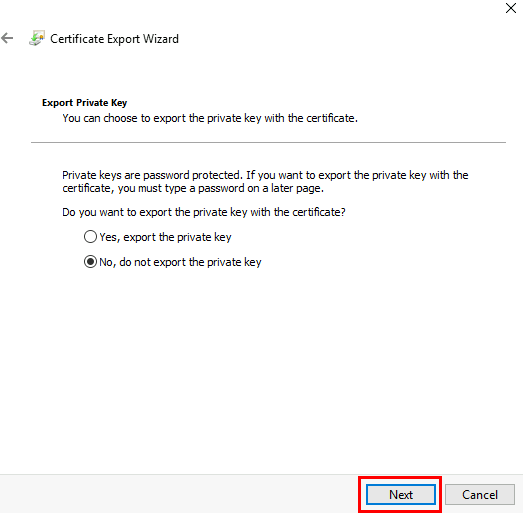
Choisissez Non, puis cliquez sur Suivant :
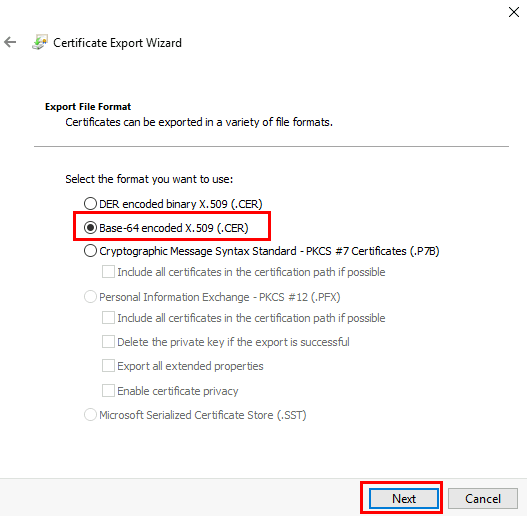
Sélectionnez Format Base-64 encodé X.509 (.CER), puis cliquez sur Suivant :
Indiquez le chemin de sauvegarde, puis cliquez sur Suivant :
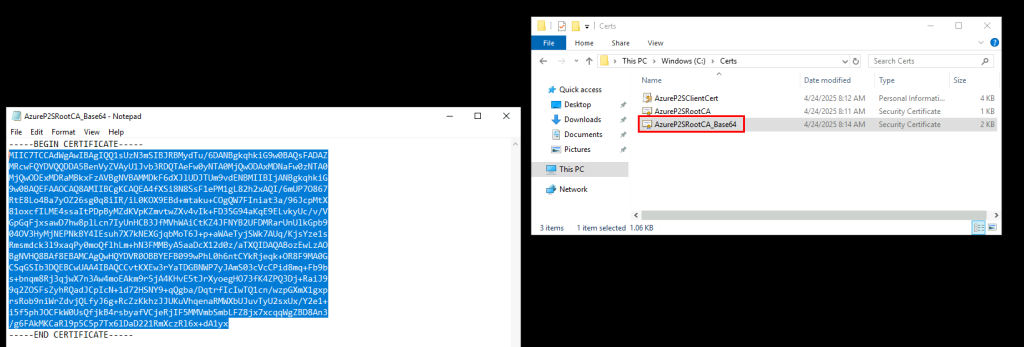
Ouvrez le fichier en base-64 avec un éditeur, puis copiez tout le texte (sauf -----BEGIN CERTIFICATE----- et -----END CERTIFICATE-----) :
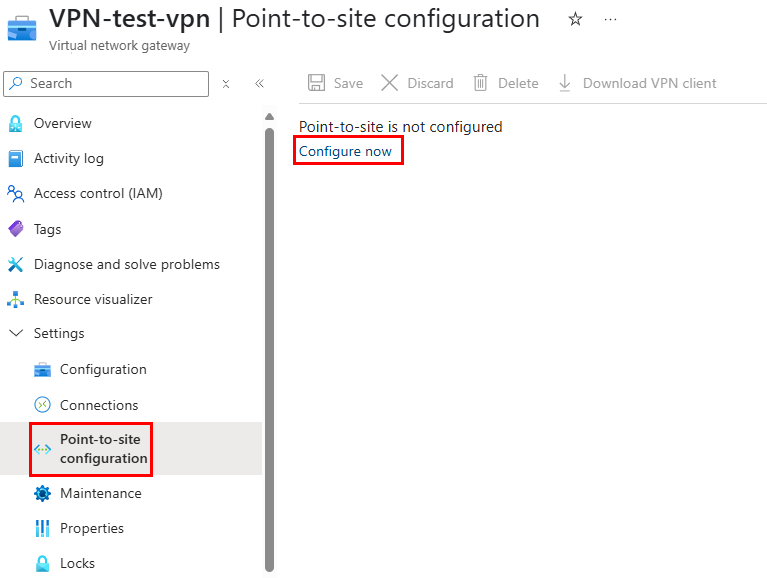
Dans le portail Azure, rendez-vous sur la page de votre passerelle VPN, puis démarrez la configuration Point à Site :
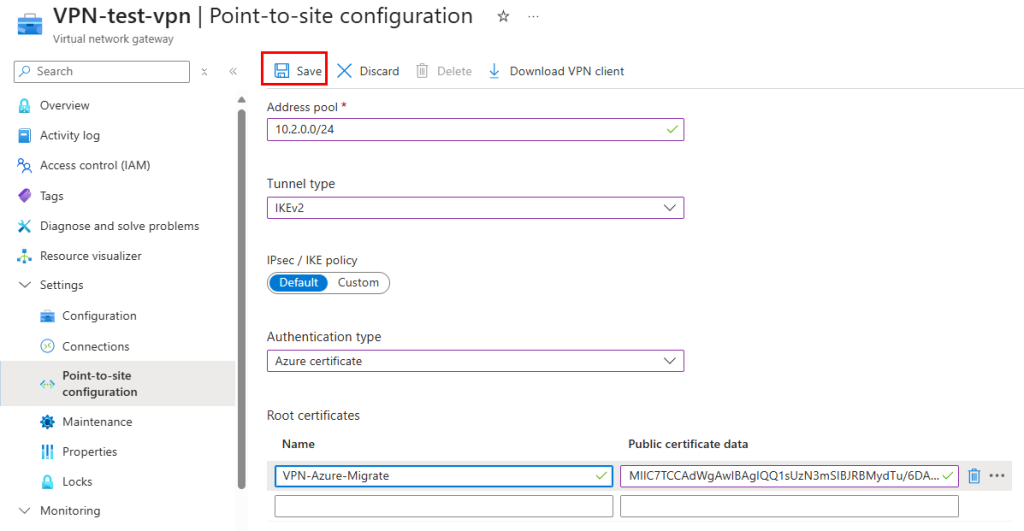
Définissez un espace d’adressage, le type de tunnel en IKEv2, collez le texte en Base-64 que vous venez de copier dans Données du certificat racine, puis cliquez sur Enregistrer.
Après quelques instants, constatez la notification Azure suivante :
Télécharger le client VPN afin de configurer plus tard le client VPN Windows natif sur la machine virtuelle à migrer :
Toujours sur appliance de réplication Azure, recherchez le service Azure Migrate :
Cliquez-ici pour commencer un projet de migration :
Cliquez-ici pour créer un projet de migration :
Renseignez toutes les informations demandées, puis cliquez sur Créer :
Cliquez sur Découvrir afin d’installer l’appliance de réplication :
Renseignez tous les champs, puis cliquez sur Créer les ressources :
Conservez les options suivantes :
Cliquez sur le bouton suivant afin de télécharger l’installeur de l’appliance de réplication :
Cliquez également sur le bouton suivant afin de sauvegarder la clef utilisée par l’appliance de réplication pour s’enrôler au coffre Azure Recovery :
Une fois téléchargé, lancez l’installeur :
Attendez quelques minutes la fin de la décompression :
Conservez ce choix, puis cliquez sur Suivant :
Acceptez les termes et conditions, puis cliquez sur Suivant :
Rechercher le fichier clef, puis cliquez sur Suivant :
Conservez ce choix, puis cliquez sur Suivant :
Attendez que les contrôles soit effectués, puis cliquez sur Suivant :
Définissez un mot de passe pour la base de données MySQL, puis cliquez sur Suivant :
Si cela n’est pas votre cas, cochez cette case, puis cliquez sur Suivant :
Cliquez sur Suivant :
Définissez les 2 liaisons réseaux, puis cliquez sur Suivant :
Cliquez sur Installer :
Attendez environ 10 minutes la fin de l’installation :
Cliquez sur Oui :
Collez cette passphrase dans un fichier texte, puis sauvegardez-le :
Une fois l’installation réussie, cliquez sur Terminer :
L’outil de configuration d’Azure Site Recovery s’ouvre automatiquement, ajoutez-le ou les comptes administrateur des machines devant être migrées dans le cloud Azure :
Retournez sur le portail Azure, rafraîchissez la page précédente, puis cliquez ici pour finaliser le processus d’enregistrement de l’application de réplication :
Attendez le succès de l’opération avec la notification suivante :
Constatez la création de nouvelles ressources dans le groupe de ressources précédemment défini :
Retournez sur l’appliance de réplication, rendez-vous dans le dossier suivant, puis copiez seulement l’exécutable ci-dessous :
Créez un dossier partagé réseau sur votre appliance de réplication, puis collez-y :
L’exécutable précédemment copié
Le fichier texte contenant la passphrase
Rendez-vous sur la console hyperviseur, puis connectez-vous à la machine virtuelle devant être migrée sur Azure :
Sur cette machine virtuelle, vérifiez la version de PowerShell installée (min 5.1) grâce à la commande suivante :
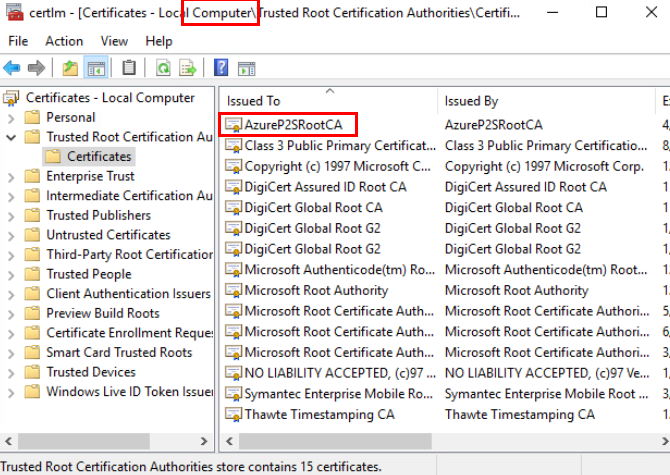
Installez le certificat root dans le magasin Trusted Root Certification Authorities du gestionnaire des certificats machines :
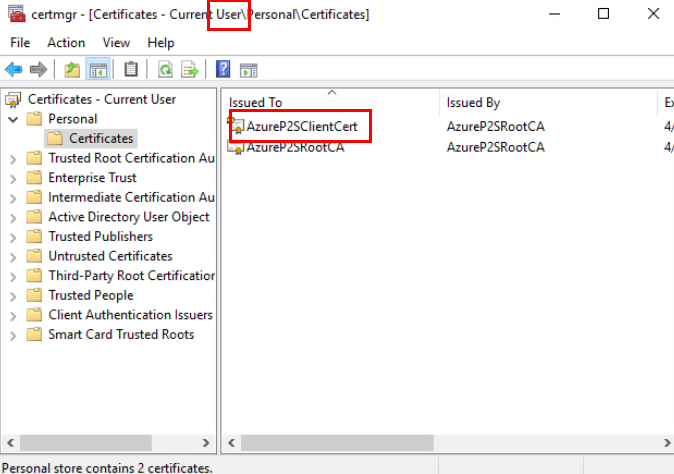
Installez le certificat client dans le magasin Personal du certificats utilisateurs :
Installez la configuration VPN Windows précédemment téléchargée depuis la page Azure de la passerelle VPN :
Lancez la connexion VPN :
Cliquez sur Connecter :
Vérifiez le statut de la connexion VPN :
Depuis votre machine virtuelle à migrer, vérifiez la connexion sur le port 9443 vers votre appliance de réplication Azure :
Toujours depuis cette VM à migrer, ouvrez le dossier partagé réseau de votre appliance de réplication de réplication :
Copiez les fichiers dans un nouveau répertoire local sur votre machine virtuelle à migrer :
Ouvrez un éditeur de texte afin de reprendre et préparer les commandes suivantes :
cd C:\Temp
ren Microsoft-ASR_UA*Windows*release.exe MobilityServiceInstaller.exe
MobilityServiceInstaller.exe /q /x:C:\Temp\Extracted
cd C:\Temp\Extracted
UnifiedAgent.exe /Role "MS" /InstallLocation "C:\Program Files (x86)\Microsoft Azure Site Recovery" /Platform "VmWare" /Silent /CSType CSLegacy
cd C:\Program Files (x86)\Microsoft Azure Site Recovery\agent
UnifiedAgentConfigurator.exe /CSEndPoint <CSIP> /PassphraseFilePath <PassphraseFilePath>
Modifiez les valeurs en rouge par l’adresse IP de votre appliance de réplication et le chemin du fichier contenant la passphrase :
Ouvrez l’invite de commande en mode administrateur, puis exécutez les commandes suivantes pour copier le programme d’installation sur le serveur à migrer :
Exécutez cette commande pour installer l’agent :
Exécutez ces commandes pour enregistrer l’agent auprès du serveur de configuration :
Avant de continuer, vérifiez le succès des opérations :
Retournez sur le projet Azure Migrate, puis cliquez sur Rafraîchir afin de voir apparaître la machine virtuelle à migrer :
Cliquez ensuite sur Répliquer :
Renseignez toutes les champs, puis cliquez sur Continuer :
Sélectionnez les informations d’identification à utiliser pour installer à distance le service de mobilité sur les machines à migrer, puis cliquez sur Suivant :
Sélectionner les machines à migrer, puis cliquez sur Suivant :
Sélectionnez les propriétés cibles pour la migration. Les machines migrées seront créées avec les propriétés spécifiées, puis cliquez sur Suivant :
Sélectionnez la taille de la VM Azure pour les machines à migrer, puis cliquez sur Suivant :
Sélectionnez le type de disque à utiliser pour les machines à migrer, puis cliquez sur Suivant :
Lancez la réplication en cliquant sur Répliquer :
Les notifications suivantes apparaissent alors :
Le compte de stockage commence à recevoir les premières données liées à la réplication :
Dans le coffre Recovery, la réplication commence elle-aussi à être visible :
Environ 1 heure plus tard, celle-ci est terminée :
Un clic sur la machine virtuelle à migrer nous affiche le schéma de réplication des données :
Si tout est OK, retournez sur le projet de migration, actualiser si nécessaire afin de pouvoir cliquer sur Migrer :
Définissez la destination cible, puis cliquez sur Continuer :
Cochez la machine virtuelle à migrer, puis cliquez sur Migrer :
Quelques secondes plus tard, la notification suivante affiche le succès de déclenchement de la migration :
Cette migration est visible sur notre projet :
Le coffre Recovery nous indique que la migration est terminée :
Le groupe de ressources Azure contient alors de nouvelles ressources créées lors de la migration :
Afin de pouvoir nous connecter à la machine virtuelle via Azure Bastion, copiez les commandes suivantes depuis la page Azure de votre machine virtuelle migrée :
# 1. Autoriser les connexions RDP
Write-Host "Activation des connexions RDP…" -ForegroundColor Cyan
Set-ItemProperty -Path 'HKLM:\SYSTEM\CurrentControlSet\Control\Terminal Server' `
-Name 'fDenyTSConnections' -Value 0
# 2. Ouvrir le Pare-feu Windows pour RDP
Write-Host "Configuration du Pare-feu pour autoriser RDP…" -ForegroundColor Cyan
Enable-NetFirewallRule -DisplayGroup "Remote Desktop"
# 3. Redémarrer le service TSE/RDP
Write-Host "Redémarrage du service TermService…" -ForegroundColor Cyan
Restart-Service -Name 'TermService' -Force
Write-Host "RDP activé et Pare-feu configuré. Vous pouvez maintenant vous connecter." -ForegroundColor Green
Collez ces commandes, puis lancez celles-ci :
Ensuite, connectez-vous à votre machine virtuelle migrée via Azure Bastion :
Constatez l’ouverture de session Windows sur votre machine virtuelle migrée sur Azure :
La migration de notre machine virtuelle hébergée sur VMware vers Azure s’est déroulée avec succès.
Conclusion
En définitive, migrer vos VMs vers Azure sans droits d’infra reste une solution de « seconde main » qui dépanne en cas de contraintes fortes, mais elle ne doit pas devenir la norme.
Pour tirer pleinement parti du cloud, il sera toujours préférable de recréer vos ressources selon les principes cloud-native : refactoring des applications, adoption de services managés et optimisation des coûts.
À long terme, cette approche garantit une meilleure scalabilité, une résilience accrue et une plus grande agilité opérationnelle, tout en maîtrisant vos dépenses. Gardez donc cette méthode de contournement sous le coude, mais visez toujours la modernisation et l’optimisation complètes de votre stack dans Azure.
Microsoft continue d’aider la communauté des développeurs AI et propose désormais de nouveaux modèles d’applications Chat IA développé en .NET. Avec ces modèles d’application comme point de départ, vous pouvez rapidement créer des applications web de chat avec un ou des modèles d’intelligence artificielle dédiés. Tous ces modèles d’application AI en .NET sont désormais disponibles en préversion depuis mars 2025.
Vous souhaitez vous lancer dans le développement de l’IA, mais vous ne savez pas par où commencer ? J’ai un cadeau pour vous : nous avons un nouveau modèle d’application Web de chat sur l’IA qui est maintenant disponible en avant-première. 😊 Ce modèle fait partie de nos efforts continus pour faciliter la découverte et l’utilisation du développement de l’IA avec .NET
A quoi sert une application développée pour du chat IA ?
Une application de chat IA ne se contente pas de générer des réponses : elle les enrichit à partir de contenus existants (comme du code, des documents, etc.).
Un modèle d’embedding, qui transforme des textes en vecteurs numériques. → Il est utilisé pour rechercher les passages les plus pertinents dans une base de connaissances locale ou distante.
Un modèle génératif, qui prend ces passages et génère une réponse claire et naturelle, dans le style d’un assistant conversationnel.
Deux modèles, deux usages ?
Quand on développe une application en relation avec des modèles l’intelligence artificielle intégrant de la données, il est important de comprendre la différence entre deux grandes catégories de modèles d’IA :
1. Modèle de génération de texte (aussi appelés LLM – Large Language Models)
🔹 Objectif : Générer du texte naturel en réponse à une consigne 🔹 Entrée : Une instruction, un prompt ou une question 🔹 Sortie : Une réponse en langage humain, souvent contextualisée 🔹 Cas d’usage :
Assistants conversationnels (chatbots)
Rédaction automatique de contenu
Résumé ou reformulation de documents
Réponse à des questions en langage naturel
🧪 Exemple d’interaction :
Entrée : “Explique-moi le fonctionnement d’un moteur thermique.” Sortie : “Un moteur thermique fonctionne en convertissant la chaleur issue de la combustion d’un carburant en énergie mécanique…”
2. Modèle d’embedding (encodage vectoriel)
🔹 Objectif : Représenter un texte sous forme de vecteur numérique pour comparaison sémantique 🔹 Entrée : Une phrase, un document, une question, etc. 🔹 Sortie : Un vecteur (tableau de nombres) capturant le sens du texte 🔹 Cas d’usage :
Recherche sémantique (trouver un document similaire)
Détection de doublons ou de similarité
Indexation pour des bases vectorielles
Classement ou regroupement de contenus (clustering)
🧪 Exemple d’interaction :
Entrée : “Comment entretenir une voiture électrique ?” Sortie : [0.12, -0.03, 0.57, ...] (vecteur utilisable pour comparer avec d’autres)
Comment ce modèle d’application est-il construit ?
Architecture et technologies :
Application web Blazor (.NET) avec des composants Razor interactifs côté serveur
Base de données SQLite utilisée pour le cache d’ingestion via Entity Framework Core
Intégration avec les modèles d’IA d’Azure OpenAI Service
Fonctionnalités principales :
Chat avec IA augmentée par récupération (RAG)
Utilise un modèle d’IA pour générer des réponses intelligentes
Les réponses sont enrichies par des données extraites de documents
Extrait le texte et crée des embeddings vectoriels via un modèle de type embedding
Stocke les vecteurs dans un JsonVectorStore pour les recherches sémantiques
Interface utilisateur
Composants de chat interactifs (ChatMessageList, ChatInput)
Rendu Markdown et sanitisation HTML via les bibliothèques JavaScript
Workflow :
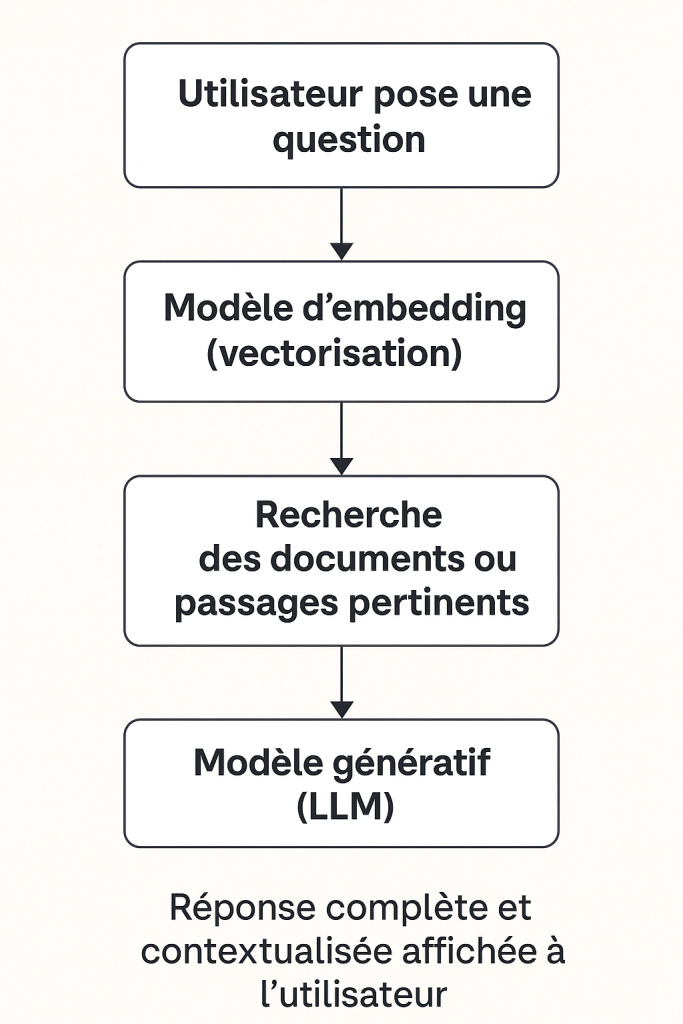
Au démarrage, l’application ingère les documents (par exemple des fichiers PDF), les découpe en fragments, puis les encode sous forme de vecteurs numériques grâce au modèle d’embedding (Modèle 2).
L’utilisateur interagit via l’interface de chat, en posant une question en langage naturel. Cette requête est ensuite traitée par le modèle génératif (Modèle 1), mais pas directement…
Avant de répondre, le système utilise le modèle d’embedding (Modèle 2) pour retrouver les passages les plus pertinents dans les documents indexés, en comparant leur sens avec celui de la question.
Enfin, le modèle génératif (Modèle 1) s’appuie à la fois sur ces passages trouvés et sur ses propres connaissances générales pour générer une réponse complète, claire et contextualisée.
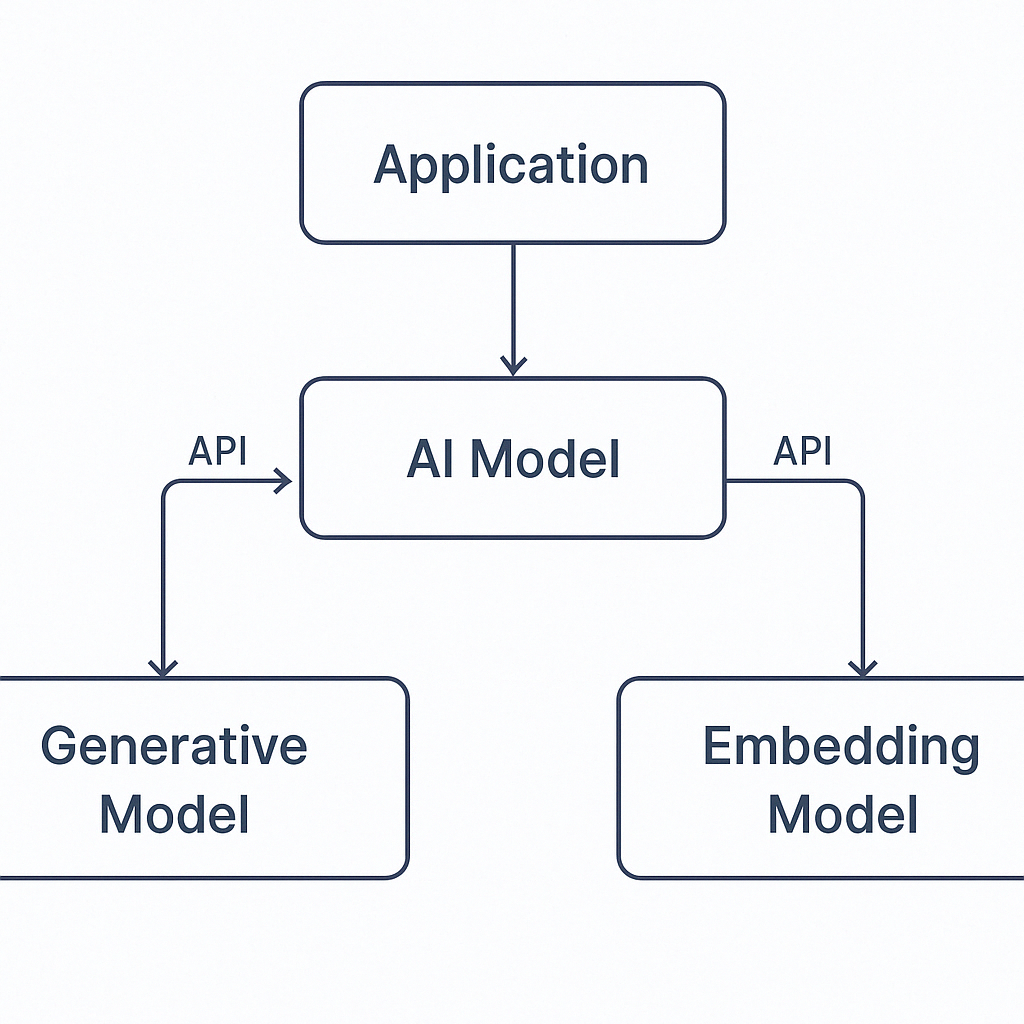
Comment connecte-t-on cette application avec un modèle d’IA ?
Ces exemples d’application ne contiennent pas l’intelligence artificielle elle-même, mais elle interagit avec un modèle IA externe (hébergé dans le cloud, en local ou dans un container).
Enfin, découvrez le dernier épisode du stand-up de la communauté .NET AI, dans lequel Alex, Bruno et Jordan présentent les nouveaux modèles :
Dans cet article, je vous propose de tester l’application en connectant celle-ci vers 3 modèles d’IA :
GitHub
Azure OpenAI
Ollama
Voici les différentes étapes que nous allons suivre :
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
Etape 0 – Rappel des prérequis :
Afin de tester les différents modèles AI en .NET, nous allons avoir besoin de :
Un poste local
Un compte GitHub des modèles GitHub Models
Une souscription Azure si utilisation du service Azure OpenAI
Commençons par créer préparer le poste local.
Etape I – Préparation du poste local :
Rendez-vous sur la page suivante afin de télécharger Visual Studio Code :
Une fois téléchargée, lancez l’installation de ce dernier :
Rendez-vous sur la page suivante afin de télécharger la version 9.0 de .NET :
Une fois téléchargée, lancez l’installation :
Une fois l’installation réussie, fermez celle-ci :
Enfin, redémarrez le poste local :
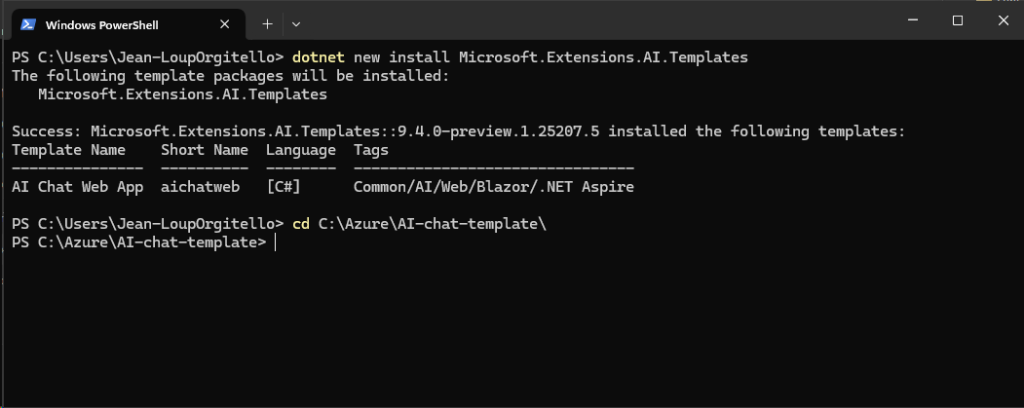
Une fois le poste local redémarré, ouvrez Windows Terminal :
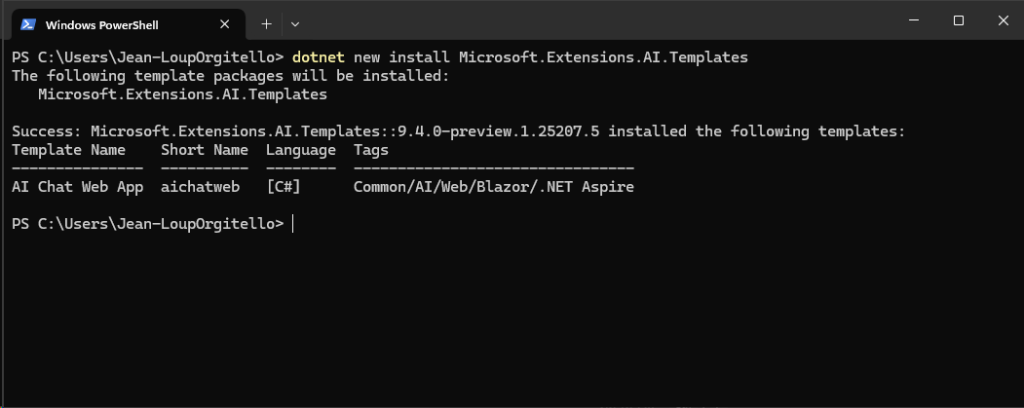
Installer les modèles de projet pour l’extension .NET liée à Microsoft.Extensions.AI, qui fait partie de l’écosystème Semantic Kernel :
dotnet new install Microsoft.Extensions.AI.Templates
Créez un dossier sur votre poste, puis positionnez-vous dedans :
Ne fermez pas cette fenêtre Windows PowerShell.
Notre environnement local est prêt. Avant de déployer des applications basées sur les templates d’IA, nous avons besoin de récupérer les identifiants de connexion (token) de certains modèles IA. Commençons par le plus simple : GitHub.
Etape II – Test de l’application avec le modèle GitHub :
Rendez-vous sur la page d’accueil de GitHub, puis authentifiez-vous, ou créez un compte au besoin :
Cliquez sur votre photo de profil en haut à droite, puis cliquez sur le bouton des Paramètres :
Tout en bas, cliquez sur le menu des paramètres suivant :
Créez un token à granularité fine, pour une utilisation personnelle de l’API GitHub :
Nommez ce token, puis choisissez une date d’expiration :
Cliquez-ici pour générer ce token :
Confirmez votre choix :
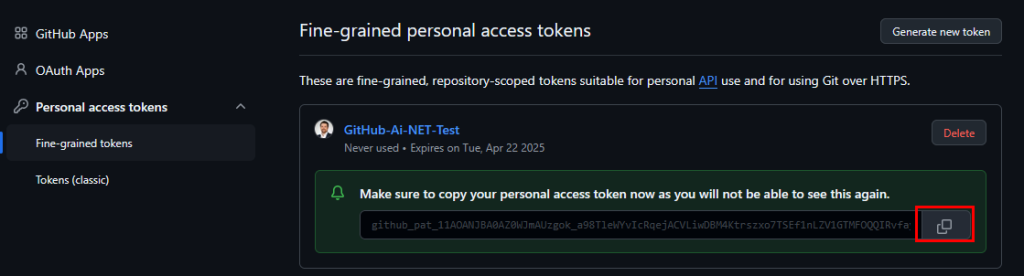
Copiez la valeur du token GitHub :
Retournez sur la fenêtre Windows PowerShell ouverte précédemment, puis lancez la commande suivante afin d’utiliser le template aichatweb pour créer une application web de chat IA en lien avec le modèle GitHub :
dotnet new aichatweb -n GitHubModels --provider githubmodels --vector-store local
Ouvrez l’explorateur Windows afin de constater la création d’un nouveau dossier ainsi que le code de l’application :
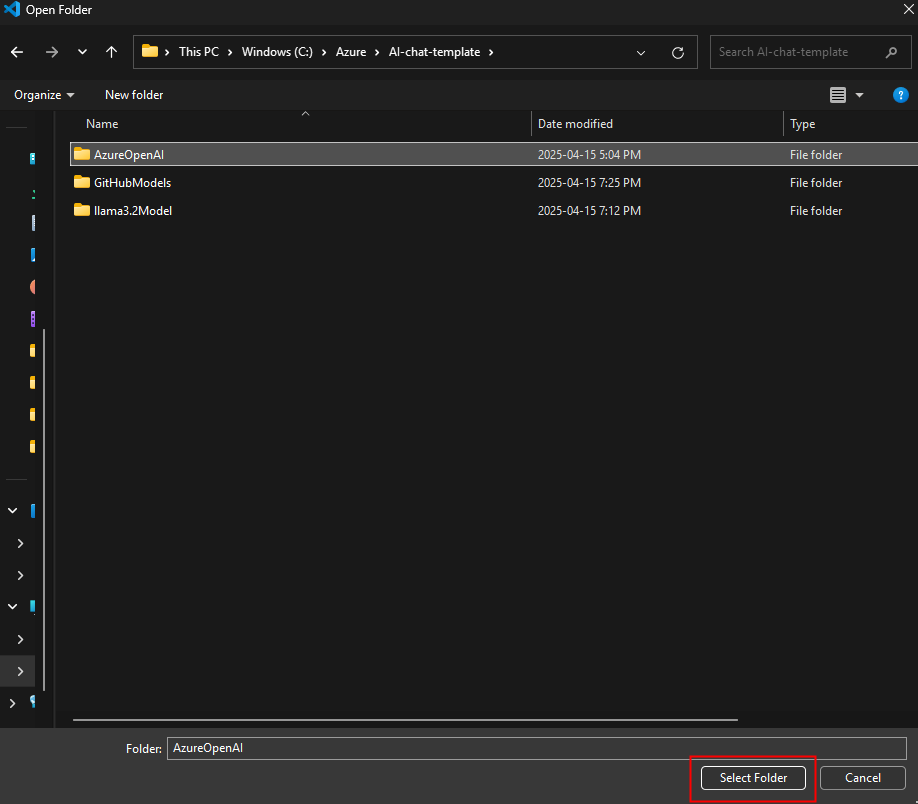
Sur votre poste local, ouvrez Visual Studio Code, puis choisissez l’action d’ouverture d’un dossier :
Sélectionnez le dossier créé par l’application IA :
Constatez l’ouverture de l’application dans Visual Studio Code :
Ouvrez la fenêtre Terminal :
Stockez un secret utilisateur localement (ici un token) de manière sécurisée pour notre projet .NET :
dotnet user-secrets set GitHubModels:Token github...
Affichez tous les secrets stockés localement pour le projet courant :
dotnet user-secrets list
Ajoutez ou retirer au besoin des fichiers PDF utilisés durant la phase d’indexation sémantique)
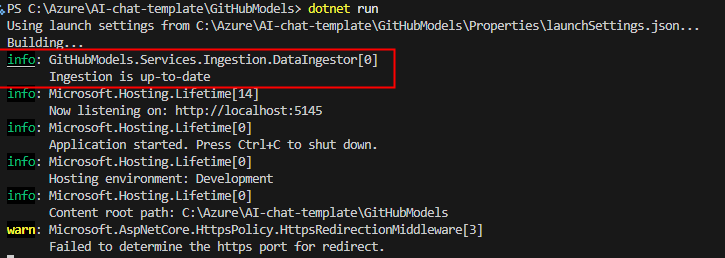
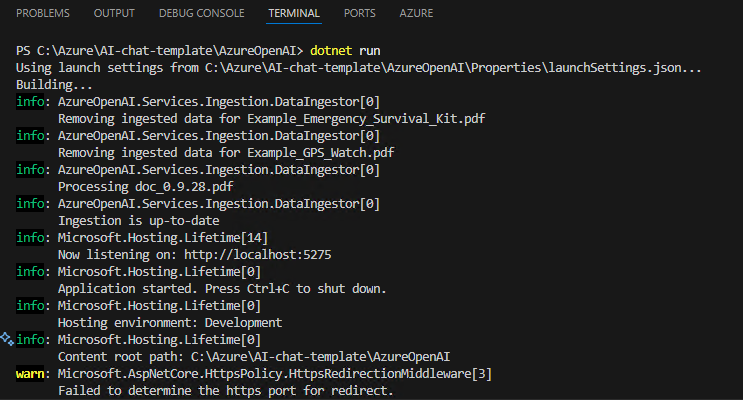
Compilez et exécutez l’application .NET dans le dossier courant :
dotnet run
L’application vérifie dans les sources de données si nouveau documents sont à indexer ou vectoriser :
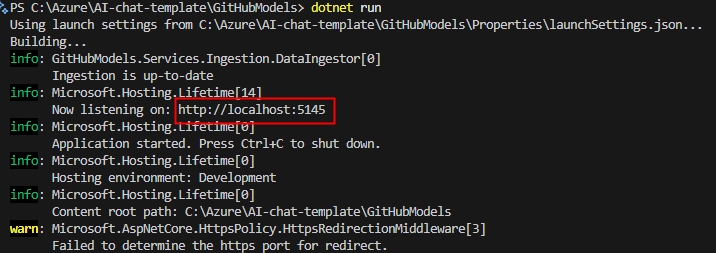
Ce message vous indique que l’application tourne localement sur le port 5145 :
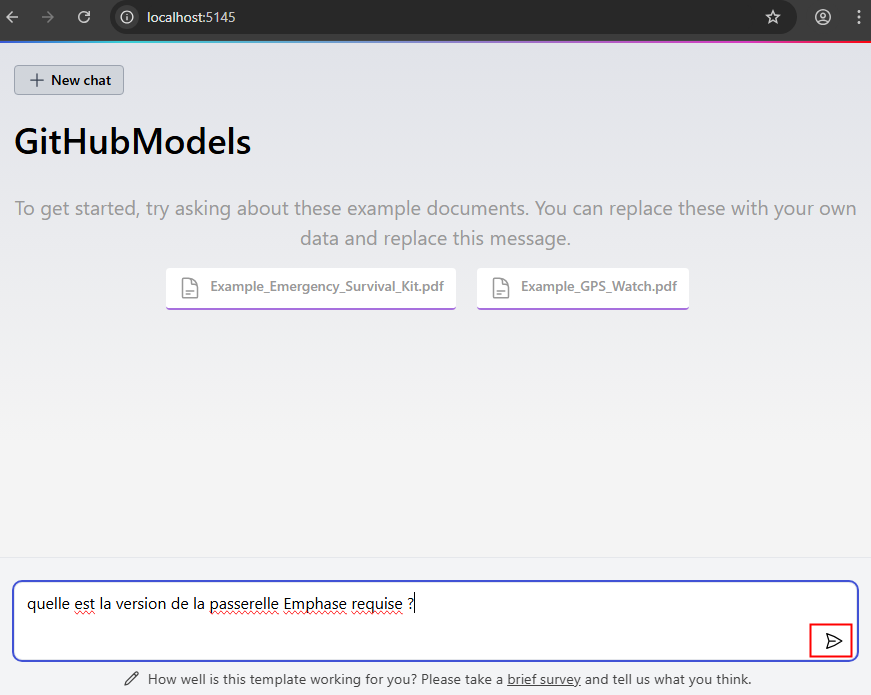
Ouvrez un navigateur web à cette adresse:port, puis posez une question à l’IA sur un sujet d’ordre général ou propre aux documents ingérés :
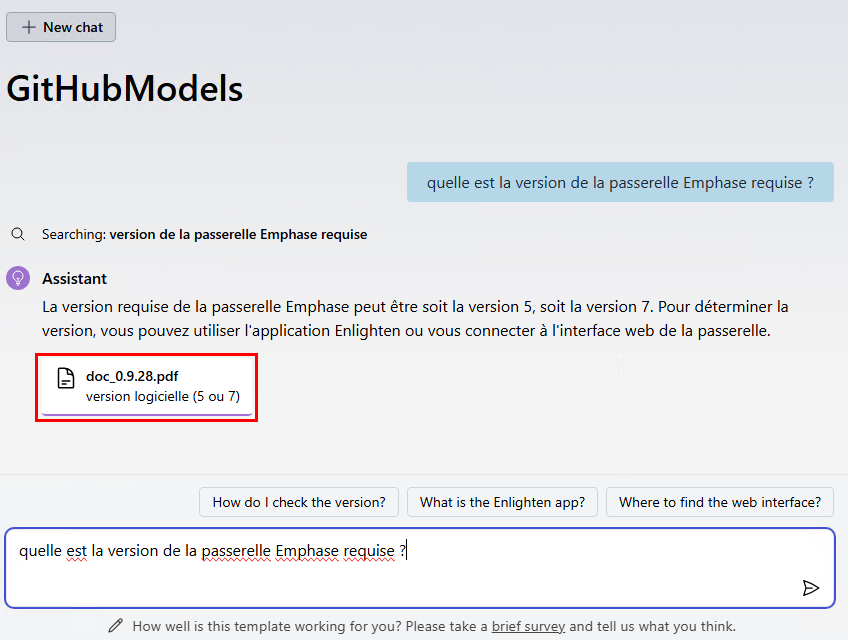
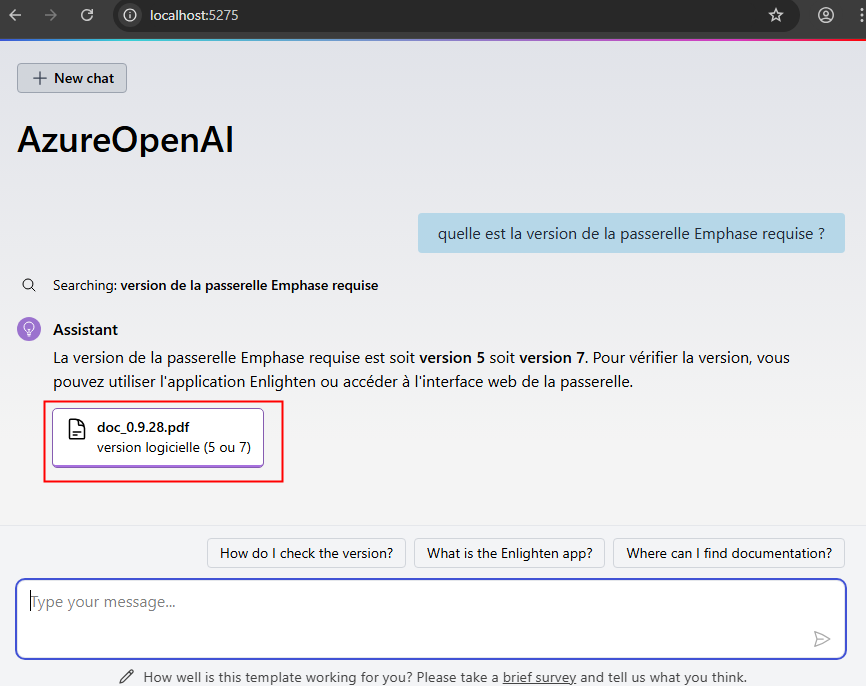
Constatez la rapidité du résultat et la ou les sources associés, puis cliquez dessus :
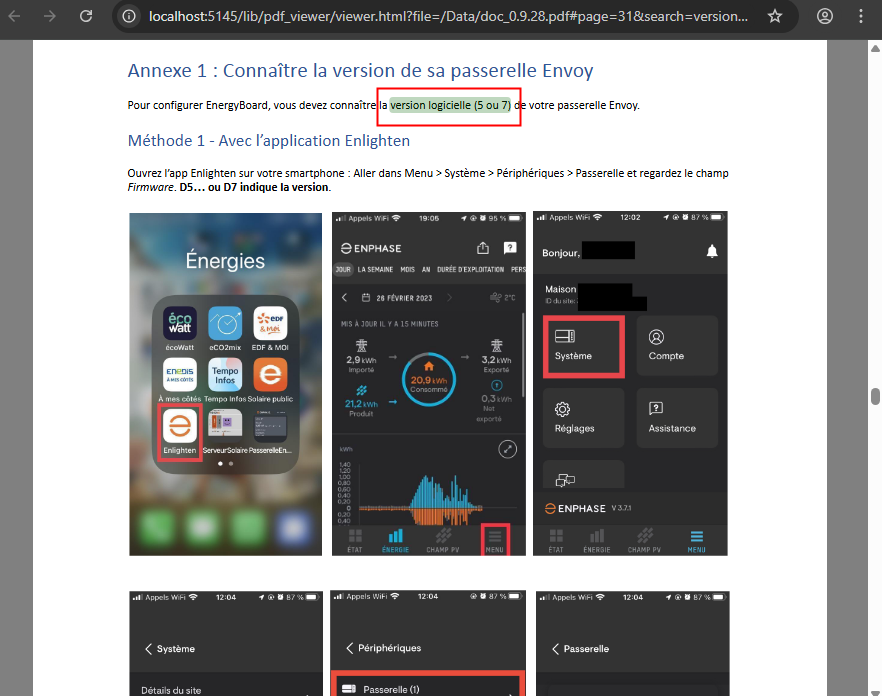
Constatez la sélection de texte en correspondance avec la question posée à l’IA :
Le test avec le modèle GitHub a bien fonctionné, pensez à détruire le token sur le portail de GitHub pour des questions de sécurité
Continuons les tests de l’application de chat IA avec le modèle Azure OpenAI.
Etape III – Test de l’application avec le modèle Azure OpenAI :
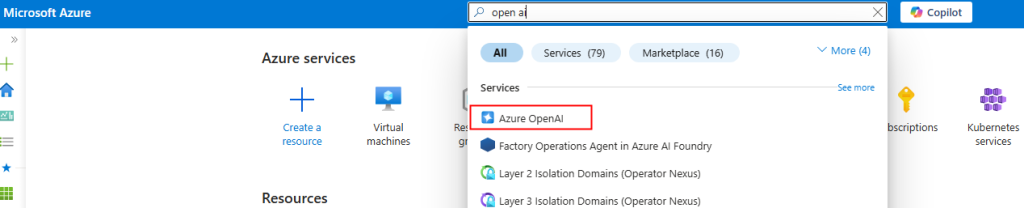
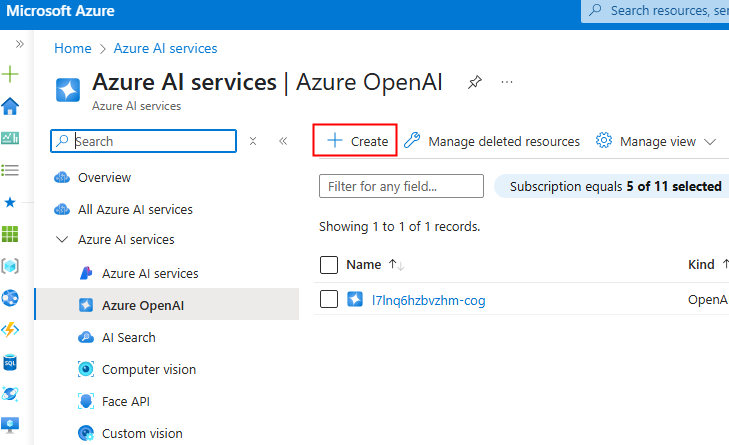
Depuis le portail Azure, commencez par rechercher le service Azure OpenAI :
Cliquez-ici pour créer un nouveau service :
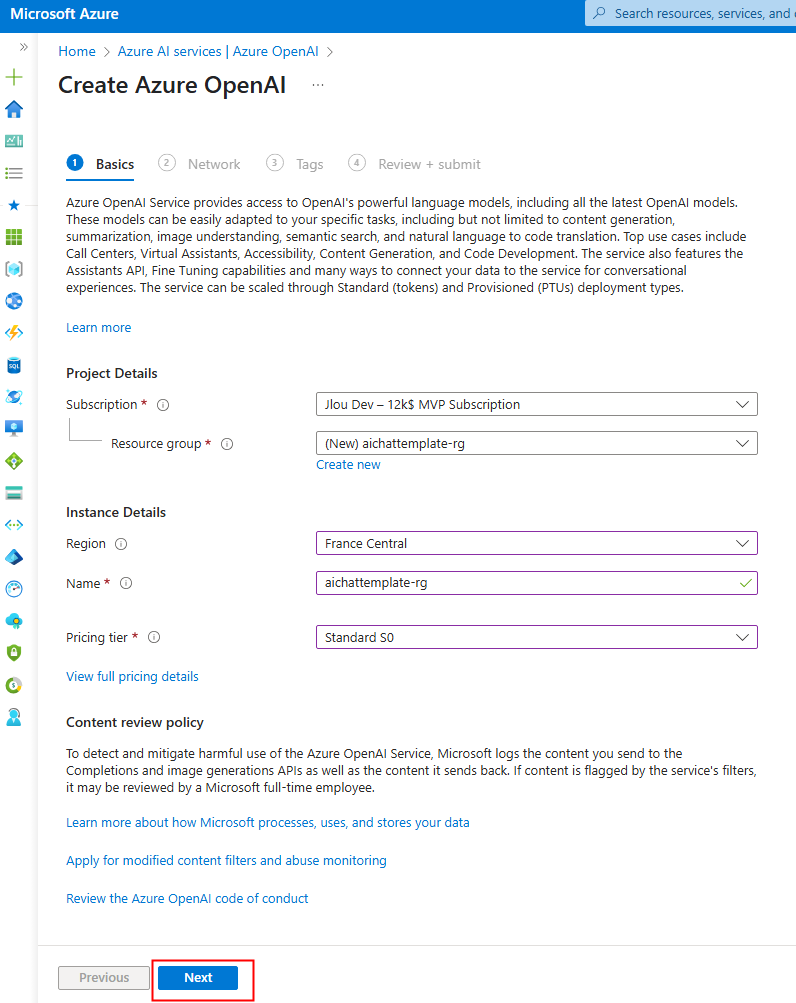
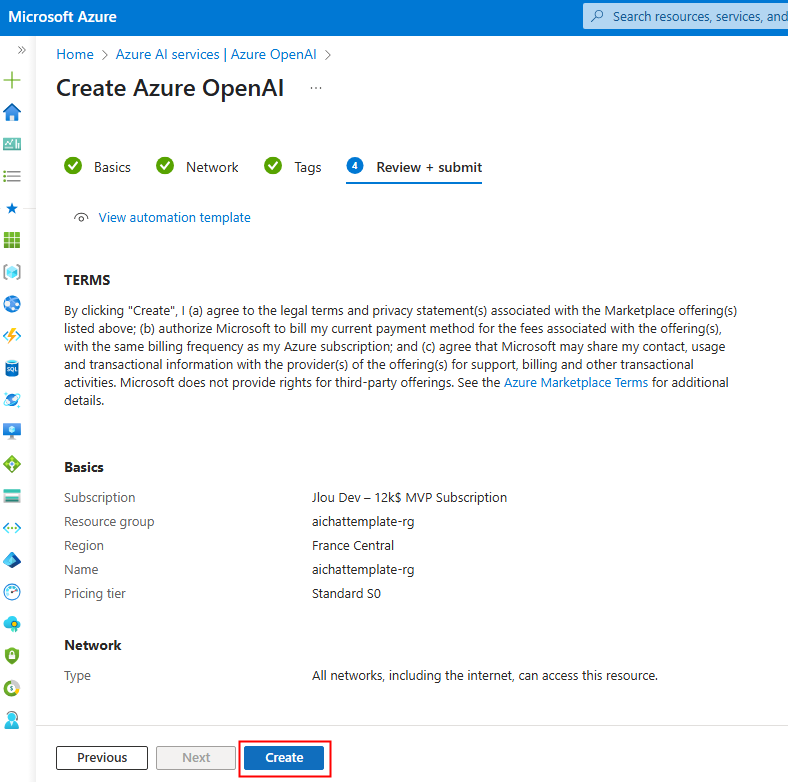
Renseignez toutes les informations, conservez le modèle de prix S0 (suffisant pour nos tests), puis cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Créer :
Une fois le déploiement terminé, cliquez-ici :
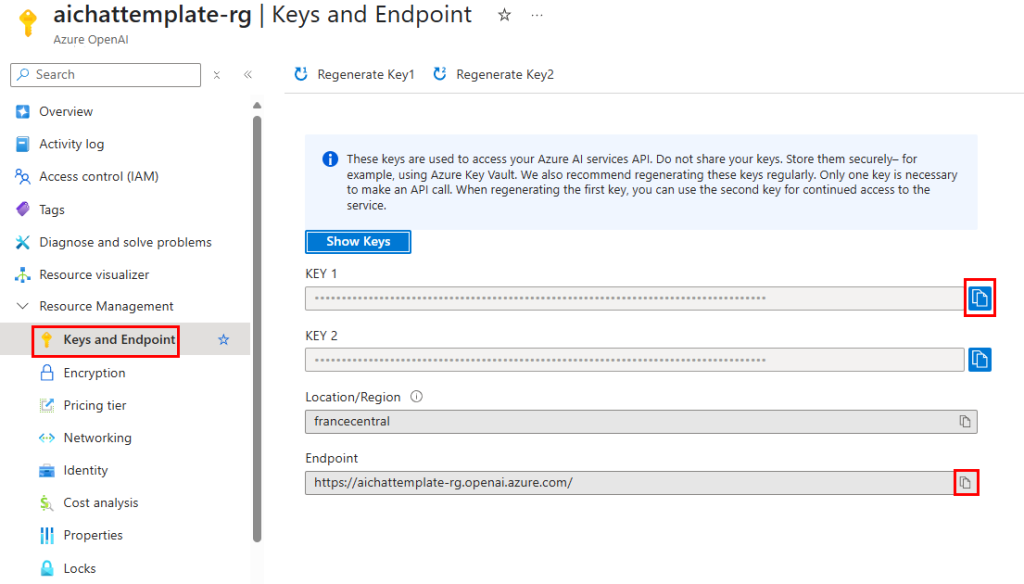
Copiez les 2 informations suivantes dans votre bloc-notes afin de vous y connecter plus tard à via API :
Afin de créer les deux modèle d’IA nécessaires au travers d’Azure, cliquez-ici pour ouvrir le portail Microsoft AI Foundry :
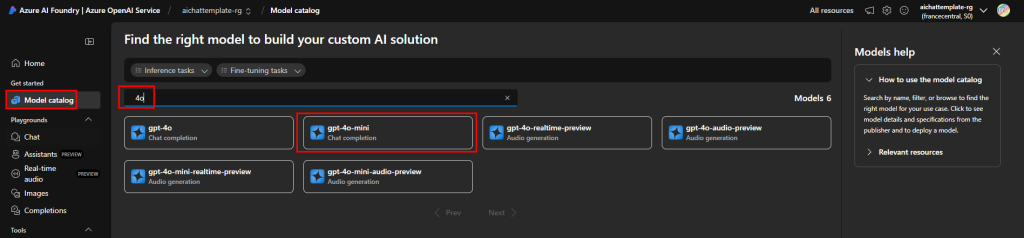
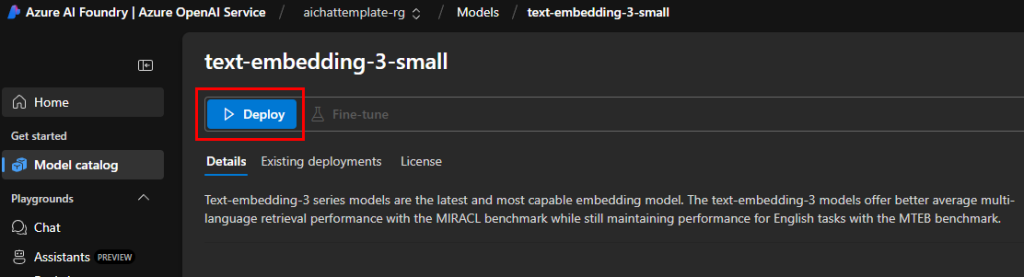
Sur ce portail, commencez par rechercher le premier modèle d’IA nécessaire à notre application :
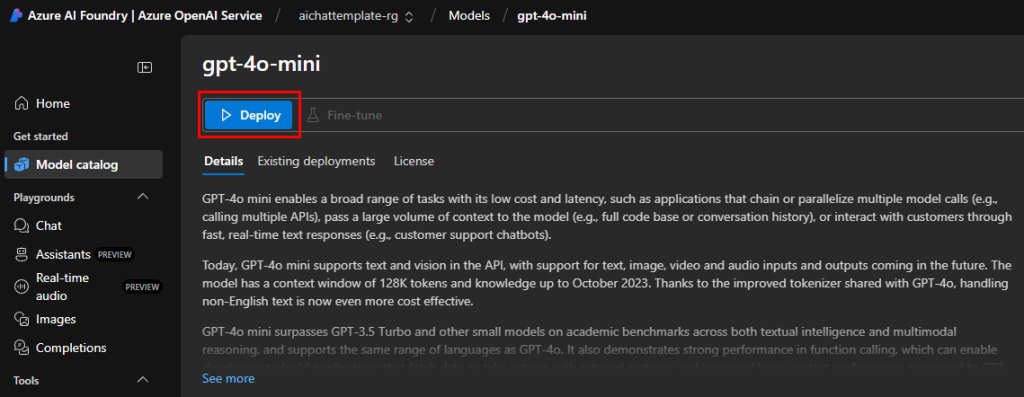
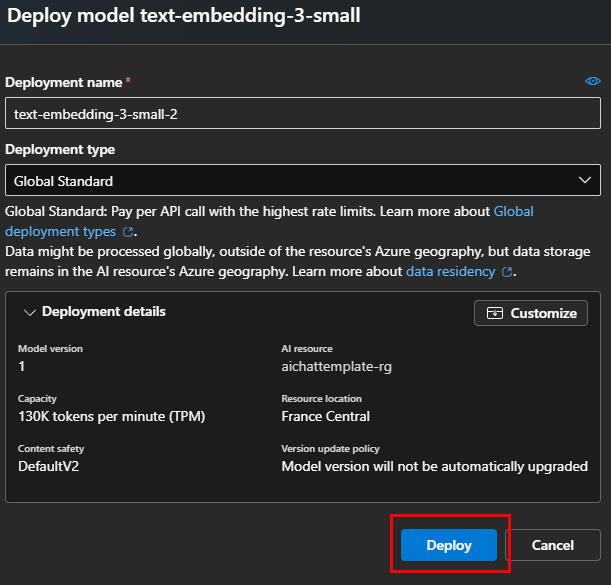
Cliquez sur Déployer :
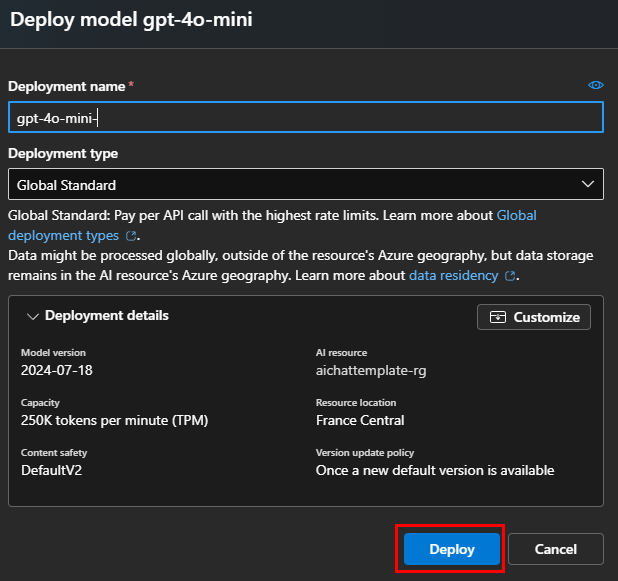
Conservez le nom d’origine, puis cliquez sur Déployer :
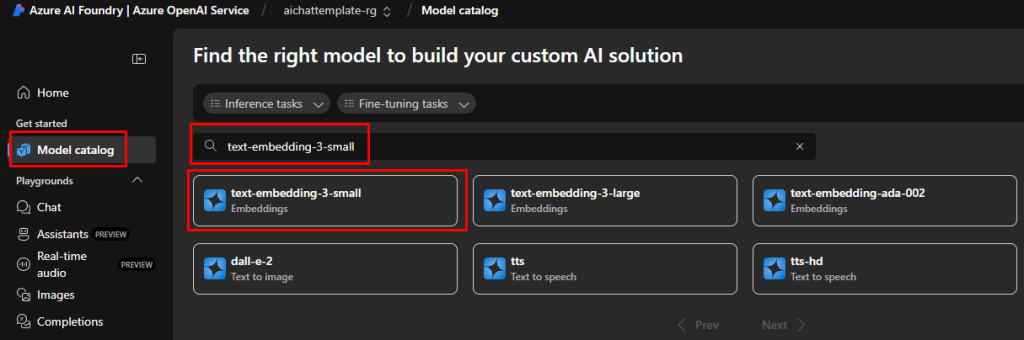
Retournez sur le catalogue des modèles d’IA, puis recherchez le second modèle d’IA nécessaire à notre application :
Cliquez sur Déployer :
Conservez le nom d’origine, puis cliquez sur Déployer :
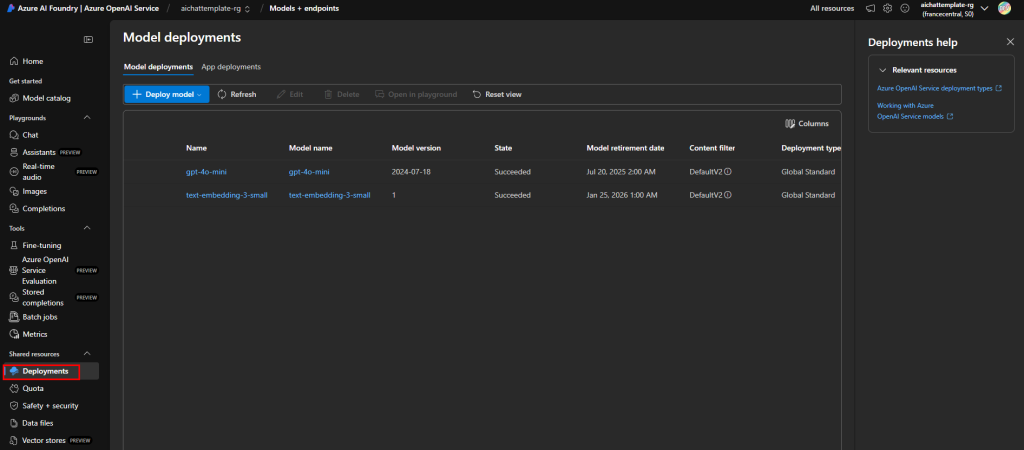
Vérifiez la présence des 2 modèles déployés dans le menu suivant :
Retournez sur la fenêtre Windows PowerShell ouverte précédemment, puis lancez la commande suivante afin d’utiliser le template aichatweb pour créer une application web de chat IA en lien avec le service AzureOpenAI :
dotnet new aichatweb -n AzureOpenAI --provider azureopenai --vector-store local
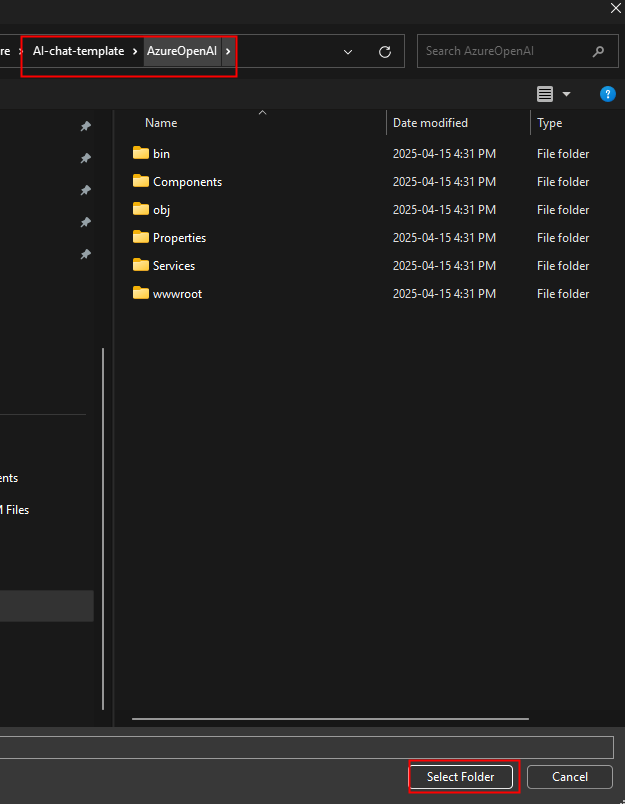
Ouvrez l’explorateur Windows afin de constater la création d’un nouveau dossier :
Sur votre poste local, ouvrez Visual Studio Code, puis choisissez l’action d’ouverture d’un dossier :
Sélectionnez le dossier créé par l’application IA :
Constatez l’ouverture de l’application dans Visual Studio Code :
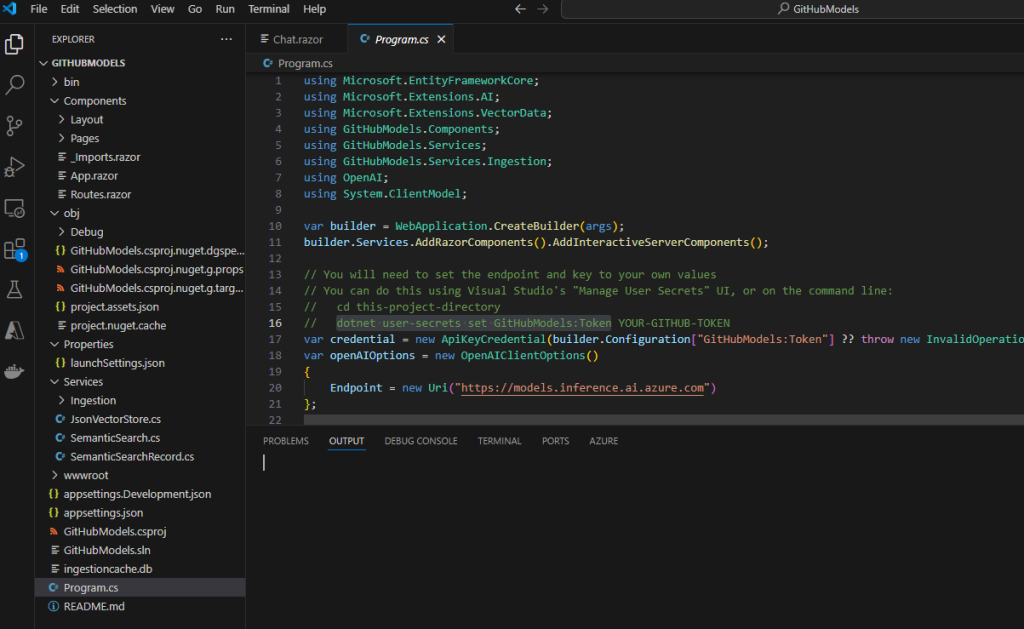
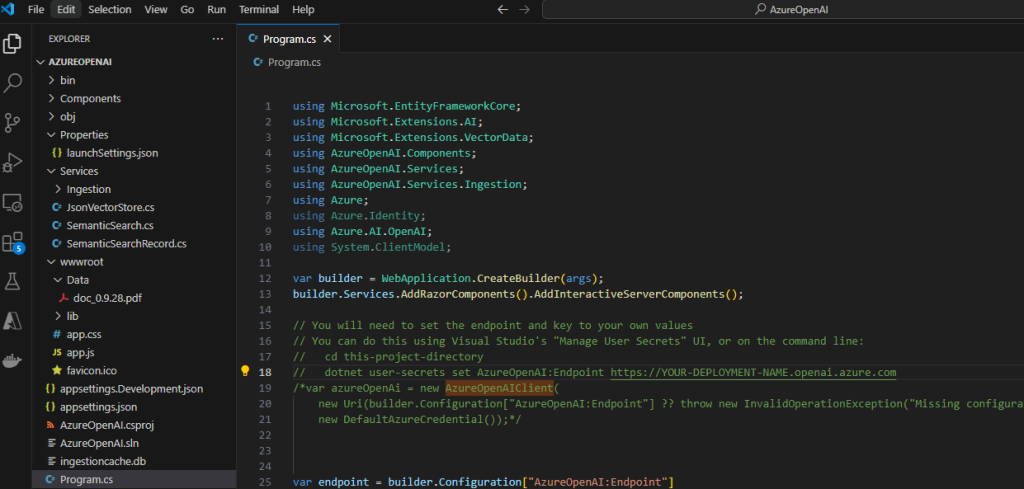
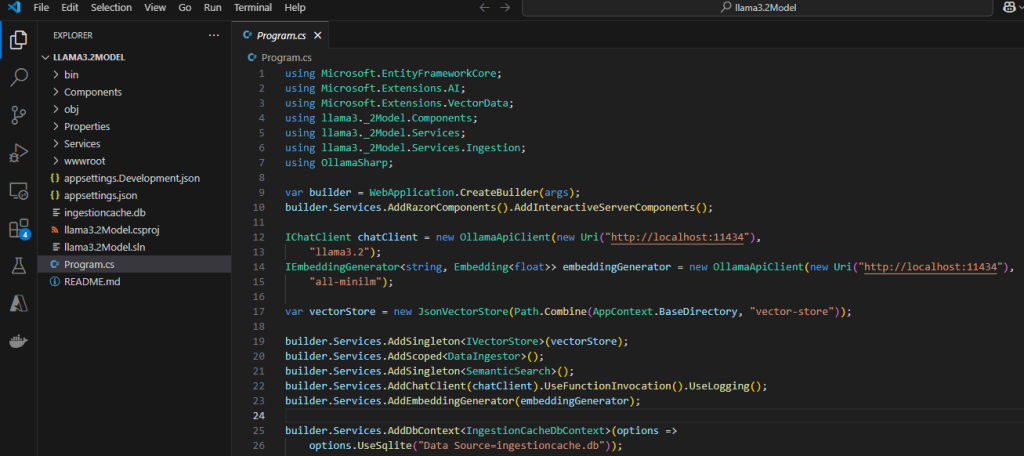
Afin de passer d’une authentification basée sur une identité Azure (DefaultAzureCredential) à une authentification explicite par clé API (AzureKeyCredential), remplacer le code suivant :
var azureOpenAi = new AzureOpenAIClient(
new Uri(builder.Configuration["AzureOpenAI:Endpoint"] ?? throw new InvalidOperationException("Missing configuration: AzureOpenAi:Endpoint. See the README for details.")),
new DefaultAzureCredential());
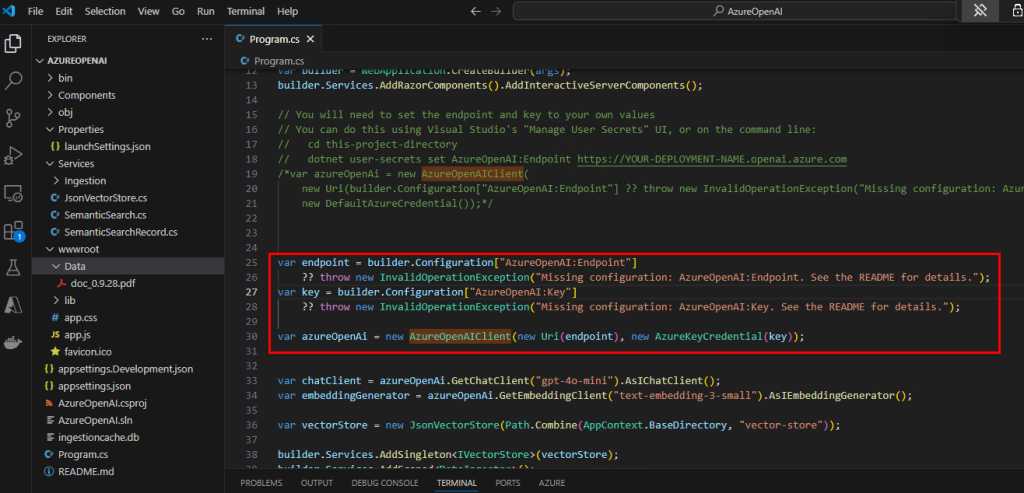
Par celui-ci, puis sauvegardez le fichier Program.cs :
var endpoint = builder.Configuration["AzureOpenAI:Endpoint"]
?? throw new InvalidOperationException("Missing configuration: AzureOpenAI:Endpoint. See the README for details.");
var key = builder.Configuration["AzureOpenAI:Key"]
?? throw new InvalidOperationException("Missing configuration: AzureOpenAI:Key. See the README for details.");
var azureOpenAi = new AzureOpenAIClient(new Uri(endpoint), new AzureKeyCredential(key));
Ouvrez la fenêtre Terminal :
Enregistrez localement (et de manière sécurisée) le point de terminaison de l’instance Azure OpenAI :
dotnet user-secrets set AzureOpenAI:Endpoint https://aichattemplate-rg.openai.azure.co
Enregistrez de manière sécurisée la clé API de l’instance Azure OpenAI dans les secrets utilisateur de .NET :
dotnet user-secrets set AzureOpenAI:Key 1zF4OGPseV...
Affichez tous les secrets stockés localement pour le projet courant :
dotnet user-secrets list
Ajoutez ou retirer au besoin des fichiers PDF utilisées durant la phase d’indexation sémantique)
Compilez et exécutez l’application .NET dans le dossier courant :
dotnet run
Ouvrez un navigateur web à cette adresse:port indiqué, puis posez une question à l’IA sur un sujet d’ordre général ou propre aux documents ajoutés :
Constatez la rapidité du résultat et la ou les sources associés, puis cliquez dessus :
Constatez la sélection de texte en correspondance avec la question posée :
Le test avec le service Azure OpenAI a bien fonctionné, pensez à détruire le service une fois les tests terminés.
Terminons les tests de l’application de chat IA avec le modèle local Ollama.
Etape IV – Test de l’application avec le modèle Ollama :
Rendez-vous sur la page suivante afin de télécharger Ollama :
Une fois téléchargée, lancez l’installation :
Une fois l’installation réussie, vérifiez via l’URL suivante le bon fonctionnement du service :
http://localhost:11434/
Depuis le menu Démarrer, ouvrez l’application CMD, puis lancez la commande suivante :
ollama pull llama3.2
Ollama télécharge alors la version mini de Phi3 d’environ 2 Go
ollama pull all-minilm
Ollama télécharge alors un modèle ouvert d’environ 270 Mo :
Vérifiez la liste des modèles en place avec la commande suivante :
ollama list
Retournez sur la fenêtre Windows PowerShell ouverte précédemment, puis lancez la commande suivante afin d’utiliser le template aichatweb pour créer une application web de chat IA en lien avec le modèle Ollama :
dotnet new aichatweb -n llama3.2Model --provider ollama --vector-store local
Ouvrez l’explorateur Windows afin de constater la création d’un nouveau dossier ainsi que le code de l’application :
Sur votre poste local, ouvrez Visual Studio Code, puis choisissez l’action d’ouverture d’un dossier :
Sélectionnez le dossier créé par l’application IA :
Constatez l’ouverture de l’application dans Visual Studio Code :
Ouvrez la fenêtre Terminal :
Ajoutez ou retirer au besoin des fichiers PDF utilisées durant la phase d’indexation sémantique)
Compilez et exécutez l’application .NET dans le dossier courant :
dotnet run
L’application vérifie dans les sources de données configurées si nouveau documents sont à indexer ou vectoriser :
Cette ligne vous indique que l’application tourne localement sur le port 5145 :
Ouvrez un navigateur web à cette adresse:port, puis posez une question à l’IA sur un sujet d’ordre général ou propre aux documents ajoutés :
Constatez le pic d’usage du CPU/GPU selon la configuration matérielle de votre poste local :
Constatez la rapidité/lenteur du résultat :
Conclusion
Avec l’arrivée des nouveaux templates .NET dédiés à l’intelligence artificielle, il n’a jamais été aussi simple de créer des applications web de chat connectées à des modèles IA.
Que vous choisissiez un modèle cloud (comme Azure OpenAI), un modèle public (via GitHub), ou même un modèle local (comme ceux proposés par Ollama), l’infrastructure est prête à l’emploi et parfaitement intégrée à l’écosystème .NET.
Les solutions de bureau à distance, telles qu’Azure Virtual Desktop et Windows 365, reposent sur des protocoles de transport pour offrir une expérience utilisateur fluide et réactive. Par défaut, UDP est souvent privilégié pour sa faible latence, mais dans certains environnements, la fiabilité et la stabilité offertes par TCP priment.
Cet article détaille les spécificités de chacun de ces protocoles, leurs avantages et inconvénients, et propose deux approches pour forcer l’usage de TCP : une modification côté serveur et une modification côté client, que ce soit directement via le registre ou en déployant une stratégie de groupe (GPO).
TCP et son rôle dans les solutions de bureau à distance :
Le Transmission Control Protocol (TCP) est un protocole orienté connexion qui assure la fiabilité des échanges. Il garantit que les paquets arrivent dans l’ordre et, en cas de perte, les retransmet automatiquement.
Avantages de TCP :
Fiabilité et intégrité des données : Chaque paquet est vérifié et retransmis en cas d’erreur ou de perte.
Contrôle d’erreur et ordonnancement : Les données arrivent dans le bon ordre, ce qui est essentiel pour des applications nécessitant une cohérence stricte.
Inconvénients de TCP :
Surcharge et latence accrue : Les mécanismes de contrôle (comme le handshake initial) ajoutent un certain délai.
Moins performant pour les applications ultra-réactives : La latence induite peut être un frein pour certaines applications en temps réel.
UDP et ses applications dans le Remote Desktop :Le User Datagram Protocol (UDP) est un protocole sans connexion qui envoie les paquets sans vérifier leur réception ni leur ordre. Cette approche permet une transmission rapide avec une latence très réduite, idéale pour des sessions interactives.
Avantages de UDP :
Faible latence : Parfait pour des sessions de Remote Desktop où la réactivité est cruciale.
Moindre surcharge : L’absence de contrôle d’erreur exhaustif accélère le transfert des données.
Inconvénients de UDP :
Fiabilité moindre : Sans retransmission automatique, la perte de paquets peut dégrader la qualité de la session.
Absence de contrôle d’erreur intégré : Dans des environnements instables, cela peut entraîner des distorsions.
Fort de cette comparaison, il apparaît que le choix du protocole doit être adapté au contexte réseau. Par exemple, dans des environnements à qualité réseau variable, forcer l’utilisation de TCP peut s’avérer judicieux pour garantir une meilleure stabilité des connexions.
Forcer le flux TCP côté serveur
Il est possible de forcer le serveur à n’accepter que des connexions TCP, ce qui est particulièrement utile dans des environnements où la stabilité prime. Pour cela, vous pouvez modifier le registre du serveur ou déployer une GPO.
Modification via Registre
Avant modification, le serveur accepte par défaut les connexions en UDP (comme indiqué par vos captures d’écran). Pour forcer TCP, la modification est simple : il suffit d’ajouter la clé de registre SelectTransport.
Pour ce faire, la modification est simple : il suffit d’ajouter la clé de registre SelectTransport :
Voici la commande permettant d’ajouter automatiquement cette clé de registre Windows avec des droits administrateur :
« Use either UDP or TCP (default) » : Si la connexion UDP est possible, la majorité du trafic RDP l’utilisera.
« Use only TCP » : Toutes les connexions RDP se feront exclusivement via TCP.
Si cette stratégie n’est pas configurée ou est désactivée, RDP sélectionnera automatiquement le protocole optimal pour offrir la meilleure expérience utilisateur.
Testons maintenant la configuration côté client.
Forcer le flux TCP côté client
Passons à présent à la configuration côté client. Avant modification, le client se connecte en UDP, comme le montrent les captures d’écran. Pour forcer l’utilisation de TCP (via WebSocket, qui repose sur TCP), il suffit d’ajouter la clé de registre fClientDisableUDP.
Avant modification, le client fonctionnait en UDP, comme vous pouvez le constater sur la capture d’écran ci‑dessous.
Pour ce faire, la modification est simple : il suffit d’ajouter la clé de registre fClientDisableUDP.
Voici la commande permettant d’ajouter automatiquement cette clé de registre Windows avec des droits administrateur :
Après modification, la connexion se fait exclusivement en TCP. Ce changement assure que le client ne tente plus d’établir une connexion via UDP :
Conclusion
Le choix entre TCP et UDP dans des environnements de bureau à distance comme Azure Virtual Desktop et Windows 365 se résume à un compromis entre rapidité et fiabilité :
UDP offre une faible latence, idéale pour des sessions interactives, mais peut souffrir de pertes de paquets dans des réseaux instables.
TCP, même via une couche WebSocket, garantit la transmission fiable des données, au prix d’un léger surcoût en latence.
Note technique : Forcer l’utilisation de TCP est particulièrement recommandé dans les environnements où la qualité du réseau est variable ou sujette à des perturbations. Dans ces situations, bien que TCP puisse introduire une latence légèrement supérieure, il offre une stabilité et une fiabilité accrues, assurant ainsi une expérience utilisateur plus homogène.
En forçant l’utilisation de TCP via une modification de registre côté serveur (ou via une GPO) et/ou côté client, vous pouvez améliorer la stabilité des connexions, particulièrement dans des environnements où la qualité de la connexion est incertaine.
Ces approches vous permettent de mieux contrôler la configuration de votre infrastructure de Remote Desktop, optimisant ainsi l’expérience pour vos utilisateurs.